0. 前言
本文主要记录课程《自动驾驶预测与决策技术》的学习过程,难免会有很多纰漏,感谢指正。
课程链接:https://www.shenlanxueyuan.com/my/course/700
相关笔记链接:
Part1_自动驾驶决策规划简介
Part2_基于模型的预测方法
Part3_路径与轨迹规划
Part4_时空联合规划
Part5_决策过程
Part6_不确定性感知的决策过程
Part7_数据驱动的预测方法
该章节主要以论文讲解为主,未仔细阅读论文原文,仅借助PPT与ChatGpt进行资料整理与记录,对应的论文链接均已附上链接。
规划方法Review
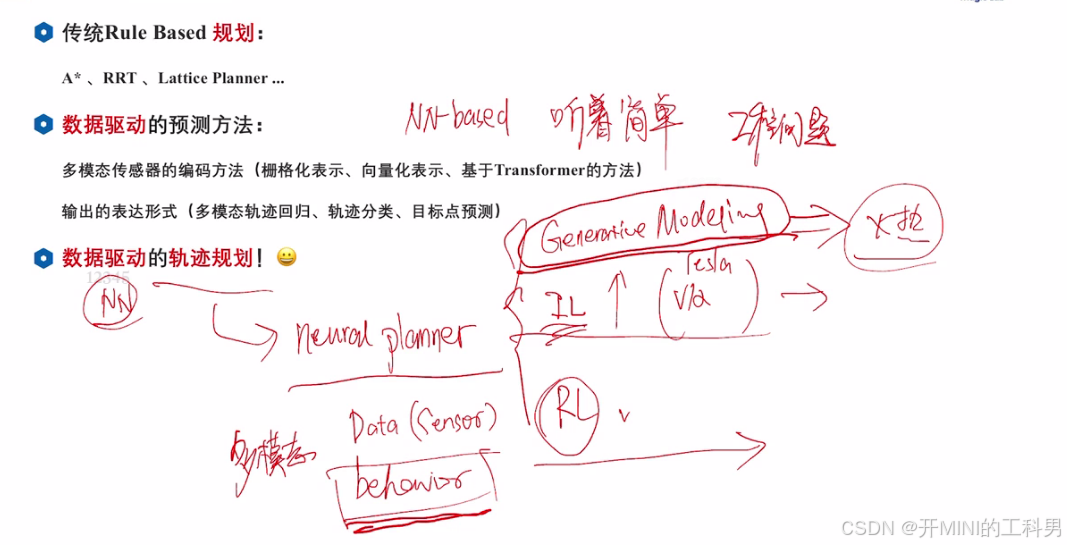
传统Rule Based 规划:
- 三板斧:采样、搜索、优化
数据驱动的轨迹规划:
- 生成模型、模仿学习、强化学习
1.生成模型
1.1 Diffusion-ES
1. Diffusion-ES算法介绍
参考链接:

Diffusion-ES(Diffusion Evolutionary Search) 是一种基于扩散模型和采样优化的轨迹生成与优化方法,特别适用于自动驾驶任务中的复杂场景。
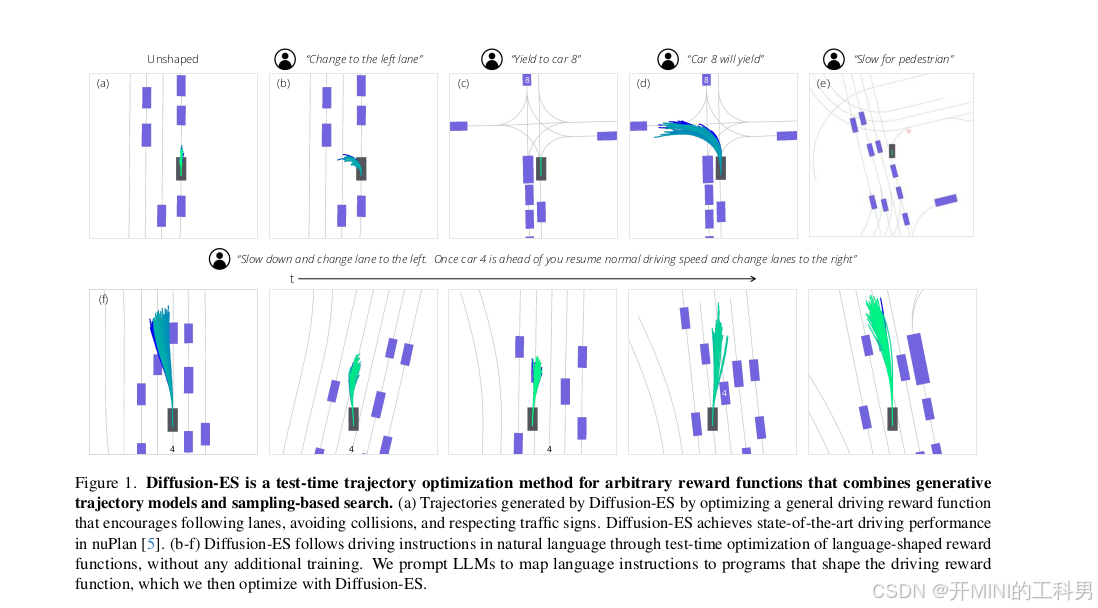
Diffusion-ES 的实现
-
整体描述:
- 图中展示了 Diffusion-ES 在不同场景下生成的驾驶轨迹,包括车道变更、礼让、减速避障等任务。
- 方法特点:
- 测试时优化(Test-Time Optimization):直接在推理阶段对轨迹进行优化。
- 零训练需求:无需额外训练模型,只需一个扩散生成模型和一个黑盒奖励函数。
- 语言指导:可以通过自然语言指令定义目标(如“切换到左车道”),然后将语言指令映射为奖励函数。
-
Diffusion-ES 的工作步骤:
- Step 1: 采样轨迹
- 利用扩散模型生成初始轨迹分布,确保轨迹处于真实数据分布的流形上。
- Step 2: 评估轨迹
- 使用黑盒奖励函数对生成的轨迹评分(如安全性、目标达成度等)。
- Step 3: 改进轨迹
- 对高分轨迹进行噪声与去噪(扩散过程的一部分),从而优化轨迹,探索潜在的更优解。
- Step 1: 采样轨迹
具体场景解析
-
(a) 未引导(Unshaped)
- 生成的轨迹仅基于基础奖励函数(如车道保持、避障等),没有特殊目标引导。
- 轨迹展现为安全、符合交通规则的路径。
-
(b) 指令:切换到左车道(“Change to the left lane”)
- Diffusion-ES 接收语言指令,将其转换为“切换车道”的目标奖励函数。
- 生成轨迹显示车辆从当前车道逐步切换到左车道。
-
© 指令:礼让车辆 8(“Yield to car 8”)
- 通过礼让规则构建奖励函数,车辆生成的轨迹表现为在车辆 8 通过后再进入目标路径。
- 突出了 Diffusion-ES 对交互行为建模的能力。
-
(d) 指令:车 8 会礼让(“Car 8 will yield”)
- 奖励函数假设车 8 会礼让,生成的轨迹引导自车在不停车的情况下通过交叉口。
- 显示对动态环境中不确定性的合理处理。
-
(e) 指令:减速避让行人(“Slow for pedestrian”)
- 扩散模型生成的轨迹表现为自车减速,礼让行人后再继续行驶。
- 显示出对安全性的优化。
-
(f) 场景:组合指令
- 复杂任务中,例如“在车辆 4 前减速,之后变道”,Diffusion-ES 根据指令生成分步优化轨迹。
- 这种场景突出方法在复杂多目标任务中的适用性。
Diffusion-ES 的关键优势
-
灵活性:
- 可处理复杂场景(如车辆交互、避障、语言引导);
- 支持非可微目标(如语言奖励)。
-
效率:
- 结合扩散模型的采样与进化优化,生成轨迹的同时进行优化,提高计算效率。
-
泛化性:
- 零训练需求,可以直接应用于新场景;
- 可结合大型语言模型(LLMs)处理零样本或少样本任务。
-
多模态能力:
- 生成多条备选轨迹,涵盖不同的可能性,特别适用于不确定性环境。
2. Diffusion-ES算法具体流程
Diffusion Model 是什么?
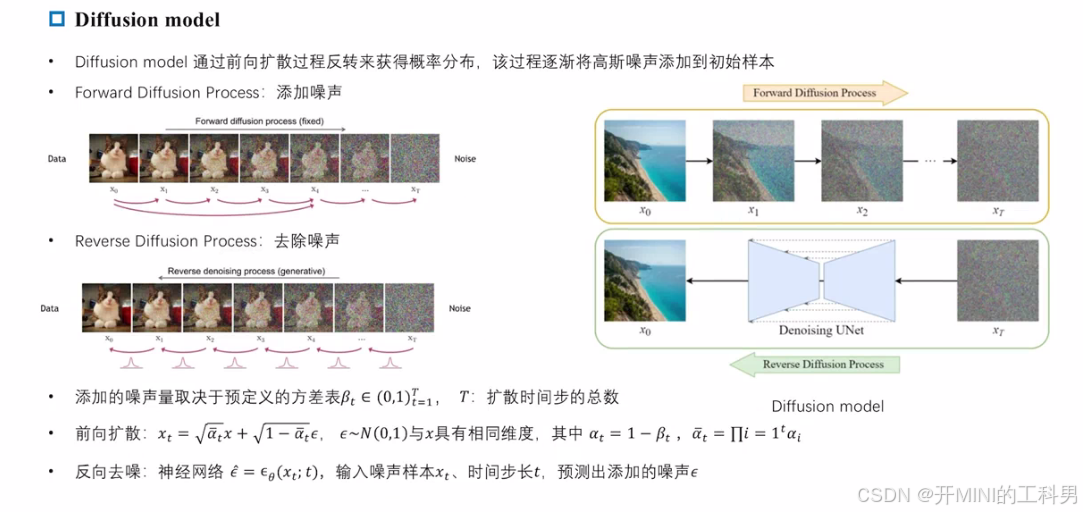
扩散模型是一种生成模型,通过模拟数据逐步添加和去除噪声的过程,从而学习复杂数据分布。它包括 前向扩散过程 和 反向扩散过程 两个阶段,用于分别破坏和生成数据。以下是具体解释:
核心概念
-
前向扩散过程 (Forward Diffusion Process)
- 在前向过程中,逐步向原始数据添加高斯噪声,使数据分布逐渐接近随机噪声的分布。
- 数学描述:
对于每一步 ( t ) ( t ) (t),输入数据 ( x 0 ) ( x_0 ) (x0) 转化为 ( x t ) ( x_t ) (xt),公式为:
x t = α t x 0 + 1 − α t ϵ , ϵ ∼ N ( 0 , 1 ) x_t = \sqrt{\alpha_t} x_0 + \sqrt{1 - \alpha_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, 1) xt=αtx0+1−αtϵ,ϵ∼N(0,1)
其中:- ( α t = 1 − β t ) ( \alpha_t = 1 - \beta_t ) (αt=1−βt),表示噪声的权重,取决于时间步长 ( t ) ( t ) (t);
- ( β t ) ( \beta_t ) (βt) 是预定义的噪声添加强度参数。
- 随着 ( t ) ( t ) (t) 增加,数据逐渐丧失原始信息,最终变为纯随机噪声。
-
反向扩散过程 (Reverse Diffusion Process)
- 从完全被噪声破坏的分布开始,逐步去噪,恢复到原始数据。
- 去噪的核心是使用神经网络(如 UNet)预测噪声并移除它,从而生成新的数据样本。
- 数学描述:
通过神经网络 ( ϵ θ ( x t , t ) ) ( \epsilon_\theta(x_t, t) ) (ϵθ(xt,t)) 预测添加的噪声 ( ϵ ) ( \epsilon ) (ϵ),然后从 ( x t ) ( x_t ) (xt) 计算得到更接近原始数据分布的 ( x t − 1 ) ( x_{t-1} ) (xt−1)。
在自动驾驶的轨迹规划中,可以将扩散模型的前向扩散过程和反向扩散过程类比为以下两个阶段:
前向扩散过程类比:轨迹的逐步扰动
-
逐渐加入随机性
- 在轨迹规划中,前向扩散过程对应于从一个确定的轨迹逐渐加入扰动,使轨迹变得随机化,探索更多潜在的可能路径。
- 类比于图片逐渐变糊的过程,轨迹逐渐偏离原始的清晰路径,变为一组“模糊的”轨迹候选。
-
意图的模糊化
- 原始轨迹可能明确表达车辆的运动意图(如直行、换道等),但在添加噪声后,这些意图被模糊化,形成一组多样化但接近于真实分布的候选轨迹。
- 目的是模拟现实中各种复杂的驾驶环境和随机性,提供多样化的选择。
反向扩散过程类比:轨迹的逐步优化
-
逐步去除随机性
- 反向扩散过程对应于逐步从随机轨迹候选集中去除不合理的偏差,逐渐趋向清晰和可行的轨迹。
- 类似于图片从模糊变清晰的过程,轨迹逐渐显现出明确的目标意图(如安全通过、礼让行人等)。
-
结合奖励函数进行优化
-
在每一步去噪中,结合黑箱奖励函数对轨迹进行打分(如是否符合交通规则、避障要求等),剔除低分轨迹,只保留高分轨迹。
-
每一步优化后,轨迹不仅更加合理,还逐渐靠近驾驶任务的要求,比如安全性、效率和用户指令(如“换到左车道”)。
-
最终,反向扩散过程生成一条或多条高质量的驾驶轨迹,能够满足规划要求(如避障、换道、减速等),且在可行性和现实性上达到平衡。
-
结合具体实例类比
-
图片逐渐变模糊 → 轨迹逐渐随机化
扩散模型在图片生成中,逐渐加入噪声使图片失去原始的清晰度;对应到轨迹规划中,逐渐加入扰动使轨迹不再精确,但保留了原始轨迹的分布特性。 -
图片逐渐变清晰 → 轨迹逐渐优化
在图片生成中,反向扩散逐步去噪使图片恢复清晰;在轨迹规划中,反向扩散逐步优化轨迹,将其从多样性中提炼出满足驾驶意图的最优轨迹。
在自动驾驶中,利用扩散模型进行轨迹规划可以:
- 探索全局最优解:通过随机化轨迹进行全局探索,避免陷入局部最优。
- 生成多样性:模拟复杂驾驶场景中的多种可能行为。
- 结合奖励函数优化:确保轨迹在安全性、规则性和驾驶意图等方面符合需求。
Diffusion-ES: Evolutionary Strategies

