前言
本文从零搭建SpringBoot项目,简单利用jsoup插件实现从微医网站爬取医生数据并持久化到MySQL数据库,注意:本文只讲应用不讲原理
1.从零搭建SpringBoot项目
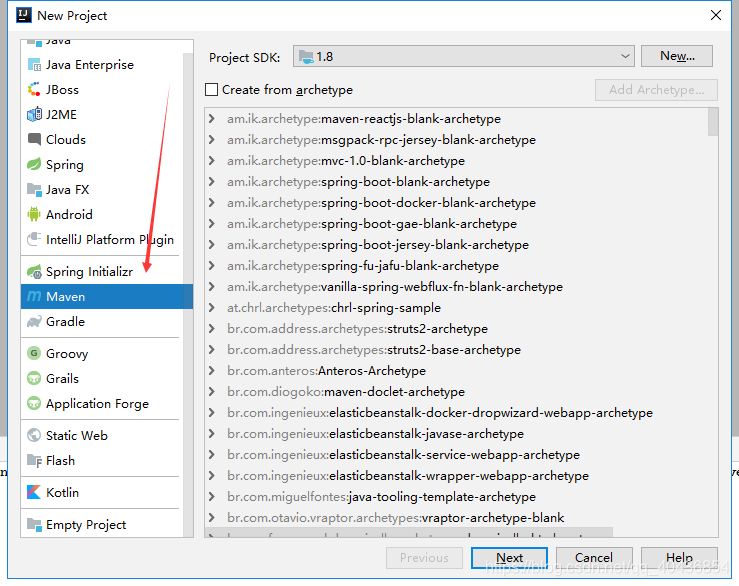
1.1 利用idea新建一个maven项目
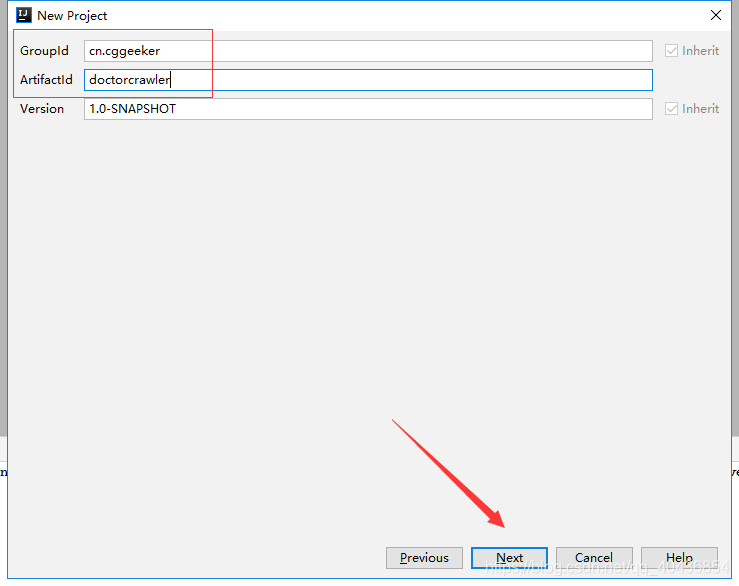
给maven项目指定组名和项目名然后next
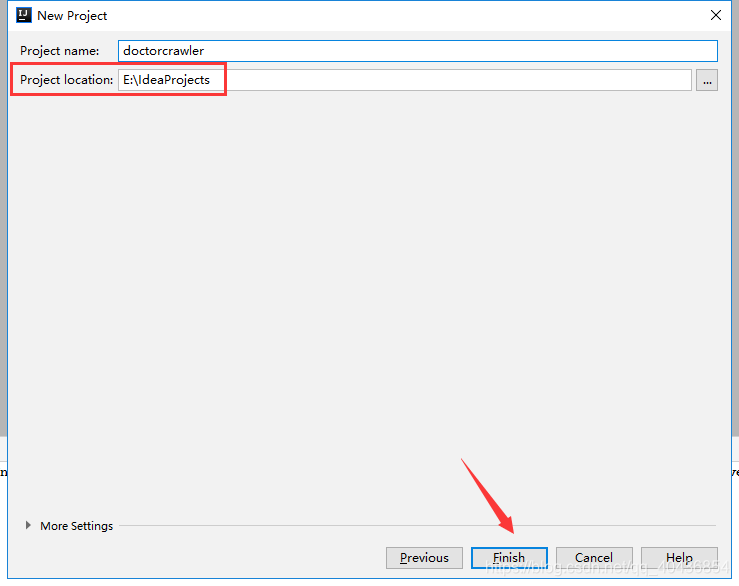
然后指定项目存放的目录,然后Finish
接下来是将maven项目的目录补全
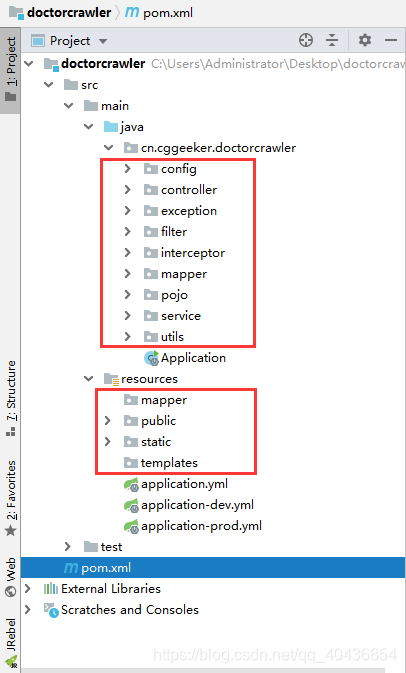
1.2 将springboot项目目录补齐
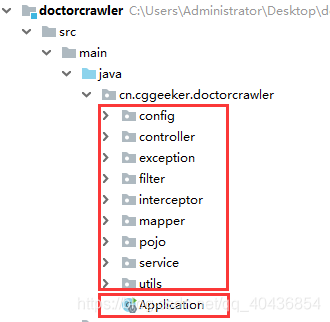
上面初步用maven将springboot项目构建出来,但是目录是不全的,这里需要补全目录如一些基本的config、controller、service、mapper、entity(或pojo)等,具体目录如下图所示:
这里对上述红框中的目录做一些描述:
java目录下的:
config目录:该目录用于存放一些配置类,配置类用注解@Configuration标识。filter目录:用于存放自定义的过滤器类,过滤掉一些错误的请求和未登录用户,也可以修改请求和相应的内容;过滤器一般实现Filter接口并且会用注解@WebFilter标识。interceptor目录:用于存放拦截器类,作用是对正在运行的流程进行干预,在某个方法被访问之前,进行拦截,然后在之前或之后加入某些操作,拦截器是AOP 的一种实现策略;拦截器一般实现HandlerInterceptor接口重写preHandle、postHandle、afterCompletion这三个方法,然后可以在这三个方法里加入一些日志用于记录某些方法的调用信息。controller目录:用于存放控制器类,控制器类也就是MVC中的“C”负责请求的接收和处理和JavaWeb中的servlet功能类似,类上常用注解@RequestMapping("/url")指定请求访问的路径,用@Controller标识该类是一个控制器类。service目录:用于存放处理具体业务逻辑的类,通常对数据库事务控制也放在这一层;常用注解@Service标识,用注解@Transactional达到事务控制的目的mapper目录:存放操作数据库的接口,封装对数据库的访问:增删改查,不涉及业务逻辑,只是达到按某个条件获得指定数据的要求。pojo(或entity)目录:用于存放实体类,注意:我这里只是将具有VO、DTO、DO、PO性质的实体类都统一放在pojo目录下。utils目录:存放一些三方工具类的,例如:Json转换、雪花算法生成这些类。exception目录:用于存放自定义业务异常类和全局异常处理类。
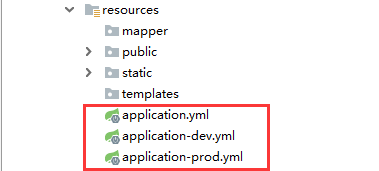
resources目录下的:
mapper目录:用于存放mybatis操作数据库的xml文件的,xml文件中写具体操作数据库数据的sql,注意:如果是用的mybatis-plus或者JPA封装好的方法操作数据库则可以不用写xml文件。public目录:用于存放静态资源文件(图片、js、css等等)或者html文件。static目录:作用同public目录,只不过springboot默认的静态资源访问路径是:META-INF/resources > resources > static > public (访问优先级也是如此)。templates目录:用于存放thymeleaf模板。
1.3 引入需要用到的jar依赖和配置application.yml以及启动类
这里先对要使用的jsoup插件进行说明: jsoup 是一款Java
的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
首先是引入pom依赖,主要是springboot和jsoup的依赖(jsoup官网传送门:https://jsoup.org)
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.3.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--jdbc-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!--mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--druid数据库连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.6</version>
</dependency>
<!--引入mybatis-plus插件-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.0</version>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--生成雪花算法的jar包-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.8</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
<!--引入log日志依赖-->
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
</dependencies>
然后编写application.yml配置文件:
一般配置文件会将线上环境、测试环境和开发环境配置的公共部分抽到application.yml里,然后将部分不同的配置(例如线上和测试用的数据库连接不一样)会分别放入用类似“-环境前缀”的yml文件里,我这里就是“-dev”(开发环境)和“-prod”(线上环境),一般在公司还会有个“-test”(测试环境)。
application.yml配置:
#公共环境配置
spring:
profiles:
active: dev #激活配置
application:
name: crawlerserver
mybatis:
mapper-locations: classpath:mapper/*Mapper.xml
type-aliases-package: cn.cggeeker.doctorcrawler.pojo
configuration:
map-underscore-to-camel-case: true
application-dev.yml配置:
#测试环境配置
server:
port: 8080
servlet:
context-path: /crawler # 给项目一个名称
session:
timeout: 30
tomcat:
uri-encoding: UTF-8
spring:
profiles: dev
mvc:
servlet:
load-on-startup: 1
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/doctorcrawler_db?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8
username: root
password: root
