日语多语言模型识别和EasyOCR的对比
本文将对比两个流行的OCR工具——PaddleOCR 和 EasyOCR 的性能,重点测试它们在日语(多语言)场景下的识别效果,结合街景图片和商品图片进行对比评估。
EasyOCR简介
- 官网地址: EasyOCR
- GitHub项目仓库: EasyOCR
- HuggingFace在线测试地址: EasyOCR HuggingFace
我们首先通过 HuggingFace 在线测试 EasyOCR 的识别准确率,并使用一张日语街景图片进行测试。
HuggingFace测试效果
使用以下街景图片进行测试:

EasyOCR 的识别结果如下:
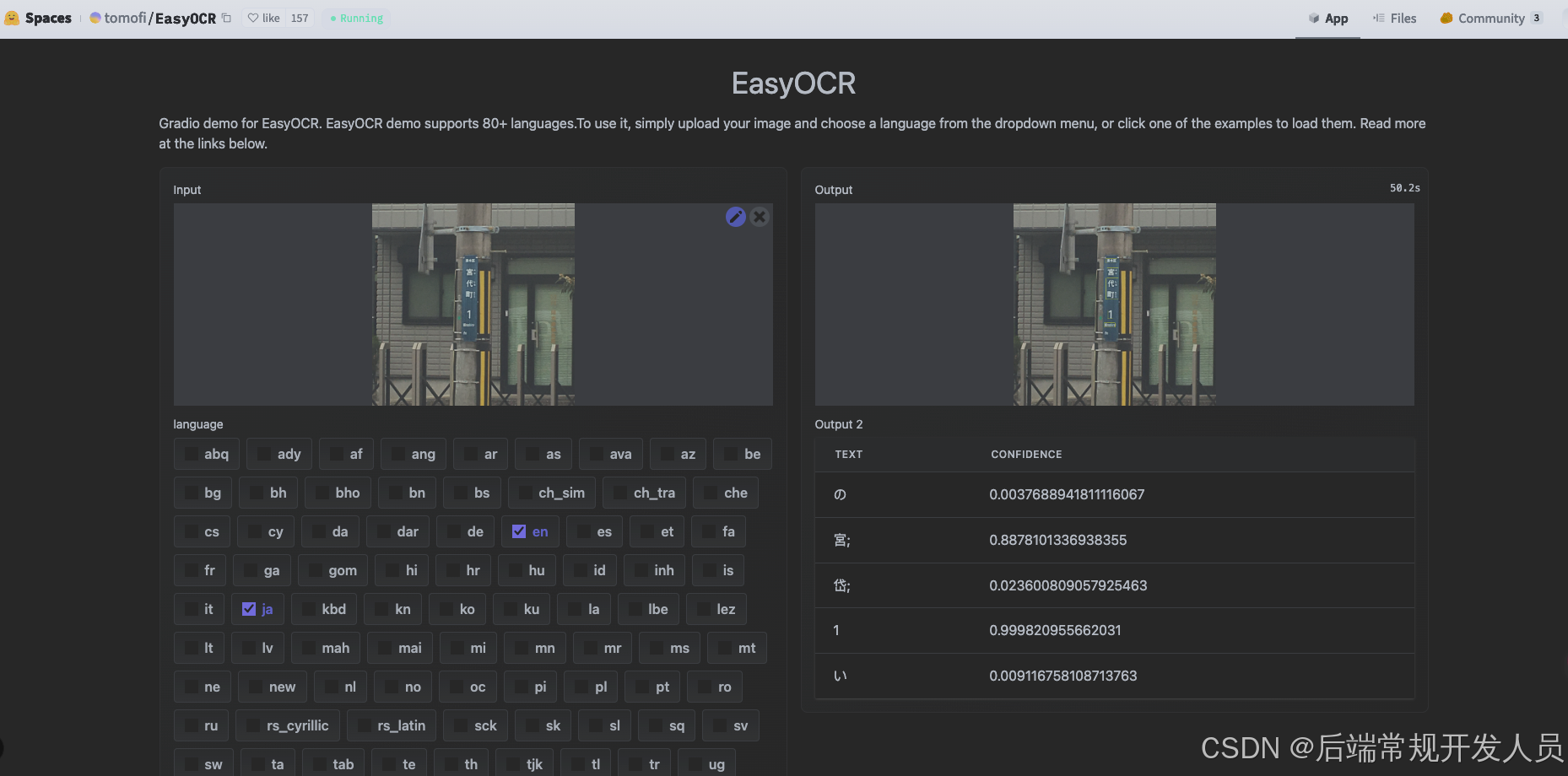
测试发现,EasyOCR的识别准确率不高。接下来,我们将在本地搭建环境以进一步测试其性能。
1. EasyOCR本地运行环境配置
我们通过 Docker 快速搭建 EasyOCR 运行环境。
1.1 Dockerfile 配置
以下为官方推荐的 Dockerfile 文件内容:
FROM docker.io/pytorch/pytorch
# if you forked EasyOCR, you can pass in your own GitHub username to use your fork
# i.e. gh_username=myname
ARG gh_username=JaidedAI
ARG service_home="/home/EasyOCR"
# Configure apt and install packages
RUN apt-get update -y && \
apt-get install -y \
libglib2.0-0 \
libsm6 \
libxext6 \
libxrender-dev \
libgl1-mesa-dev \
git \
# cleanup
&& apt-get autoremove -y \
&& apt-get clean -y \
&& rm -rf /var/lib/apt/lists
# Clone EasyOCR repo
RUN mkdir "$service_home" \
&& git clone "https://github.com/$gh_username/EasyOCR.git" "$service_home" \
&& cd "$service_home" \
&& git remote add upstream "https://github.com/JaidedAI/EasyOCR.git" \
&& git pull upstream master
# Build
RUN cd "$service_home" \
&& python setup.py build_ext --inplace -j 4 \
&& python -m pip install -e .
CMD ["tail", "-f", "/dev/null"]
1.2 Docker-Compose配置
services:
easyocr:
container_name: easyocr
shm_size: 1g
build:
context: .
dockerfile: ./Dockerfile
volumes:
- .:/app