Diffusion-ES Method
1. 初始轨迹生成(Initial proposals (x^0))
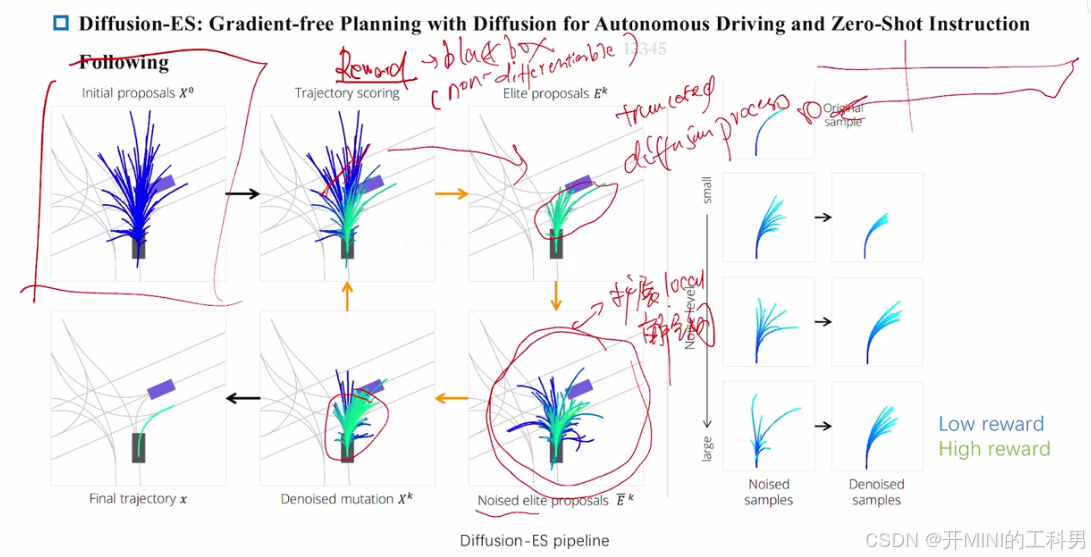

- 扩散模型首先从其生成的潜在分布中采样一组初始轨迹。
- 这些轨迹分布在可能的行动空间中,体现了生成模型对数据分布的学习结果。
2. 轨迹打分(Trajectory scoring)
- 利用黑箱奖励函数对每条轨迹进行评估,根据设定的目标(如安全性、交通规则遵守情况等)计算分数。
- 低分轨迹被淘汰,高分轨迹被保留。
- 奖励函数的引入使得扩散模型可以在无梯度信息的情况下优化复杂目标,如语言指令或非显式目标。
3. 精英轨迹选择(Elite proposals (E^k))
-
根据奖励函数得分选择一组“精英轨迹”,即得分较高的轨迹作为下一阶段的优化起点 --> 扩展局部解空间。
-
中间部分,精英轨迹集中在靠近理想驾驶路径的区域(深蓝色)。
4. 轨迹扰动与去噪(Noised elite proposals 和 Denoised mutation (x^k))
- 对选出的精英轨迹加入一定的随机噪声(noised samples),使轨迹变得稍微偏离原始分布,便于探索更多可能的解决方案。
- 扩散模型通过反向去噪过程,将加入噪声的轨迹“修复”回合理分布内,生成一组改进后的轨迹(denoised mutation)。
5. 最终轨迹选择(Final trajectory (x))
- 根据多轮迭代后的优化结果,选取最终轨迹作为车辆的执行路径。
- 这条路径既符合奖励函数目标(如避障、换道),又能保持合理的车辆行为。
Diffusion-ES Mapping Language instructions to reward functions with LLM prompting

自然语言指令
图中的自然语言指令是:
“Slow down and change lane to the left. Once car 4 is ahead of you, resume normal driving speed and change lanes to the right.”
这是一条复合指令,包含多个步骤:
- 减速并变道到左侧车道。
- 等待“车辆 4”超车后恢复正常车速。
- 随后变道回到右侧车道。
转换为奖励函数
-
语言模型生成伪代码
- 指令被输入到LLM中,模型生成了逻辑化的伪代码,表示每个子任务的具体逻辑。
- 伪代码结构:
- 监测当前速度
current_speed,根据需要调整速度(例如减速到 50%)。 - 调用
add_lane_follow_reward()等函数,为变道到左车道的行为添加奖励。 - 定义逻辑判断,当“车4”超车后触发“恢复正常车速”和“变道到右车道”的奖励。
- 监测当前速度
- 代码解析:
current_speed = ego_vehicle.speed add_vel_reward(current_speed * 0.5) # 减速 lane = get_left_lane() add_lane_follow_reward(lane) # 激励进入左车道 while not reach_lane(lane): yield # 等待左车道变道完成 def vehicle_ahead_of_us(): vehicle = get_vehicle(4) return vehicle.is_ahead_of(ego_vehicle) while not vehicle_ahead_of_us(): yield # 等待车辆4超车 remove_vel_reward() # 恢复正常车速 lane = get_right_lane() add_lane_follow_reward(lane) # 激励进入右车道 while not reach_lane(lane): yield # 等待右车道变道完成
-
奖励函数的组合
- 每个子任务(减速、变道、超车、恢复车速)都被映射为一个奖励函数。
- 奖励函数根据车辆的行为评分,鼓励符合目标指令的轨迹。
轨迹生成与优化
-
轨迹示意图
- 图中展示了车辆的轨迹规划过程,蓝色轨迹表示可能的规划路径。
- 初始路径分布较广,通过奖励函数的逐步优化,筛选出符合指令的最优轨迹。
-
扩散过程结合奖励
- 初始轨迹(带噪声)通过扩散模型逐步去噪。
- 奖励函数对每条候选轨迹进行评分,符合“减速-左变道-超车-右变道”的轨迹得分更高。
- 最终输出一条最优轨迹(图中加粗的绿色线)。
上述展现了从自然语言到奖励函数的完整映射流程,以及如何通过奖励函数指导扩散模型优化轨迹。它使得自动驾驶系统能够灵活处理复杂的驾驶指令,同时确保生成的轨迹满足高层次目标。

1.2 UniGen驾驶场景生成
UniGen: Unified Modeling of Initial Agent States and Trajectories for Generating Autonomous Driving Scenarios
参考链接:
- UniGen: Unified Modeling of Initial Agent States and Trajectories for Generating Autonomous Driving Scenarios
- https://zhuanlan.zhihu.com/p/711013842
摘要:本文介绍了 UniGen,一种用于生成全新交通场景的方法,旨在通过仿真评估和改进自动驾驶软件。我们的方法将驾驶场景的所有元素统一建模,包括新增交通参与者的位置、初始状态以及未来的运动轨迹。通过从共享的全局场景嵌入中预测所有这些变量的分布,我们确保生成的最终场景能够完全基于现有场景的上下文进行条件约束。我们的统一建模方法结合自回归的代理注入机制,使得每个新增代理的位置和运动轨迹都依赖于所有现有代理及其轨迹,从而生成真实感强且碰撞率低的场景。实验结果表明,在 Waymo Open Motion Dataset 上,UniGen 的表现优于之前的最新研究成果。

