查看Spark日志与排查报错问题的方法请看:https://blog.csdn.net/qq_33588730/article/details/109353336
1. org.apache.spark.SparkException: Kryo serialization failed: Buffer overflow
原因:kryo序列化缓存空间不足。
解决方法:增加参数,--conf spark.kryoserializer.buffer.max=2047m。
2. org.elasticsearch.hadoop.rest.EsHadoopNoNodesLeftException: Connection error
原因:此时es.port可能为9300,因为ElasticSearch客户端程序除了Java使用TCP方式连接ES集群以外,其他语言基本上都是使用的Http方式,ES客户端默认TCP端口为9300,而HTTP默认端口为9200。elasticsearch-hadoop使用的就是HTTP方式连接的ES集群。
解决方法:可以将es.port设置为 9200。
3. Error in query: nondeterministic expressions are only allowed in Project, Filter, Aggregate or Window, found
解决方法:如果是SparkSQL脚本,则rand()等函数不能出现在join...on的后面。
4. driver端日志中频繁出现:Application report for application_xxx_xxx (stage: ACCEPTED)
解决方法:通过yarn UI左侧的“Scheduler”界面,搜索自己任务提交的yarn队列,查看资源是否用完,与同队列同事协调资源的合理使用,优化资源使用量不合理的任务,如下所示:
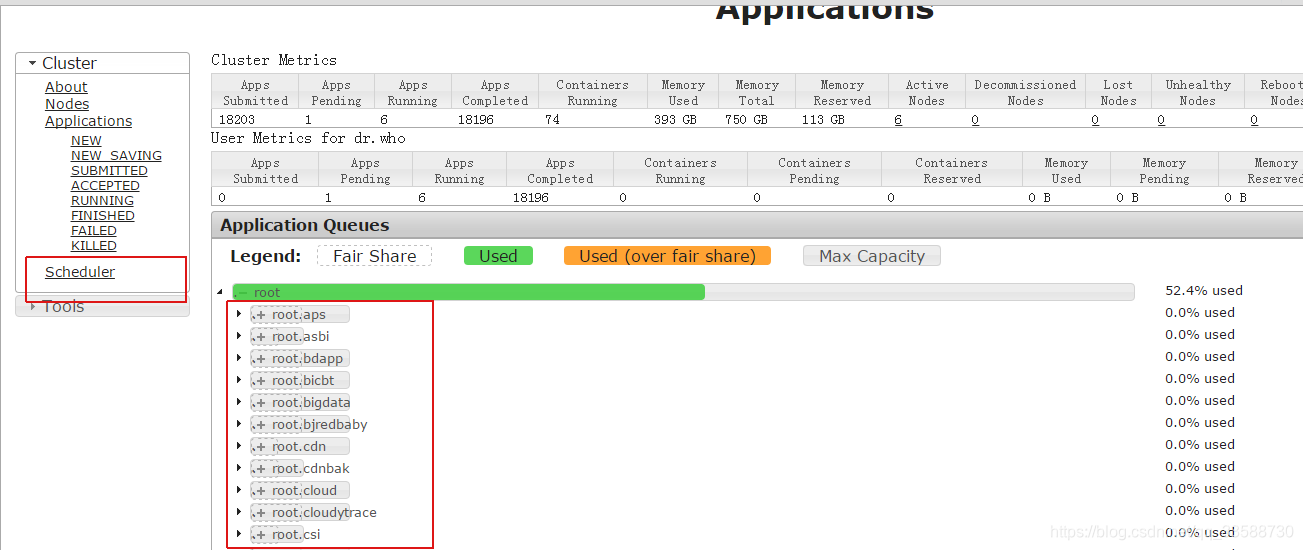
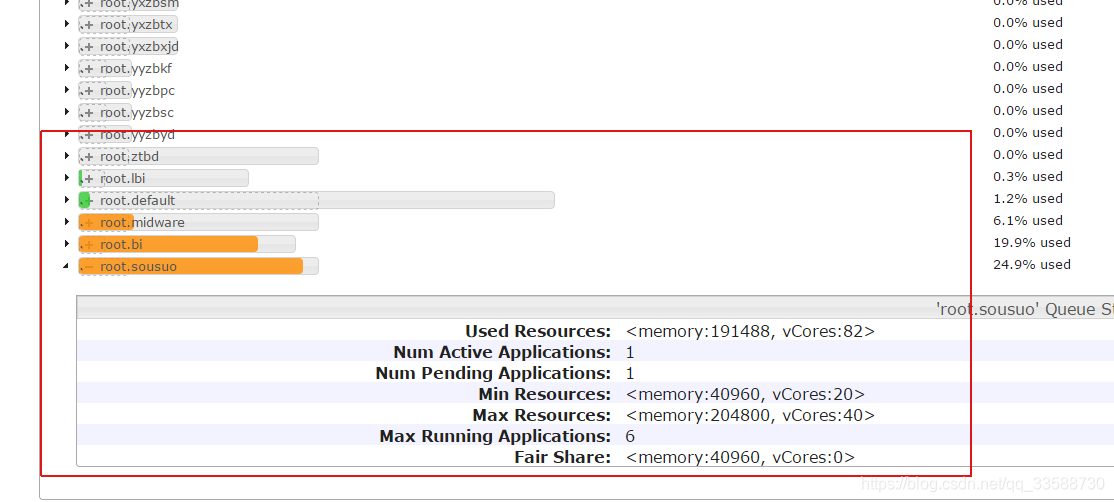
5. Spark任务数据量过大(如上百亿条记录)跑不过去
