概述
结构化流是一种基于Spark SQL引擎的可扩展且容错的流处理引擎。他可以像表达静态数据的批处理计算一样表达流式计算。
快速示例
监听本地netcat服务器的输入内容 实时计算每个单词出现的次数在屏幕上打印
可以通过运行下载的Spark目录下的程序直接启动 再另外启动一个netcat服务器 再服务器终端输入内容即可在控制台看见相应的输出
编程模型
结构化流中的关键思想是将实时数据流视为连续追加的表。这使得新的流处理模型非常类似于批处理模型。您将流式计算表示为静态表上的标准批处理查询,Spark将其作为无界输入表上的增量查询运行。
基本概念
将输入数据流视为“输入表”。到达流的每个数据项都像一个新行被附加到输入表。
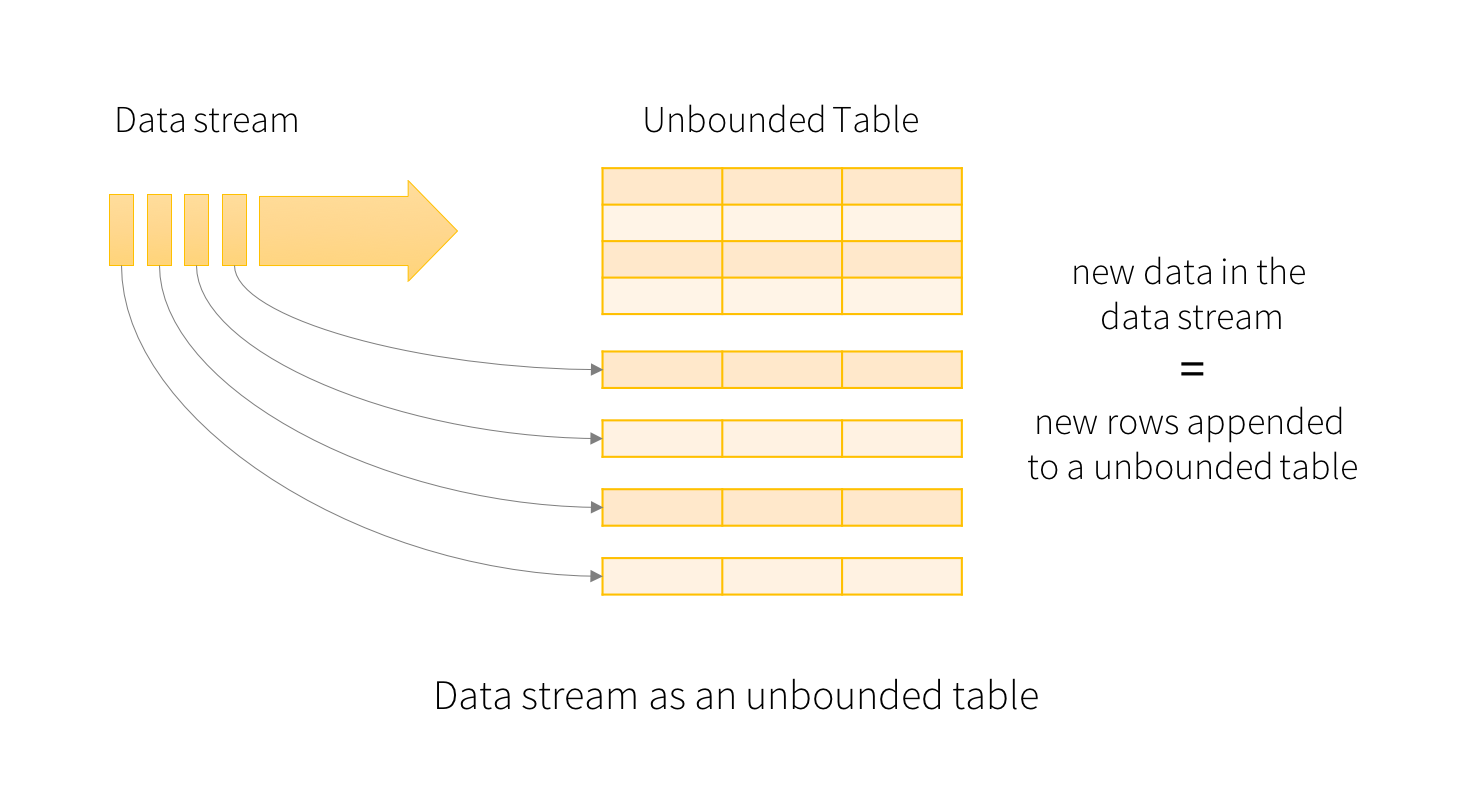
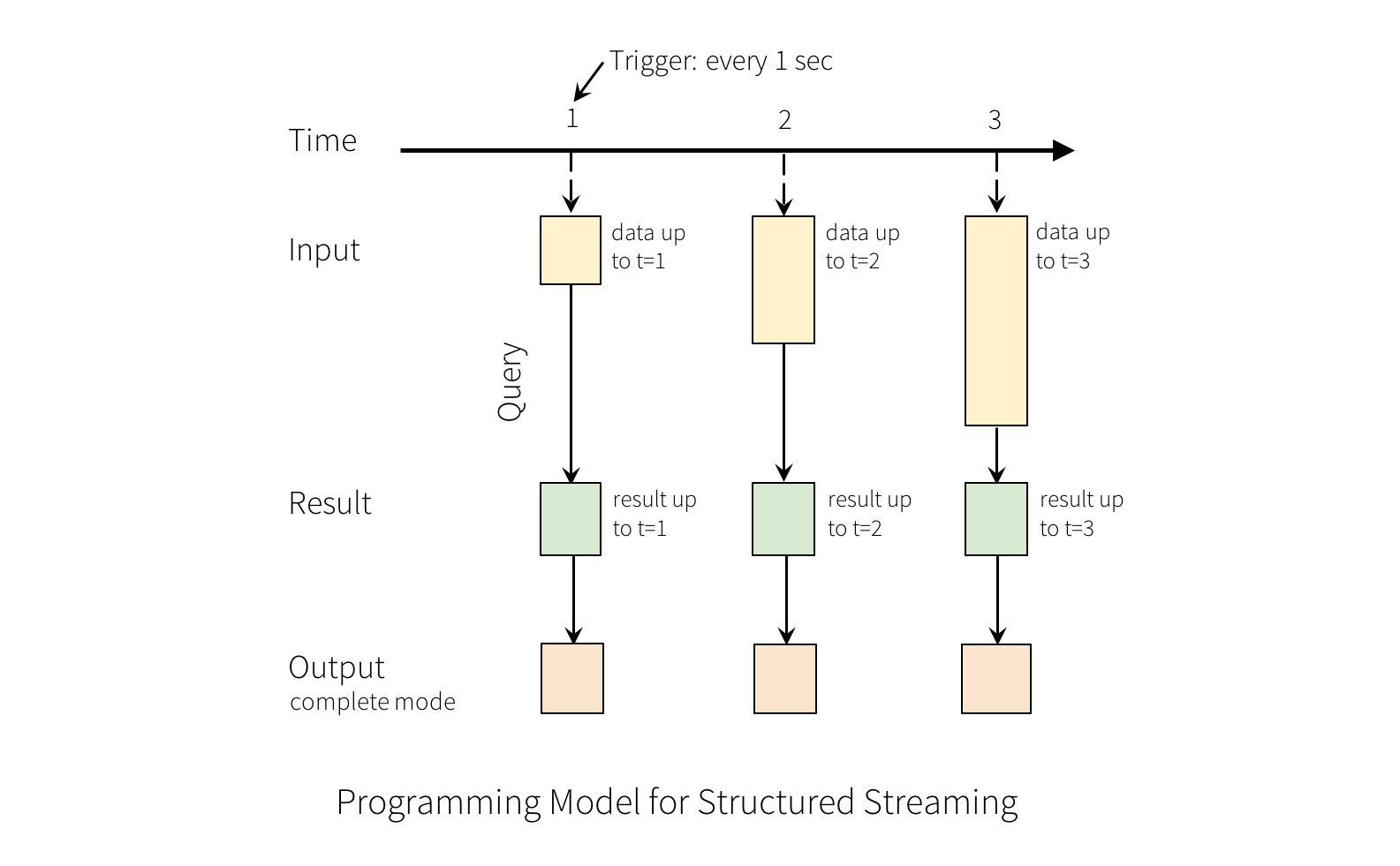
使用数据集和数据资源的API
创建流式DataFrames和流式Datasets
输入源
有一些内置源。
- 文件来源。目录中写入的文件作为数据源
- Kafka来源。从Kafka读取源数据
- 套接字来源
- 速率源
流式 DataFrames/Datasets的操作
基本操作-查询 投影 聚合
case class DeviceData(device: String, deviceType: String, signal: Double, time: DateTime)
