TinyWebServer代码详细讲解(http模块)
这里的参照的代码是https://github.com/qinguoyi/TinyWebServer
对于原代码的不足之处,我会在之后的文章中给出改进代码 在笔者fork的这版中,原代码作者对于代码作出了更细化的分类
细节问题可以参考《APUE》《Linux高性能服务器编程》或者我之前的博客
毋庸置疑,http模块是整个服务器的核心部分
http模块设计思路
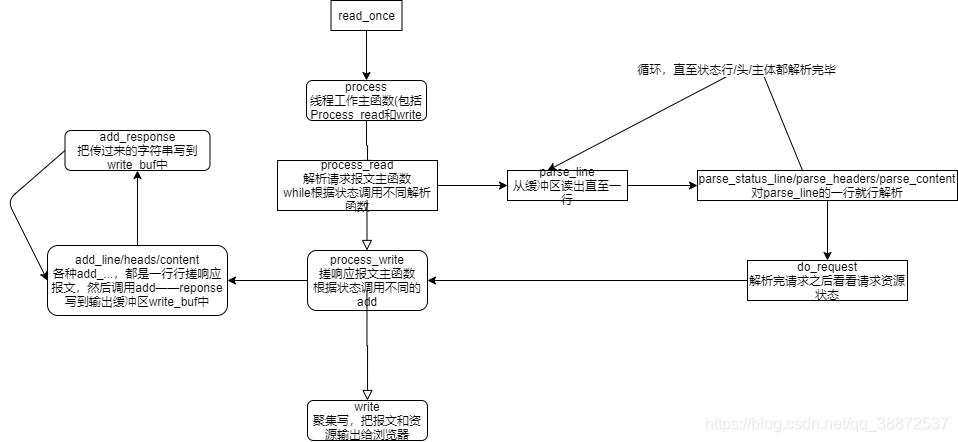
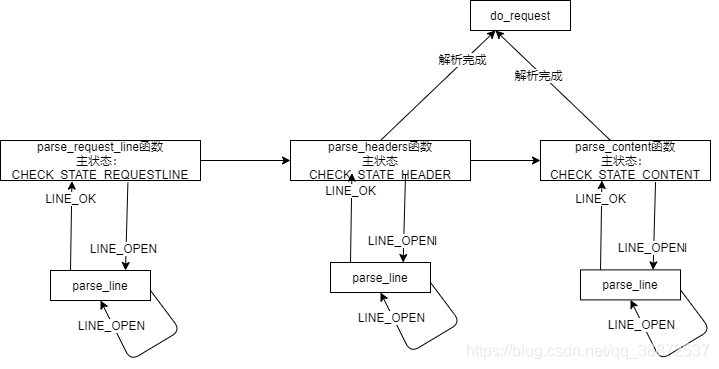
我们先理解这一块使用到的“状态机设计模式”,我们学过UML里的状态图,那么我们应该很容易理解这个设计模式。简单理解就是,我们经常会遇到需要根据不同的情况作出不同的处理的情况,这时候我们写出大量的if else使得逻辑十分混乱。那么我们可以这样设计:我们在类里面设计一个状态,并且允许一个对象在其内部状态改变时改变它的行为,对象看起来似乎修改了它的类。感觉说起来还是比较抽象,看代码会比较容易理解,其实就是看状态调用不同的函数。
关于状态机,请参考:Linux网络编程:状态机
http_conn.cpp
首先先从process说起。
这是线程处理业务时的回调入口,并且这个函数同时处理了read和write事件
同时考虑到了关闭连接与读完成问题(NO_REQUEST为读完成状态)
void http_conn::process()
{
HTTP_CODE read_ret = process_read();
//NO_REQUEST,表示请求不完整,需要继续接收请求数据
if (read_ret == NO_REQUEST)
{
//注册并监听读事件
modfd(m_epollfd, m_sockfd, EPOLLIN, m_TRIGMode);
return;
}
//调用process_write完成报文响应
bool write_ret = process_write(read_ret);
if (!write_ret)
{
close_conn();
}
//注册并监听写事件
modfd(m_epollfd, m_sockfd, EPOLLOUT, m_TRIGMode);
}
read业务函数集
process_read函数
在while条件中,完成从状态机的激活,并且得到对应状态。
简单说来,从状态机更专注于对于字符的过滤和判断,主状态机专注于对于整个文本块的判断与过滤
//通过while循环 封装主状态机 对每一行进行循环处理
//此时 从状态机已经修改完毕 主状态机可以取出完整的行进行解析
http_conn::HTTP_CODE http_conn::process_read()
{
//初始化从状态机的状态
LINE_STATUS line_status = LINE_OK;
HTTP_CODE ret = NO_REQUEST;
char *text = 0;
//判断条件,这里就是从状态机驱动主状态机
while ((m_check_state == CHECK_STATE_CONTENT && line_status == LINE_OK) || ((line_status = parse_line()) == LINE_OK))
{
text = get_line();
//m_start_line 是每一个数据行在m_read_buf中的起始位置
//m_checked_idx 表示从状态机在m_read_buf中的读取位置
m_start_line = m_checked_idx;
LOG_INFO("%s", text);
//三种状态转换逻辑
switch (m_check_state)
{
case CHECK_STATE_REQUESTLINE:
{
//解析请求行
ret = parse_request_line(text);
if (ret == BAD_REQUEST)
return BAD_REQUEST;
break;
}
case CHECK_STATE_HEADER:
{
//解析请求头
ret = parse_headers(text);
if (ret == BAD_REQUEST)
return BAD_REQUEST;
//作为get请求 则需要跳转到报文响应函数
else if (ret == GET_REQUEST)
{
return do_request();
}
break;
}
case CHECK_STATE_CONTENT:
{
//解析消息体
ret = parse_content(text);
//对于post请求 跳转到报文响应函数
if (ret == GET_REQUEST)
return do_request();
//更新 跳出循环 代表解析完了消息体
line_status = LINE_OPEN;
break;
}
default:
return INTERNAL_ERROR;
}
}
return NO_REQUEST;
}
parse_request_line函数
对于一行进行解析
//解析http请求行,获得请求方法,目标url及http版本号
http_conn::HTTP_CODE http_conn::parse_request_line(char *text)
{