如何大规模生成稀有长尾场景
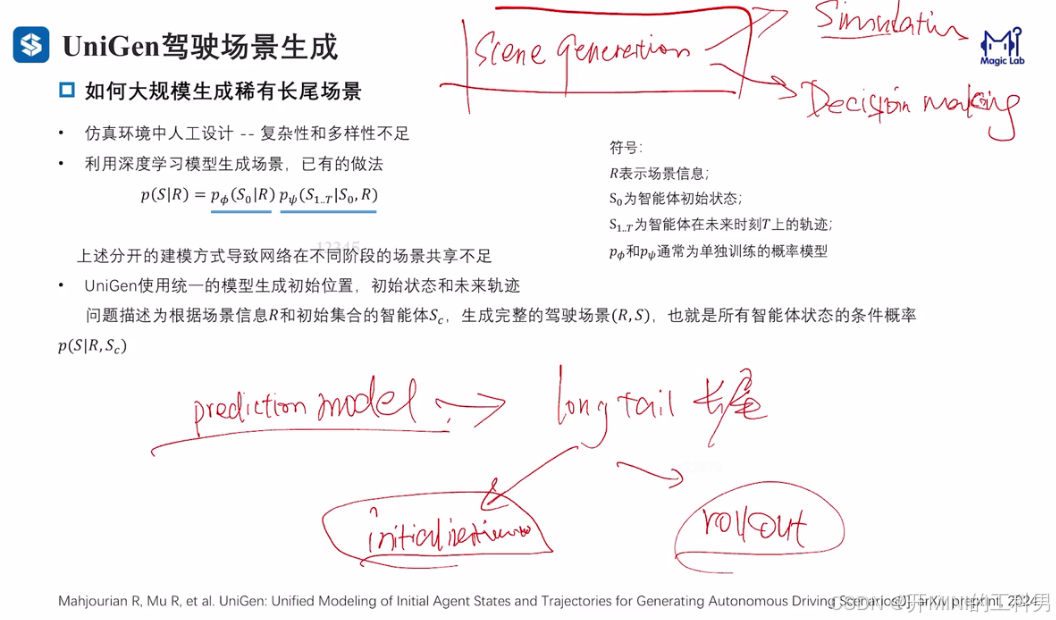
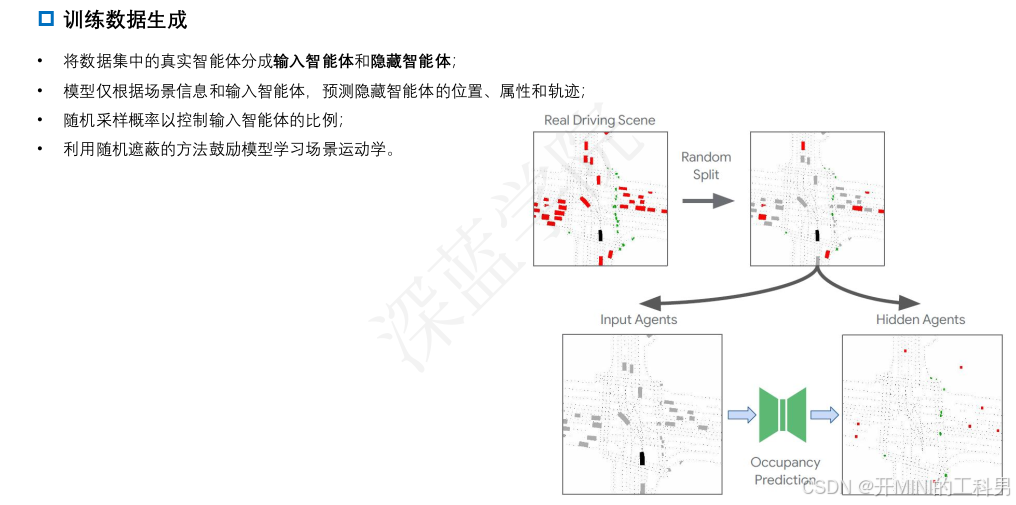
UniGen 架构
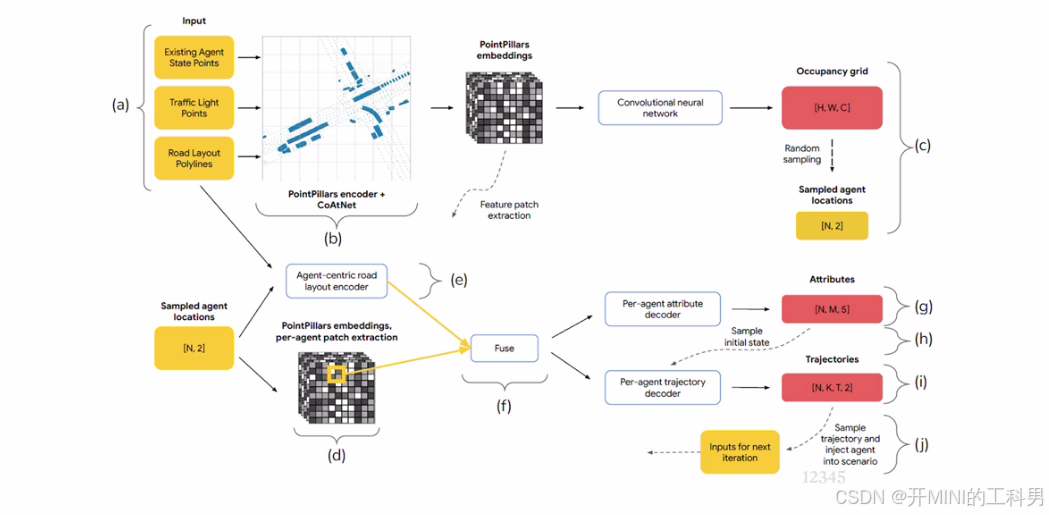
(a) 输入数据
- Existing Agent State Points:现有的交通参与者(车辆、行人等)状态,例如位置、速度等。
- Traffic Light Points:交通信号灯的信息。
- Road Layout Polylines:道路的几何布局数据,例如车道线、路口形状。
(b) 特征提取
点集被编码为密集的场景嵌入,三个解码器分别预测新智能体插入的占据分布、初始状态和未来轨迹。
- PointPillars Encoder + CoAtNet:
- 使用 PointPillars(用于点云数据)和 CoAtNet(结合卷积和注意力机制的网络)编码输入的空间特征。
- 输出的特征表示是一个包含空间信息的网格化嵌入,能捕捉道路布局、信号灯和参与者状态。
( c ) Occupancy Grid 和采样
占据解码器预测
C
C
C个类别智能体的初始位置分布。每轮迭代时从占据热力图中采样一个位置插入智能体。
- Occupancy Grid:
- 将场景嵌入到规则化的栅格( [ H , W , C ] [H, W, C] [H,W,C])中,每个单元格编码占用信息(如是否有车辆)。
- 随机采样:
- 在 Occupancy Grid 中随机采样交通参与者的位置,生成 Sampled Agent Locations(N 个 [x, y] 坐标)。
- 这些采样位置决定了新的交通参与者在场景中的位置。
(d) 每个采样代理的特征提取
新智能体的位置通过线性映射到密集场景嵌入的一个位置,提取其周围的特征块。
- Agent-Centric Patch Extraction:
- 根据采样的位置,从 PointPillars 嵌入中提取每个交通参与者的局部特征(以采样点为中心)。这些特征能描述采样位置附近的道路和环境信息。
(e-f) 融合与建模
- Agent-Centric Road Layout Encoder:
- 编码以代理为中心的道路几何特征,例如当前车道方向、邻近车道关系。
- 融合 (Fuse):
- 将提取的局部特征与道路几何特征融合,为每个agent提供更丰富的场景上下文信息。
(g) 生成初始状态(Attributes)
融合后的特征经过特征解码器预测为具备M个模态的5D多元混合分布(宽度,长度,单位方向向量,标量速度)
- Per-Agent Attribute Decoder:
- 对每个代理生成其初始属性(Attributes),包括:
- 速度、加速度、朝向等动态属性。
- 车辆类别(如轿车、卡车等)或行人类型。
- 对每个代理生成其初始属性(Attributes),包括:
(h) 初始状态采样(Sample initial state)
采样5维的属性数值,和智能体位置构成了完整的初始状态
(i) 生成轨迹(Trajectories)
轨迹解码器收到初始智能体状态和(f)中融合后的特征,预测K条时长为t的轨迹,每个轨迹点表示为2D高斯分布
- Per-Agent Trajectory Decoder:
- 根据初始属性和环境特征,为每个代理生成时间序列轨迹。
- 轨迹描述了每个agnet的未来运动行为(如加速、转弯等)。
(j) 场景迭代
从K个选择中采样单条轨迹,至此完成了新智能体的构建,新的智能体被加入场景输入(a),开始新一轮迭代
- 场景注入与迭代:
- 将生成的轨迹注入到当前场景中,更新场景状态。
- 继续采样和生成新代理的轨迹,构建更复杂的驾驶场景。
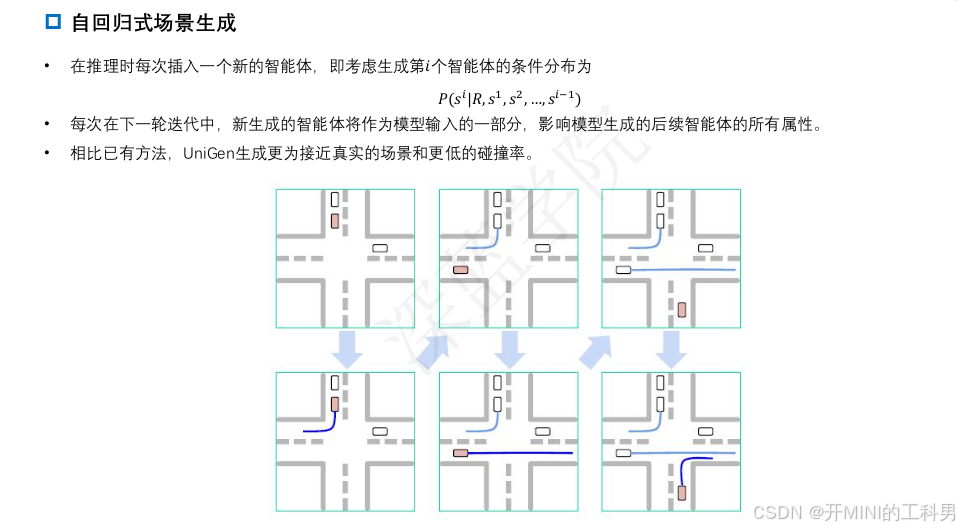
自回归式场景生成
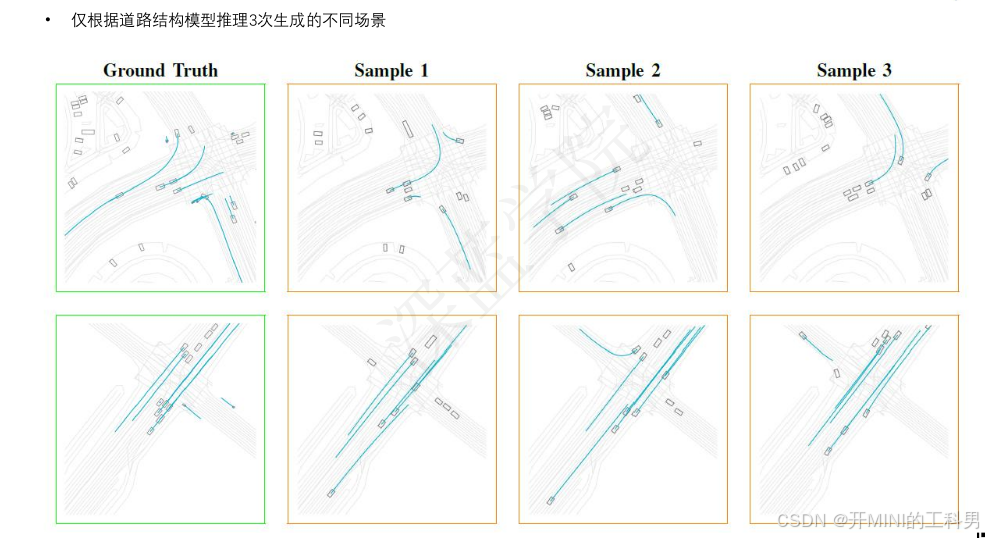
1.3 GenAD生成式端到端自动驾驶
GenAD: Generative End-to-End Autonomous Driving
参考链接:GenAD: Generative End-to-End Autonomous Driving
- GenAD: Generative End-to-End Autonomous Driving
- https://github.com/wzzheng/GenAD
- 【E2E】【笔记】GenAD: Generative End-to-End Autonomous Driving
- (E2E论文阅读)GenAD:Generative End-to-End Autonomous Driving
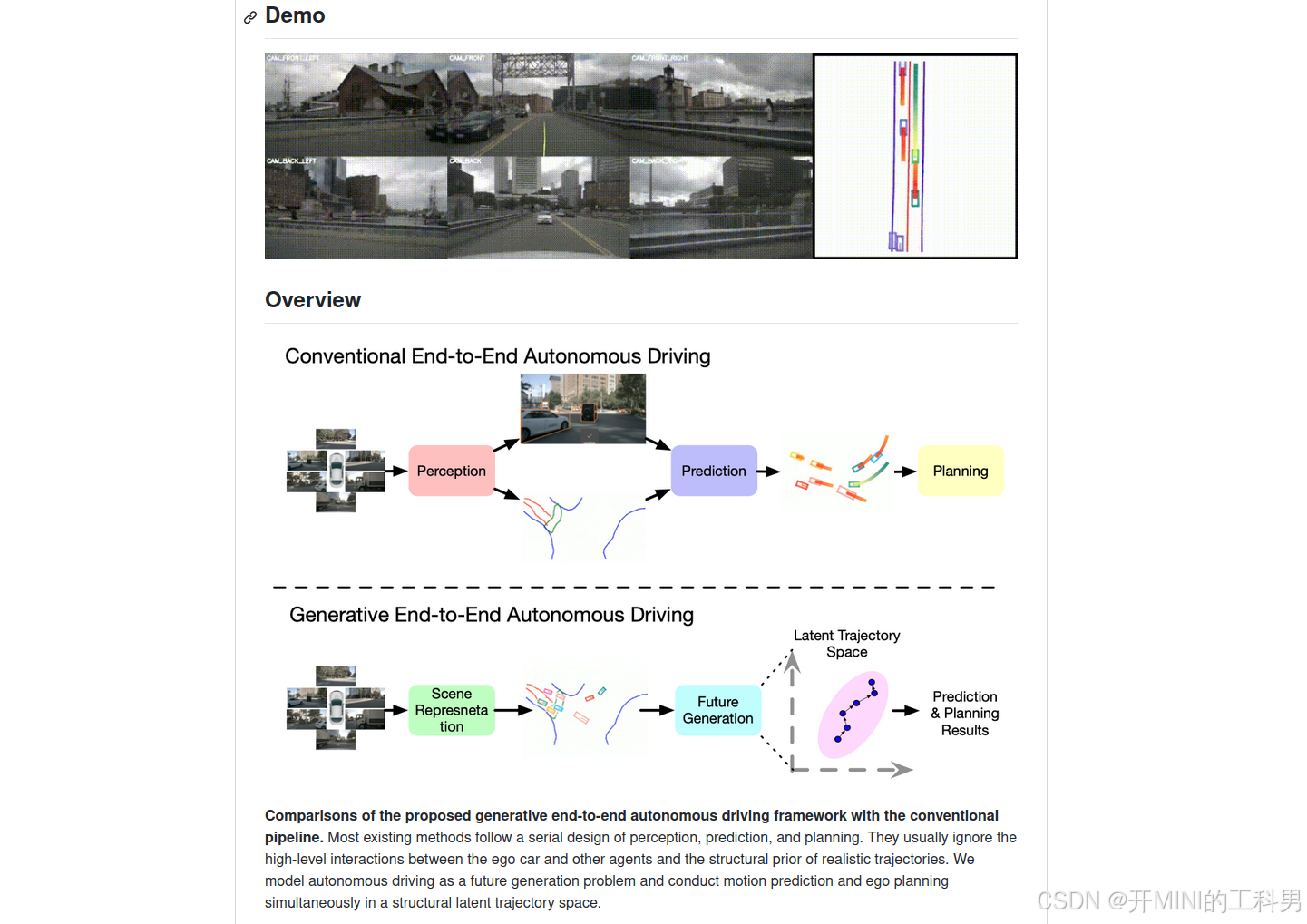
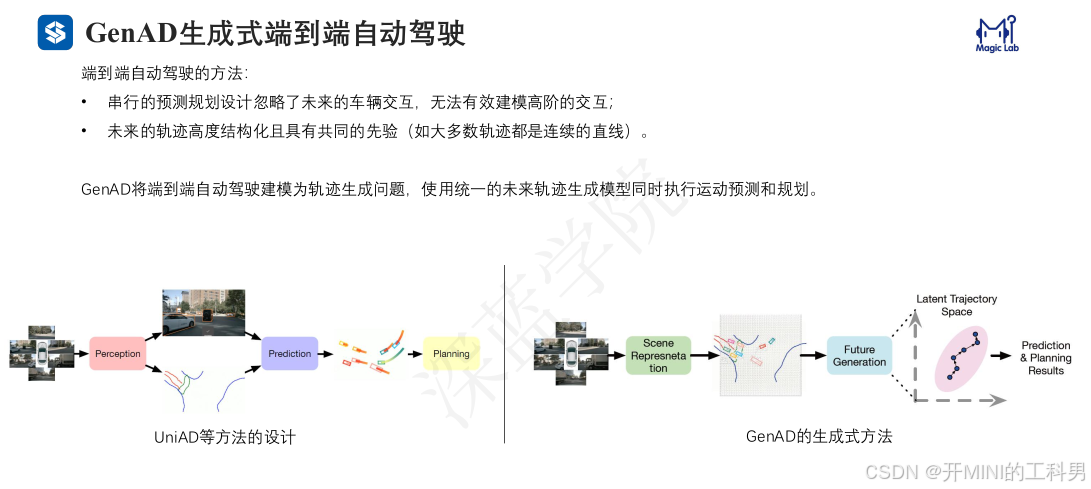
对比提出的生成式端到端自动驾驶框架与传统流水线方法。大多数现有方法采用感知、预测和规划的串行设计,通常忽略了自车与其他交通参与者之间的高级交互以及现实轨迹中的结构性先验信息。GenAD将自动驾驶建模为一个未来生成问题,在一个结构化的潜在轨迹空间中同时进行运动预测和自车规划。
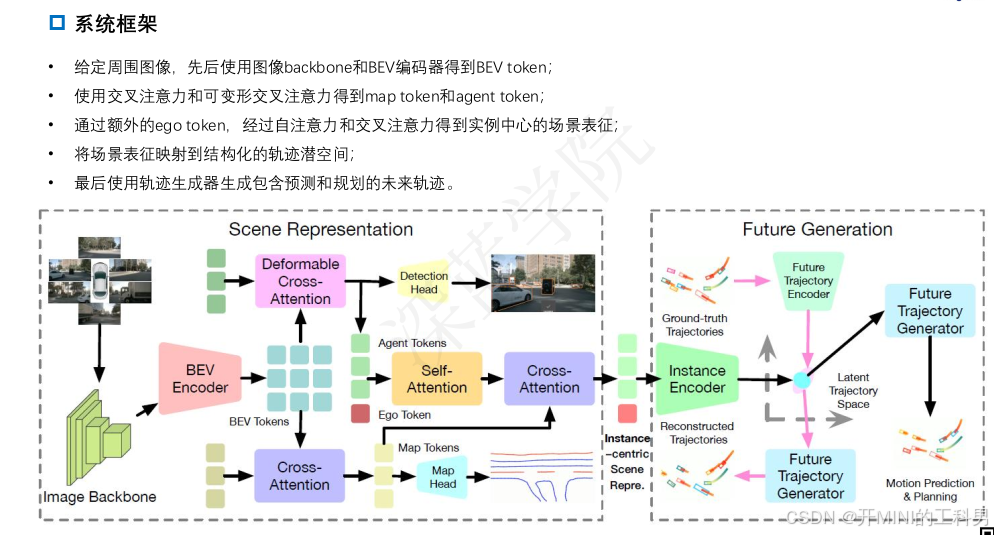