val df: DataFrame = ... // streaming DataFrame with IOT device data with schema { device: string, deviceType: string, signal: double, time: string }
val ds: Dataset[DeviceData] = df.as[DeviceData] // streaming Dataset with IOT device data
// Select the devices which have signal more than 10
df.select("device").where("signal > 10") // using untyped APIs
ds.filter(_.signal > 10).map(_.device) // using typed APIs
// Running count of the number of updates for each device type
df.groupBy("deviceType").count() // using untyped API
// Running average signal for each device type
import org.apache.spark.sql.expressions.scalalang.typed
ds.groupByKey(_.deviceType).agg(typed.avg(_.signal)) // using typed API
还可以将流式DataFrame / Dataset注册为临时视图,然后在其上执行SQL命令。
df.createOrReplaceTempView("updates")
spark.sql("select count(*) from updates") // returns another streaming DF
事件时间的窗口操作(Window Operations on Event Time)
计算10分钟内的单词,每5分钟更新一次。也就是说,在10分钟窗口12:00-12:10,12:05-12:15,12:10-12:20等之间收到的单词数量。
import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word"
).count()
处理延迟数据和水印
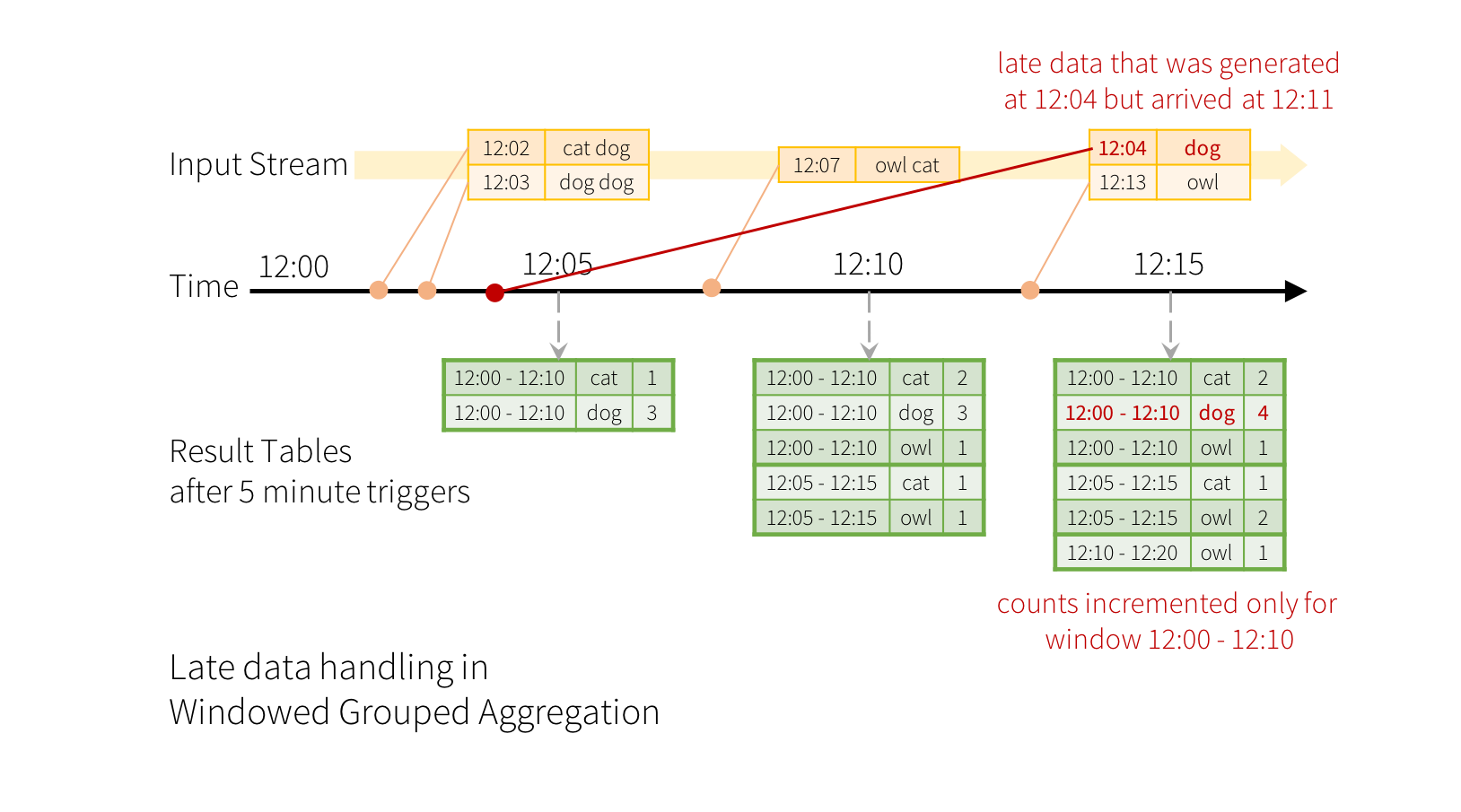
import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words
.withWatermark("timestamp", "10 minutes")
.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word")
.count()
加入操作
流和静态数据连接
自Spark 2.0引入以来,Structured Streaming支持流和静态DataFrame / Dataset之间的连接(内连接和某种类型的外连接)。
val staticDf = spark.read. ...
val streamingDf = spark.readStream. ...
streamingDf.join(staticDf, "type") // inner equi-join with a static DF
streamingDf.join(staticDf, "type", "right_join") // right outer join with a static DF
流和流的连接
在Spark 2.3中,我们添加了对流 - 流连接的支持,也就是说,您可以加入两个流Datasets/DataFrames.。在两个数据流之间生成连接结果的挑战是,在任何时间点,数据集的视图对于连接的两侧都是不完整的,这使得在输入之间找到匹配更加困难。从一个输入流接收的任何行都可以与来自另一个输入流的任何未来的,尚未接收的行匹配。因此,对于两个输入流,我们将过去的输入缓冲为流状态,以便我们可以将每个未来输入与过去的输入相匹配,从而生成连接结果。
流中重复数据的删除
您可以使用事件中的唯一标识符对数据流中的记录进行重复数据删除。
al streamingDf = spark.readStream. ... // columns: guid, eventTime, ...