networks:
- my_network
networks:
my_network:
external: true
1.3 Makefile配置
dev-build:
docker-compose build
dev-up: dev-build
docker-compose up -d
dev-shell: dev-up
docker-compose exec easyocr bash
1.4 构建命令
通过以下命令快速构建和运行容器:
make dev-shell
2. PaddleOCR的多语言模型配置
2.1 下载模型与相关资源:
PaddleOCR官方模型列表:https://paddlepaddle.github.io/PaddleOCR/latest/ppocr/model_list.html
以下为本文用到的模型及其下载地址:
- 多语言检测模型:ml/multilingual_ppocr_v3.0_det
下载链接 - 日语识别模型:japan_pporc_server_v4_rec
下载链接 - 文本方向分类模型:ch_ppocr_mobile_v2.0_cls
下载链接 - 日语语言字典:japan_dict
下载链接 - 日语字体:japan.ttc
下载链接
模型转换:
# 检测模型转换
paddle2onnx --model_dir ./Multilingual_PP-OCRv3_det_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file ./Multilingual_PP-OCRv3_det.onnx \
--opset_version 14 --enable_onnx_checker True
# 识别模型转换
paddle2onnx --model_dir ./japan_PP-OCRv4_rec_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file ./japan_PP-OCRv4_rec.onnx \
--opset_version 14 --enable_onnx_checker True
# 方向分类模型转换
paddle2onnx --model_dir ./ch_ppocr_mobile_v2.0_cls_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file ./ch_ppocr_mobile_v2.0_cls.onnx \
--opset_version 14 --enable_onnx_checker True
2.2 PaddleOCR相关版本配置:
分别下载和解压以上资源文件,然后根据之前的文章分别配置PaddleOCR日语模型版本和ONNX模型推理版本:
- PaddleOCR日语模型版本 配置
最好用的图文识别OCR – PaddleOCR(1) 快速集成 - ONNX模型推理版本 配置
最好用的图文识别OCR – PaddleOCR(2) 提高推理效率(PPOCR模型转ONNX模型进行推理)
3. EasyOCR与PaddleOCR对比测试
我们将对以下三个版本进行详细测试:
- EasyOCR 版本
- PaddleOCR 多语言版本
- PaddleOCR ONNX模型版本
场景一:街景图片
测试街景图片





