“Flink中流式处理的概念是实时计算的基石,也是你踏入Flink的第一步。”
今天和大家一起聊聊流式处理的通用概念。如果还不清楚这些概念的同学,今天的分享一定会给你带来收获的。关于Flink,之前的《Flink入门安装》可以先看看。
01 Flink 是什么
在讲流式处理的通用概念之前,我们先引用Flink官网的一段话:
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
从中可以看出,Flink是一个框架,用于对无界或有界数据流进行有状态计算的分布式处理引擎。
我们来一点点分析,这其中涉及到的概念。
02 无界或有界数据流
什么是无界数据流?什么又是有界数据流?
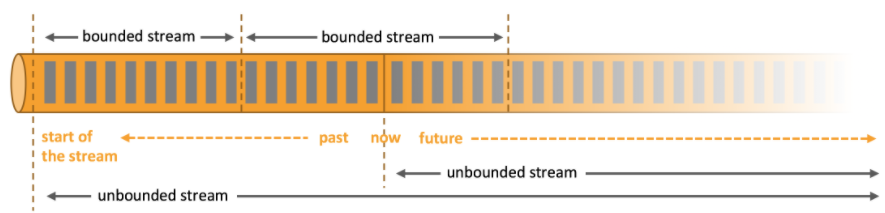
在Flink的世界观中,一切都是流组成的。
- 离线数据是有界数据流(bounded stream)
- 实时数据是无界数据流(unbounded stream)
让我们来看一下它们的特点及区别。
有界流 Vs. 无界流
有界流:
- 明确定义了开始和结束
- 在执行计算前,获取所有数据
- 有界数据流不需要有序获取,因为可以在处理时进行排序
无界流:
- 定义了开始,没有定义结束,无界流不会终止并提供数据。
- 无界流必须持续处理,事件在获取之后必须立刻处理
- 无法等待所有数据到达
- 无界流通常要求顺序处理事件,以保证数据的完整性
03 Stateful Computations(有状态计算)
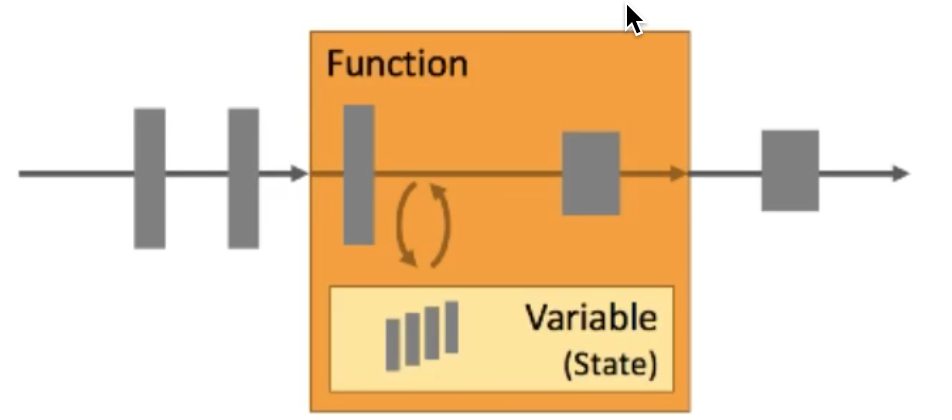
Flink是对数据进行有状态的计算,状态是Flink实现容错和精确一次消费的基础,可以理解为存储了数据位置信息和算子信息的结构体,即数据消费到了什么位置,进行了哪些算子计算,得到了什么结果,是一个累积状态。
在上图中,**Variable(State)**就是我们的状态。
Flink状态可以存储在内存或磁盘,即本地状态,减少了与网络IO消耗,提高了处理效率,同时可以将状态定期写入数据库或其他存储,避免因长期作业导致的状态过大消耗大量内存。
当我们写入数据库或其他存储时,就引入了状态后端的概念。
(1)State Backend(状态后端)
当一个实时计算程序一直执行时,其状态会变得很大,可能超出单一节点的内存,这时需要一个状态后端来保存它。
Flink中关于状态后端的具体实现,我会在后续的文章中给出,这里暂不详述。
(2)State Fault Tolerance(状态容错)
让我们来考虑三个问题:
- 如何保证Exactly Once的状态容错?
- 如何在分布式场景下替多个拥有本地状态的算子产生一个全域一致的快照?
- 如何在不中断处理的前提下产生快照?
