为什么管MQ叫做分布式消息中间件?分布式表示应用场景(用户基数大采用分布式提供服务的方式)。消息表示通信形式。中间件表示媒介。生产者和消费者都只是个python程序而已。MQ它也是个软件(说明有端口),按照官方文档说,MQ就是个消息容器用于应用程序间的通信。刚刚说的redis也可用做MQ,比如使用scrapy-redis进行分布式爬虫时,用redis中的某个键充当调度器队列,同时运行多个一样的scrapy框架代码,各个下载器就会进入监听调度器队列状态,只要在redis中往这个队列插入一个url,各自的下载器马上抢这个url来发请求(分布式爬虫每个服务器共用一个调度器)。
各类MQ的主要特点:
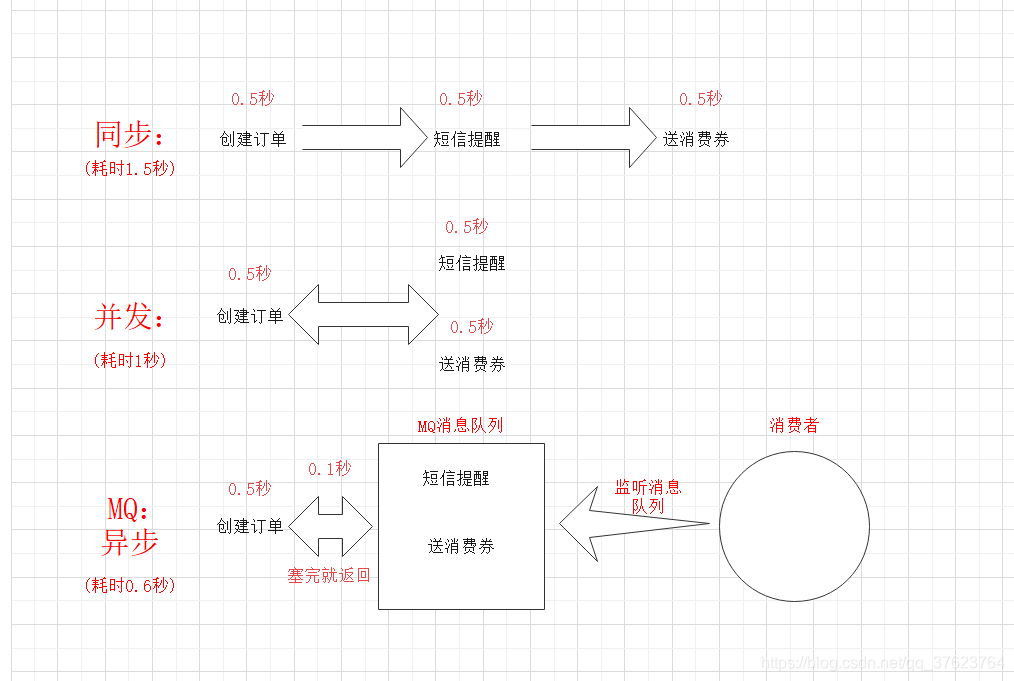
1、异步。请求过来,耗时操作(比如短信通知)直接塞进MQ,消费者在另一边自己处理,系统继续进行下一步操作(不会在页面一直等待)。
2、解耦。比如订单系统是调库存接口完成库存操作,现在就可以把商品id及购买数量放进MQ,库存接口充当消费者减库存。如果库存系统挂了,先不考虑超卖至少订单系统还是会正常创建订单。
3、削峰限流。用在秒杀和抢购,在一段时间内只允许MQ容纳100个消息。第101个请求直接回给用户抢购结束。
RabbitMQ的安装:建议用docker跑一个带management后台的RabbitMQ服务,映射后台管理界面的默认端口15672
docker run -d --name rabbitmq --publish 5671:5671 --publish 5672:5672 --publish 4369:4369 --publish 25672:25672 --publish 15671:15671 --publish 15672:15672 rabbitmq
docker exec -it rabbitmq bash进入容器后
1、先开启管理功能:rabbitmq-plugins enable rabbitmq_management
2、增加用户:rabbitmqctl add_user 用户名 密码
3、让该用户变为管理员可以登后台:rabbitmqctl set_user_tags 用户名 administrator
4、删除默认管理员guest:rabbitmqctl delete_user guest
物理安装的话有点麻烦,因为RabbitMQ是二郎写的,很神很高效,除了装MQ服务器还要装二郎环境,下面就是带management的RabbitMQ后台管理页面,访问http://ip:15672就来到MQ后台管理的用户登录页面,登陆进去即可(默认管理员是guest密码guest我一般会把它删掉)
RabbitMQ相对其他消息中间件使用起来较灵活,所以模式稍微多了一点。RabbitMQ一共有五种常用模式:简单模式,Work模式,发布订阅模式(fanout),关键字模式(direct),通配符模式(topic)。也可以按有无exchange交换机来分,分为简单模式、exchange模式。python代码连接RabbitMQ需要安装pika。由于是测试,我就直接用的默认账户guest。要是连接其他用户,还要用账户和密码实例化一个pika.PlainCredentials对象传进ConnectionParameters。
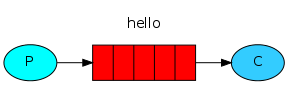
一、简单模式:
一对一,一个生产者,一个消费者。一边塞,一边取。
生产者端python文件:
import pika
# 1、连接rabbitmq服务器
with pika.BlockingConnection(pika.ConnectionParameters('x.x.x.x')) as connection:
channel = connection.channel()
# 2、创建一个名为hello的队列
# channel.queue_declare(queue='hello', durable=True) # 持久化队列
channel.queue_declare(queue='hello')
