pandas 案例积累(一)—— 基础应用
使用list构造Series
import pandas as pd
courses = ["数学", "语文", "英语", "计算机"]
data = pd.Series(data=courses)
print(data)
运行结果:

使用dict构造Series
import pandas as pd
grades = {"语文":80, "数学":90, "英语":90, "计算机":100}
data = pd.Series(data=grades)
print(data)
运行结果:

通过可迭代对象构造Series
import pandas as pd
data = range(5)
print(type(data))
ser_obj = pd.Series(data, index=['a', 'b', 'c', 'd', 'e'])
print(ser_obj)
运行结果:

通过一维数组构造Series
import numpy as np
import pandas as pd
x = np.arange(10, 60, 10)
y = pd.Series(x)
print(y)
运行结果:

通过标量(常数)构造Series
import pandas as pd
x = 22
y1 = pd.Series(x)
print(y1)
print("-分割-"*4)
y2 = pd.Series(x,index=list(range(5)))
print(y2)
运行结果:

Series转换成List
import pandas as pd
grades = {"语文":80, "数学":90, "英语":90, "计算机":100}
ser_obj = pd.Series(data=grades)
print(ser_obj.tolist())
运行结果:

将Series转换成DataFrame
import pandas as pd
grades = {"语文":80, "数学":90, "英语":90, "计算机":100}
ser_obj = pd.Series(data=grades)
df1 = pd.DataFrame(data=ser_obj, columns=["grade"])
df2 = ser_obj.reset_index()
df2.columns = ["index", "grade"]
print(df1)
print("-分割-"*4)
print(df2)
运行结果:

转换Series的数据类型
import pandas as pd
grades = {"语文":80, "数学":90, "英语":90, "计算机":100}
ser_obj = pd.Series(data=grades, dtype=int)
# 这里的float将被作为一种类型
ser_obj1 = ser_obj.astype(float)
# 这里的str将被作为方法
ser_obj2 = ser_obj.map(str)
print(ser_obj1)
print("-分割-"*4)
print(ser_obj2)
运行结果:

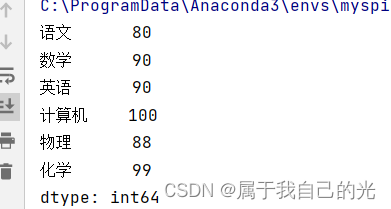
给Series添加新的元素
import pandas as pd
grades = {"语文":80, "数学":90, "英语":90, "计算机":100}
ser_obj = pd.Series(data=grades, dtype=int)
ser_obj = ser_obj.append(pd.Series({
"物理":88,
"化学":99
}))
print(ser_obj)
运行结果:
使用dict创建DataFrame
import pandas as pd
df = pd.DataFrame({
"姓名":["小明", "小王", "小李"],
"年龄":[23, 12, 24],
"性别":["男", "男", "女"]
})
print(df)
# 设置姓名列为索引列
df.set_index("姓名", inplace=True)
print("-分割-"*4)
print(df)
运行结果:

使用Series组成的字典创建DataFrame
d = {
'x':pd.Series([1, 2, 3], index=['a', 'b', 'c'], dtype=float),
'y':pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'], dtype=float)
}
df = pd.DataFrame(data=d)
print(df)
"""
x y
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0
"""
使用字典组成的列表创建DataFrame
list_one = [
{'x':1, 'y':2, 'z':3},
{'x':4, 'y':5}
]
df = pd.DataFrame(data=list_one, index=['a', 'b'])
print(df)
"""
x y z
a 1 2 3.0
b 4 5 NaN
"""
其他创建DataFrame的方法
df1 = pd.DataFrame.from_dict({'国家':['中国', '美国', '日本'], '人口':[13.97, 3, 2]})
print(df1)
"""
国家 人口
0 中国 13.97
1 美国 3.00
2 日本 2.00
"""
df2 = pd.DataFrame.from_records([('中国', '美国', '日本'), (13.97, 3, 2)])
print(df2)
"""
0 1 2
0 中国 美国 日本
1 13.97 3 2
"""
生成指定范围的日期
import pandas as pd
date_range1 = pd.date_range(start='2021-10-01', end='2021-10-06')
print(date_range1)
print("-分割-"*4)
date_range2 = pd.date_range(start='2021-10-01', periods=6)
print(date_range2)
运行结果:

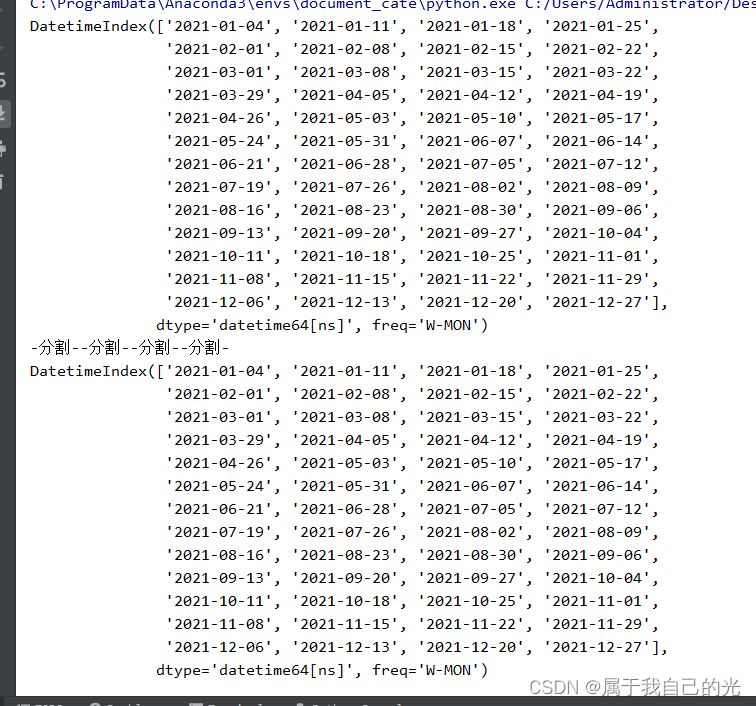
生成一年的所有周一日期
import pandas as pd
date_range1 = pd.date_range(start='2021-01-01', end='2021-12-31', freq='W-MON')
date_range2 = pd.date_range(start='2021-01-01', periods=52, freq='W-MON')
print(date_range1)
print("-分割-"*4)
print(date_range2)
运行结果:
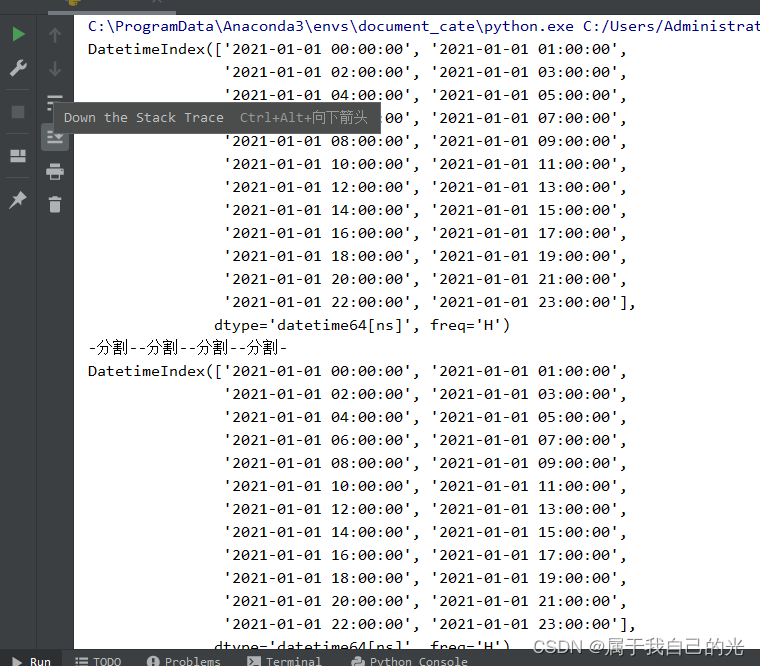
生成一天的所有小时
import pandas as pd
date_range1 = pd.date_range(start='2021-01-01', periods=24, freq='H')
date_range2 = pd.date_range(start='2021-01-01', end='2021-01-02', freq='H', closed='left')
print(date_range1)
print("-分割-"*4)
print(date_range2)
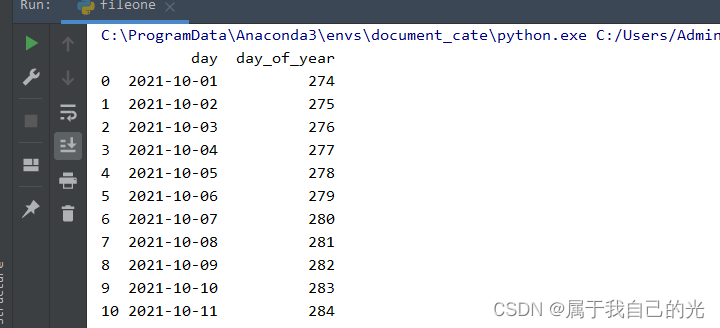
用日期生成DataFrame
import pandas as pd
date_range = pd.date_range(start='2021-10-01', periods=31)
df = pd.DataFrame(data=date_range, columns=['day'])
# day 这一列是时间,可以使用dt访问日期的方法
# 获得第二列,是日期属于本年度的第几天
df['day_of_year'] = df['day'].dt.dayofyear
print(df)
将日期作为DataFrame的索引
import numpy as np
import pandas as pd
date_range = pd.date_range(start='2021-10-01', periods=5)
data = {
'norm':np.random.normal(loc=0, scale=1, size=5),
'uniform':np.random.uniform(low=0, high=1, size=5),
# 二项分布
'binomial':np.random.binomial(n=1, p=0.2, size=5)
}
df = pd.DataFrame(data=data, index=date_range)
print(df)
查看数据
import numpy as np
import pandas as pd
date_range = pd.date_range(start='2021-10-01', periods=500)
data = {
'norm':np.random.normal(loc=0, scale=1, size=500),
'uniform':np.random.uniform(low=0, high=1, size=500),
'binomial':np.random.binomial(n=1, p=0.2, size=500)
}
df = pd.DataFrame(data=data, index=date_range)
print("查看前3行:\n", df.head(3), end='\n\n')
print("查看后2行:\n", df.tail(2), end='\n\n')
print("随机查看3行:\n", df.sample(3), end='\n\n')
print("查看数据类型、索引情况、行列数、字段类型、使用内存等:")
df.info()
print("\n查看数值型汇总统计:")
print(df.describe())
print("\n查看数据行和列名:\n", df.axes)
print("\n查看各字段类型:\n", df.dtypes)
print("\n查看列名:\n", df.columns)
print("\n查看指定列:\n", df['norm'])
print("\n查看指定的两列:\n", df[['norm', 'binomial']])
print("\n查看指定的两列(等价):\n", df.loc[:, ['norm', 'binomial']])
print("\n查看指定行:\n", df[df.index == '2021-10-04'])
print("\n查看第2到5行(索引取值):\n", df[1:4]) # 第5行没包括
print("\n查看第2到5行(等价写法):\n", df.iloc[1:4, :]) # 第5行没包括
print("\n查看第2到10行(索引取值, 两行取一行):\n", df[1:9:2]) # 第10行没包括
print("\n查看指定行列数据:\n", df.loc['2021-10-04', 'uniform':'binomial'])
