聚类算法K-means能够处理一些聚类问题,但是其本身存在缺点:1.对噪声(奇异点)很敏感;2.易收敛于局部最优解;3.不能发现非球状簇。
具体应用时,需要提前设置K值,且K值对运算过程和结果的影响很大;对于不规则聚类的处理效果很差,如下图所示:
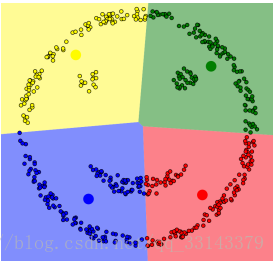
本文将提出另一种聚类算法,基于密度的聚类算法——DBSAN,它能够很好地解决上面实际应用中存在的问题。
一、 密度聚类、DBSCAN
1、密度聚类的核心思想:
1) 簇群是数据空间中的密集区域,在低密度区域处隔开;
2) 一个簇被定义为最大的密度连接点集;
3) 能够找到任意形状的簇集。
2、基本概念
1) DBSCAN算法中有两个重要参数 :ε和MinPts,前者为密度定义时的邻域半径,后者是定义核心点时的阈值(也就是可以构成一个cluster的所需之最小的点数);
2) ε邻域:以p对象为中心,半径为ε的圆形或球形空间内所有对象的集合;p的ε邻域:
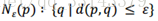
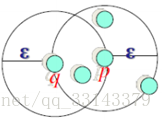
3) 高密度:ε邻域内至少包括MinPts个对象;低密度:ε邻域内对象少于MinPts个。因此上图中,p的密度为高密度,q的为低密度。
4) 三种类型的点:
① 核心点:高密度点,它是位于cluster内部的点,属于某特定簇的点;
② 边界点:低密度点,但其与核心点相邻