//请求行中最先含有空格和\t任一字符的位置并返回
m_url = strpbrk(text, " \t");
//没有目标字符 则代表报文格式有问题
if (!m_url)
{
return BAD_REQUEST;
}
//用于将前面的数据取出
*m_url++ = '\0';
//取出数据 确定请求方式
char *method = text;
if (strcasecmp(method, "GET") == 0)
m_method = GET;
else if (strcasecmp(method, "POST") == 0)
{
m_method = POST;
cgi = 1;
}
else
return BAD_REQUEST;
//m_url此时跳过了第一个空格或者\t字符,但是后面还可能存在
//不断后移找到请求资源的第一个字符
m_url += strspn(m_url, " \t");
//判断http的版本号
m_version = strpbrk(m_url, " \t");
if (!m_version)
return BAD_REQUEST;
*m_version++ = '\0';
m_version += strspn(m_version, " \t");
//目前社长项目仅支持http1.1
if (strcasecmp(m_version, "HTTP/1.1") != 0)
return BAD_REQUEST;
//对请求资源的前七个字符进行判断
//对某些带有http://的报文进行单独处理
if (strncasecmp(m_url, "http://", 7) == 0)
{
m_url += 7;
m_url = strchr(m_url, '/');
}
//https的情况
if (strncasecmp(m_url, "https://", 8) == 0)
{
m_url += 8;
m_url = strchr(m_url, '/');
}
//不符合规则的报文
if (!m_url || m_url[0] != '/')
return BAD_REQUEST;
//当url为/时,显示欢迎界面
if (strlen(m_url) == 1)
strcat(m_url, "judge.html");
//主状态机状态转移
m_check_state = CHECK_STATE_HEADER;
return NO_REQUEST;
}
总结
其实如果你能理解http部分的状态机与整个调用流程,http没有很难理解的地方。他主要就是解析。这里给出详细注释的头文件,方便你读懂代码
如果你对http的工作逻辑不懂,参考我的博客:从零开始:编写一个Web服务器—HTTP部分详细讲解以及代码实现(一)
#ifndef HTTPCONNECTION_H
#define HTTPCONNECTION_H
#include <unistd.h>
#include <signal.h>
#include <sys/types.h>
#include <sys/epoll.h>
#include <fcntl.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <sys/stat.h>
#include <string.h>
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <stdarg.h>
#include <errno.h>
#include <sys/wait.h>
#include <sys/uio.h>
#include <map>
#include "../lock/locker.h"
#include "../CGImysql/sql_connection_pool.h"
#include "../timer/lst_timer.h"
#include "../log/log.h"
//激发http连接数 最大数量对应于最大fd
class http_conn
{
public:
//设置读取文件的名称m_real_file大小
static const int FILENAME_LEN = 200;
//设置读缓冲区m_read_buf大小
static const int READ_BUFFER_SIZE = 2048;
//设置写缓冲区m_write_buf大小
static const int WRITE_BUFFER_SIZE = 1024;
//报文的请求方法,本项目只用到GET和POST
enum METHOD
{
GET = 0,
POST,
HEAD,
PUT,
DELETE,
TRACE,
OPTIONS,
CONNECT,
PATH
};
//主状态机的状态
enum CHECK_STATE
{
CHECK_STATE_REQUESTLINE = 0,
CHECK_STATE_HEADER,
CHECK_STATE_CONTENT
};
//报文解析的结果
enum HTTP_CODE
{
NO_REQUEST,
GET_REQUEST,
BAD_REQUEST,
NO_RESOURCE,
FORBIDDEN_REQUEST,
FILE_REQUEST,
INTERNAL_ERROR,
CLOSED_CONNECTION
};
//从状态机的状态
enum LINE_STATUS
{