print("\n查看指定行列数据:\n", df.loc['2021-10-04':'2021-10-06', 'uniform':'binomial'])
查看前3行:
norm uniform binomial
2021-10-01 -0.781939 0.719271 0
2021-10-02 0.487875 0.292774 0
2021-10-03 -0.572962 0.055363 0
查看后2行:
norm uniform binomial
2023-02-11 0.62362 0.135654 0
2023-02-12 -0.35141 0.070681 0
随机查看3行:
norm uniform binomial
2022-11-24 -1.632031 0.153601 0
2023-01-19 -1.239771 0.812020 0
2022-02-12 -1.460656 0.196312 0
查看数据类型、索引情况、行列数、字段类型、使用内存等:
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 500 entries, 2021-10-01 to 2023-02-12
Freq: D
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 norm 500 non-null float64
1 uniform 500 non-null float64
2 binomial 500 non-null int32
dtypes: float64(2), int32(1)
memory usage: 13.7 KB
查看数值型汇总统计:
norm uniform binomial
count 500.000000 500.000000 500.000000
mean -0.014227 0.492807 0.196000
std 1.090939 0.294254 0.397366
min -3.052117 0.001042 0.000000
25% -0.729646 0.242891 0.000000
50% -0.029443 0.495509 0.000000
75% 0.711569 0.749239 0.000000
max 3.439975 0.996878 1.000000
查看数据行和列名:
[DatetimeIndex(['2021-10-01', '2021-10-02', '2021-10-03', '2021-10-04',
'2021-10-05', '2021-10-06', '2021-10-07', '2021-10-08',
'2021-10-09', '2021-10-10',
...
'2023-02-03', '2023-02-04', '2023-02-05', '2023-02-06',
'2023-02-07', '2023-02-08', '2023-02-09', '2023-02-10',
'2023-02-11', '2023-02-12'],
dtype='datetime64[ns]', length=500, freq='D'), Index(['norm', 'uniform', 'binomial'], dtype='object')]
查看各字段类型:
norm float64
uniform float64
binomial int32
dtype: object
查看列名:
Index(['norm', 'uniform', 'binomial'], dtype='object')
查看指定列:
2021-10-01 -0.781939
2021-10-02 0.487875
2021-10-03 -0.572962
2021-10-04 0.346431
2021-10-05 0.762362
...
2023-02-08 -1.381426
2023-02-09 0.371719
2023-02-10 -0.348213
2023-02-11 0.623620
2023-02-12 -0.351410
Freq: D, Name: norm, Length: 500, dtype: float64
查看指定的两列:
norm binomial
2021-10-01 -0.781939 0
2021-10-02 0.487875 0
2021-10-03 -0.572962 0
2021-10-04 0.346431 1
2021-10-05 0.762362 0
... ... ...
2023-02-08 -1.381426 0
2023-02-09 0.371719 0
2023-02-10 -0.348213 0
2023-02-11 0.623620 0
2023-02-12 -0.351410 0
[500 rows x 2 columns]
查看指定的两列(等价):
norm binomial
2021-10-01 -0.781939 0
2021-10-02 0.487875 0
2021-10-03 -0.572962 0
2021-10-04 0.346431 1
2021-10-05 0.762362 0