测试代码和结果
EasyOCR 识别代码和结果
-
识别代码:
import easyocr import cv2 import time time1 = time.time() reader = easyocr.Reader(['ja','en'],gpu=False) img_num_list = ['06062','06063','06764','06829','06982'] for i in img_num_list: img_name = f'./test/tr_img_{str(i)}.jpg' img = cv2.imread(img_name) result = reader.readtext(img_name) print(f"---------------- 结果{str(i)} ---------------------") for res in result: print(res[1],res[2]) time_count = time.time() - time1 print(f'------------------------ 总花费时间: {time_count} 秒----------------------') -
识别结果和所用时间:



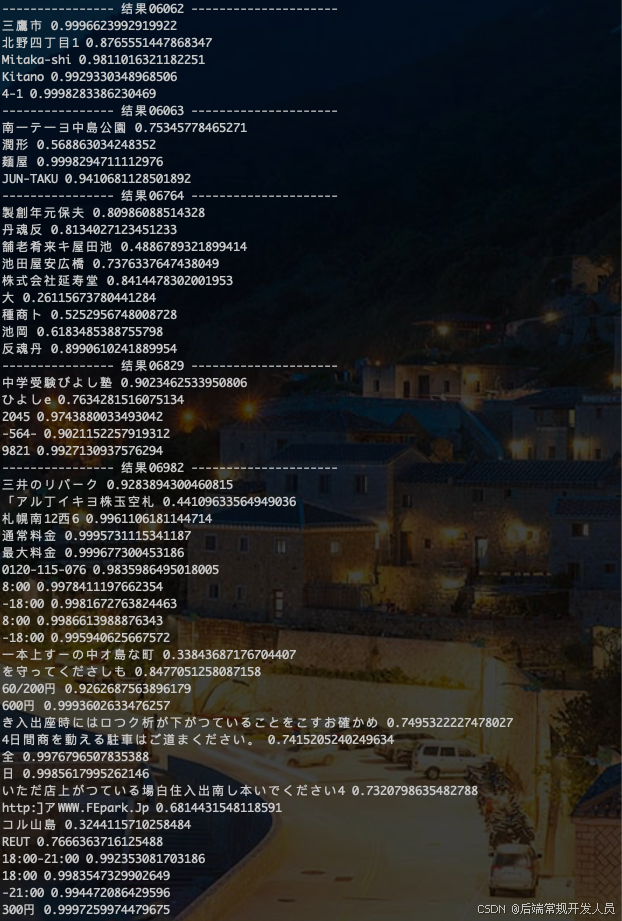
PaddleOCR多语言版本 识别代码和结果
-
识别代码:
from paddleocr import PaddleOCR, draw_ocr import time import cv2 from pathlib import Path def resize_image(image_path, scale=0.5, max_size=960, border=False): # 读取图片 img = cv2.imread(image_path) if img is None: raise FileNotFoundError(f"图片 {image_path} 不存在!") # 获取原始宽高 original_height, original_width = img.shape[:2] # print(f"原始宽高: {original_width}x{original_height}") # 首先将宽高缩小 new_width = int(original_width * scale) new_height = int(original_height * scale) # 如果缩放后仍有一边大于 max_size,则进行二次等比缩放 if max(new_width, new_height) > max_size: if new_width > new_height: # 宽度是最大边 scale = max_size / new_width else: # 高度是最大边 scale = max_size / new_height new_width = int(new_width * scale) new_height = int(new_height * scale) # print(f"调整后的宽高: {new_width}x{new_height},倍数是:{scale}") # 调整图片大小 # resized_img = cv2.resize(img, None, fx=scale, fy=scale, interpolation=cv2.INTER_AREA) resized_img = cv2.resize(img, (new_width, new_height), interpolation=cv2.INTER_AREA) if border and min(new_width, new_height) < max_size : # 填充到固定尺寸 top = (max_size - new_height) // 2 bottom = max_size - new_height - top left = (max_size - new_width) // 2 right = max_size - new_width - left resized_img = cv2.copyMakeBorder( resized_img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=[0, 0, 0] ) return resized_img module_dir = Path(__file__).resolve().parent.parent time1 = time.time() ocr = PaddleOCR( use_angle_cls=True, lang="japan", drop_score=0.2, ocr_version='PP-OCRv4', show_log=False, det_limit_side_len=2450 ) # 可通过参数控制单独执行识别、检测 # result = ocr.ocr(img_path, det=False) 只执行识别 # result = ocr.ocr(img_path, rec=False) 只执行检测 img_num_list = ['06062','06063','06764','06829','06982'] for i in img_num_list: img_path = f"../tb-img/tr_img_{str(i)}.jpg" img = resize_image(img_path, scale=0.35, max_size=2000) result = ocr.ocr(img) print(f"---------------- 结果{str(i)} ---------------------") for res in result[0]: print(res[1][0],res[1][1]) time_count = time.time() - time1 print(f'------------------------ 总花费时间: {time_count} 秒----------------------') -
识别结果和所用时间:

2.1.4 onnx模型 识别代码和结果
-
识别代码:
import cv2 import time from onnxocr.onnx_paddleocr import ONNXPaddleOcr,sav2Img from pathlib import Path import numpy as np def resize_image(image_path, scale=0.5, max_size=960, border=False): # 读取图片 img = cv2.imread(image_path) if img is None: raise FileNotFoundError(f"图片 {image_path} 不存在!") # 获取原始宽高 original_height, original_width = img.shape[:2] # print(f"原始宽高: {original_width}x{original_height}") # 首先将宽高缩小 new_width = int(original_width * scale) new_height = int(original_height * scale) # 如果缩放后仍有一边大于 max_size,则进行二次等比缩放 if max(new_width, new_height) > max_size: if new_width > new_height: # 宽度是最大边 scale = max_size / new_width else: # 高度是最大边 scale = max_size / new_height new_width = int(new_width * scale) new_height = int(new_height * scale) # print(f"调整后的宽高: {new_width}x{new_height},倍数是:{scale}") # 调整图片大小 # resized_img = cv2.resize(img, None, fx=scale, fy=scale, interpolation=cv2.INTER_AREA) resized_img = cv2.resize(img, (new_width, new_height), interpolation=cv2.INTER_AREA) if border == True and (min(new_width, new_height) < max_size) : # 填充到固定尺寸 top = (max_size - new_height) // 2 bottom = max_size - new_height - top left = (max_size - new_width) // 2 right = max_size - new_width - left resized_img = cv2.copyMakeBorder( resized_img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=[0,0,0] ) return resized_img # 获取当前文件所在的目录 module_dir = Path(__file__).resolve().parent japan_model = { "det_model_dir": f'{module_dir}/onnxocr/models/ppocrv4/det/ml/Multilingual_PP-OCRv3_det.onnx', "rec_model_dir": f'{module_dir}/onnxocr/models/ppocrv4/rec/japan/japan_PP-OCRv4_rec.onnx', "cls_model_dir": f'{module_dir}/onnxocr/models/ppocrv4/cls/ch_ppocr_mobile_v2.0_cls.onnx', "rec_char_dict_path": f'{module_dir}/onnxocr/models/ppocrv4/rec_char_dict/japan_dict.txt', "vis_font_path":f'{module_dir}/onnxocr/fonts/japan.ttc' } time1 = time.time() model = ONNXPaddleOcr( use_angle_cls=True, use_gpu=False, det_model_dir=japan_model["det_model_dir"], rec_model_dir=japan_model["rec_model_dir"], cls_model_dir=japan_model["cls_model_dir"], rec_char_dict_path=japan_model["rec_char_dict_path"], vis_font_path=japan_model["vis_font_path"], drop_score=0.1, det_limit_side_len = 2000, det_limit_type = 'max', # show_log=True, ) img_num_list = ['06062','06063','06764','06829','06982'] for i in img_num_list: img = f"../tb-img/tr_img_{str(i)}.jpg" resized_img = resize_image(img, scale=0.35, max_size=960, border=True) result = model.ocr(resized_img) sav2Img(resized_img, result) print(f"---------------- 结果{str(i)} ---------------------") for res in result[0]: print(res[1][0],res[1][1]) time_count = time.time() - time1 print(f'------------------------ 总花费时间: {time_count} 秒----------------------') # sav2Img(resized_img, result) -
识别结果和所用时间:
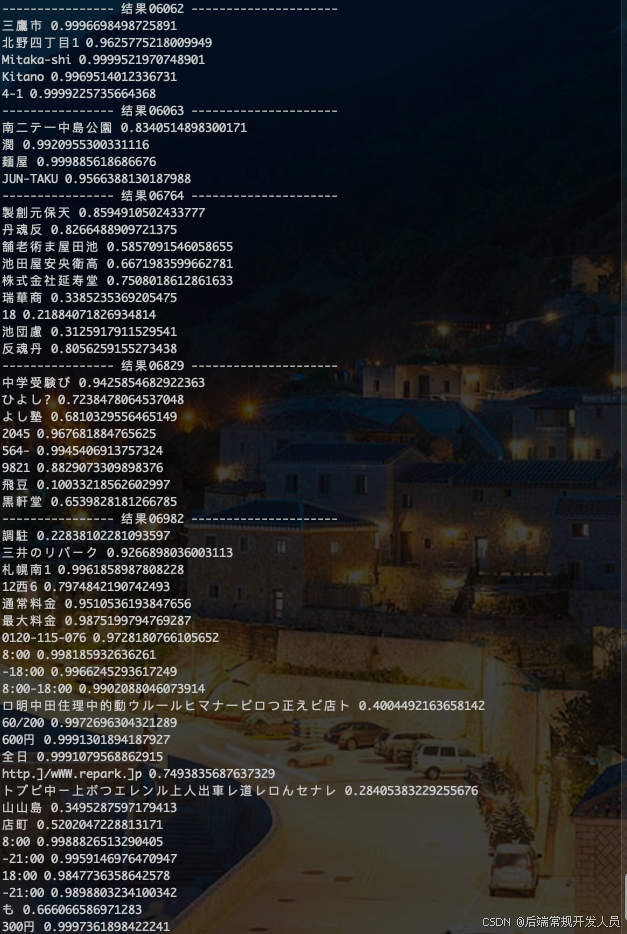

