Linux、Windows下C语言内存布局(内存模型)
在虚拟地址空间及编译模式中提到,虚拟地址空间在32位环境下大小为4GB,在64位环境下大小为256TB,那么,一个C语言程序的内存在整个地址空间中是如何分布的呢?数据在哪里?代码在哪里?为什么要这样分布?
内核空间和用户空间
对于32位环境,理论上程序可以拥有4GB的独立空间,我们在C语言中使用到的变量、函数、字符串等都会对应内存中的一块区域。
但是,在这4GB的地址空间中,要拿出一部分给操作系统内核使用,应用程序无法直接访问这一段内存,这一部分内存地址被称为内核空间(Kernel Space)。
Windows在默认情况下会将高地址的2GB空间分配给内核(也可以配置为1GB),而Linux默认情况下会将高地址的1GB空间分配给内核。也就是说,应用程序只能使用剩下的2GB或3GB的地址空间,称为用户空间(User Space)。
Linux下32位环境的用户空间内存分布情况
我们暂时不关心内核空间的内存分布情况,下图是Linux下32位环境的一种经典内存模型:
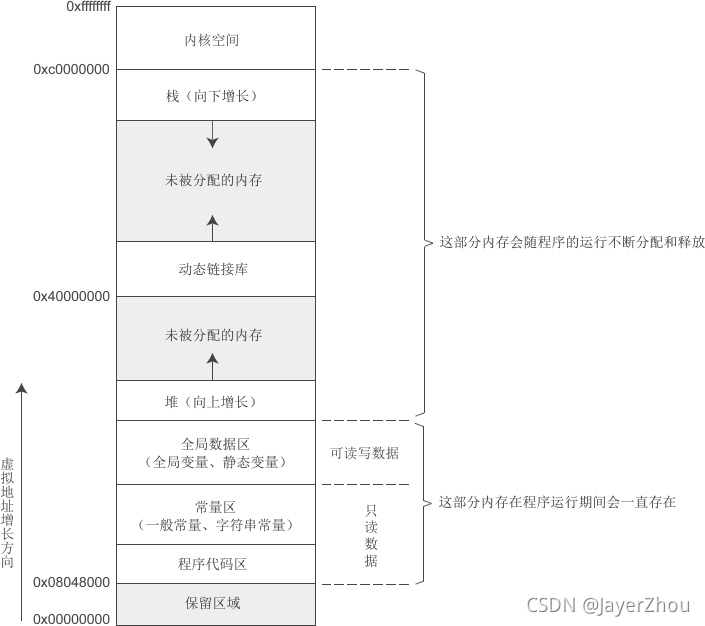
对各个内存分区的说明:
| 内存分区 | 说明 |
|---|---|
| 程序代码区(code) | 存放函数体的二进制代码。一个C语言程序由多个函数构成,C语言程序的执行就是函数之间的相互调用。 |
| 常量区(constant) | 存放一般的常量、字符串常量等。这块内存只有读取权限,没有写入权限,因此他们的值在程序运行期间不能改变。 |
| 全局数据区(global data) | 存放全局变量、静态变量等。这块内存有读写权限,因此他们的值在程序运行期间可以任意改变。 |
| 堆区(heap) | 一般由程序员分配和释放,若程序员不释放,程序运行结束时由操作系统回收。malloc()、calloc()、free()等函数操作的就是这块内存。也是我们要解释的重点。 注意:这里所说的堆区与数据结构中的堆不是一个概念,堆区的分配方式倒是类似于链表。 |
| 动态链接库 | 用于在程序运行期间加载和卸载动态链接库。 |
| 栈区(Stack) | 存放函数的参数值、局部变量的值等,其操作方式类似于数据结构中的栈。 |
在这些内存分区中(暂时不讨论动态链接库),程序代码区用来保存指令,常量区、全局数据区、堆、栈都用来保存数据。对内存的研究,重点是对数据分区的研究。
程序代码区、常量区、全局数据区在程序加载到内存后就分配好了,并且在程序运行期间一直存在,不能销毁也不能增加(大小已被固定),只能等到运行结束后由操作系统收回,所以全局变量、字符串等在程序任何地方都能访问,因为他们的内存一直都在。
常量区和全局数据区有时也被合称为静态数据区,意思是这段内存专门用来保存数据,在程序运行期间一直存在。
函数被调用时,会将参数、局部变量、返回地址等与函数相关的信息压入栈中,函数执行结束后,这些信息都将被销毁。所以局部变量、参数只在当前函数中有效,不能传递到函数外部,因为他们的内存不在了。
常量区、全局数据区、栈上的内存由系统自动分配和释放,不能由程序员控制。程序员唯一能控制的内存区域就是堆(heap):他是一块巨大的内存空间,常常占据整个虚拟空间的绝大部分,在这片空间中,程序可以申请一块内存,并自由的使用(放入任何数据)。堆内存在程序主动释放之前一直存在,不随函数的结束而失效。在函数内部产生的数据只要放到堆中,就可以在函数外部使用。
一个实例
代码如下:
#include <stdio.h>
char *str1 = "hello,world"; //字符串在常量区,str1在全局数据区
int n; //全局数据区
char* func(){
char *str = "你好,世界"; //字符串在常量区,str在栈区
return str;
}
int main(){
int a; //栈区
char *str2 = "01234"; //字符串在常量区,str2在栈区
char arr[20] = "56789"; //字符串和arr都在栈区
char *pstr = func(); //栈区
int b; //栈区
printf("str1: %#X\npstr: %#X\nstr2: %#X\n", str1, pstr, str2);