1.4 生成模型总结

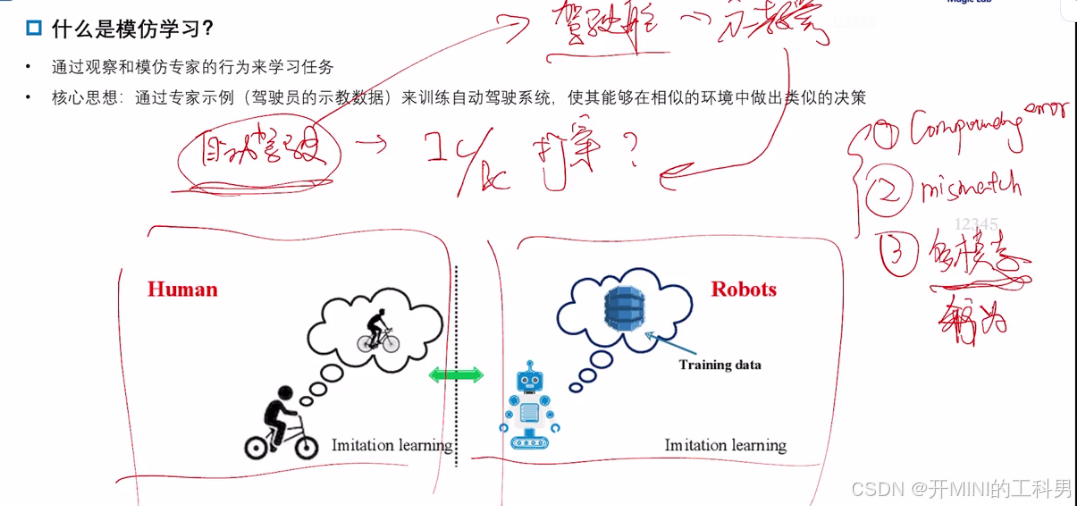
2.模仿学习
什么是模仿学习
2.1 QuAD:Query-based Interpretable Neural Motion Planning for Autonomous Driving
QuAD 算法简介
参考文献:
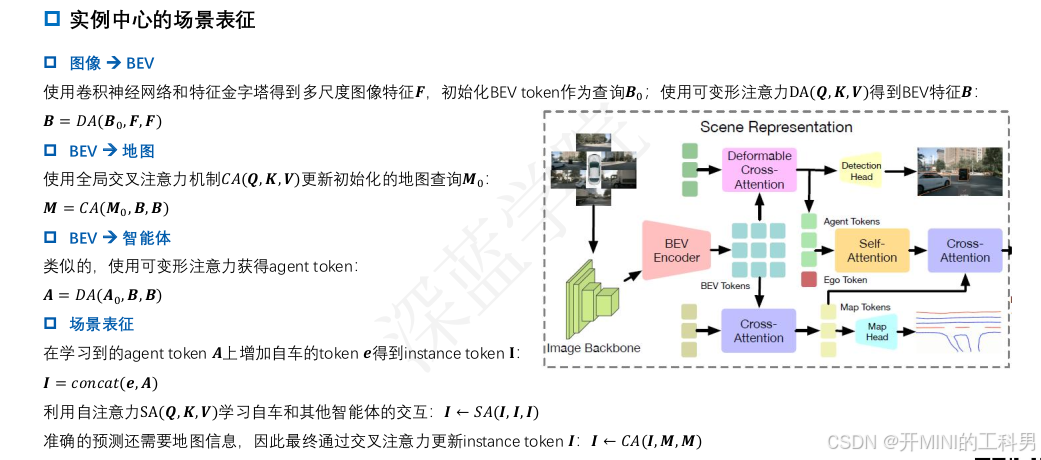
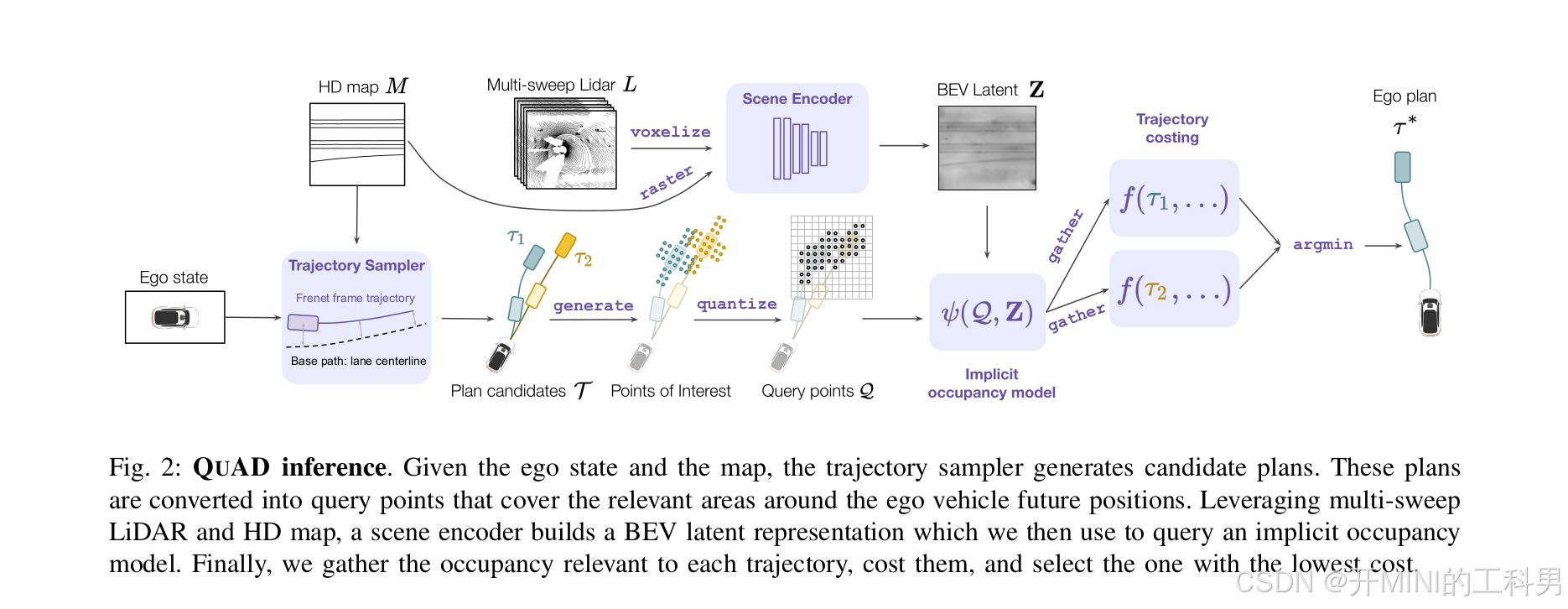
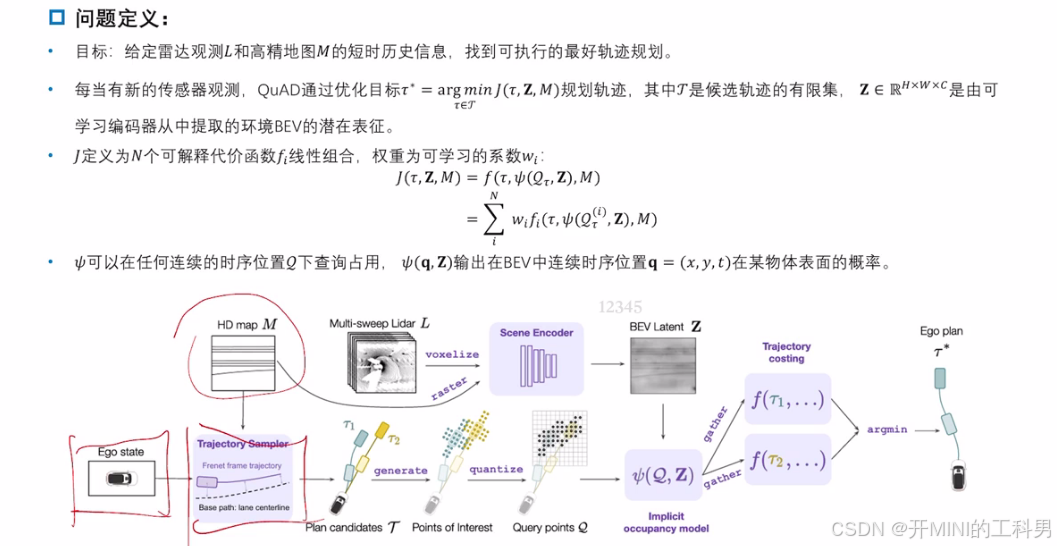
QuAD 提出了一种 基于查询(Query-based) 的运动规划方法,将运动规划问题建模为一种交互式查询任务。其目标是生成高效且安全的驾驶行为,同时提供模型决策的可解释性。这种方法通过直接从环境信息中生成驾驶轨迹,并结合查询机制,解释环境中各要素(如其他车辆、障碍物)对决策的影响

