Flink系统架构中包含了两个角色,分别是JobManager和TaskManager,是一个典型的Master-Slave架构。JobManager相当于是Master,TaskManager相当于是Slave

1. Standalone 部署安装
https://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.9.2/flink-1.9.2-bin-scala_2.
11.tgz
| node1 | node2 | node3 |
| (master) | (slave) | (slave) |
1.1 修改flink-conf.yaml配置文件
#JobManager地址
jobmanager.rpc.address: node01
# JobManagerRPC通信端口
jobmanager.rpc.port: 6123
# JobManager所能使用的堆内存大小
jobmanager.heap.size: 1024m
# TaskManager所能使用的堆内存大小
taskmanager.heap.size: 1024m
# TaskManager管理的TaskSlot个数,依据当前物理机的
taskmanager.numberOfTaskSlots: 2
#核心数来配置,一般预留出一部分核心(25%)给系统及其他进程使用,一个slot对应一个core。如果core支持超线程,那么slot个数*2
#指定WebUI的访问端口
rest.port: 80811.2 修改slaves文件
配置slave节点
node2
node31.3 启动集群

2. flink 高可用集群搭建
3. flink on yarn
以 Yarn 模式部署 Flink 任务时,要求 Flink 是有 Hadoop 支持的版本, Hadoop环境需要保证版本在 2.2 以上,并且集群中安装有 HDFS 服务
3.1 Session-cluster 模式
Session-Cluster 模式需要先启动集群,然后再提交作业,接着会向 yarn 申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn 中的其中一个作业执行完成释放了资源, 下个作业才会正常提交,所有作业共享 Dispatcher 和 ResourceManager;共享资源;适合规模小执行时间短的作业
在 yarn 中初始化一个 flink 集群,开辟指定的资源,以后提交任务都向这里提交。这个 flink 集群会常驻在 yarn 集群中, 除非手工停止
启动hadoop集群
启动yarn-session
./yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d3.2 Per-Job-Cluster 模式
4. filink 任务提交的两种方式
4.1 命令行提交任务
flink run -c test.WordCount -p 2 -d flinkDemo-1.0-SNAPSHOT.jar-c :指定全限定类名
-d:后台运行
-p : 2代表设置的默认并行度
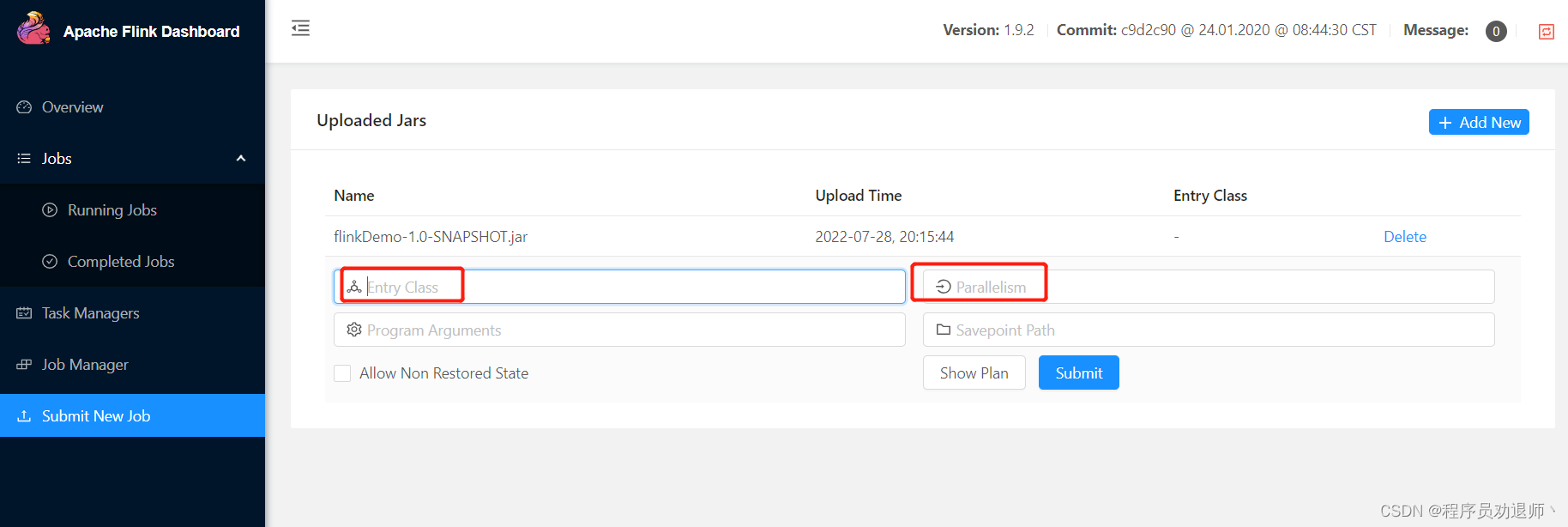
4.2 webUI页面提交
指定全限定类名
指定并行度
取消任务:
./bin/flink list
./bin/flink cancel jobid