原因:数据量过大导致executor内存扛不住那么多数据。
解决方法:增加参数,--conf spark.shuffle.spill.numElementsForceSpillThreshold=2000000,将过量数据写入到磁盘中。
6. user clas threw exeception:ml.dmlc.xgboost4j.java.XGBoostError:XGBoostModel trained failed, caused by Values to assemble cannot be null
原因:机器学习训练数据中有为null的地方。
解决方法:把数据中有null的地方去掉,或对null值先进行预处理再训练。
7. Caused by: org.apache.spark.sql.catalyst.parser.ParseException: Datatype void is not supported
原因:Spark不支持Hive表中的void字段类型,代码中临时create的Hive表中,如果from的源表中某字段为全空值,则create table时该临时表的这个字段类型就会变成void。
解决方法:如果是上面这种情况,可以用Hive跑任务或者修改该Hive表的字段类型不为void,或将null转换为string等。
8. ERROR SparkUI: Failed to bind SparkUI java.net.BindException: Address already in use: Service failed after 16 retries
原因:Spark UI端口绑定尝试连续16个端口都已被占用。
解决方法:可以把spark.port.maxRetries参数调的更大如128。
9. Error in Query: Cannot create a table having a column whose name contains commas in Hive metastore
解决方法:查看SparkSQL脚本中是否存在类似于“round(t1.sim_score , 5)”这种以函数结果作为字段值的语句,后面如果没加“as”别名会导致该错误。