1. 输入部分
- 自车状态 (Ego State):
提供当前自车的位置、速度等动态信息,用于生成候选轨迹。 - 高清地图 (HD Map):
包括道路结构、车道线、交通标志等环境约束信息。 - 多帧 LiDAR 点云 (Multi-sweep LiDAR):
表示环境中动态和静态障碍物,用于构建场景表示。
2. 场景编码器 (Scene Encoder)
- LiDAR 点云被 体素化 (Voxelize) 并 栅格化 (Raster),与高清地图信息结合。
- 使用一个场景编码器生成基于鸟瞰图 (BEV, Bird’s Eye View) 的潜在特征表示
(
Z
)
( Z )
(Z)。
这个潜在表示编码了场景中的空间关系、障碍物信息以及动态元素。
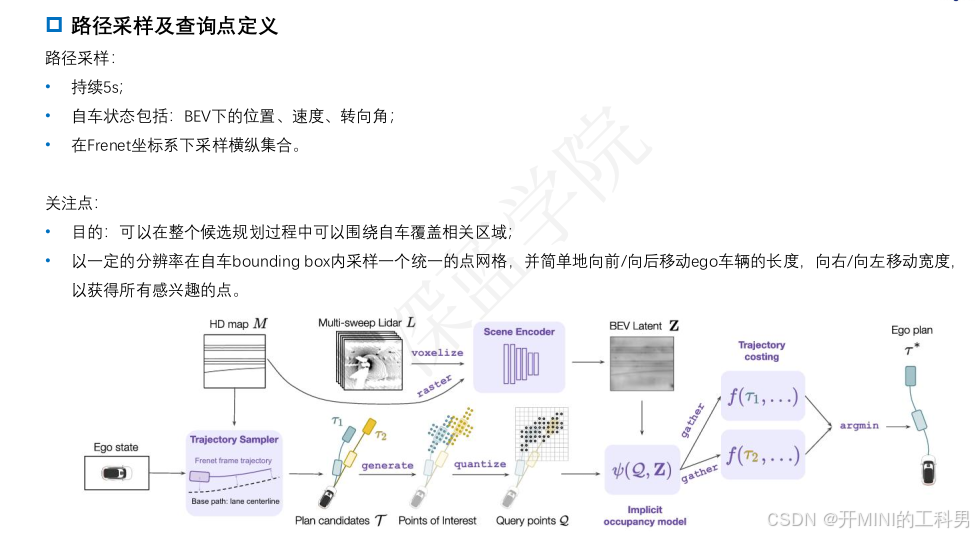
3. 候选轨迹生成 (Trajectory Sampler)
- 基于自车状态和车道中心线,生成多条候选轨迹 ( T ) ( \mathcal{T}) (T)(例如 ( τ 1 , τ 2 ) ( \tau_1, \tau_2 ) (τ1,τ2))。
- 每条轨迹用Frent坐标系 (Frenet Frame) 表示,确保与道路几何对齐。
4. 查询点生成 (Query Points)
- 沿着每条候选轨迹
(
τ
i
)
( \tau_i)
(τi),在轨迹覆盖的区域生成离散的查询点集合
(
Q
)
( Q )
(Q)。
查询点代表轨迹上与环境交互的关键位置。 - 通过量化 (Quantize) 处理,确保查询点分布均匀且与轨迹结构一致。
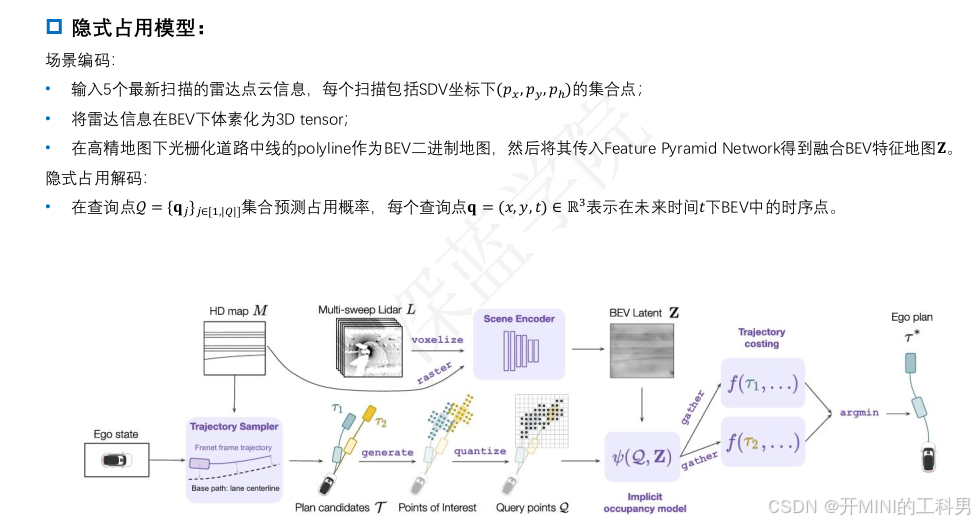
5. 隐式占据模型 (Implicit Occupancy Model)
- 结合查询点
(
Q
)
( Q )
(Q) 和场景的 BEV 潜在特征
(
Z
)
( Z )
(Z),隐式占据模型
(
ψ
(
Q
,
Z
)
)
( \psi(Q, Z) )
(ψ(Q,Z)) 对每条轨迹执行环境交互评估:
- 检测轨迹是否会碰撞、进入危险区域,或违反约束条件。
- 输出与每条轨迹相关的占据分数或代价。
6. 轨迹代价计算 (Trajectory Costing)
- 基于隐式占据模型的输出 ( f ( τ i ) ) ( f(\tau_i) ) (f(τi)),对所有候选轨迹计算代价函数。
- 代价函数综合考虑碰撞风险、轨迹平滑性、目标到达性等因素。
7. 最优轨迹选择 (Ego Plan)
- 从所有候选轨迹中,选择代价最低的轨迹 ( τ ∗ ) ( \tau^* ) (τ∗),作为最终规划路径。
- 这一轨迹既满足环境约束,又具备良好的驾驶行为。
QuAD 算法框架


QuAD 效果对比
安全场景对比 1、 Cut in
- 其他车辆突然切入自车(SDV)前方,要求方法能够合理规划轨迹以避免碰撞。

- QUAD
- 表现:
- 成功适应前方车辆的突然切入。
- 根据动态环境生成多条候选轨迹(红色表示高成本,蓝色表示低成本),最终选择了最优的安全路径。
- 在整个过程中没有与其他车辆发生碰撞。
- 评价:
- 轨迹成本分析精确,能够及时调整速度和位置。
- 在动态交互中展现了较强的适应能力。
- P3
- 表现:
- 与 QUAD 类似,成功应对切入车辆的动态变化。
- 轨迹生成较为平滑,选择了安全的低成本路径。
- 评价:
- 虽然成功规避了碰撞,但在应对快速动态场景时表现稍逊于 QUAD。
- OccFlow
- 表现:
- 未能有效考虑切入车辆的动态性,最终与其发生碰撞。
- 轨迹生成的适应性较弱,缺乏有效的动态响应机制。
- 评价:
- 对动态环境的建模不足,难以处理复杂交互场景。
- NMP
- 表现:
- 能够适应前方车辆的切入。
- 生成的轨迹成本分布合理,但路径选择略显激进。
- 成功避免了碰撞。
- 评价:
- 动态规划能力尚可,但在复杂环境中仍可能有风险。
- PlanT
- 表现:
- 能够调整路径以适应动态环境。
- 生成的轨迹成本较低,但路径选择存在不稳定性。
- 评价:
- 表现较为可靠,但动态交互能力不及 QUAD 和 P3。
安全场景对比 2、Merge into the desired lane
场景描述:
- 车辆需要从匝道并入目标车道,同时目标车道已有车辆,形成较高的交通密度。
- 方法需要综合评估交通流动态,生成安全且高效的轨迹。