thymeleaf:
cache: false
mode: HTML5
encoding: UTF-8
logging:
level:
cn.cggeeker: debug
path: "E:/doctorcrawler/logs"
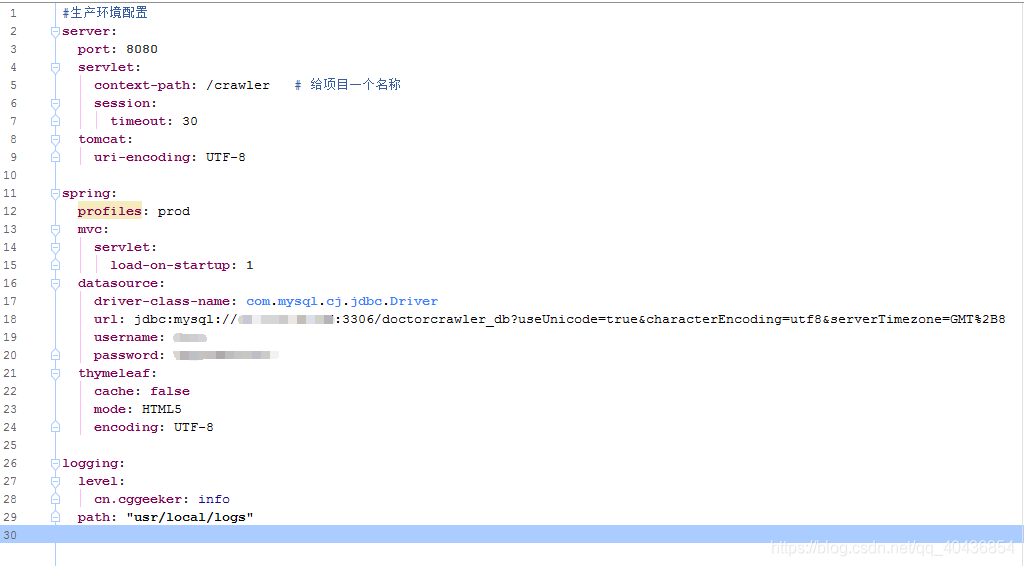
application-prod.yml配置(对敏感数据已做脱敏处理):
最后是编写最重要的Application启动类,启动类需要和config、controller这些目录同级
启动类代码:
@SpringBootApplication // 该注解用于标识Application类是启动类
/**
* 使用@ServletComponentScan注解后,Servlet、Filter、Listener可以直接通过
* @WebServlet、@WebFilter、@WebListener注解自动注册,无需其他代码。
*/
@ServletComponentScan
@MapperScan("cn.cggeeker.doctorcrawler.mapper") // 扫描mapper目录下的接口
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
}
}
1.4 各个目录下类的具体代码
整体结构预览:
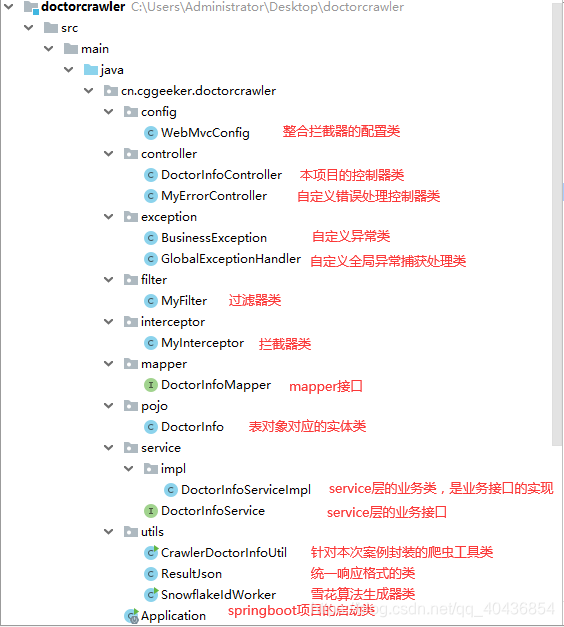
- utils目录下的:
ResultJson、SnowflakeIdWorker和CrawlerDoctorInfoUtil类(这个类后面说明,该类就是用Jsoup工具爬取网页数据的)
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.stereotype.Component;
@Component
public class ResultJson {
//定义jackson对象
private static final ObjectMapper MAPPER = new ObjectMapper();
//响应业务状态
private Integer status; //规定200:请求成功 401:没有权限 500:请求失败(或异常)
//响应消息
private String message; //返回后端的消息给前台
//响应的数据
private Object data; //返回后端数据给前台
public ResultJson(){}
public ResultJson(Integer status, String message, Object data) {
this.status = status;
this.message = message;
this.data = data;
}
public static ObjectMapper getMAPPER() {
return MAPPER;
}
public Integer getStatus() {
return status;
}
public void setStatus(Integer status) {
this.status = status;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public Object getData() {
return data;
}
public void setData(Object data) {
this.data = data;
}
}
import org.apache.commons.lang3.RandomUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.SystemUtils;
import java.net.Inet4Address;
import java.net.UnknownHostException;
/**
* Twitter_Snowflake<br>
* SnowFlake的结构如下(每部分用-分开):<br>
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br>
* 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0<br>
* 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)
* 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69<br>
* 10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId<br>
* 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号<br>
* 加起来刚好64位,为一个Long型。<br>
* SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。
*/
public class SnowflakeIdWorker {
// ==============================Fields===========================================
/** 开始时间截 (2015-01-01) */
private final long twepoch = 1489111610226L;
/** 机器id所占的位数 */
private final long workerIdBits = 5L;
/** 数据标识id所占的位数 */
private final long dataCenterIdBits = 5L;
/** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/** 支持的最大数据标识id,结果是31 */
private final long maxDataCenterId = -1L ^ (-1L << dataCenterIdBits);
/** 序列在id中占的位数 */
private final long sequenceBits = 12L;
/** 机器ID向左移12位 */
private final long workerIdShift = sequenceBits;
/** 数据标识id向左移17位(12+5) */
private final long dataCenterIdShift = sequenceBits + workerIdBits;
/** 时间截向左移22位(5+5+12) */
private final long timestampLeftShift = sequenceBits + workerIdBits + dataCenterIdBits;
/** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/** 工作机器ID(0~31) */
private long workerId;
/** 数据中心ID(0~31) */
private long dataCenterId;
/** 毫秒内序列(0~4095) */
private long sequence = 0L;
/** 上次生成ID的时间截 */
private long lastTimestamp = -1L;