... ... ...
2023-02-08 -1.381426 0
2023-02-09 0.371719 0
2023-02-10 -0.348213 0
2023-02-11 0.623620 0
2023-02-12 -0.351410 0
[500 rows x 2 columns]
查看指定行:
norm uniform binomial
2021-10-04 0.346431 0.353069 1
查看第2到5行(索引取值):
norm uniform binomial
2021-10-02 0.487875 0.292774 0
2021-10-03 -0.572962 0.055363 0
2021-10-04 0.346431 0.353069 1
查看第2到5行(等价写法):
norm uniform binomial
2021-10-02 0.487875 0.292774 0
2021-10-03 -0.572962 0.055363 0
2021-10-04 0.346431 0.353069 1
查看第2到10行(索引取值, 两行取一行):
norm uniform binomial
2021-10-02 0.487875 0.292774 0
2021-10-04 0.346431 0.353069 1
2021-10-06 1.388616 0.544167 0
2021-10-08 0.554392 0.312004 1
查看指定行列数据:
uniform 0.353069
binomial 1.000000
Name: 2021-10-04 00:00:00, dtype: float64
查看指定行列数据:
uniform binomial
2021-10-04 0.353069 1
2021-10-05 0.619799 0
2021-10-06 0.544167 0
条件选择
import pandas as pd
df = pd.read_excel('team.xlsx')
print(df.head())
"""
name team Q1 Q2 Q3 Q4
0 Liver E 89 21 24 64
1 Arry C 36 37 37 57
2 Ack A 57 60 18 84
3 Eorge C 93 96 71 78
4 Oah D 65 49 61 86
"""
# 查询Q1列大于90的
print(df[df.Q1 > 90])
"""
name team Q1 Q2 Q3 Q4
3 Eorge C 93 96 71 78
17 Henry A 91 15 75 17
19 Max E 97 75 41 3
32 Alexander C 91 76 26 79
38 Elijah B 97 89 15 46
80 Ryan E 92 70 64 31
88 Aaron A 96 75 55 8
97 Lincoln4 C 98 93 1 20
"""
# 查询team为C(仅查看前五个)
print(df[df.team=='C'][:5])
"""
name team Q1 Q2 Q3 Q4
1 Arry C 36 37 37 57
3 Eorge C 93 96 71 78
5 Harlie C 24 13 87 43
12 Archie C 83 89 59 68
13 Theo C 51 86 87 27
"""
# 查看第10条
print(df[df.index==10])
"""
name team Q1 Q2 Q3 Q4
10 Leo B 17 4 33 79
"""
# 组合条件 and 关系写法(编号800)
print(df[(df['Q1'] > 90) & (df['team'] == 'C')])
# 组合条件 多重筛选写法(编号800等价写法)
print(df[df['team'] == 'C'].loc[df.Q1 > 90])
"""
name team Q1 Q2 Q3 Q4
3 Eorge C 93 96 71 78
32 Alexander C 91 76 26 79
97 Lincoln4 C 98 93 1 20
"""
对列进行排序
import pandas as pd
df = pd.read_excel('team.xlsx')
# 按Q1列数据升序排序
print(df.sort_values(by='Q1'))
"""
name team Q1 Q2 Q3 Q4
37 Sebastian C 1 14 68 48
39 Harley B 2 99 12 13
85 Liam B 2 80 24 25
58 Lewis B 4 34 77 28
82 Finn E 4 1 55 32
.. ... ... .. .. .. ..
3 Eorge C 93 96 71 78
88 Aaron A 96 75 55 8
38 Elijah B 97 89 15 46
19 Max E 97 75 41 3
97 Lincoln4 C 98 93 1 20
[100 rows x 6 columns]
"""
# 按Q1列数据降序排序
print(df.sort_values(by='Q1', ascending=False))