10. Failed to send RPC to ...
原因:数据量过大超出默认参数设置的内存分配阈值,container会被yarn杀掉,其他节点再从该节点拉数据时,会连不上。
解决方法:可以优化代码将过多的连续join语句(超过5个)拆分,每3个左右的连续join语句结果生成一个临时表,该临时表再和后面两三个连续join组合,再生成下一个临时表,并在临时表中提前过滤不必要的数据量,使多余数据不参与后续计算处理。只有在代码逻辑性能和参数合理的前提下,最后才能增加--executor-memory、--driver-memory等资源,不能本末倒置。
11. ERROR shuffle.RetryingBlockFetcher: Failed to fetch block shuffle_7_18444_7412, and will not retry
原因:Executor被kill,无法拉取该block。可能是开启DA特性时数据倾斜造成的,其他executor都已完成工作被回收,只有倾斜的executor还在工作,拉取被回收的executor上的数据时可能会拉不到。
解决方法:如果确实是发生了数据倾斜,可以根据这两个链接的方法进行处理:(1)http://www.jasongj.com/spark/skew/;(2)https://www.cnblogs.com/hd-zg/p/6089220.html;
还可以参考《SparkSQL内核剖析》第11章第266页的几种SQL层面的处理方法,如下所示:
--广播小表
select /*+ BROADCAST (table1) */ * from table1 join table2 on table1.id = table2.id
--分离倾斜数据(倾斜key已知)
select * from table1_1 join table2 on table1_1.id = table2.id
union all
select /*+ BROADCAST (table1_2) */ * from table1_2 join table2 on table1_2.id = table2.id
--打散数据(倾斜key未知)
select id, value, concat(id, (rand() * 10000) % 3) as new_id from A
select id, value, concat(id, suffix) as new_id
from (
select id, value, suffix
from B Lateral View explode(array(0, 1, 2)) tmp as suffix
)
--打散数据(倾斜key已知)
select t1.id, t1.id_rand, t2.name
from (
select id ,
case when id = null then concat(‘SkewData_’, cast(rand() as string))
else id end as id_rand
from test1
where statis_date = ‘20200703’) t1
left join test2 t2
on t1.id_rand = t2.id
同时,适度增大spark.sql.shuffle.partitions参数,通过提高并发度的方式也可缓解数据倾斜。
12. org.apache.spark.memory.SparkOutOfMemoryError: Unable to acquire 65536 bytes of memory, got 0
原因:代码逻辑或任务参数配置不合理、数据倾斜等导致OOM。分为driver OOM和executor OOM。
解决方法:(1)查看代码中是否有coalesce()等函数,该函数相比repartition()不会进行shuffle,处理大分区易造成OOM,如果有则可换成repartition(),尽量减少coalesce()的使用。
(2)是否使用了将各executor上所有数据拉回到driver的collect()函数,尽量避免或谨慎使用collect()与cache()等函数,让各executor分布式拉数据与执行,多节点分担海量数据负载。
(3)代码中是否有超过5个连续join或多层嵌套for循环等不合理的代码逻辑,代码解析与相关对象序列化都是在driver端进行,过于冗余复杂不拆分的代码会造成driver OOM,可参考第10点优化。
(4)代码中是否广播了过大的表,可以合理设置spark.sql.adaptiveBroadcastJoinThreshold参数(以B为单位,默认10485760即10MB);在业务代码逻辑极复杂、扫描文件数和数据量、task数等极端大(如几十万个)且广播阈值设置的再小也依然OOM,可以设置为-1关闭broadcast join。
(5)查看任务提交参数中--executor-cores与--executor-memory的比例是否至少为1:4,一个executor上的所有core共用配置的executor内存,如果有类似2core4G等情况存在,在数据量较大的情况下易OOM,至少应是1core4G或者2core8G等。
(6)个别executor的OOM也是数据倾斜会出现的现象之一,如果是这种情况可参考第11点解决。
(7)在代码逻辑和参数合理的前提下,最后一步才是适度增加资源,例如--executor-memory=8g、--driver-memory=4g等。
13. Caused by: Java.lang.ClassCastException:org.apache.hadoop.io.IntWritable cannot be cast to org.apache.hadoop.io.DoubleWritable
原因:下游Hive表在select from上游Hive表时,select的同名字段的类型不同。
解决方法:修改该下游Hive表的对应字段类型与上游表一致,alter table xxx change 原字段名 新字段名(可不变) 类型;
14. driver端频繁出现“Full GC”字样或“connection refused”等日志内容。
原因:与第12点OOM类似,driver端此时内存压力很大,无力处理与executor的网络心跳连接等其他工作。
解决方法:(1)查看是否有过于复杂不拆分不够优化的代码逻辑(如过多连续join),可参考第10点将不合理的代码拆分精简,在临时表中尽早过滤多余数据。
(2)如果数据量确实十分巨大,并非代码不够合理的原因,可以减小SparkSQL的broadcast join小表阈值甚至禁用该功能,增加参数set spark.sql.autoBroadcastJoinThreshold=2048000或-1等(默认为10M,根据具体数据量调整)。
(3)由于driver也负责application对应的spark ui网页状态维护,小文件过多会造成task数较多,在维护job执行进度时也会内存压力较大,可通过该博客来判断小文件现象:https://blog.csdn.net/qq_33588730/article/details/109353336
(4)改过代码也合理调参过了,最后才是增加driver端内存,--driver-memory=4g等。
15. Caused by: org.apache.spark.SparkException: This RDD lacks a SparkContext. It could happen in the following cases:(1) RDD transformations and actions are NOT invoked by the driver, but inside of other transformations; for example, rdd1.map(x => rdd2.values.count() * x) is invalid because the values transformation and count action cannot be performed inside of the rdd1.map transformation. For more information, see SPARK-5063.(2) When a Spark Streaming job recovers from checkpoint, this exception will be hit if a reference to an RDD not defined by the streaming job is used in DStream operations. For more information, See SPARK-13758.