private static SnowflakeIdWorker idWorker;
static {
idWorker = new SnowflakeIdWorker(getWorkId(),getDataCenterId());
}
//==============================Constructors=====================================
/**
* 构造函数
* @param workerId 工作ID (0~31)
* @param dataCenterId 数据中心ID (0~31)
*/
public SnowflakeIdWorker(long workerId, long dataCenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("workerId can't be greater than %d or less than 0", maxWorkerId));
}
if (dataCenterId > maxDataCenterId || dataCenterId < 0) {
throw new IllegalArgumentException(String.format("dataCenterId can't be greater than %d or less than 0", maxDataCenterId));
}
this.workerId = workerId;
this.dataCenterId = dataCenterId;
}
// ==============================Methods==========================================
/**
* 获得下一个ID (该方法是线程安全的)
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift)
| (dataCenterId << dataCenterIdShift)
| (workerId << workerIdShift)
| sequence;
}
/**
* 阻塞到下一个毫秒,直到获得新的时间戳
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回以毫秒为单位的当前时间
* @return 当前时间(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
private static Long getWorkId(){
try {
String hostAddress = Inet4Address.getLocalHost().getHostAddress();
int[] ints = StringUtils.toCodePoints(hostAddress);
int sums = 0;
for(int b : ints){
sums += b;
}
return (long)(sums % 32);
} catch (UnknownHostException e) {
// 如果获取失败,则使用随机数备用
return RandomUtils.nextLong(0,31);
}
}
private static Long getDataCenterId(){
int[] ints = StringUtils.toCodePoints(SystemUtils.getHostName());
int sums = 0;
for (int i: ints) {
sums += i;
}
return (long)(sums % 32);
}
/**
* 静态工具类
*
* @return
*/
public static synchronized Long generateId(){
long id = idWorker.nextId();
return id;
}
//==============================Test=============================================
/** 测试 */
public static void main(String[] args) {
System.out.println(System.currentTimeMillis());
long startTime = System.nanoTime();
for (int i = 0; i < 50000; i++) {
long id = SnowflakeIdWorker.generateId();
System.out.println(id);
}
System.out.println((System.nanoTime()-startTime)/1000000+"ms");
}
}
- config目录下的:
WebMvcConfig类:
import cn.cggeeker.doctorcrawler.interceptor.MyInterceptor;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurerAdapter;
@Configuration
public class WebMvcConfig extends WebMvcConfigurerAdapter implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
// 拦截器,"/**"表示拦截所有请求,然后排除/image/**和/error/**路径的请求放行静态资源文件
registry.addInterceptor(new MyInterceptor()).addPathPatterns("/**").excludePathPatterns("/image/**","/error/**");
}
}
- filter目录下的:
MyFilter类:
import org.springframework.core.annotation.Order;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import java.io.IOException;
@WebFilter(urlPatterns = "/doctorInfo/*",filterName = "myFilter") // 填写需要过滤的请求路径
@Order(1)//指定过滤器的执行顺序,值越大越靠后执行
public class MyFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("---------初始化过滤器------------");
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
HttpServletRequest servletRequest= (HttpServletRequest) request;
String uri = servletRequest.getRequestURI();
String method = servletRequest.getMethod();
// 通常开发中首先校验是否是开放api的url请求 ,如果是就直接放行,否再校验token
// 开发中一般可以用request.getHeader("token")来获取请求的请求头里是否携带token,然后在做一些处理逻辑