"""
name team Q1 Q2 Q3 Q4
97 Lincoln4 C 98 93 1 20
19 Max E 97 75 41 3
38 Elijah B 97 89 15 46
88 Aaron A 96 75 55 8
3 Eorge C 93 96 71 78
.. ... ... .. .. .. ..
58 Lewis B 4 34 77 28
82 Finn E 4 1 55 32
85 Liam B 2 80 24 25
39 Harley B 2 99 12 13
37 Sebastian C 1 14 68 48
[100 rows x 6 columns]
"""
# team升序,Q1降序
print(df.sort_values(by=['team', 'Q1'], ascending=[True, False]))
"""
name team Q1 Q2 Q3 Q4
88 Aaron A 96 75 55 8
17 Henry A 91 15 75 17
70 Nathan A 87 77 62 13
42 Dylan A 86 87 65 20
71 Blake A 78 23 93 9
.. ... ... .. .. .. ..
98 Eli E 11 74 58 91
43 Jude E 8 45 13 65
45 Rory9 E 8 12 58 27
61 Jackson5 E 6 10 15 33
82 Finn E 4 1 55 32
[100 rows x 6 columns]
"""
分组聚合
import pandas as pd
df = pd.read_excel('team.xlsx')
print(df.head(3))
"""
name team Q1 Q2 Q3 Q4
0 Liver E 89 21 24 64
1 Arry C 36 37 37 57
2 Ack A 57 60 18 84
"""
# 聚合求和
print(df.groupby('team').sum())
"""
Q1 Q2 Q3 Q4
team
A 1066 639 875 783
B 975 1218 1202 1136
C 1056 1194 1068 1127
D 860 1191 1241 1199
E 963 1013 881 1033
"""
# 不同列不同的聚合方法(总和、总数、均值、最大值)
print(df.groupby('team').agg({
'Q1': sum,
'Q2': 'count',
'Q3': 'mean',
'Q4': max
}))
"""
Q1 Q2 Q3 Q4
team
A 1066 17 51.470588 97
B 975 22 54.636364 99
C 1056 22 48.545455 98
D 860 19 65.315789 99
E 963 20 44.050000 98
"""
表格转置翻转
import pandas as pd
df = pd.read_excel('team.xlsx')
df2 = df.groupby('team').sum()
print(df2)
""""
Q1 Q2 Q3 Q4
team
A 1066 639 875 783
B 975 1218 1202 1136
C 1056 1194 1068 1127
D 860 1191 1241 1199
E 963 1013 881 1033
"""
# 转置(编号802)
print(df2.T)
# 编号802等价写法 如果unstack不加参数0,则数据不会发生转置
print(df2.stack().unstack(0))
"""
team A B C D E
Q1 1066 975 1056 860 963
Q2 639 1218 1194 1191 1013
Q3 875 1202 1068 1241 881
Q4 783 1136 1127 1199 1033
"""
统计分析
import pandas as pd
df = pd.read_excel('team.xlsx')
# 返回所有列的均值
print(df.mean())
"""
Q1 49.20
Q2 52.55
Q3 52.67
Q4 52.78
dtype: float64
"""
# 返回所有行的均值
print(df.mean(1))
"""
dtype: float64
0 49.50
1 41.75
2 54.75
3 84.50
4 65.25
...
95 67.00
96 31.25
97 53.00
98 58.50
99 44.75
Length: 100, dtype: float64
"""
# 返回列与列之间的相关系数
df.corr()
# 返回每一列中的非空值的个数
df.count()
# 返回每一列的最大值
df.max()
# 返回每一列的最小值
df.min()
# 返回每一列的中位数
df.median()
# 返回每一列的标准差
df.std()
# 返回每一列的方差
df.var()
# 返回众数
print(df['Q1'].mode())
"""
0 9
dtype: int64
"""