带着上面的三个问题,我们来看下面的概念:
Checkpoint,检查点,当各个拥有本地状态的算子在做checkpoint时,会将本地状态传输到共享状态的DFS,当任务失败时,会从上一个检查点进行恢复,只有进行了所有算子状态保存的检查点才可用于恢复。
恢复过程:
- 将数据源的消息偏移量调到检查点中的位置
- 重新消费数据
- 根据检查点中保存的状态重新计算
通过Checkpoint,我们解决了问题【1】和问题【2】。我们再来看问题【3】:
Checkpoint Barrier,检查点分界线,用于标记此时进行checkpoint,会随着数据在程序中流动,每个算子检测到barrier就会进行checkpoint,当所有算子都进行了checkpoint时,这一次checkpoint才算完成。
可以理解为,当代码触发了checkpoint时,会从Source的数据流中插入一个特殊的标志,即checkpoint barrier,barrier随着数据流经过代码中的各个算子,每个算子读取到barrier就触发该算子的checkpoint。
这样就实现了,在不中断程序代码的前提下产生一致性快照。
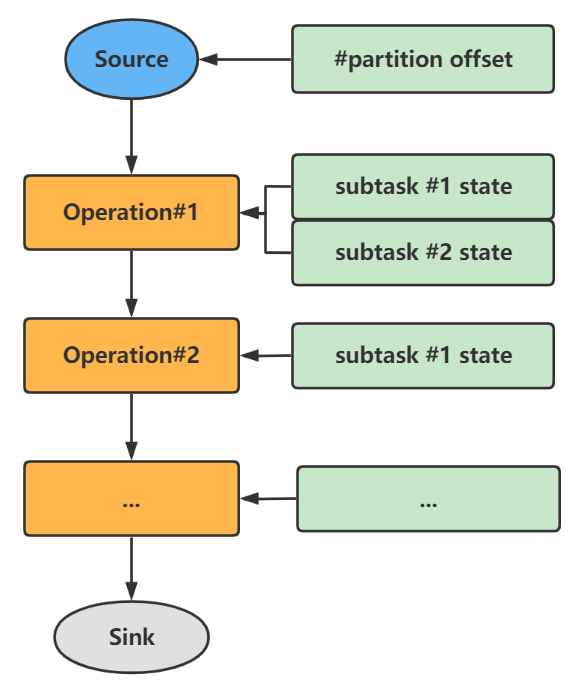
最后给出checkpoint的大致结构:
如下图所示,左侧代表程序的处理流程,右侧代表了每个流程的子任务状态。
checkpoint大致结构:
(3)State Management(状态管理)
我们再来简单看一下状态管理:
Flink使用状态后端来进行状态管理,提供两种状态后端:
- JVM Heap状态后端,本地状态后端,在本地算子进行状态保存时没有什么消耗,但在进行全域状态维护时需要序列化
- RocksDB状态后端,适合长期任务的状态维护,可以保存大状态,代价是每次读取时都要进行序列化和反序列化
(4)Savepoints and Job Migration(状态保存与迁移)
到目前为止,我们解决了状态的管理、容错,那么如何来进行状态的迁移呢?
思考如下场景:
- 更改代码逻辑或修Bug时,如何将前一任务的状态转移到新的任务?
- 如何重新定义运行的并行度?
- 如何升级集群的版本号?
Savepoint,社区翻译为保存点,本质上可以理解为一个手动产生的检查点(checkpoint),记录着流式应用中所有算子的状态
通过如下的步骤,就可以解决上述的场景:
- 在执行任务停止之前,产生一个保存点
- 从保存点恢复新的执行,利用EventTime处理赶上最新的数据
这里提到了EventTime,下面来看一下Flink中的时间语义。
04 Time(时间语义)
在实时处理中,对时间非常关注,业务与时间的关系非常紧密。
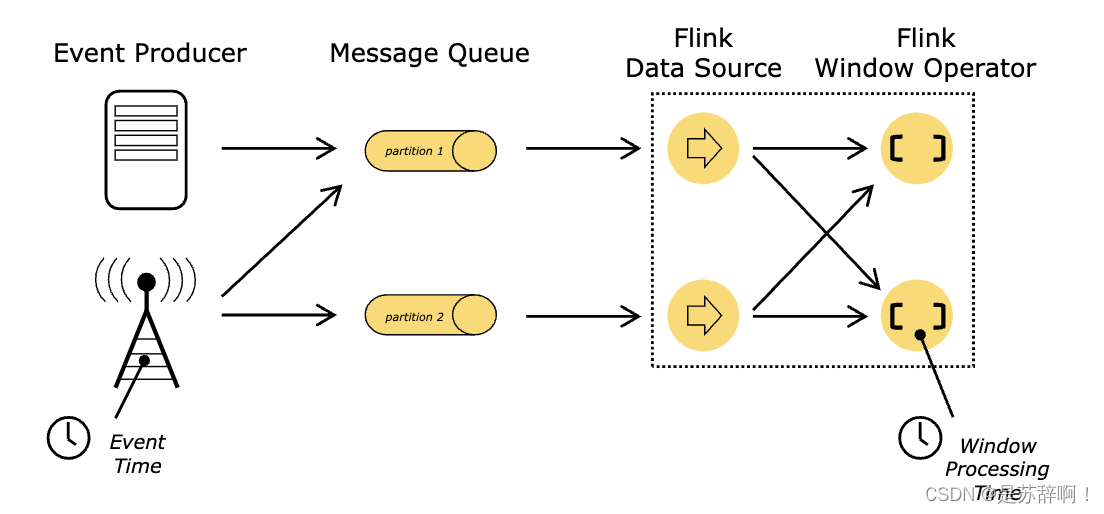
(1)Event Time
事件时间,即数据事件发生的时间,一般跟随数据传输而来,Flink一般使用EventTime进行时间处理。
思考一下,程序何时应该产生结果?即,程序何时判断自己该执行这个算子?