原因:根据上面英文提示的原因,对RDD的transformation中嵌套transformation或action操作会导致计算失败。
解决方法:从报错那一行附近找到嵌套的transformation或action操作,将该嵌套逻辑独立出来。
16. removing executor 38 because it has been idle for 60 seconds
原因:一般为数据倾斜导致,开启AE特性后空闲下来的executor会被回收。
解决方法:与第11与第12点的解决方法类似,第10、11、12、16、17点的日志现象可能会有某几种同时出现。
17. Container killed by YARN for exceeding memory limits. 12.4 GB of 11GB physical memory used.
原因:(1)数据倾斜,个别executor内存占用非常大超出限制。
(2)任务小文件过多,且数据量较大,导致executor内存用光。
(3)任务参数设置不合理,executor数量太少导致压力负载集中在较少的executor上。
(4)代码不合理,有repartition(1)等代码逻辑。
解决方法:(1)数据倾斜情况可以参考第11、12点。
(2)数据量很大可参考第10、14点。
(3)查看是否任务参数设置不合理,例如executor-memory是设的大,但是--num-executors设置的很少才几十个,可以根据集群情况和业务量大小合理增大executor数,数量判断标准是一个executor的CPU core同一时刻尽量只处理一个HDFS block的数据(如128或256M),在没有设置--executor-cores等参数的情况下,默认一个executor包含一个CPU core。
(4)查看代码中是否有如repartition(1)等明显不合理的逻辑。
(5)在代码性能与逻辑合理,且参数合理的前提下再增加资源,可增加对外内存:--conf spark.yarn.executor.memoryOverhead=4096(单位为M,根据业务量情况具体设置)。
18. Found unrecoverable error returned Bad Request - failed to parse; Bailing out
原因:ES中有历史索引没删除。
解决方法:删除ES中的对应历史索引。
19. org.apache.spark.shuffle.FetchFailedException: Too large frame
原因:shuffle中executor拉取某分区时数据量超出了限制。
解决方法:(1)根据业务情况,判断是否多余数据量没有在临时表中提前被过滤掉,依然参与后续不必要的计算处理。
(2)判断是否有数据倾斜情况,如果是则参考第11、12点,或者通过repartition()进行合理重分区,避免某个分区内数据量过大。
(3)判断--num-executors即executor数量是否过少,可以合理增加并发度,使数据负载不集中于少量executor上,减轻压力。
20. 读写Hive表时报“Table or view not found”,但实际上Hive表在元数据库与HDFS上都存在。
解决方法:排除不是集群连接地址配置等原因后,查看代码中SparkSession建立时是否有加enableHiveSupport(),没加可能会无法识别到Hive表。