// 这里只是做演示就写简单点
System.out.println(uri + " " + method + " ------进入了 MyFilter 过滤器了---------");
chain.doFilter(request,response);
}
@Override
public void destroy() {
System.out.println("---------过滤器销毁------------");
}
}
- interceptor目录下的:
MyInterceptor类:
import lombok.extern.slf4j.Slf4j;
import org.springframework.lang.Nullable;
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@Slf4j
public class MyInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
log.debug("MyInterceptor------preHandle");
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, @Nullable ModelAndView modelAndView) throws Exception {
System.out.println("---------执行了拦截器的postHandle方法------------");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, @Nullable Exception ex) throws Exception {
System.out.println("---------执行了拦截器的afterCompletion方法------------");
}
}
- exception目录下的:
BusinessException类和GlobalExceptionHandler类:
import org.springframework.http.HttpStatus;
import org.springframework.web.bind.annotation.ResponseStatus;
@ResponseStatus(code= HttpStatus.INTERNAL_SERVER_ERROR,reason="自定义业务异常")
public class BusinessException extends RuntimeException{
//自定义错误码
private Integer code;
//自定义构造器,必须输入错误码及内容
public BusinessException(int code, String msg) {
super(msg);
this.code = code;
}
public Integer getCode() {
return code;
}
public void setCode(Integer code) {
this.code = code;
}
}
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.http.HttpStatus;
import org.springframework.http.converter.HttpMessageNotReadableException;
import org.springframework.validation.BindException;
import org.springframework.validation.BindingResult;
import org.springframework.validation.FieldError;
import org.springframework.web.HttpMediaTypeNotSupportedException;
import org.springframework.web.HttpRequestMethodNotSupportedException;
import org.springframework.web.bind.MethodArgumentNotValidException;
import org.springframework.web.bind.MissingServletRequestParameterException;
import org.springframework.web.bind.annotation.*;
import javax.validation.ConstraintViolation;
import javax.validation.ConstraintViolationException;
import javax.validation.ValidationException;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
@RestControllerAdvice
public class GlobalExceptionHandler {
// 日志记录工具
private static final Logger logger = LoggerFactory.getLogger(GlobalExceptionHandler.class);
/**
* 400 - Bad Request
*/
@ResponseStatus(HttpStatus.BAD_REQUEST)
@ExceptionHandler(MissingServletRequestParameterException.class)
public Map<String, Object> handleMissingServletRequestParameterException(MissingServletRequestParameterException e) {
logger.error("缺少请求参数", e);
Map<String, Object> map = new HashMap<String, Object>();
map.put("rspCode", 400);
map.put("rspMsg", e.getMessage());
//发生异常进行日志记录,写入数据库或者其他处理,此处省略
return map;
}
/**
* 400 - Bad Request
*/
@ResponseStatus(HttpStatus.BAD_REQUEST)
@ExceptionHandler(HttpMessageNotReadableException.class)
public Map<String, Object> handleHttpMessageNotReadableException(HttpMessageNotReadableException e) {
logger.error("参数解析失败", e);
Map<String, Object> map = new HashMap<String, Object>();
map.put("rspCode", 400);
map.put("rspMsg", e.getMessage());
//发生异常进行日志记录,写入数据库或者其他处理,此处省略
return map;
}
/**
* 400 - Bad Request
*/
@ResponseStatus(HttpStatus.BAD_REQUEST)