# 3、如果exchange为空,即简单模式:向名为hello队列中插入字符串Hello World!
channel.basic_publish(exchange='',
routing_key='hello',
body="Hello World",
# 持久化队列配置
# properties=pika.BasicProperties(
# delivery_mode=2,
# )
)
print("发送 ‘{}’ 成功".format("Hello World!"))
消费者端代码:
import pika
# 1、连接rabbitmq服务器
connection = pika.BlockingConnection(pika.ConnectionParameters(host='x.x.x.x'))
channel = connection.channel()
# 2、两边谁先启动谁创建队列
# channel.queue_declare(queue='hello',durable=True) # 持久化队列
channel.queue_declare(queue='hello')
# 一旦有消息就执行该回调函数(比如减库存操作就在这里面)
def callback(ch,method,properties,body):
print("消费者端收到来自消息队列中的{}成功".format(body))
# 数据处理完成,MQ收到这个应答就会删除消息
ch.basic_ack(delivery_tag=method.delivery_tag)
# 消费者这边监听的队列是hello,一旦有值出现,则触发回调函数:callback
channel.basic_consume(queue='hello',
auto_ack=False, # 默认就是False,可以直接不写
on_message_callback=callback,
)
print('当前MQ简单模式正在等待生产者往消息队列塞消息.......要退出请按 CTRL+C.......')
channel.start_consuming()
参数一,消息确认机制:auto_ack=False 和 ch.basic_ack(delivery_tag=method.delivery_tag)套用
消费者中有一个监听队列的函数basic_consume,它里面有个参数auto_ack,如果为True就是自动应答,即MQ会把消费者拿掉的这个消息马上删除。这样会有问题,消费者这边监听函数肯定是正常取消息,如果万一回调函数callback崩了,相当于操作消息失败,想要再去MQ拿,就拿不到了。为了避免这个问题出现,我们必须用auto_ack=False,意思就是手动应答,即MQ必须收到消费者端的成功应答,才会把这个消息删除,否则就一直备份着。所以就在回调函数的最后应答ch.basic_ack(delivery_tag=method.delivery_tag)。这样做可以允许消费者端的回调函数出bug,debug后,再次取用消息进行操作,算是个防止消息丢失的方法。
参数二,消息持久化机制:durable=True 和 properties=pika.BasicProperties(delivery_mode=2)套用
MQ存储的所有消息都是在内存,只要MQ服务器宕机,消息全丢失。为了解决这个问题,引入了消息持久化,创建队列时加上durable=True,就能创建持久化队列。即该队列中的所有消息不再存于内存中,全部持久化到磁盘,相比不加,能最大程度保证消息不丢失。方法:创建队列时加上durable=True,然后给队列塞消息时加上properties=pika.BasicProperties(delivery_mode=2)。注意,队列不能由持久化变为普通队列,反之亦然,否则会报错。持久化存储存到磁盘会占空间,并且肯定是比内存慢,所以不是所有队列都要创建为持久化队列,一般只是把重要的消息塞进持久化队列中而已。
二、Work模式
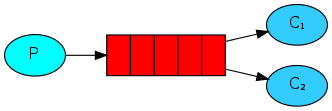