-
QUAD:
- 成功导航到目标车道。
- 能够高效调整轨迹,避开与其他车辆的碰撞。
-
P3:
- 和 QUAD 一样,顺利完成换道操作。
- 表现稍逊于 QUAD,但仍未引发碰撞。
-
OccFlow:
- 由于未能正确排序轨迹优先级,发生碰撞。
- 在处理中对动态环境的理解存在问题。
-
NMP:
- 表现较为激进。
- 由于操作过于激烈,导致与其他车辆碰撞。
-
PlanT:
- 在地图超出分布范围的情况下,出现轨迹偏移,偏离主车道。
- 未能正确完成换道任务。
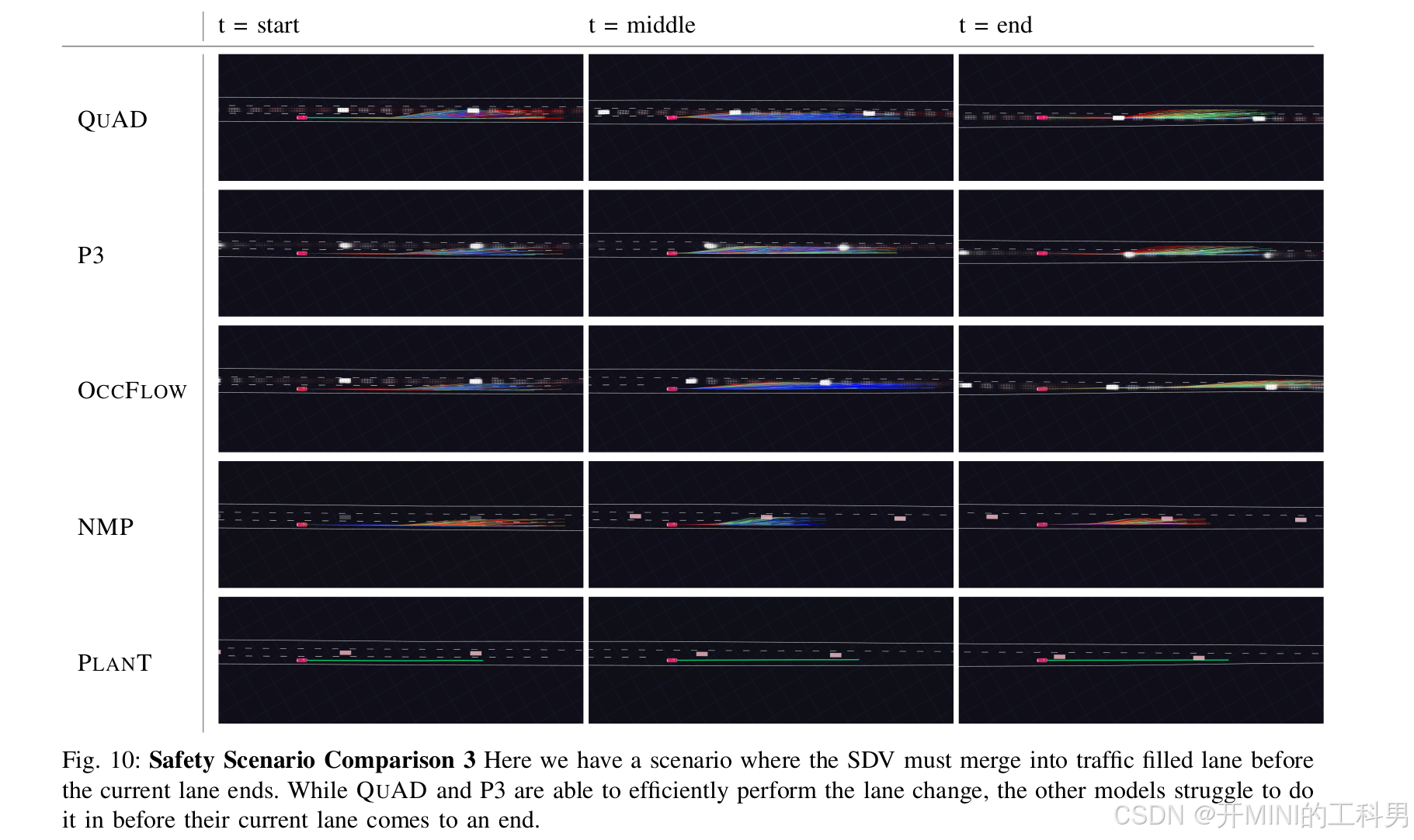
安全场景对比 3、 Lane change
场景描述:
- 车辆当前所在车道即将结束,需要并入一条有其他车辆占用的目标车道。
- 方法需要在有限的时间内完成轨迹规划和安全换道。
-
QUAD:
- 能够精准地规划轨迹,及时完成换道操作。
- 高效避让其他车辆,展现出强大的动态交互能力。
-
P3:
- 表现类似于 QUAD,顺利完成换道。
- 整体规划能力稍弱,但仍未出现失误。
-
OccFlow:
- 无法及时完成换道。
- 对动态场景理解有限,导致未能正确排序轨迹,换道失败。
-
NMP:
- 表现较为激进,出现不合理的加速或减速。
- 最终因操作不当引发碰撞。
-
PlanT:
- 无法及时生成有效的规划,未完成换道。
- 可能是因为未能有效处理当前车道即将结束的情况。

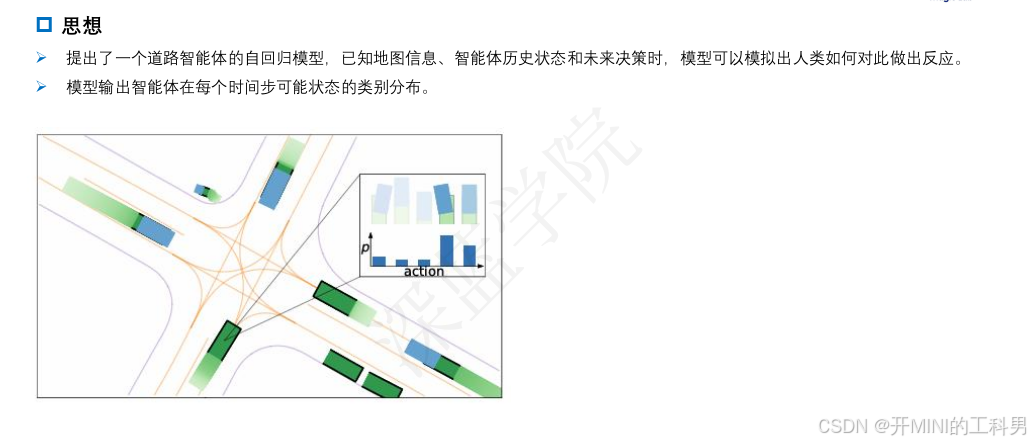
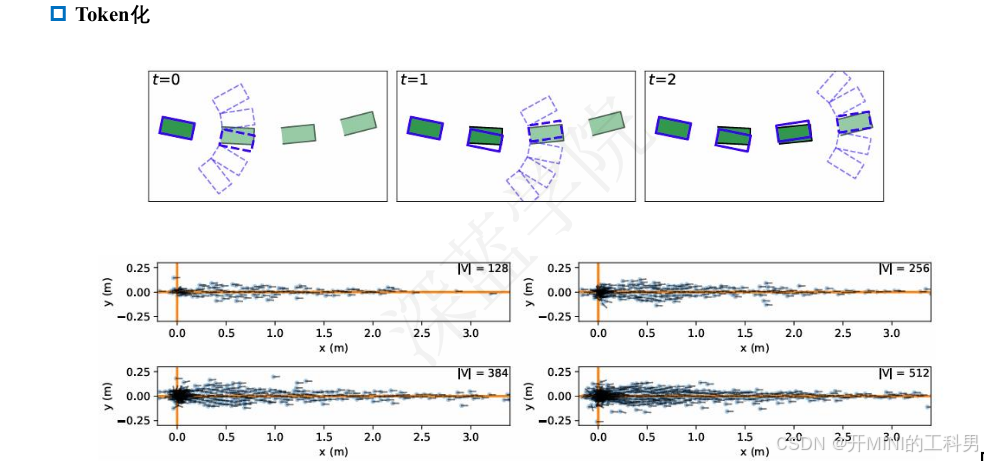
2.2 TRAJEGLISH: Traffic Modeling as Next-Token Prediction
TRAJEGLISH 算法简介
参考链接:
自动驾驶开发中的一个长期挑战是模拟基于记录驾驶日志的动态驾驶场景。为实现这一功能,我们应用离散序列建模工具,模拟车辆、行人和骑行者在驾驶场景中的交互。通过一种简单的数据驱动的标记化方案,我们将轨迹离散化为厘米级分辨率,并使用一个小规模词汇表表示。随后,我们利用类似 GPT 的编码器-解码器模型对离散运动标记的多智能体序列进行时间上的自回归建模,同时考虑智能体之间的时间步内交互。
从我们的模型中采样的场景展现出最先进的真实感;在 Waymo Sim Agents 基准测试中,我们的模型在真实感元指标上超越了之前的工作,提高了 3.3%,并在交互指标上提高了 9.9%。我们在完全自动驾驶和部分自动驾驶设置中对建模选择进行了消融分析,证明了模型学习的表示可以快速适配以提升 nuScenes 数据集上的性能。此外,我们评估了模型在参数数量和数据集规模方面的可扩展性,并利用模型的密度估计量化了上下文长度和时间步内交互对交通建模任务的重要性。