测试结果
| 工具版本 | 准确率 | 平均耗时 | 总耗时 | 效率 |
|---|---|---|---|---|
| EasyOCR | 较低 | 22.86 秒 | 114.32 秒 | 最低 |
| PaddleOCR | 较高 | 4.77 秒 | 23.86 秒 | 较低 |
| ONNX模型 | 较高 | 1.14 秒 | 5.57 秒 | 最高 |
场景二:商品图片
测试商品图片:





EasyOCR 识别代码和结果
-
识别代码:
# 代码同上 -
识别结果和所用时间:

PaddleOCR多语言版本 识别代码和结果
-
识别代码:
# 代码同上 -
识别结果和所用时间:

onnx模型 识别代码和结果
-
识别代码:
# 代码同上 -
识别结果和所用时间:

测试结果
| 工具版本 | 准确率 | 平均耗时 | 总耗时 | 效率 |
|---|---|---|---|---|
| EasyOCR | 较高 | 3.97 秒 | 19.85 秒 | 最低 |
| PaddleOCR | 较低 | 2.61 秒 | 13.07 秒 | 较低 |
| ONNX模型 | 一般 | 1.38 秒 | 6.92 秒 | 最高 |
总结与分析
通过对比可以看出:
- 街景图
- 准确率: PaddleOCR 的多语言模型在日语识别中表现优异,尤其是 ONNX 优化版本具有更高的准确率。
- 运行效率: ONNX 优化模型的推理速度最快。
- 商品图
- 准确率: EasyOCR 的多语言模型在日语识别中表现优异。
- 运行效率: ONNX 优化模型的推理速度最快。
对于需要处理多语言 OCR 的场景,推荐使用 PaddleOCR 进行微调,把微调后的模型转 ONNX 优化模型版本进行推理。