顾名思义,就是工作模式,通常会把这个Work模式跟简单模式统称为简单模式。因为它们都没有使用到exchange交换机(exchange为空)。只不过这个Work模式是一个生产者P,对应多个消费者,多个消费者同时监听这一个队列。那到底怎么分配消息呢,MQ的Work模式默认是平均分配,就会引发问题,因为每个消费者处理消息的效率肯定是不同的,队列是先进先出,比如,第一个消息出来,分给第一个消费者,这个消费者马上处理完了,然后第二个消息就能出队列,再给到第二个消费者,要是这个消费者的cpu很垃圾的话,就会导致队列中后面的消息全出不来,一直等第二个消费者把第二个消息处理完,所以我们需要在每个消费者端配置一句话channel.basic_qos(prefetch_count=1),表示谁处理完谁来拿消息处理,就不分你我,大家共同目的就是早处理完消息,你可以在消费者端的回调函数中进行time.sleep()验证。
Work模式的代码跟简单模式一样,实验的话,就跑多次消费者端代码就行了。但是直接跑不会重新开启新的控制台,需要配置pycharm工具栏---->run---->Edit Configurations---->Allow parallal run(在右上角的位置)
三、发布订阅模式(fanout)模式
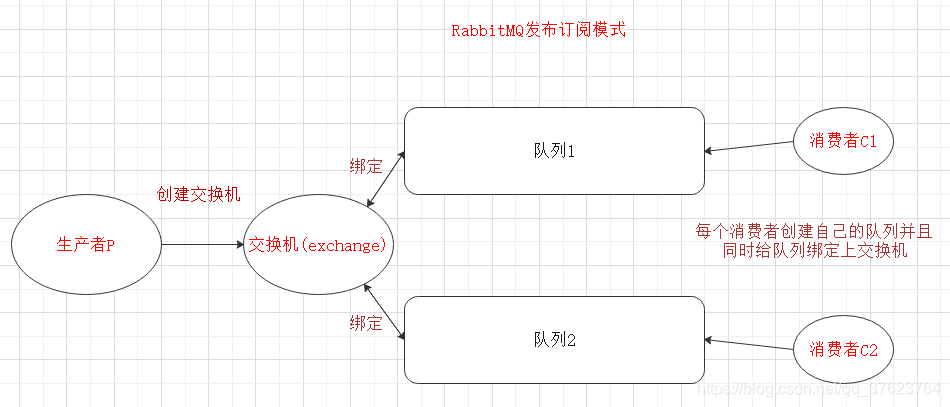
redis里你也听说过发布订阅,前面有篇博客
讲解过,其实redis的发布订阅就包含了RabbitMQ的exchange的三种模式,可以把订阅电台写死,也可以正则,目的就是为了能更细致地分清订阅者,只不过在RabbitMQ中划分成了三种模式。发布订阅,关键字,模糊匹配。这三种模式,生产者不再创建队列,只创建交换机,生产者只往交换机里边塞消息,由交换机来向绑定了交换机的队列转发消息,所以消费者端必须创建队列,然后同时还要为自己创建的队列绑定生产者创建的交换机,下面是发布订阅模式 。
生产者端python代码:
import pika
# 1、连接rabbitmq服务器
connection = pika.BlockingConnection(pika.ConnectionParameters(host='x.x.x.x'))
channel = connection.channel()
# 2、创建一个名为logs的交换机(用于分发日志),模式是发布订阅模式
channel.exchange_declare(exchange='logs',
exchange_type='fanout')
message = "I am producer this is my message"
# 生产者向交换机logs塞消息message
channel.basic_publish(exchange='logs',
routing_key='',
body=message,
)
print("发送 {} 成功".format(message))
# 关闭连接
connection.close()
消费者端python代码:
import pika
# 1、连接rabbitmq服务器
connection = pika.BlockingConnection(pika.ConnectionParameters(host='x.x.x.x'))
channel = connection.channel()
# 2、创建一个名为logs的交换机(用于分发日志),模式是发布订阅模式
channel.exchange_declare(exchange='logs',
exchange_type='fanout')
# 3、创建一个随机队列(exclusive=True)
result = channel.queue_declare(queue='',exclusive=True)
queue_name = result.method.queue # 获取随机队列名称
print('随机队列名: {}'.format(queue_name))
# 4、为名为queue_name的随机队列绑定名为logs的交换机
channel.queue_bind(exchange='logs',
queue=queue_name,
)
print('当前MQ发布订阅模式正在等待交换机往消息队列塞消息.......要退出请按 CTRL+C.......')