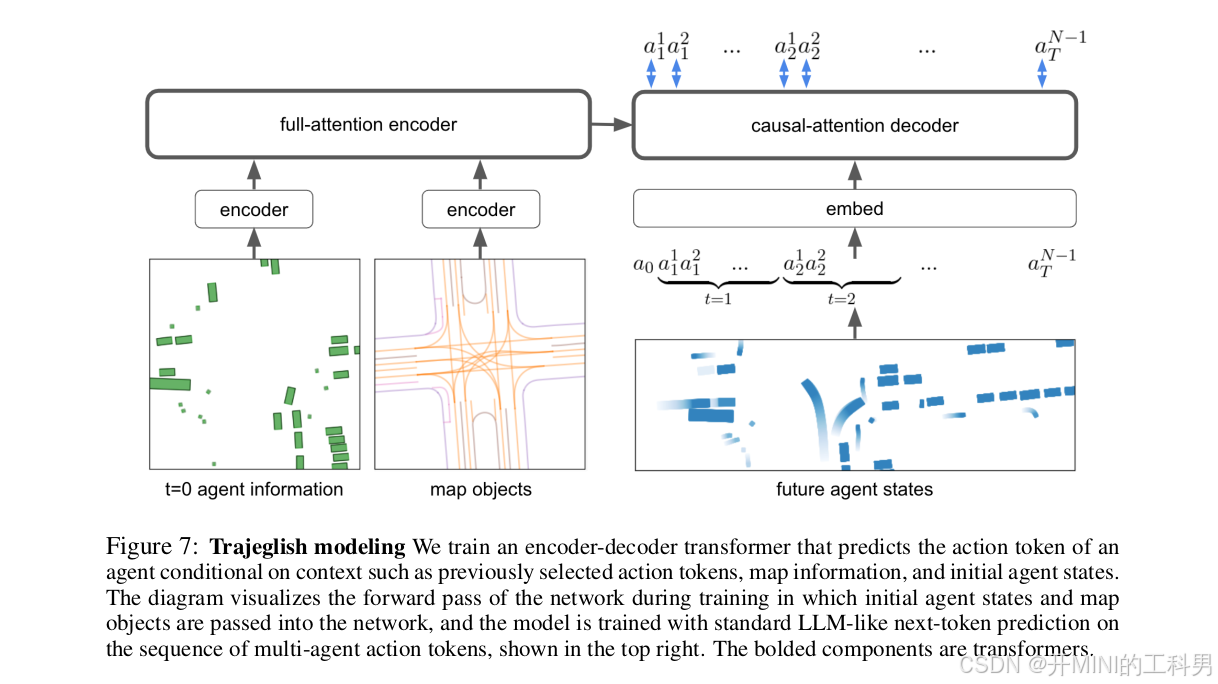
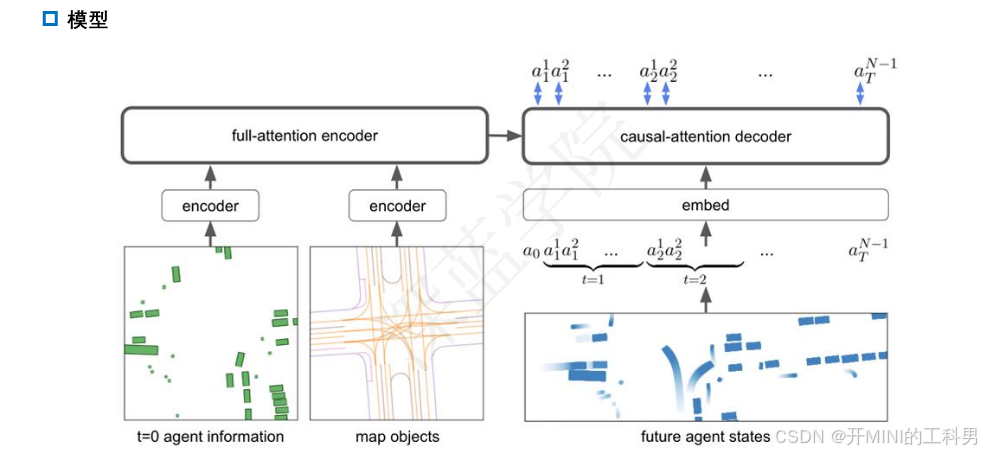
模型结构:
-
输入:
- 初始智能体信息(左下角):每个智能体的初始状态(如位置、朝向等)。
- 地图对象(左中下方):环境中的地图数据(如车道、路口布局等)。
-
编码器:
- 将初始智能体状态和地图信息通过单独的编码器模块进行处理。
- 使用 全注意力(full-attention)编码器,整合初始信息为场景的全局表示。
-
解码器:
- 使用 因果注意力(causal-attention)解码器,基于时间步递归生成每个智能体的动作序列。
- 输入包括:
- 当前的上下文信息(如前面生成的动作 tokens)。
- 编码后的场景全局表示。
- 输出每个时间步的智能体动作序列 ((a_t^1, a_t^2, \dots))。
运行逻辑:
-
时间步处理:
- 模型在每个时间步生成所有智能体的动作(如车辆移动的方向或速度)。
- 动作是通过离散 token 的形式表示,类似语言模型中的“下一词预测”机制。
-
训练方式:
- 模型基于标准的大型语言模型(LLM)训练方法,采用“下一 token 预测”策略。
- 动作 tokens 的生成顺序既考虑了时间上的因果性,也考虑了同一时间步内智能体间的相互作用。
TRAJEGLISH 算法架构

3.强化学习
3.1 Learning Realistic Traffic Agents in Closed-loop
Learning Realistic Traffic Agents in Closed-loop 简介
参考文献:Learning Realistic Traffic Agents in Closed-loop
摘要:真实的交通模拟对自驾驶软件的开发至关重要,因为它能在实际部署之前以安全且可扩展的方式进行测试。通常,模仿学习(Imitation Learning, IL)被用于从离线收集的真实观测数据中直接学习类人的交通智能体。然而,由于没有明确的交通规则约束,仅通过模仿学习训练的智能体常常会表现出不真实的违规行为,例如碰撞或驶出道路。这一问题在分布外和极端情况(long-tail scenarios)中尤为严重。另一方面,强化学习(Reinforcement Learning, RL)能够训练交通智能体避免违规,但单独使用强化学习往往会导致不符合人类驾驶习惯的行为。
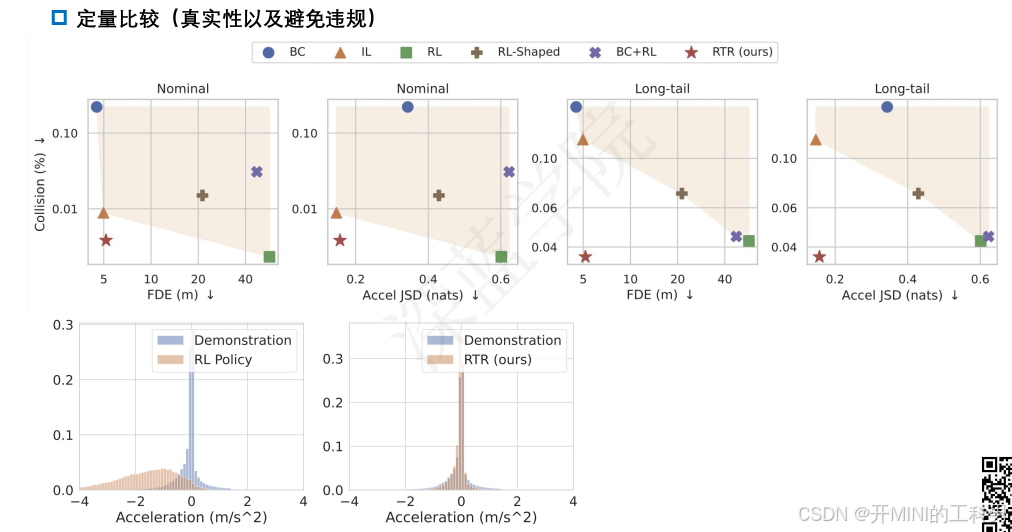
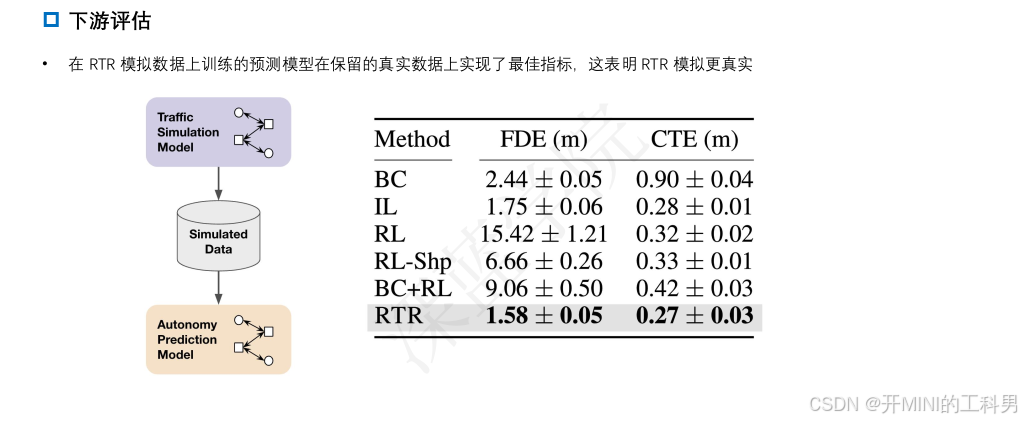
我们提出了一种名为 Reinforcing Traffic Rules (RTR) 的整体闭环学习目标,该方法在交通合规性约束下匹配专家示范,自然地结合了模仿学习和强化学习的优点,从而兼顾两者。我们的方法在闭环模拟中进行学习,既包括源自真实数据集的常规场景,也包括程序生成的极端场景。实验表明,RTR 学习到的交通模拟策略更加真实且具有更强的泛化能力,在常规和极端场景中,在类人驾驶和交通合规性之间实现了显著更好的平衡。此外,当 RTR 用作生成预测模型训练数据的工具时,相较于基线交通智能体,它显著提升了下游预测指标的表现。
更多信息,请访问项目网站:https://waabi.ai/rtr。
Reinforcing Traffic Rules (RTR) 方法的核心流程
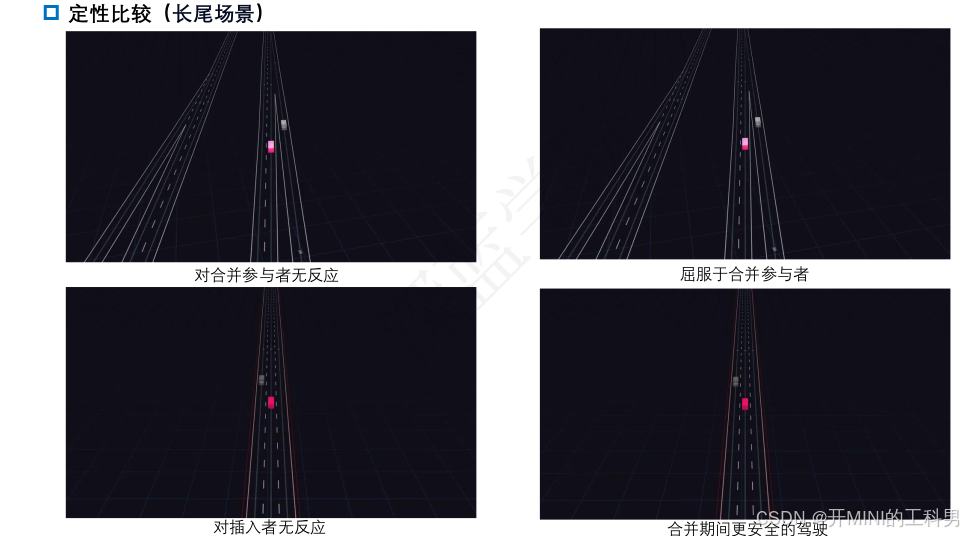
将常规和极端场景结合,通过闭环模拟环境和 IL + RL 目标,学习到更真实、类人且符合交通规则的多智能体策略。这种方法不仅可以生成更真实的交通行为,还能更好地推广到未见过的场景,从而改进自驾驶系统的开发和测试。