这里我们需要引入另一个概念Watermark。
WaterMarks(水位线)
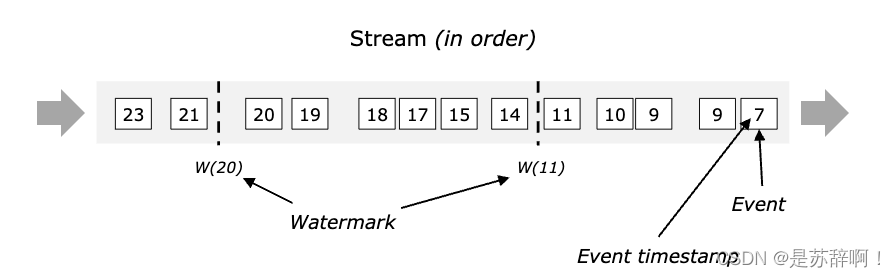
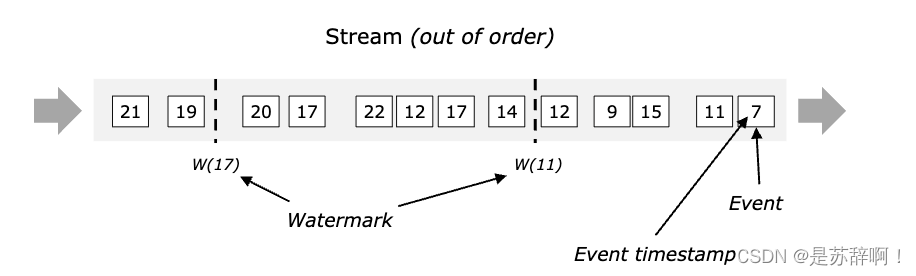
在无界数据流中,数据进入Flink的顺序由于各种原因,可能不会按照事件时间顺序到来,如上图,数据以乱序的顺序进入了Flink,Flink如何保证计算的数据不存在丢失的情况呢?或者说,对于迟到的数据,Flink如何处理呢?
首先,我们在Flink中定义了Watermark:
- WaterMark是Flink中的特殊事件,会随着数据在程序中流动。
- 带有时间戳t的watermark会让算子判定不在接收任何时间戳<t的数据,并触发计算
这样,我们解决了Flink何时触发计算的问题,那么对于迟到数据呢?
Watermark可以理解为一个延迟触发机制,设置watermark的延时时长w,每次系统会校验已经到达的数据中最大的maxEventTime,然后认定eventTime小于maxEventTime-w的所有数据都已到达,如果有窗口的eventTime等于maxEventTime-w,窗口将被触发执行
这样,Flink就能尽量避免丢失迟到数据,具体的watermark使用会在后续的文章中给大家介绍。
(2)Processing Time
处理时间,即程序对数据进行处理的时间,在数据源中不存在时间字段时才会使用。
(3)Ingestion Time
摄入时间,数据进行Flink集群的时间,一般不使用。
04 Window 窗口 & Trigger 触发器
在对Watermark的介绍中,我们提到了窗口的概念,当窗口中有EventTime等于maxEventTime-延迟时长时,窗口将被触发执行。
(1)Window 窗口
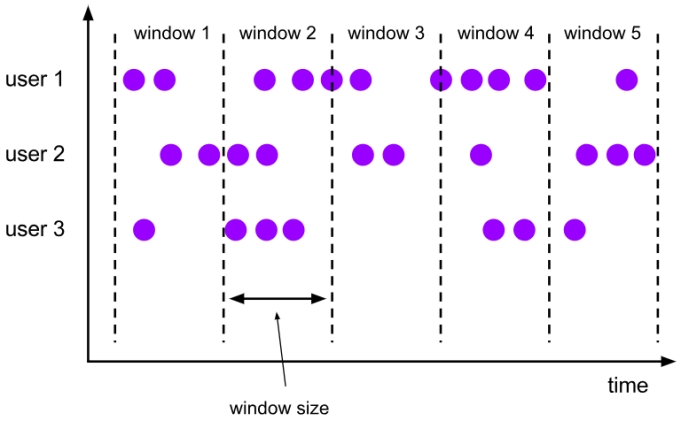
Window是无界数据流处理的核心,将流分成有限大小的“桶”,在桶上进行应用计算。
如下图,数据流被切分为一个个window,针对每个window触发计算,这里只给出窗口的概念,具体的使用参考后续文字。
(2) Trigger 触发器
上面我们知道了Flink需要对数据流进行切分成window,然后对window进行触发计算,那么如何来切分呢?由谁来进行切分呢?
Trigger触发器就是为了解决上述问题,触发器确定窗口(由窗口分配器形成)何时准备好由窗口函数处理。
关于Flink的流式处理概念,我们就分享这些了,希望对大家接触Flink有所帮助。
更多内容,扫码关注公众号:实时数仓 AI