# 创建回调函数(收到监听队列的消息后执行该回调)
def callback(ch,method,properties,body):
print("接收到 {} 成功.......".format(body))
# 给mq发送应答信号,表明数据已经处理完成,可以删除
ch.basic_ack(delivery_tag=method.delivery_tag)
# 监听随机队列,一旦有消息出现,则触发回调函数:callback
channel.basic_consume(queue=queue_name,
auto_ack=False, # 默认就是False,可以直接不写
on_message_callback=callback,
)
# 哪个消费者先处理完谁就去消息队列取
channel.basic_qos(prefetch_count=1)
channel.start_consuming()
前面的Work模式跟这个发布订阅模式,表面上看是一样的呀,都是一个生产者对应多个消费者,其实它们最大的区别就是Work模式是多个消费者监听同一个队列,如果队列里面只有一个消息,却有一万个消费者正在监听,只有一个消费者能拿到消息。而发布订阅,是每个消费者都创建了自己的随机队列(创建自定义的队列名也可以),只要它们各自的队列绑定了exchange,exchange一收到生产者消息后,就会给队列转发消息,这就是区别。
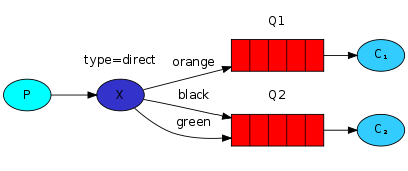
四、关键字(direct)模式:
前面的发布订阅,为随机队列绑定交换机时,routing_key为空,即只要是绑定了交换机的队列就能收到消息,而这个关键字模式,仅仅是多了个关键字,相当于是细化了exchange转发消息的条件,现在就变成这样了,消费者端创建随机队列后,给队列绑定交换机时,传一个routing_key给交换机,然后生产者端发送消息给交换机时,也给交换机一个routing_key,只有双方给交换机的关键字暗号对的上,交换机才会转发消息给队列。仅仅是多了个关键字绑定,当然肯定不局限于一个关键字 ,消费者和生产者都可以绑定多个关键字。关键字模式是或的关系不是且,只要双方对得上一个关键字就算匹配成功。提一下简单模式和Work模式,它们的routing_key里面放的是队列名,并不是关键字,因为它们根本就没有exchange的概念,直接通过队列来通信没有中间这一层交换机。
生产者端代码:
import pika
# 1、连接rabbitmq服务器
connection = pika.BlockingConnection(pika.ConnectionParameters(host='x.x.x.x'))
channel = connection.channel()
# 2、声明一个名为direct_logs的交换机,类型为关键字模式
channel.exchange_declare(exchange='direct_logs',
exchange_type='direct',
)
message = "I am producer this is my message Hello!"
# 3、向交换机发送消息,并告诉交换机只发给绑定了lan或yue关键字的消费者队列
channel.basic_publish(exchange='direct_logs',
routing_key='lan', # 可以用for循环,不用像这样一个一个加
body=message,
)
channel.basic_publish(exchange='direct_logs',
routing_key='yue',
body=message,
)
print("Sent {} 成功".format(message))
# 关闭连接
connection.close()
消费者端代码:
import pika
# 1、连接rabbitmq服务器
connection = pika.BlockingConnection(pika.ConnectionParameters(host='x.x.x.x'))
channel = connection.channel()
# 跟队列同理,因为不确定生产者和消费者谁先跑起来,消费者端也要创建交换机
# 2、创建一个名为direct_logs的交换机,类型为关键字模式。
channel.exchange_declare(exchange='direct_logs',
exchange_type='direct',
)
# 3、创建一个随机队列
result = channel.queue_declare(queue='',exclusive=True)
queue_name = result.method.queue
# 4、为随机队列绑定名为direct_logs的交换机,关键字为lan和yue
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key='yue') # 也推荐用for循环
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key='chuan')
print('当前MQ关键字模式正在等待交换机往消息队列塞消息.......要退出请按 CTRL+C.......')