21. java.io.FileNotFoundException
原因:(1)除文件确实在对应HDFS路径上不存在以外,可能代码中前面有create view但数据来源于最后要insert的目标表,后面insert overwrite 目标表时又from这个view,因为Spark有“谓词下推”等懒执行机制,实际开始执行create view的transformation操作时,因为前面insert overwrite目标表删了目标表上的文件,所以相当于自己查询自己并写入自己,会造成要读的文件不存在。
(2)由于Spark的内存缓存机制,短时间内该目录下文件有变动但缓存中的元信息未及时同步,依然以为有该文件,Spark会优先读取缓存中的文件元信息,如果和实际该目录下的文件情况不一致也会报错。
解决方法:(1)如果是上述的代码逻辑,可以不用create view,而是创建临时表落到磁盘,insert目标表时from临时表就可以了。
(2)可以在读写代码前面加上refresh table 库名.表名,这样就丢弃了该缓存信息,依然从磁盘实际文件情况来读。
22. org.apache.shuffle.FetchFailedException: Connect from xxx closed
原因:一般是数据倾斜导致,其他executor工作完成因闲置被回收,个别负载大的executor拉其他executor数据时拉不到。
解决方法:可参考第11点,加上参数,set spark.sql.adaptive.join.enabled=true和set spark.sql.adaptive.enabled=true,并根据业务数据量合理设置spark.sql.adaptiveBroadcastJoinThreshold即broadcast join的小表大小阈值。
23. caused by:org.apache.hadoop.hbase.client.RetriesExhaustedException: Can't get the locations
原因:如果地址配置等都正确,一般就是大数据平台对HBase组件的连接并发数有限制,导致大量SparkSQL任务连接HBase时有部分任务会连接超时。
解决方法:检查代码与任务中的HBase连接配置等属性是否正确,若正确则直接请教负责HBase组件的平台开发人员。
24. sparksql在某个stage长时间跑不动,但task很少,数据量也不大,且代码逻辑只是简单的join,如下现象所示:

原因:点进该stage的链接查看细节现象,发现stage中各task的shuffle read数据量不大,但shuffle spill数据量大得多,如下所示:
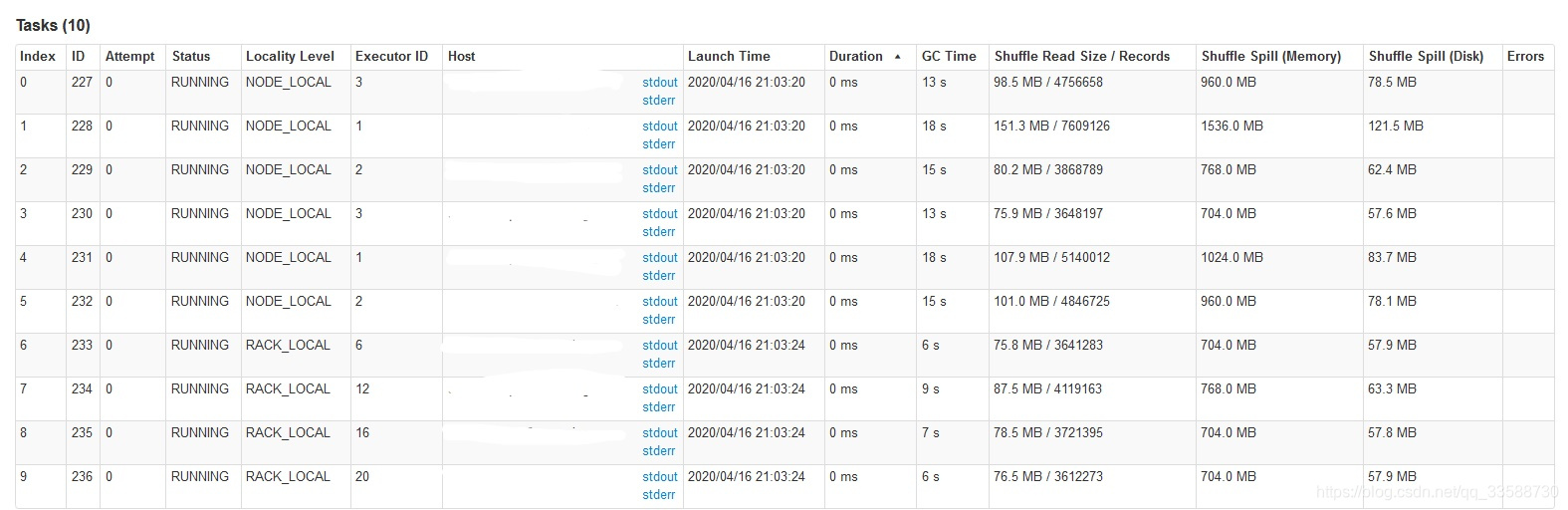
可以判定该join操作可能发生了笛卡尔积,join on中的两个字段各自都有很多重复值不唯一,会导致这种情况。
解决方法:加上参数,set spark.sql.adaptive.shuffle.targetPostShuffleInputSize=64000000能够缓解这种现象,根本上依然是根据业务逻辑进行字段值去重、避免重复字段值参与join等。
25. ERROR:Recoverable Zookeeper: Zookeeper exists failed after 4 attempts baseZNode=/hbase Unable to set watcher on znode (/hbase/...)