@ExceptionHandler(MethodArgumentNotValidException.class)
public Map<String, Object> handleMethodArgumentNotValidException(MethodArgumentNotValidException e) {
logger.error("参数验证失败", e);
BindingResult result = e.getBindingResult();
FieldError error = result.getFieldError();
String field = error.getField();
String code = error.getDefaultMessage();
String message = String.format("%s:%s", field, code);
Map<String, Object> map = new HashMap<String, Object>();
map.put("rspCode", 400);
map.put("rspMsg", message);
//发生异常进行日志记录,写入数据库或者其他处理,此处省略
return map;
}
/**
* 400 - Bad Request
*/
@ResponseStatus(HttpStatus.BAD_REQUEST)
@ExceptionHandler(BindException.class)
public Map<String, Object> handleBindException(BindException e) {
logger.error("参数绑定失败", e);
Map<String, Object> map = new HashMap<String, Object>();
BindingResult result = e.getBindingResult();
FieldError error = result.getFieldError();
String field = error.getField();
String code = error.getDefaultMessage();
String message = String.format("%s:%s", field, code);
map.put("rspCode", 400);
map.put("rspMsg",message);
//发生异常进行日志记录,写入数据库或者其他处理,此处省略
return map;
}
/**
* 400 - Bad Request
*/
@ResponseStatus(HttpStatus.BAD_REQUEST)
@ExceptionHandler(ConstraintViolationException.class)
public Map<String, Object> handleServiceException(ConstraintViolationException e) {
logger.error("参数验证失败", e);
Set<ConstraintViolation<?>> violations = e.getConstraintViolations();
ConstraintViolation<?> violation = violations.iterator().next();
String message = violation.getMessage();
Map<String, Object> map = new HashMap<String, Object>();
map.put("rspCode", 400);
map.put("rspMsg", message);
//发生异常进行日志记录,写入数据库或者其他处理,此处省略
return map;
}
/**
* 400 - Bad Request
*/
@ResponseStatus(HttpStatus.BAD_REQUEST)
@ExceptionHandler(ValidationException.class)
public Map<String, Object> handleValidationException(ValidationException e) {
logger.error("参数验证失败", e);
Map<String, Object> map = new HashMap<String, Object>();
map.put("rspCode", 400);
map.put("rspMsg", e.getMessage());
//发生异常进行日志记录,写入数据库或者其他处理,此处省略
return map;
}
/**
* 405 - Method Not Allowed
*/
@ResponseStatus(HttpStatus.METHOD_NOT_ALLOWED)
@ExceptionHandler(HttpRequestMethodNotSupportedException.class)
public Map<String, Object> handleHttpRequestMethodNotSupportedException(HttpRequestMethodNotSupportedException e) {
logger.error("不支持当前请求方法", e);
Map<String, Object> map = new HashMap<String, Object>();
map.put("rspCode", 405);
map.put("rspMsg", e.getMessage());
//发生异常进行日志记录,写入数据库或者其他处理,此处省略
return map;
}
/**
* 415 - Unsupported Media Type
*/
@ResponseStatus(HttpStatus.UNSUPPORTED_MEDIA_TYPE)
@ExceptionHandler(HttpMediaTypeNotSupportedException.class)
public Map<String, Object> handleHttpMediaTypeNotSupportedException(HttpMediaTypeNotSupportedException e) {
logger.error("不支持当前媒体类型", e);
Map<String, Object> map = new HashMap<String, Object>();
map.put("rspCode", 415);
map.put("rspMsg", e.getMessage());
//发生异常进行日志记录,写入数据库或者其他处理,此处省略
return map;
}
/**
* 自定义异常类
*/
@ResponseBody
@ExceptionHandler(BusinessException.class)
public Map<String, Object> businessExceptionHandler(BusinessException e) {
logger.error("自定义业务失败", e);
Map<String, Object> map = new HashMap<String, Object>();
map.put("rspCode", e.getCode());