# 构建回调函数
def callback(ch,method,properties,body):
print("Received {} 成功.......".format(body))
# 给mq发送应答信号,表明数据已经处理完成,可以删除
ch.basic_ack(delivery_tag=method.delivery_tag)
# 监听随机队列,一旦有值出现,则触发回调函数:callback
channel.basic_consume(queue=queue_name,
auto_ack=False, # 默认就是False,可以直接不写
on_message_callback=callback,
)
# 消费者不止这一个时,谁先处理完谁就去消息队列取
channel.basic_qos(prefetch_count=1)
channel.start_consuming()
五、模糊匹配(topic)模式:
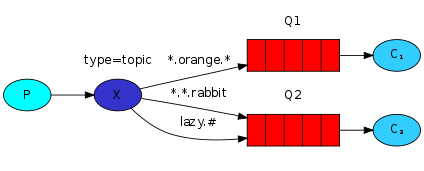
场景最多的就是fanout和direct模式,基本没人会用这个topic模式,发布订阅fanout模式是没有关键字只要绑定就转发。关键字direct模式是绑定一个或多个关键字,只要有一个关键字对的上就转发。而现在,这个模糊匹配就是在关键字模式上又做了个升级,即关键字不写死,两方都可以通过通配符来设置routing_key的值。#匹配0个或多个单词,*只匹配一个单词,a和abc都叫做一个单词
生产者端代码:
import pika
# 1、连接rabbitmq服务器
connection = pika.BlockingConnection(pika.ConnectionParameters(host='x.x.x.x'))
channel = connection.channel()
# 2、创建一个名为topic_logs的交换机
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic',
)
message = "welcome to rabbitmq lyc"
# 3、向交换机发送数据,让交换机只给能匹配lan.adasd.*的队列发消息
channel.basic_publish(exchange='topic_logs',
routing_key='lan.adasd.*',
body=message,
)
print("Sent {} 成功".format(message))
# 关闭连接
connection.close()
消费者端代码:
import pika
# 1、连接rabbitmq服务器
connection = pika.BlockingConnection(pika.ConnectionParameters(host='x.x.x.x'))
channel = connection.channel()
# 2、创建一个名为topic_logs的交换机
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic',
)
# 3、创建一个随机队列
result = channel.queue_declare(queue='',exclusive=True)
queue_name = result.method.queue
# 4、为名为queue_name的随机队列绑定名为logs的交换机
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key='lan.*.#') # 以routing_key作为关键字
print('当前MQ模糊匹配模式正在等待交换机往消息队列塞消息.......要退出请按 CTRL+C.......')
# 构建回调函数
def callback(ch,method,properties,body):
body = body.decode('utf8')
print("接收 {} 成功.......".format(body))
# 给mq发送应答信号,表明数据已经处理完成,可以删除
ch.basic_ack(delivery_tag=method.delivery_tag)
# 监听随机队列,一旦有值出现,则触发回调函数:callback
channel.basic_consume(queue=queue_name,
auto_ack=False, # 默认就是False,可以直接不写
on_message_callback=callback,
)
# 消费者不止这一个时,谁先处理完谁就去消息队列取
channel.basic_qos(prefetch_count=1)
channel.start_consuming()
exchange模式和非exchange模式梳理:
简单模式是一对一,一个消费者监听一个队列。Work模式是一对多,多个消费者监听同一个队列,统称为非exchange模式,缺点就是生产者的所有消息全堆积到同一个队列中,没有做消息分类。fanout,direct和topic统称为exchange模式或交换机模式,该模式下的每个消费者都有自己创建的队列,采用三种方式中的任意一种来绑定交换机,再由交换机分配消息给这些队列。exchange模式除了可以应对多个消费者之外,还可以应对消息多样化,因为MQ不知道这个消息到底分给哪个消费者来做,比如一个项目里面,有发送邮件,有发送支付短信,有赠送优惠券,这就是三类消息,使用exchange模式就很好应对,生产者和消费者两端商量好,双方都用send_email作为关键字,来表明这个是发邮件的消息,那交换机就会按照send_email去找队列,就完成了该队列只用于存放邮箱地址。其他类的消息双方又商量同时用另外一个关键字。应用场景最多的就是发布订阅和关键字模式。
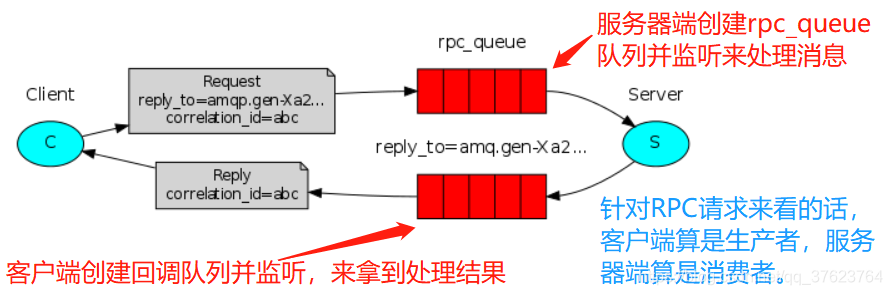
六、最后谈一下用RabbitMQ实现RPC模式:
RPC——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议,和RabbitMQ没有必然关系,RPC可以基于tcp或http,http是基于tcp的,RPC直接工作在会话层。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使分布式系统中的应用程序通信更加容易,RPC采用C/S模式。在MQ的RPC模式中:客户端和服务器两边都在生产消息也在监听队列,客户端启动时,它将创建一个回调队列(可以是个随机队列,就是上图下方的reply_to那个队列),对于RPC请求,客户端发送一条消息,该消息中要带上两个属性: reply_to(回调队列,告诉服务器端你把结果给我放进我的创建的这个回调队列)和correlation_id(请求的唯一标识),塞进rpc_queue队列。服务器端正在监听。出现消息后,服务器端处理消息再把响应数据以及correlation_id按照reply_to字段中的指向,塞进那个回调队列。客户端监听这个回调队列,回调队列出现消息后,客户端将检查correlation_id与它请求时带的值是否一致,一致的话说明正是客户端这次RPC请求的响应结果。这儿RPC模式它怪就怪在这儿,发起RPC请求的一方能通过跟服务器商量,让服务器按要求把响应数据返回回来。RPC基本会用在公司内部系统上下游的应用程序通信,因为传输文件不能过大,所以对外基本是使用http的restful接口。用RabbitMQ来实现RPC模式,下面案例的目标就是客户端想用RPC请求调用另一台机上的fun函数,并且还要拿到响应结果。
客户端代码:
import pika
# 用于生成请求的唯一标识correlation_id
import uuid
class RpcClient(object):
def __init__(self):
# 连接rabbitmq服务器
self.connection = pika.BlockingConnection(pika.ConnectionParameters(host='x.x.x.x'))
self.channel = self.connection.channel()
# 创建随机回调队列,你不随机也是可以的,反正必要要传过去
result = self.channel.queue_declare(queue='',exclusive=True)
# 拿到这个随机队列名
self.callback_queue = result.method.queue
# 监听这个回调队列,一旦有响应结果就促发回调on_response(就是为了对比id)
self.channel.basic_consume(
queue=self.callback_queue,
auto_ack=True,
on_message_callback=self.on_response
)
# 对比id确定这个结果确实是我的响应结果
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
self.response = None
# 用于生成请求的唯一标识
self.corr_id = str(uuid.uuid4())
# 向rpc_queue队列中塞消息body,并添加reply_to和correlation_id两个属性
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=self.corr_id,
),
# 消息
body=str(n)
)
while self.response is None:
# 防止连接自动断开,消费者主线程定时发心跳交互,耗时较长的消息消费
self.connection.process_data_events()
return str(self.response)
rpc = RpcClient()
response = rpc.call(2)
print("客户端已发出RPC请求,我客户端这边传了个2给你,想要调用你服务器端的fun函数")
print("客户端拿到本次RPC请求的响应结果:{}".format(response))
服务器端代码:

import pika
# 连接rabbitmq服务器
connection = pika.BlockingConnection(pika.ConnectionParameters(host='x.x.x.x'))
channel = connection.channel()
# 创建rpc_queue队列
channel.queue_declare(queue='rpc_queue')
# 这个fun就是我们远程要调用的这么一个简单的接口
def fun(n):
return 100 * n
# body就是来自客户端塞进队列的消息,props就是来自客户端properties里的两个键值对
def on_request(ch, method, props, body):
n = int(body)
response = fun(n)
# 向接收到的props.reply_to队列塞进响应结果response
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id=props.correlation_id),
body=str(response))
print("服务器端已经把响应结果放进客户端的回调队列了,结果是:{}".format(response))
# 通知MQ这条消息对应处理成功,可以删除这条消息了
ch.basic_ack(delivery_tag=method.delivery_tag)
# 消费者不止这一个时,谁先处理完谁就去消息队列取,这句话最好在每个消费者端都加上,这儿服务器端同样也加上
channel.basic_qos(prefetch_count=1)
# 监听rpc_queue队列,一收到来自客户端的消息则促发回调on_request
channel.basic_consume('rpc_queue',on_request)
print("服务器端正在等待客户端往rpc_queue放消息......")
channel.start_consuming()
以上就是RabbitMQ常用的包括RPC在内的六种模式,以及如何在python中使用RabbitMQ,感兴趣的兄弟可以自己copy一份到本地跑一下试试。另外希望朋友们看完能点个赞评论一下,有误的地方还望海涵。