// Without watermark using guid column
streamingDf.dropDuplicates("guid")
// With watermark using guid and eventTime columns
streamingDf
.withWatermark("eventTime", "10 seconds")
.dropDuplicates("guid", "eventTime")
不支持的操作
流式DataFrames / Datasets不支持一些DataFrame / Dataset操作。其中一些如下。
- 流数据集尚不支持多个流聚合(即流式DF上的聚合链)。
- 流数据集不支持限制和前N行。
- 不支持对流数据集进行不同的操作。
- 仅在聚合和完全输出模式之后,流数据集才支持排序操作。
- 不支持流数据集上的几种外连接类型。
此外,有一些数据集方法不适用于流数据集。它们是立即运行查询并返回结果的操作,这对流式数据集没有意义。相反,这些功能可以通过显式启动流式查询来完成。
-
count() - 无法从流式数据集返回单个计数。而是使用ds.groupBy().count()它返回包含运行计数的流数据集。
-
foreach()- 而是使用ds.writeStream.foreach(…)(见下一节)。
-
show() - 而是使用控制台接收器(参见下一节)。
如果您尝试任何这些操作,您将看到AnalysisException类似“operation XYZ is not supported with streaming DataFrames/Datasets”。虽然其中一些可能在未来的Spark版本中得到支持,但还有一些基本上难以有效地实现流数据。例如,不支持对输入流进行排序,因为它需要跟踪流中接收的所有数据。因此,这基本上难以有效执行。
启动流式查询
一旦定义了最终结果DataFrame / Dataset,必须使用返回的DataStreamWriter Dataset.writeStream()在此接口中指定以下一项或多项:
- 输出下沉的细节:数据格式和位置等。
- 输出模式
- 查询名称:可选地,指定查询的唯一名称以进行标识。
- 触发间隔:可选择指定触发间隔。
- 检查点位置:对于可以保证端到端容错的某些输出接收器,请指定系统写入所有检查点信息的位置。
输出模式
有几种类型的输出模式。
- Append mode (默认):这是默认模式,其中只有自上次触发后添加到结果表的新行将输出到接收器。
- Complete mode: 每次触发后,整个结果表将输出到接收器。
- Update mode:(自Spark 2.1.1起可用)仅将结果表中自上次触发后更新的行输出到接收器。
输出下沉接收器
有几种类型的内置输出接收器。
- File Sink-将输出存储到目录。
`writeStream
.format("parquet") // can be "orc", "json", "csv", etc.
.option("path", "path/to/destination/dir")
.start()`
- Kafka sink - 将输出存储到Kafka中的一个或多个主题。
writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()
- Foreach接收器 - 对输出中的记录运行任意计算。
writeStream
.foreach(...)
.start()
- 控制台接收器(用于调试) - 每次触发时将输出打印到控制台/标准输出。支持Append和Complete输出模式。这应该用于低数据量的调试目的,因为在每次触发后收集整个输出并将其存储在驱动程序的内存中。
writeStream
.format("console")
.start()
- 内存接收器(用于调试) - 输出作为内存表存储在内存中。支持Append和Complete输出模式。这应该用于低数据量的调试目的,因为整个输出被收集并存储在驱动程序的内存中。
writeStream
.format("memory")
.queryName("tableName")
.start()
使用Foreach和ForeachBatch
oreach 允许每行上的自定义写入逻辑,foreachBatch允许在每个微批量的输出上进行任意操作和自定义逻辑。
ForeachBatch
foreachBatch(…)允许您指定在流式查询的每个微批次的输出数据上执行的函数。它需要两个参数:DataFrame或Dataset,它具有微批次的输出数据和微批次的唯一ID。
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
// Transform and write batchDF
}.start()
foreach
如果foreachBatch不是一个选项(例如,相应的批处理数据写入器不存在,或连续处理模式),那么您可以使用表达自定义编写器逻辑foreach。具体来说,可以通过将其划分为三种方法表达数据写入逻辑:open,process,和close。
在Scala中,您必须扩展类ForeachWriter:
streamingDatasetOfString.writeStream.foreach(
new ForeachWriter[String] {
def open(partitionId: Long, version: Long): Boolean = {
// Open connection
}
def process(record: String): Unit = {
// Write string to connection
}
def close(errorOrNull: Throwable): Unit = {
// Close the connection
}
}
).start()