map.put("rspMsg", e.getMessage());
//发生异常进行日志记录,写入数据库或者其他处理,此处省略
return map;
}
/**
* 获取其它异常。包括500
* @param e
* @return
* @throws Exception
*/
@ExceptionHandler(value = Exception.class)
public Map<String, Object> defaultErrorHandler(Exception e) {
logger.error("Exception", e);
Map<String, Object> map = new HashMap<String, Object>();
map.put("rspCode", 500);
map.put("rspMsg", e.getMessage());
//发生异常进行日志记录,写入数据库或者其他处理,此处省略
return map;
}
}
- pojo目录下的:
DoctorInfo类:
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.io.Serializable;
@Data
@TableName(value = "doctorinfo")
public class DoctorInfo implements Serializable {
@TableId(value = "id")
private Long id;
@TableField(value = "doct_headurl")
private String headurl;
@TableField(value = "doct_name")
private String name;
@TableField(value = "doct_job")
private String job;
@TableField(value = "doct_hospital")
private String hospital;
@TableField(value = "doct_firstroom")
private String firstroom;
@TableField(value = "doct_secondroom")
private String secondroom;
@TableField(value = "doct_lastroom")
private String lastroom;
@TableField(value = "doct_goodat")
private String goodat;
@TableField(value = "doct_marks")
private String marks;
@TableField(value = "doct_ask")
private int ask;
@TableField(value = "doct_province")
private String province;
@TableField(value = "doct_city")
private String city;
}
顺带附上需要用到的表结构:
-- ----------------------------
-- Table structure for `doctorinfo`
-- ----------------------------
DROP TABLE IF EXISTS `doctorinfo`;
CREATE TABLE `doctorinfo` (
`id` bigint(20) NOT NULL COMMENT '医生信息id(使用雪花算法生成)',
`doct_headurl` varchar(500) DEFAULT NULL COMMENT '医生头像url',
`doct_name` varchar(20) DEFAULT NULL COMMENT '医生姓名',
`doct_job` varchar(20) DEFAULT NULL COMMENT '医生职称',
`doct_hospital` varchar(30) DEFAULT NULL COMMENT '医院名',
`doct_firstroom` varchar(30) DEFAULT NULL COMMENT '一级科室名',
`doct_secondroom` varchar(30) DEFAULT NULL COMMENT '二级科室名',
`doct_lastroom` varchar(30) DEFAULT NULL COMMENT '直属科室',
`doct_goodat` varchar(500) DEFAULT NULL COMMENT '擅长',
`doct_marks` varchar(10) DEFAULT '暂无评分' COMMENT '评分',
`doct_ask` int(11) DEFAULT '0' COMMENT '问诊量',
`doct_province` varchar(10) DEFAULT NULL COMMENT '省or直辖市',
`doct_city` varchar(20) DEFAULT NULL COMMENT '城市(市级)',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='医生信息表';
- controller目录下的:
DoctorInfoController和MyErrorController类:
import cn.cggeeker.doctorcrawler.exception.BusinessException;
import cn.cggeeker.doctorcrawler.pojo.DoctorInfo;
import cn.cggeeker.doctorcrawler.service.DoctorInfoService;
import cn.cggeeker.doctorcrawler.utils.CrawlerDoctorInfoUtil;
import cn.cggeeker.doctorcrawler.utils.ResultJson;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RequestMapping("/doctorInfo")
@RestController
public class DoctorInfoController {
@Autowired
DoctorInfoService doctorInfoService;
@Autowired
CrawlerDoctorInfoUtil crawlerDoctorInfoUtil;
@Autowired
ResultJson resultJson;
@RequestMapping("/setDoctorInfoByUrl")
public ResultJson setDoctorInfoByUrl(String url){
List<DoctorInfo> doctorInfoList = crawlerDoctorInfoUtil.getDoctorInfoList(url);
int result = doctorInfoService.addBatchSomeColumn(doctorInfoList);
if(result == 1){
resultJson.setData(doctorInfoList);
resultJson.setMessage("OK");
resultJson.setStatus(200);