原因:Spark任务连接不上HBase,如果不是任务中连接参数和属性等配置的有问题,就是HBase组件限制了连接并发数。
解决方法:可参考第23点的解决方法。
26. Parquet record is malformed: empty fields are illegal, the field should be ommited completely instead
原因:数据中有Map或Array数组,其中有key为null的元素。
解决方法:增加处理key为null数据的逻辑(如将key转换为随机数或干脆丢弃该条数据),或使用ORC格式。
27. Java.io.IOException: Could not read footer for file
原因:该报错分为两种情况:(1)虽然建表时,该hive表元信息设置的是parquet格式,但是实际写入后,对应目录里面的文件并不是parquet格式的;
(2)读到的这个文件是个空文件。
解决方法:(1)如果对应文件在HDFS上查看后发现不是parquet格式,可以重建对应格式的表并把文件移到新表对应目录下,或者正确修改代码配置重跑一次任务,从而删除文件覆盖写入;
(2)如果是空文件,可以直接删掉该文件。
28. com.mysql.jdbc.exceptions.jdbc4.CommunicationsException:Communications link failure
原因:查看报该错误的executor日志上发现有Full GC,Full GC会导致所有其他线程暂停,包括维持MySQL连接的线程,而MySQL在一段时间连接无响应后会关闭连接,造成连接失败。
解决方法:可参考第14点方法解决。
29. java.util.concurrent.TimeoutException: Futures timed out after [300 seconds]
原因:数据量比较大,但是各executor负载压力比较大,出现彼此通信超时的状况,有时候也会伴随“Executor heartbeat timed out after xxx ms”的内容。
解决方法:(1)检查是否有数据倾斜情况,或者是否设置的并发度参数过小,可以根据具体业务量适当增大spark.default.parallelism与spark.sql.shuffle.partitions参数,两者的值设置为一样。
(2)查看报错位置的堆栈信息,如果有下图所示的broadcast join调用:
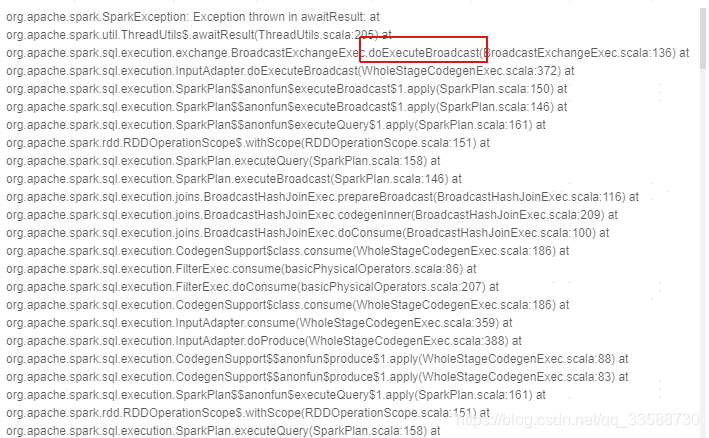
可以将spark.sql.autoBroadcastJoinThreshold参数设置的更小(数值以B为单位),或者关闭设为-1。
(3)经过代码优化和前面参数的调整,依然效果不佳,还可以尝试适当增大spark.network.timeout参数如600s,但不宜过大。
30. Error communicating with MapOutputTracker
原因:目前遇到的情况是NameNode主备切换导致的短时间服务不可用
解决方法:检查是否HDFS的NM正在主备切换状态,切换好后再次重跑任务即可。
31. org.apache.spark.shuffle.FetchFailedException: Connection from xxx closed
