源代码链接:https://github.com/happyday22/HLS_accelerator
1.Introduction
卷积神经网络(CNN)主要由卷积层、池化层、全连接层和激活层等网络层顺序连接而成。本文主要针对计算密集型的卷积层,利用Vivado HLS工具对其在FPGA上的实现进行加速。
2.Basic knowledge
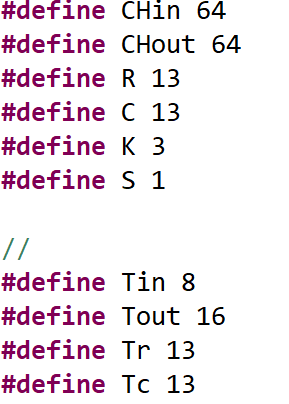
一个基本的卷积运算由6层for循环实现。如下面代码所示,从外向里的循环依次是K*K大小的卷积核,输出特征图的行列(Tr,Tc),输出通道数(Tout),输入通道数(Tin)
Kernel_Row:
for(int kr=0;kr<K;kr++)
{
Kernel_Col:
for(int kc=0;kc<K;kc++)
{
Row:
for(int r=0;r<Tr;r++)
{
Column:
for(int c=0;c<Tc;c++)
{
Out_channel:
for(int out=0;out<Tout;out++)
{
in_channel:
for(int in=0;in<Tin;in++)
{
Out[out][r][c]+=In[in][S*r+kr][S*c+kc]*W[out][in][kr][kc];
}
}
}
}
}
}
用C++语言实现上述卷积运算后,Vivado HLS能够将其综合为RTL硬件代码。除上述的C++代码,Vivado HLS还需要输入时钟周期,芯片类型以及编译制导语句(Directives)等。本文的芯片类型以及时钟周期选定如下
set_part {xc7k160tfbg484-1} -tool vivado
create_clock -period 10 -name default
到此,我们总结一下Vivado HLS会做哪些工作:
1.将高级语言C/C++代码转换成等价的RTL代码,并根据设定的时钟周期和芯片延迟信息,调度RTL的执行,并尽可能的将多个操作放在同一个时钟周期内执行;
2.根据Directive语句进行特定的优化;
3.使用接口综合语句指定数据传输所使用的总线协议。
3.Convolution design with Vivado HLS
下面,开始说卷积层加速的具体实现过程。主要涉及到以下几方面
3.1 片上资源
Vivado HLS最终综合形成的RTL代码需要在FPGA上执行。但FPGA片上缓存BRAM数量有限,而卷积层的参数量又是非常大的。一种解决方法是将大量的参数存储在DRAM上,循环分片计算输出特征图。下面是循环分片的代码,我们对输出特征图的行、列,输入通道数,输出通道数四个维度进行循环分片,从而保证FPGA片上资源能够满足使用。
r_channel_tiling:
for(int r=0;r<R;r+=Tr)
{
c_channel_tiling:
for(int c=0;c<C;c+=Tc)
{
out_channel_tiling:
for(int cho=0;cho<CHout;cho+=Tout)
{
in_channel_tiling:
for(int chi=0;chi<CHin;chi+=Tin)
{
// compute
}
}
}
}
3.2 并行计算
FPGA相比于通过处理器CPU来说,它有着优秀的并行处理能力。因此我们对卷积运算过程并行化,相比于其它维度,输入通道和输出通道更容易实现并行化。如下所示,利用一条PIPELINE语句即可实现。
Kernel_Row:
for(int kr=0;kr<K;kr++)
{
Kernel_Col:
for(int kc=0;kc<K;kc++)
{
Row:
for(int r=0;r<Tr;r++)
{
Column:
for(int c=0;c<Tc;c++)
{
#pragma HLS PIPELINE
Out_channel:
for(int out=0;out<Tout;out++)
{
in_channel:
for(int in=0;in<Tin;in++)
{
Out[out][r][c]+=In[in][S*r+kr][S*c+kc]*W[out][in][kr][kc];
}
}
}
}
}
}
我们希望PIPELINE下面的代码可以在一个周期内执行完成,但目前还达不到这样的效果。因为并行化后,一个周期内需要对同一数组进行多次读写,数组默认的端口数是不能满足该条件的。我们继续对数组进行优化。如下所示,在指定维度对数组展开,从而提供多端口读写能力
data_t In[Tin][S*Tr+K-S][S*Tc+K-S];
#pragma HLS ARRAY_PARTITION variable=In complete dim=1
data_t W[Tout][Tin][K][K];
#pragma HLS ARRAY_PARTITION variable=W complete dim=1
#pragma HLS ARRAY_PARTITION variable=W complete dim=2
static data_t Out[Tout][Tr][Tc];
#pragma HLS ARRAY_PARTITION variable=Out complete dim=1
到此,我们成功在FPGA上实现了卷积层的并行计算过程。但还不能说在FPGA上实现了卷积加速。计算能力有了,我们还缺少用来计算的数据。
3.3 数据传输
前面说过FPGA片上缓存资源有限,大量的参数是存储在DRAM上的。FPGA需要时,参数再通过总线从DRAM上传输到FPGA上。这里我们采用AXI4总线协议传输数据,Vivado HLS中是利用INTERFACE语句指定数据传输所使用的总线协议。
#pragma HLS INTERFACE m_axi depth=10800 port=In_addr bundle=BUS0
#pragma HLS INTERFACE m_axi depth=55296 port=W_addr bundle=BUS2
#pragma HLS INTERFACE m_axi depth=21632 port=Out_addr bundle=BUS3
并行计算需要大量的数据。可以利用DATAPACK语句提高总线带宽。
#pragma HLS DATA_PACK variable=In_addr
#pragma HLS DATA_PACK variable=W_addr
3.4 任务级并行
数据读取,卷积计算,写回数据是在FPGA上执行卷积运算的三个过程。上面三个函数能否在一定程度上并行执行呢?答案是可以的。Vivado HLS提供了DATAFLOW语句实现任务级并行。至于任务级并行是什么呢,可以参考这里。我们实现时并没有直接使用DATAFLOW语句,而是用了(pingpong标记+if-else语句)实现的。综合后的效果与DATAFLOW语句基本等价。具体的实现过程可以参考源码,这里就不列出了。
4.Result
最后看一下综合后结果
4.1 卷积参数和分片大小
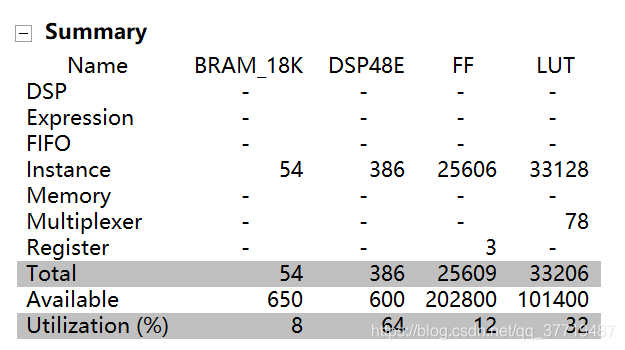
4.2 综合报告
4.3 资源使用