1、PySpark的编程模型
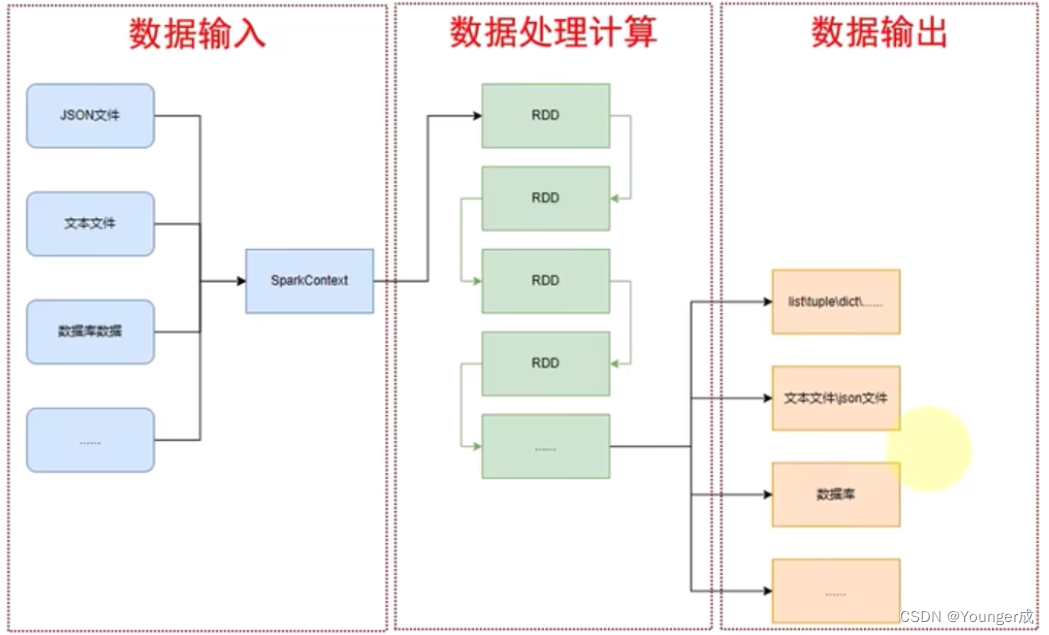
分三个模块:
数据输入:通过SparkContext对象,完成数据输入
数据处理计算:输入数据后得到RDD对象,对RDD对象的成员方法进行迭代计算
数据输出:最后通过RDD对象的成员方法,完成数据输出,将结果输出到list、元组、字典、文本文件、数据库等
2、如何安装PySpark库
pip install pyspark
注:sprak支持环境变量,通过入参告诉spark,python在哪里
3、为什么要构建SparkContext对象作为执行入口
PySaprk的功能都是从SparkContext对象作为开始入口
4、算子
PySpark的数据计算,都是基于RDD对象来进行的,RDD对象内置丰富的成员方法(算子)
1、map算子
功能:map算子,是将RDD的数据一条条处理(处理的逻辑基于map算子种接收的处理函数),返回新的RDD对于返回值是新RDD的算子,可以通过链式调用的方法多次调用算子

2、flatMap算子
功能:对rdd执行map操作,然后进行解除嵌套操作

func:(T)->U:传入参数有一个,最少一个返回值
func:(V,V)-> V :接受两个传入参数,返回一个返回值,类型和传入参数一致
3、reduceByKey算子
功能:针对KV型RDD,自动按照key分组,对组内的数据进行两两计算,然后根据你提供的聚合逻辑,完成组内数据的聚合操作
注:reduceByKey中接收的函数,只负责聚合,不理会分组

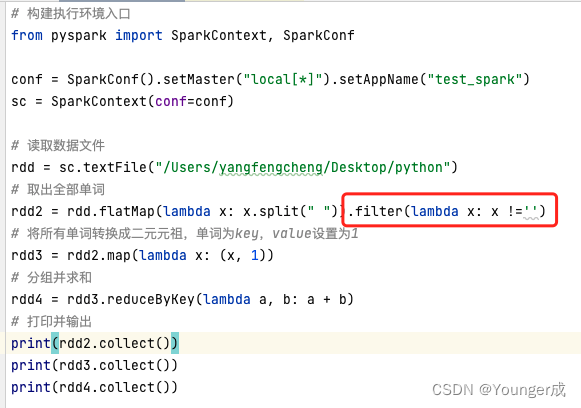
4 、filter算子
功能:过滤器,接收一个处理函数,用lambda编写
5、distinct算子(无需传参)
功能:对RDD的数据进行去重,返回新的RDD
6、sortBy算子
功能:对RDD数据进行排序,基于你指定的排序一句
rdd.sortBy(func,ascending=False,numPartitions=1)
func:(T)->U :告知rdd中按照哪个进行排序,比如lambda x:x[1],表示按照rdd的第二列元素进行排序
ascending True 升序 False降序
numPartiontions:用多少分区排序

输出数据
7、collect算子
功能:将 RDD各个分区内的数据,统一收集到Driver中,形成一个List对象
用法:rdd.collect(),返回值是一个list
8、reduce算子
功能:对RDD数据集按照你传入的逻辑进行聚合
rdd.reduce()
# func:(T,T)-> T
# 2参数传入 1个返回值,返回值和参数类型要求类型一致
9、take算子
功能:将RDD的前n个元素,组合成list返回
10、count算子
功能:统计RDD元素的个数