return resultJson;
}
resultJson.setMessage("err");
resultJson.setStatus(500);
return resultJson;
}
@RequestMapping("/getDoctorInfo")
public ResultJson getDoctorInfo(){
List<DoctorInfo> doctorInfoList = doctorInfoService.getDoctorInfoList();
resultJson.setData(doctorInfoList);
resultJson.setMessage("OK");
resultJson.setStatus(200);
return resultJson;
}
@RequestMapping("/testMyException")
public String testMyException(@RequestParam("i") int i){
if(0 == i){
throw new BusinessException(600,"自定义业务异常");
}
return "success";
}
}
import org.springframework.boot.web.servlet.error.ErrorController;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.util.HashMap;
import java.util.Map;
/**
* 当用户访问不存在的请求路径时,根据用户请求方式返回不同类型的404提示信息
*/
@Controller
@RequestMapping("${server.error.path:${error.path:/error}}")
// @RequestMapping("error") 或者这种写法也可以
public class MyErrorController implements ErrorController {
// 必须重写getErrorPath方法。默认返回null就可以了,否则报错
@Override
public String getErrorPath() {
return null;
}
// 一定要添加URL映射,指向error
@RequestMapping(value = "",consumes = "application/json;charset=UTF-8",produces = "application/json;charset=UTF-8")
@ResponseBody
public Map<String,Object> errorJson(){
Map<String, Object> map = new HashMap<>();
map.put("code",404);
map.put("msg","访问路径不存在");
return map;
}
// 一定要添加URL映射,指向error
@RequestMapping(value = "",produces = "text/html;charset=UTF-8")
public String errorHtml(HttpServletRequest request, HttpServletResponse response){
return "redirect:/error/404.html";
//return "forward:/error/404.html";
}
}
- service目录下的:
DoctorInfoService接口和子目录impl下的DoctorInfoServiceImpl实现类:
import cn.cggeeker.doctorcrawler.pojo.DoctorInfo;
import java.util.List;
public interface DoctorInfoService {
public int addBatchSomeColumn(List<DoctorInfo> doctorInfoList);
List<DoctorInfo> getDoctorInfoList();
}
impl目录下的实现类:
import cn.cggeeker.doctorcrawler.mapper.DoctorInfoMapper;
import cn.cggeeker.doctorcrawler.pojo.DoctorInfo;
import cn.cggeeker.doctorcrawler.service.DoctorInfoService;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Propagation;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
import static org.springframework.transaction.annotation.Isolation.REPEATABLE_READ;
@Service
@Transactional(isolation = REPEATABLE_READ,propagation = Propagation.REQUIRES_NEW)
public class DoctorInfoServiceImpl implements DoctorInfoService {
@Autowired
DoctorInfoMapper doctorInfoMapper;
@Override
public int addBatchSomeColumn(List<DoctorInfo> doctorInfoList){
try{
for(DoctorInfo doctorInfo : doctorInfoList){
doctorInfoMapper.insert(doctorInfo);
}
}catch (Exception e){
e.printStackTrace();
return 0;
}
return 1;
}
@Override
public List<DoctorInfo> getDoctorInfoList() {
QueryWrapper<DoctorInfo> queryWrapper = new QueryWrapper<>();
queryWrapper.ne("id","");
List<DoctorInfo> doctorInfoList = doctorInfoMapper.selectList(queryWrapper);
return doctorInfoList;
}
}
- mapper目录下的:
DoctorInfoMapper接口:
import cn.cggeeker.doctorcrawler.pojo.DoctorInfo;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.baomidou.mybatisplus.core.toolkit.Constants;
import com.baomidou.mybatisplus.extension.injector.methods.InsertBatchSomeColumn;
import com.baomidou.mybatisplus.extension.injector.methods.LogicDeleteByIdWithFill;
import org.apache.ibatis.annotations.Param;