原因:数据量较大,过多block fetch操作导致shuffle server挂掉,还会伴随stage中task的失败和重试,对应task的executor上还会有如下的报错内容:“ ERROR shuffle-client-7-2 OneForOneBlockFetcher: Failed while starting block fetches”,或者“Unable to create executor due to Unable to register with external shuffle server due to : java.util.concurrent.TimeoutException: Timeout waiting for task.”。
解决方法:加上--conf spark.reducer.maxReqsInFlight=10和--conf spark.reducer.maxBlocksInFlightPerAddress=10参数(具体数值根据集群情况和业务量判断),来限制block fetch并发数。或者合入Spark3中的remote shuffle service源码特性。
32. Error in query: org.apache.hadoop.hive.ql.metadata.Table.ValidationFailureSemanticException:Partition spec {statis_date=,STATIS_DATE=xxx} contains non-partition column
原因:SparkSQL会把大写SQL语句变为小写,如果用hive建表时分区字段为大写,Spark读大写分区字段名后会报错。
解决方法:将hive表分区字段名改为小写,或者修改spark源码逻辑(AstBuilder.scala),自动将读到的大写分区字段名转为小写再处理。
33.Error: Could not find or load main class org.apache.spark.deploy.yarn.ApplicationMaster
原因:HDFS上未传Spark对应版本的包,Spark程序在客户端机器(安装有spark完整目录)上提交到集群后,集群计算机器上是没有装各计算组件的,而是从HDFS上下载该application需要的Spark jar包后再开始跑,如果HDFS上没有该spark目录,就会因未下到需要的jar包而报错。
解决方法:用hadoop fs -put命令将对应版本的Spark目录上传到HDFS上对应父目录下。
34.ERROR Driver ApplicationMaster: User class threw exception: org.apache.spark.sql.catalyst.analysis.NoSuchDatabaseException: Database 'xxx' not found
原因:有两种情况:(1)建立SparkSession对象时没有加.enableHiveSupport();
(2)Spark2开始用SparkSession封装代替SparkContext作为Application程序的入口,只允许初始化一个SparkSession对象然后用sparkSession.sparkContext来获取SparkContext,如果没有初始化SparkSession对象,也只能初始化一个SparkContext对象。这里可能是重复初始化创建了多个SparkContext。
解决方法:(1)在SparkSession对象初始化位置的.getOrCreate()之前加上.enableHiveSupport()。
(2)删除代码中其他SparkContext初始化语句,只通过sparkSession.sparkContext来获取SparkContext。
35.Caused by: java.lang.RuntimeException: Unsupported data type NullType.