LINE_OK = 0,
LINE_BAD,
LINE_OPEN
};
public:
http_conn() {}
~http_conn() {}
public:
//初始化套接字地址,函数内部会调用私有方法init
void init(int sockfd, const sockaddr_in &addr, char *, int, int, string user, string passwd, string sqlname);
//关闭http连接
void close_conn(bool real_close = true);
//主从状态机 报文解析
void process();
//读取浏览器端发来的全部数据
bool read_once();
//响应报文写入函数
bool write();
sockaddr_in *get_address()
{
return &m_address;
}
//同步线程初始化数据库读取表
void initmysql_result(connection_pool *connPool);
int timer_flag;
int improv;
private:
void init();
//从m_read_buf读取,并处理请求报文
HTTP_CODE process_read();
//向m_write_buf写入响应报文数据
bool process_write(HTTP_CODE ret);
//主状态机解析报文中的请求行数据
HTTP_CODE parse_request_line(char *text);
//主状态机解析报文中的请求头数据
HTTP_CODE parse_headers(char *text);
//主状态机解析报文中的请求内容
HTTP_CODE parse_content(char *text);
//生成响应报文
HTTP_CODE do_request();
//m_start_line是已经解析的字符
//get_line用于将指针向后偏移,指向未处理的字符
char *get_line() { return m_read_buf + m_start_line; };
//从状态机读取一行,分析是请求报文的哪一部分
LINE_STATUS parse_line();
//申请IO映射
void unmap();
//根据响应报文格式,生成对应8个部分,以下函数均由do_request调用
bool add_response(const char *format, ...);
bool add_content(const char *content);
bool add_status_line(int status, const char *title);
bool add_headers(int content_length);
bool add_content_type();
bool add_content_length(int content_length);
bool add_linger();
bool add_blank_line();
public:
static int m_epollfd;
static int m_user_count;
MYSQL *mysql;
int m_state; //读为0, 写为1
private:
int m_sockfd;
sockaddr_in m_address;
//存储读取的请求报文数据
char m_read_buf[READ_BUFFER_SIZE];
//缓冲区中m_read_buf中数据的最后一个字节的下一个位置
int m_read_idx;
//m_read_buf读取的位置m_checked_idx
int m_checked_idx;
//m_read_buf中已经解析的字符个数
int m_start_line;
//存储发出的响应报文数据
char m_write_buf[WRITE_BUFFER_SIZE];
//指示buffer中的长度
int m_write_idx;
//主状态机的状态
CHECK_STATE m_check_state;
//请求方法
METHOD m_method;
//以下为解析请求报文中对应的6个变量
//存储读取文件的名称
char m_real_file[FILENAME_LEN];
char *m_url;
char *m_version;
char *m_host;
int m_content_length;
bool m_linger;
char *m_file_address; //读取服务器上的文件地址
struct stat m_file_stat;
struct iovec m_iv[2]; //io向量机制iovec
int m_iv_count;
int cgi; //是否启用的POST
char *m_string; //存储请求头数据
int bytes_to_send;//剩余发送字节数
int bytes_have_send; //已发送字节数
char *doc_root;
map<string, string> m_users;
int m_TRIGMode;
int m_close_log;
char sql_user[100];
char sql_passwd[100];
char sql_name[100];
};
#endif