puts("--------------");
printf("&str1: %#X\n &n: %#X\n", &str1, &n);
puts("--------------");
printf(" &a: %#X\n arr: %#X\n &b: %#X\n", &a, arr, &b);
puts("--------------");
printf("n: %d\na :%d\nb: %d\n", n, a, b);
puts("--------------");
printf("%s\n", pstr);
return 0;
}
运行结果:
str1: 0X400710
pstr: 0X400720
str2: 0X400731
--------------
&str1: 0X601040
&n: 0X60104C
--------------
&a: 0X19D0728C
arr: 0X19D07270
&b: 0X19D0726C
--------------
n: 0
a: -858993460
b: -858993460
--------------
你好,世界
对代码的说明:
- 全局变量的内存在编译时就已经分配好了,他的默认初始值是0(他所占用的每一个字节都是0值),局部变量的内存在函数调用时分配,他的默认初始值是不确定的,由编译器决定,一般是垃圾值,之后我们会详细说。
- 函数func()中的局部字符串常量“你好,世界”也被存储到常量区,不会随着func()的运行结束而销毁,所以最后依然能输出。
- 字符数组arr[20]在栈区分配内存,字符串“56789”就保存在这块内存中,而不是在常量区,要注意区分。
Linux下64位环境的用户内存分布情况
在64位环境下,虚拟地址空间大小为256TB,Linux将高128TB的空间分配给内核使用,而将低128TB的空间分配给用户程序使用,如图:
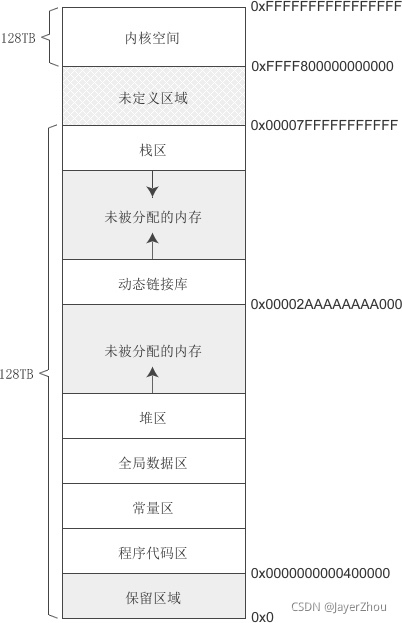
虚拟地址空间及编译模式中提到在64位环境下,虚拟地址虽然占用64位,但只有最低48位有效。这里需要补充一点是,任何虚拟地址的48位至63位必须与47位一致。
上图中,用户空间地址的47位是0,所以高16位也是0,换算成十六进制形式,最高的四个数都是0。内核空间地址的47位是1,所以高16位也是1,换算成十六进制,最高的四个数都是1.这样中间的一部分地址正好空出来,也就是图中的“未定义区域”,这部分内存无论如何也访问不到。
Windows下C语言程序的内存布局(内存模型)
在32位环境下,Windows默认会将高地址的2GB空间分配给内核(也可以配置为1GB),而将剩下的2GB空间分配给用户程序。
不同于Linux,Windows是闭源的,有版权保护,资料较少,不好深入研究每一个细节,至今仍然有一些内部原理不被大家知晓。关于Windows地址空间的内存分布,官网上只给出了简单的说明:
- 对于32位程序,内核占用较高的2GB,剩下的2GB分配给用户程序
- 对于64位程序,内核占用最高的248TB,用户程序占用最低的8TB
下图是一个典型的Windows 32位程序的内存分布:
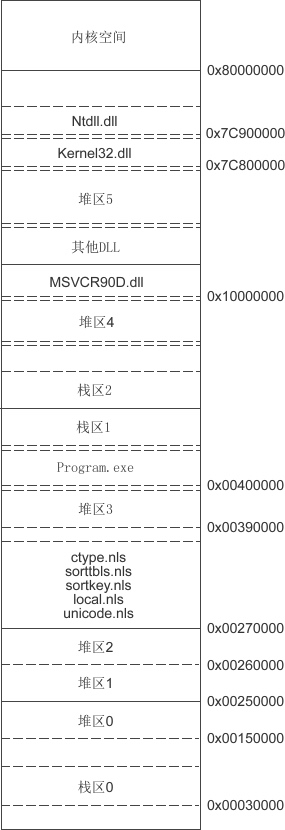
可以看到,Windows的地址空间被分配给了各种exe、dll文件、堆、栈。其中exe文件一般位于0x00400000起始的地址;一部分DLL位于0x10000000起始的地址,如运行库dll;还有一部分DLL位于接近0x80000000的位置,如系统dll,Ntdll.dll、Kernel32.dll。
栈的位置则在 0x00030000 和 exe 文件后面都有分布,可能有读者奇怪为什么Windows需要这么多栈呢?我们知道,每个线程的栈都是独立的,所以一个进程中有多少个线程,就有多少个对应的栈,对于Windows来说,每个线程默认的栈大小是1MB。
在分配完上面这些地址以后,Windows的地址空间已经是支离破碎了。当程序向系统申请堆空间时,只好从剩下的还没有被占用的地址上分配。
Windows64位程序的地址空间分布情况如下图所示:
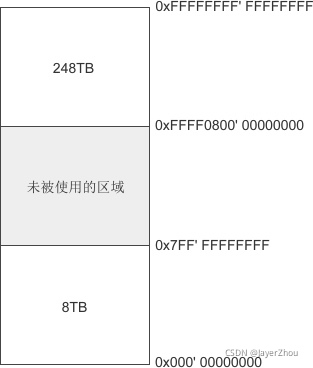
由于官方资料不足,我们不再深入讲解 Windows 64 位程序的具体内存分布。