原因:使用Parquet格式读写数据时,如果表中某一列的字段值全为null,用create table xxx using parquet as select ...语句建表时,全为null的那一列会被识别为void类型,就会报错,可以参考该链接:https://stackoverflow.com/questions/40194578/getting-java-lang-runtimeexception-unsupported-data-type-nulltype-when-turning。
解决方法:尽量避免一列全为null值,比如代码中加入空值检测逻辑,赋予随机值;如果业务上要求就是要这一列全为null,可以建表时使用using orc as或stored as orc as语句。
36.Failed to create local dir in /xxxx
原因:一般是磁盘满了或者磁盘损坏。
解决方法:联系运维处理。
37.Java.lang.IllegalArgumentException:…wholeTextFiles…CharBuffer.allocation…
原因:wholeTextFile不支持一次性读入大于1G的大文件,因为是将整个文件内容变成一个Text对象,而Text对象有长度限制。
解决方法:将单个大文件分割成多个小文件读取。
38.Total size of serialized results of 2000 tasks (2048MB) is bigger than spark.maxResultSize(1024.0 MB)
原因:各Executor上的各task返回给driver的数据量超过了默认限制。
解决方法:适当增大参数spark.driver.maxResultSize,且该参数要小于--driver-memory的值。
39.Caused by: java.util.concurrent.ExecutionException: java.lang.IndexOutOfBoundsException: Index: 0
原因:查询的Hive表中对应分区或HDFS目录下有空文件。
解决方法:加上参数set spark.sql.hive.convertMetastoreOrc=true;。
40.Caused by:java.io.NotSerializableException:org.apache.kafka.clients.producer.KafkaProducer
原因:KafkaProducer对象的初始化代码是在driver端执行的,driver会将相关代码对象序列化后发送给各executor,而KafkaProducer对象不支持序列化。
解决方法:将该对象的初始化代码从通过driver初始化的位置移到让executor初始化的位置,例如如果用了foreachPartition(),就可以将KafkaProducer对象的初始化代码移动到该函数内部,可参考该链接:https://stackoverflow.com/questions/40501046/spark-kafka-producer-serializable
41.Hive表某些列的数据错位、字段值显示异常或数据量不对,但SQL中select字段顺序正确且语法无问题
原因:使用HQL或SparkSQL建表时,使用的是create table xxx as select xxx语法而未加建表格式,默认会按读写性能和压缩效率最低的Text格式来建表,可能会因数据本身的部分字段值中包含与Text表的行或列分隔符相同的内容(如逗号等),导致行或列分隔符误判,从而出现列字段值错位显示异常的现象。
解决方法:建hive表时可使用ORC格式,该格式有编码机制防止内容像Text那样因分隔符等原因错位,同时压缩效率比Text、RCFile高,读写性能也更好:create table xxx stored as orc as select xxx
42.java.lang.IllegalArgumentException: Can't zip RDDs with unequal numbers of partitions
原因:(1)代码中使用了zip()等函数,该函数的要求之一是两个RDD的partition个数相同,不相同时会报错。
(2)使用了参数spark.sql.join.preferSortMergeJoin=false开启了Shuffled Hash Join,该种join会先计算各字段值的哈希值并分发到各partition中,如果两个join的表中的数据量有较大差异,导致各字段值哈希计算后生成的partition数不同,也会报错。
解决方法:(1)根据具体业务逻辑和数据情况,选择repartition()等其他函数实现对应逻辑,或对数据本身进行针对性的分区处理。
(2)去掉spark.sql.join.preferSortMergeJoin=false这个参数,依然使用SortMergeJoin。
43.org.apache.hadoop.hive.ql.parse.SemanticException: No partition predicate found for table
原因:对分区表的查询没有指定分区。
解决方法:select语句后面加上where筛选条件,指定要扫描的分区。
44.java.io.InvalidClassException: org.apache.spark.sql.execution.exchange.ShuffleExchangeExec$; local class incompatible: stream classdesc serialVersionUID = -1370062776194295619, local class serialVersionUID = -1798326439004742901
原因:Spark客户端机器本地的jar包与HDFS上的同名jar包实际上不是同一个。
解决方法:排查Spark客户端与HDFS上的同名jar包情况(如时间、md5值等),换成同一版本的。
45.org.apache.orc.FileFormatException: Malformed ORC file
原因:hive表建表时指定了采用ORC格式,而对应HDFS目录下的文件内容并非ORC,可能并非用正常MR或Spark任务跑出,而是其他格式文件直接导入到表HDFS目录下的。
解决方法:使用Hive或Spark引擎正常刷入ORC格式的数据到对应HDFS目录中。