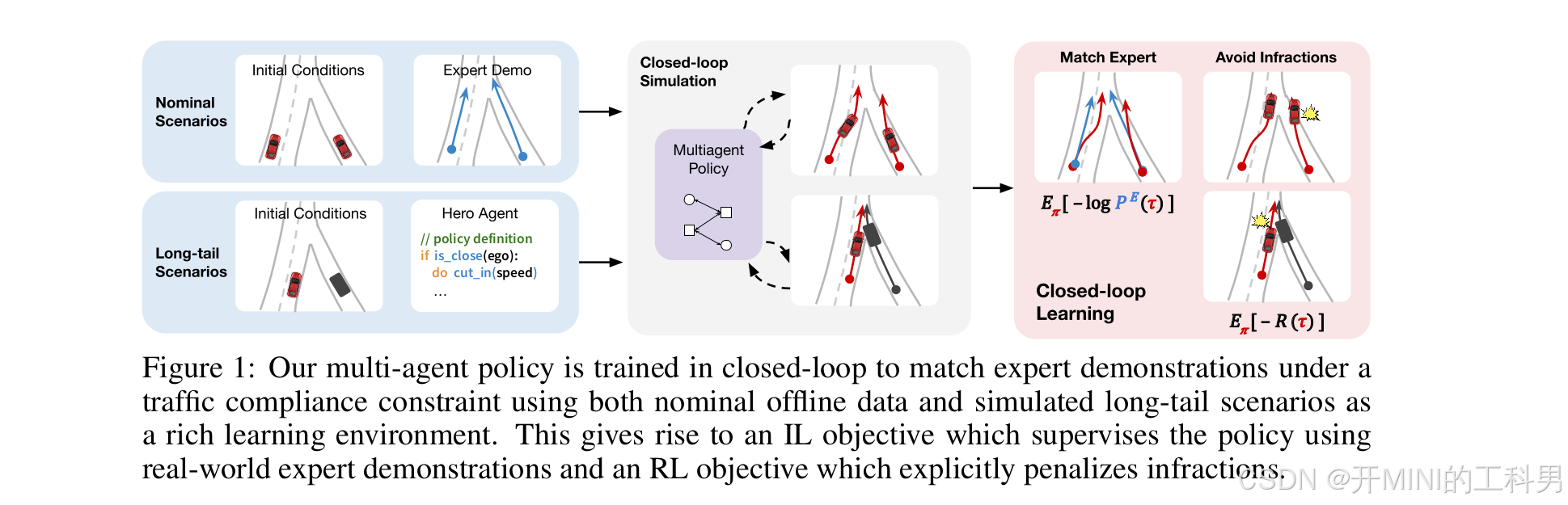
输入场景和策略训练环境
- Nominal Scenarios(常规场景):使用源自真实世界的数据集的正常驾驶场景,提供了丰富的专家示范(Expert Demo)。
- Long-tail Scenarios(极端场景):通过程序化生成的边缘情况,例如罕见或危险的驾驶场景,能够让策略更好地学习应对极端情况。这些场景中引入了“Hero Agent”(英雄智能体)的概念,其策略定义为应对特定环境的规则,比如在距离近时调整速度。
这两个场景作为输入,为多智能体策略提供丰富的学习环境。
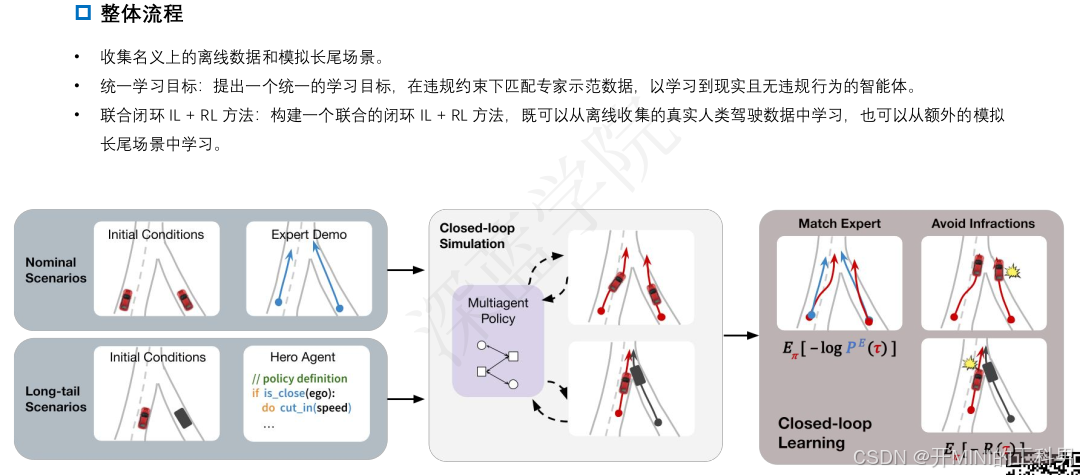
闭环模拟和多智能体策略
- 多智能体策略在闭环模拟环境中训练,这意味着每个智能体的行为会动态影响整个环境的未来状态。
- 闭环学习(Closed-loop Learning):结合了两种学习目标:
- 匹配专家行为:模仿学习的目标,通过专家演示来监督策略。
- 避免违规行为:强化学习的目标,通过显式惩罚违规行为(如碰撞或偏离道路)来优化策略。
这种闭环结构能更有效地捕捉动态交互,减少错误累积带来的影响。
训练目标
- Match Expert Demo(匹配专家行为):通过模仿学习监督策略,使其接近专家示范的轨迹(图中左上方红色路径)。
- Avoid Infractions(避免违规行为):强化学习通过设计奖励函数(如惩罚碰撞),显式地让策略避免发生不合理行为(图中右上方有碰撞的黄色标志)。
这两个目标共同形成了统一的 IL + RL 学习框架。
Learning Realistic Traffic Agents in Closed-loop 整体流程




3.2 Think2Drive
Think2Drive 简介
参考文献:
摘要:
现实世界的自动驾驶(AD),如城市驾驶,涉及许多极端情况。最新发布的自动驾驶基准测试 CARLA Leaderboard v2 (即 CARLA v2) 包含驾驶场景中的 39 种新常见事件,相比 CARLA Leaderboard v1 提供了一个更接近真实的测试环境。然而,这也带来了新的挑战,目前尚无文献报道在 V2 的新场景中取得成功的案例。
在本研究中,我们率先直接训练了一个神经规划器,希望能够灵活且高效地应对这些极端情况。据我们所知,我们提出了首个基于模型的强化学习方法(称为 Think2Drive)用于自动驾驶。该方法利用一个紧凑的潜在世界模型学习环境的状态转移过程,并将其作为神经模拟器来训练智能体(即规划器)。得益于潜在世界模型的低维状态空间和张量的并行计算,Think2Drive 显著提升了强化学习的训练效率。
在仅使用一张 A6000 GPU 训练三天后,Think2Drive 能够在 CARLA v2 中实现专家级表现。此外,据我们所知,目前尚无其他方法在 CARLA v2 上实现 100% 路径完成率。
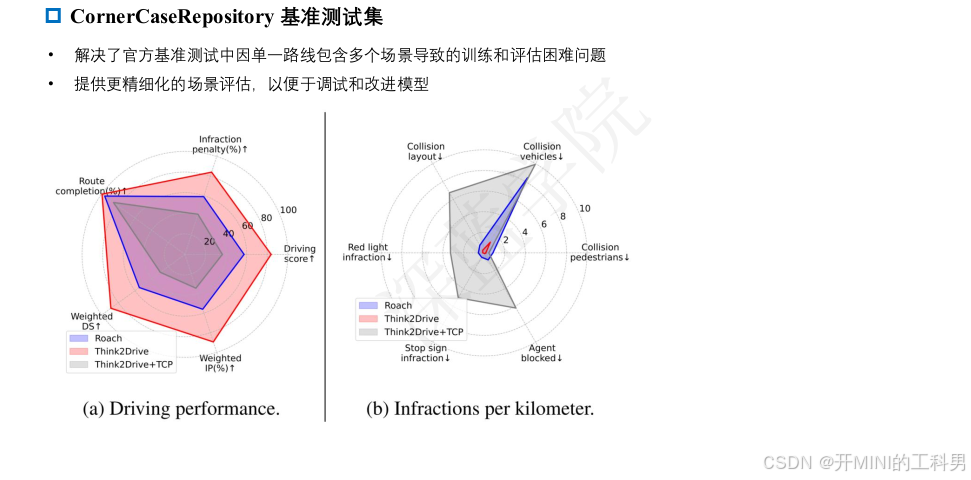
我们还开发了一个名为 CornerCaseRepo 的基准库,用于通过特定场景评估驾驶模型的表现。同时,我们提出了一种综合平衡的评价指标,结合了路径完成率、违规次数和场景密度,从多个维度评估模型性能。
关键词: 自动驾驶 · 神经规划器 · 世界模型 · 基于模型的强化学习 · CARLA v2 · Think2Drive

Think2Drive 整体流程





4.总结

- 生成模型
基本概念:
生成模型通过模拟环境或场景生成丰富的驾驶数据,从而为自动驾驶系统提供高质量的训练样本。它常用于创建复杂或难以直接采集的场景,如极端天气、稀有交通状况(如行人突然闯入道路)等。
优点:
-
高逼真度和复杂性:
- 生成模型可以构造出非常接近真实世界的场景和数据,提供对现实中不常见但重要的“长尾场景”的良好覆盖。
- 这种高复杂度的数据能有效提高模型在真实场景中的表现。
-
适应性强:
- 可以灵活地生成多样化的场景,用于不同的测试和训练需求。
缺点:
-
计算密集:
- 生成模型通常需要庞大的算力和时间成本,例如生成高精度三维仿真场景或进行物理引擎模拟。
- 模拟多个复杂场景可能会导致系统资源不足。
-
难以处理稀有行为:
- 虽然生成模型可以模拟稀有场景,但对涉及复杂人类行为的场景建模(如突然违规的驾驶员行为)依然具有挑战性。
- 模仿学习(IL:Imitation Learning)
基本概念:
模仿学习通过学习专家的示范(例如人类驾驶员的行为数据)来训练规划器。这种方法直接模仿专家的操作,适用于有大量高质量驾驶数据的情况。
优点:
-
类人行为:
- 模仿学习能够很好地捕捉人类驾驶员的行为模式,容易产生接近人类驾驶员风格的操作。
-
数据利用率高:
- 模仿学习直接使用现有的驾驶数据,避免了生成模型或强化学习中需要大量采样或计算的复杂过程。
-
实现简单:
- 相较于其他方法,模仿学习的训练流程相对直观,尤其是在已有高质量标注数据的前提下。
缺点:
-
规则遵循不足:
- 由于直接模仿专家行为,系统可能会忽略一些隐藏的交通规则,甚至在专家行为本身存在问题时“继承错误”。
-
泛化问题:
- 模仿学习的模型很容易过拟合于训练数据,在遇到未知场景(例如长尾场景)时表现不佳。
- 强化学习(RL:Reinforcement Learning)
基本概念:
强化学习通过让智能体与环境交互并从反馈中学习最优策略。该方法常用于解决高维和动态规划问题,如复杂的驾驶决策。
优点:
-
规则遵循高:
- 强化学习通过奖励和惩罚机制明确引导智能体遵循交通规则(例如红灯停车、不超速)。
-
探索性学习:
- RL能够自主探索可能的驾驶策略,而不局限于专家的示范。这在解决“长尾场景”时非常有用。
缺点:
-
类人行为不足:
- 强化学习中的驾驶策略可能过于“机械化”,因为它主要优化规则遵循而非人类驾驶风格。
- 驾驶行为可能缺乏流畅性和自然性。
-
样本效率低:
- 强化学习需要大量的交互和采样数据,而生成这些数据往往成本高昂。
- 未来趋势展望
当前规划方法在优点和缺点之间的权衡给未来的研究指明了方向。以下是未来的重点趋势:
(1) 稀有场景的生成和处理能力
- 自动驾驶车辆需要在极端和稀有场景中表现良好,例如突然的障碍物、复杂的多车交互、恶劣天气等。未来的技术需要:
- 生成稀有场景:
提高模拟器的多样性,生成真实场景中罕见但高风险的驾驶状况。 - 泛化能力:
使规划器不仅能处理普通场景,还能应对长尾情况。
- 生成稀有场景:
(2) 提高数据利用效率
- 模仿学习和强化学习都有数据利用率的问题。未来技术应:
- 结合生成模型与模仿学习:
通过生成数据弥补模仿学习中稀缺样本的问题。 - 高效的模型训练:
使用高效算法或压缩的状态空间(例如Think2Drive中的潜在世界模型)来减少计算成本。
- 结合生成模型与模仿学习:
(3) 平衡类人行为和规则遵循
- 类人行为和规则遵循往往冲突,例如人类驾驶员在某些情况下会“灵活变通”,而强化学习策略通常严格按照规则行事。未来技术需要:
- 多目标优化:
在优化类人行为的同时确保安全性和规则遵循。 - 混合方法:
使用“模仿学习+强化学习”联合方法(如RTR方法),实现两者的平衡。
- 多目标优化:
5 参考
- 《自动驾驶预测与决策技术》
- Part1_自动驾驶决策规划简介
- Part2_基于模型的预测方法
- Part3_路径与轨迹规划
- Part4_时空联合规划
- Part5_决策过程
- Part6_不确定性感知的决策过程
- Part7_数据驱动的预测方法