import java.util.List;
/**
* 这里mapper接口直接继承mybatis-plus的BaseMapper<T>接口,这样省去了自己写简单sql的时间
*/
public interface DoctorInfoMapper extends BaseMapper<DoctorInfo> {
}
2.定位网页标签并利用jsoup抓取网页数据
2.1 分析目标网页
本次演示的是爬取微医网页上的医生数据:
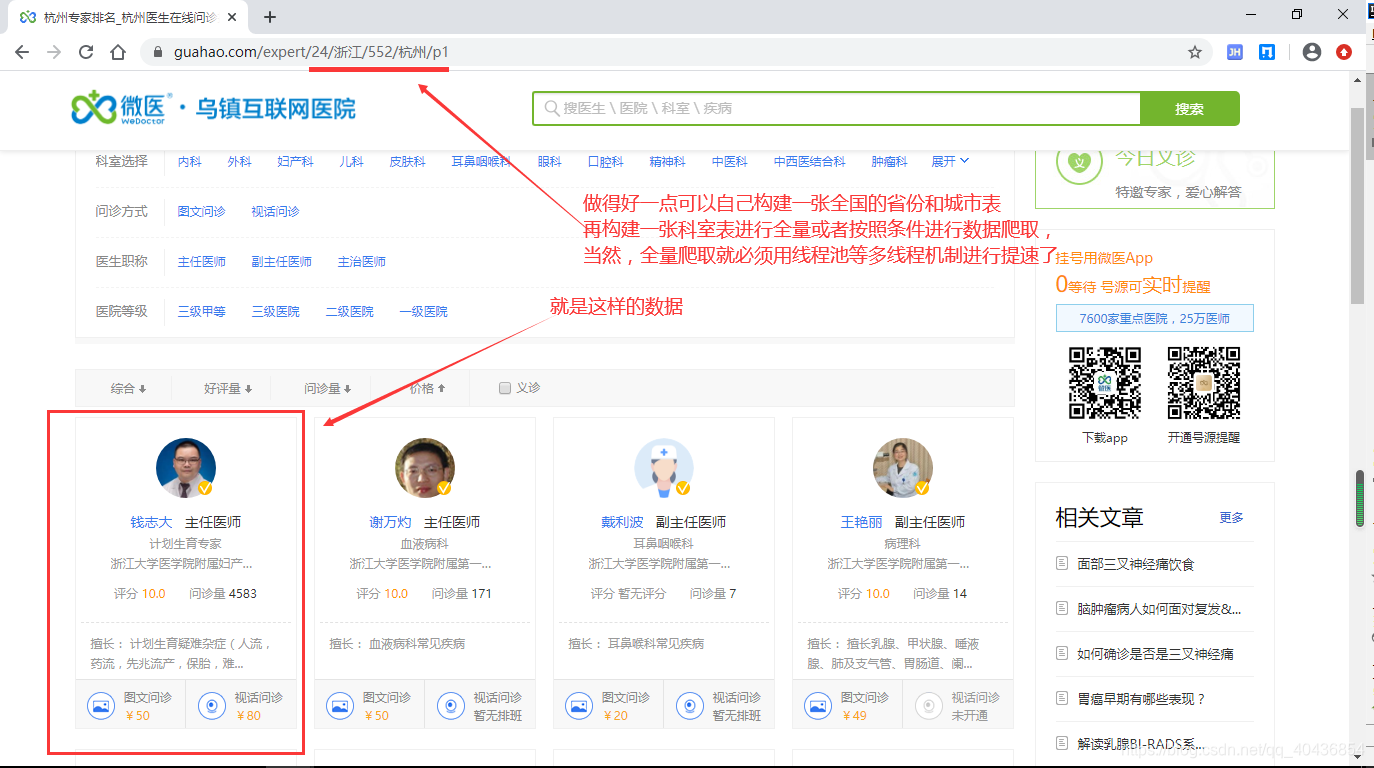
由于本次只是小白入门级别的,就不打算用多线程全量爬取微医网上医生数据了,见谅。
对目标网页标签进行分析:
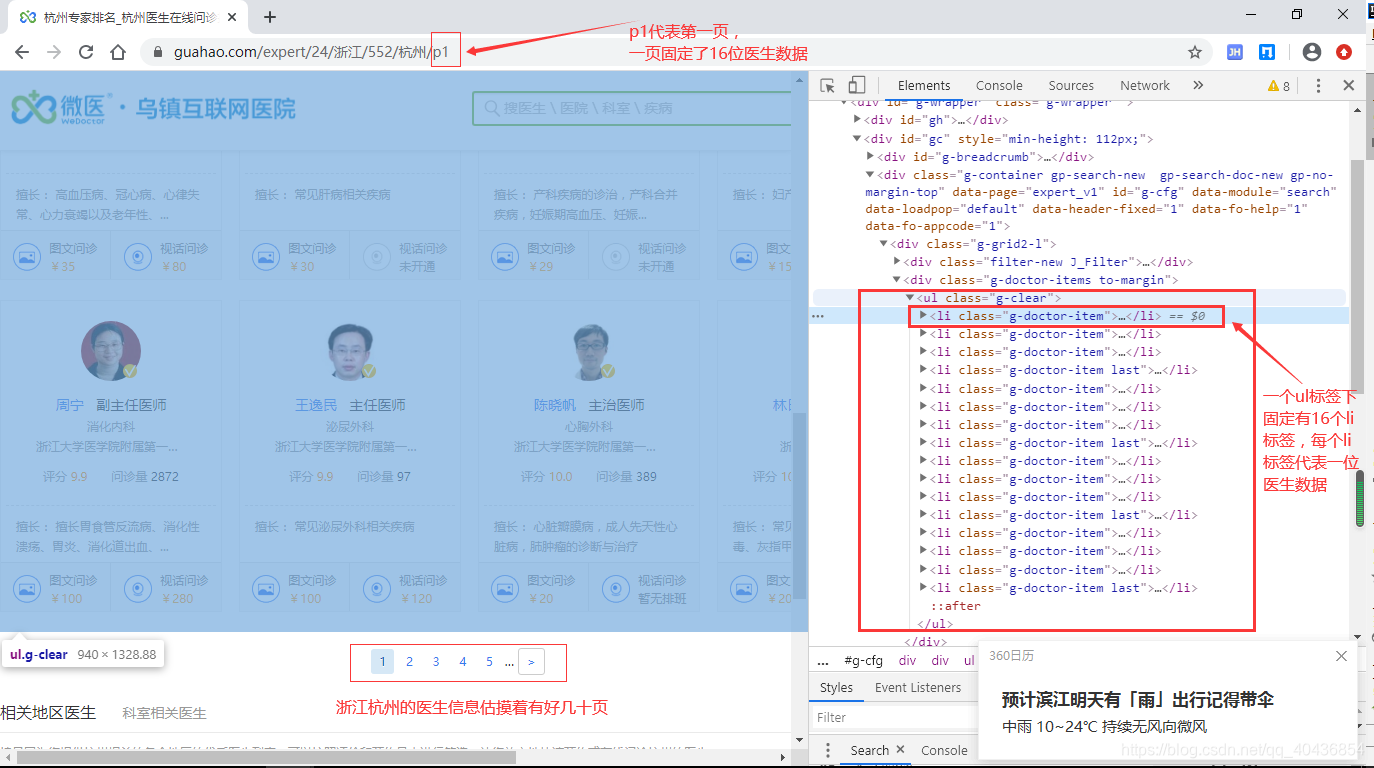
打开li标签
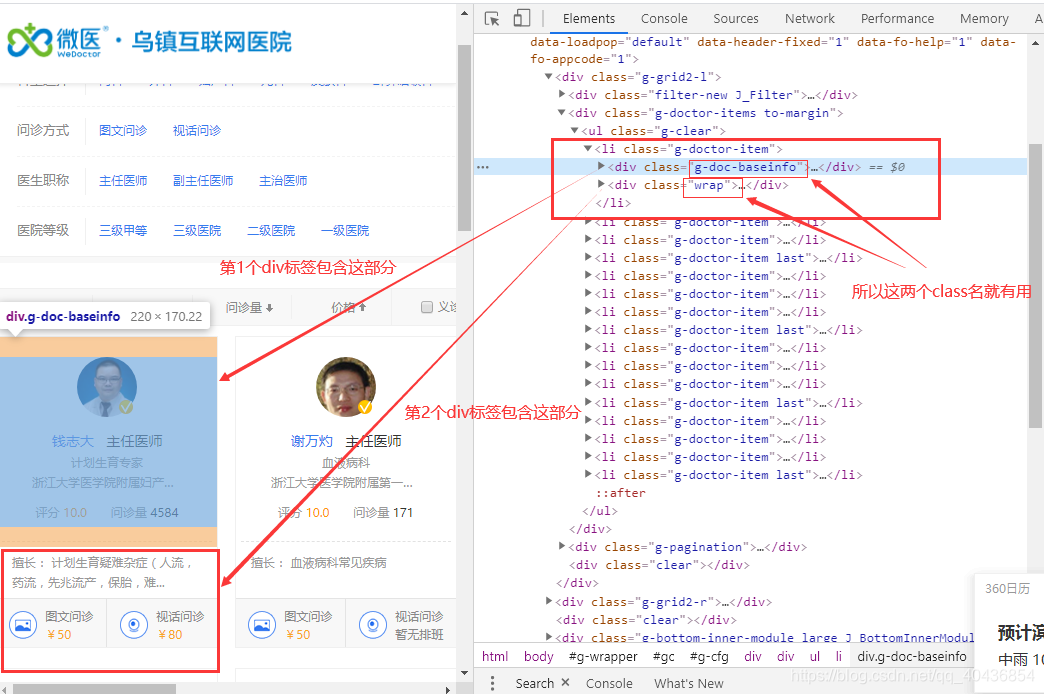
继续分析第一个div标签
分析第2个div标签
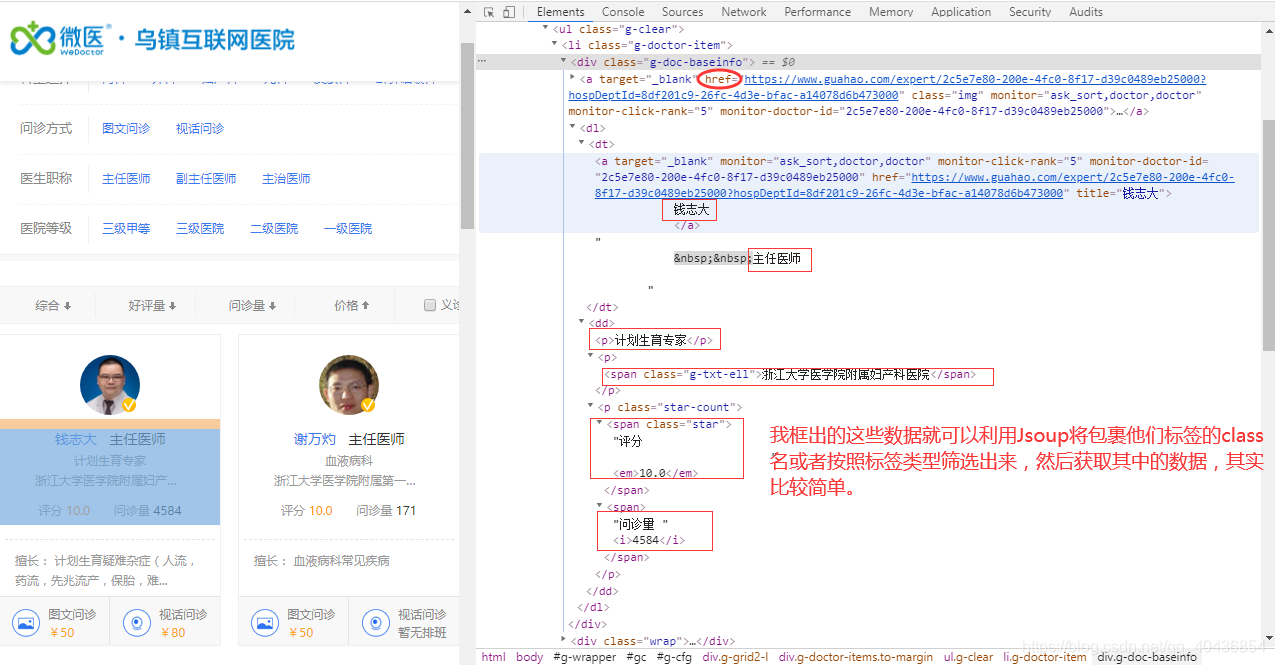
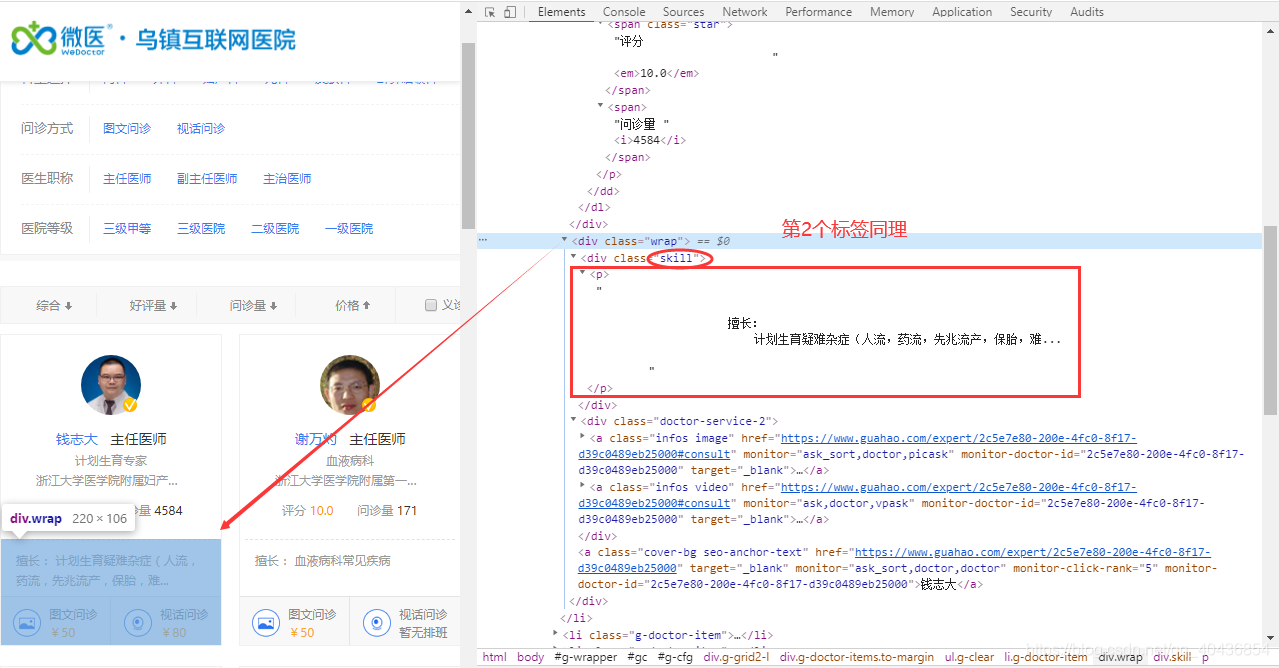
2.2 utils目录下CrawlerDoctorInfoUtil类的全量代码
其实也很简单,都是一些jsoup的基础用法,想了解更多用法可以去官网自行查阅。
import cn.cggeeker.doctorcrawler.pojo.DoctorInfo;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@Component
public class CrawlerDoctorInfoUtil {
public List<DoctorInfo> getDoctorInfoList(String url) {
// 用List存放爬取的医生数据
List<DoctorInfo> doctorInfoList = new ArrayList<>();
// html的Document对象
Document doc = null;
// 微医网页上一个城市的医生数据最多只有39页,故这个循环每执行一次就修改一次url指向的页号
for (int page = 1; page < 39; page++) {
if(page < 11){
url = url.substring(0,url.length()-1) + page;
}else{
url = url.substring(0,url.length()-2) + page;
}
try {
doc = Jsoup.connect(url).get(); // 利用jsoup连接目标url网页获取整个html对象
} catch (IOException e) {
e.printStackTrace();
}
// 调用Document对象的api并用类似于css选择器的方法筛选出li标签对象集合,为空说明此页没有相应的li标签直接break
if(doc.select("li[class^=g-doctor-item]").size() == 0){
break;
}
// 如果有相应的class名为“g-doctor-item”的li标签就对其遍历,然后按照同样的方式一层层获取想要的数据即可
for (int j = 0; j < doc.select("li[class^=g-doctor-item]").size(); j++) {
DoctorInfo doctorInfo = new DoctorInfo();
if (null != doc) {
/* Element doctorli = doc.selectFirst("li[class=g-doctor-item]");*/
Element doctorli = doc.select("li[class^=g-doctor-item]").get(j);
if (null != doctorli) {
//提取姓名与职称
Element div1 = doctorli.selectFirst("div[class=g-doc-baseinfo]");
Element div2 = doctorli.selectFirst("div[class=wrap]");
if (null != div1) {
Element img = div1.selectFirst("img");
if (null != img) {
doctorInfo.setHeadurl(img.attr("src").toString());
}
}
//提取是否为专家
Element dt1 = div1.selectFirst("dt");
if (null != dt1) {
String[] nameAndJob = dt1.text().split(" ");
doctorInfo.setName(nameAndJob[0]);
doctorInfo.setJob(nameAndJob[1]);
}
//提取医院和科室,评分和问诊量
Element dd1 = div1.selectFirst("dd");
if (null != dd1) {
Element p1 = dd1.selectFirst("p");
Element p2 = dd1.select("p").get(1).selectFirst("span");
Element em = dd1.selectFirst("p[class=star-count]").selectFirst("span[class=star]").selectFirst("em");
Element i = dd1.selectFirst("p[class=star-count]").select("span").get(1).selectFirst("i");
if (null != p1) {
doctorInfo.setLastroom(p1.text());
}
if (null != p2) {
doctorInfo.setHospital(p2.text());
}
if(null != em){
doctorInfo.setMarks(em.text());
}
if(null != i){
doctorInfo.setAsk(Integer.parseInt(i.text()));
}
}
//提取擅长领域
Element skilldiv = div2.selectFirst("div[class=skill]");
if(null != skilldiv){
Element p = skilldiv.selectFirst("p");
if(null != p){
doctorInfo.setGoodat(p.text());
}
}
}
}
// 使用雪花算法生成id
long id = SnowflakeIdWorker.generateId();
doctorInfo.setId(id);
doctorInfoList.add(doctorInfo);
}
}
return doctorInfoList;
}
}
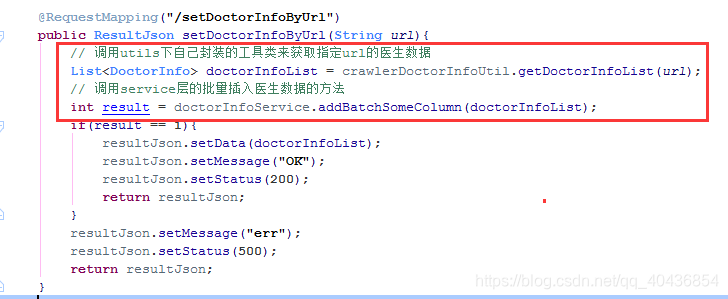
3.将网页数据持久化至数据库
其实前面就已经将所有目录的全量代码贴上了,持久化数据也就是下面这两行调用而已
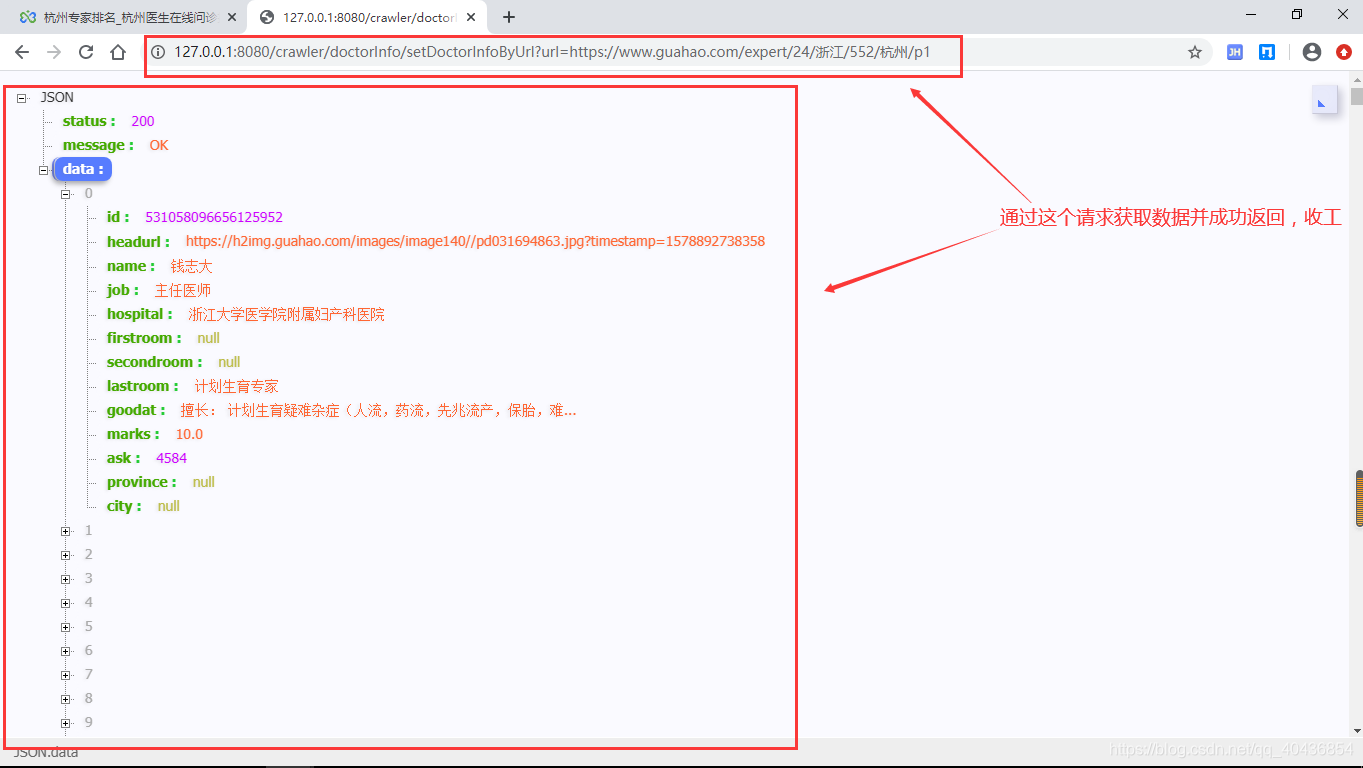
4.测试与验证
简单的在谷歌浏览器上测试一把
感谢阅读,欢迎评论和点赞!咋们下期再见啦。