目录
前言
最近心血来潮想看看 OCR 相关的任务,想通过调试分析 PaddleOCR 代码把 PP-OCRv4 模型导出,并在 tensorRT 上推理得到结果,这篇文章主要分析 PP-OCRv4 模型的 ONNX 导出以及解决导出过程中遇到的各种问题。若有问题欢迎各位看官批评指正😄
1. 概述
正式开始之前我们还是对相关知识做一些补充🤗
1.1 OCR
Note:以下内容均 Copy 自:《动手学 OCR》电子书
OCR(Optical Character Recognition,光学字符识别)是计算机视觉重要方向之一。传统定义的 OCR 一般面向扫描文档类对象,现在我们常说的 OCR 一般指场景文字识别(Scene Text Recognition,STR),主要面向自然场景,如下图中所示的车牌等各种自然场景可见的文字:

虽然 OCR 是一个相对具体的任务,但涉及了多方面的技术,包括文本检测、文本识别、端到端文本识别、文档分析等等,下面我们主要介绍下 PP-OCRv4 中比较关键的文本检测和文本识别技术
目前较为流行的文本检测算法可以大致分为基于回归和基于分割的两大类文本检测算法,也有一些算法将二者相结合。基于回归的算法借鉴通用物体检测算法,通过设定 anchor 回归检测框,或者直接做像素回归,这类方法对规则形状文本检测效果较好,但是对不规则形状的文本检测效果会相对差一些;基于分割的算法在各种场景、对各种形状文本的检测效果都可以达到一个更高的水平,但缺点就是后处理一般会比较复杂,因此常常存在速度问题,并且无法解决重叠文本的检测问题
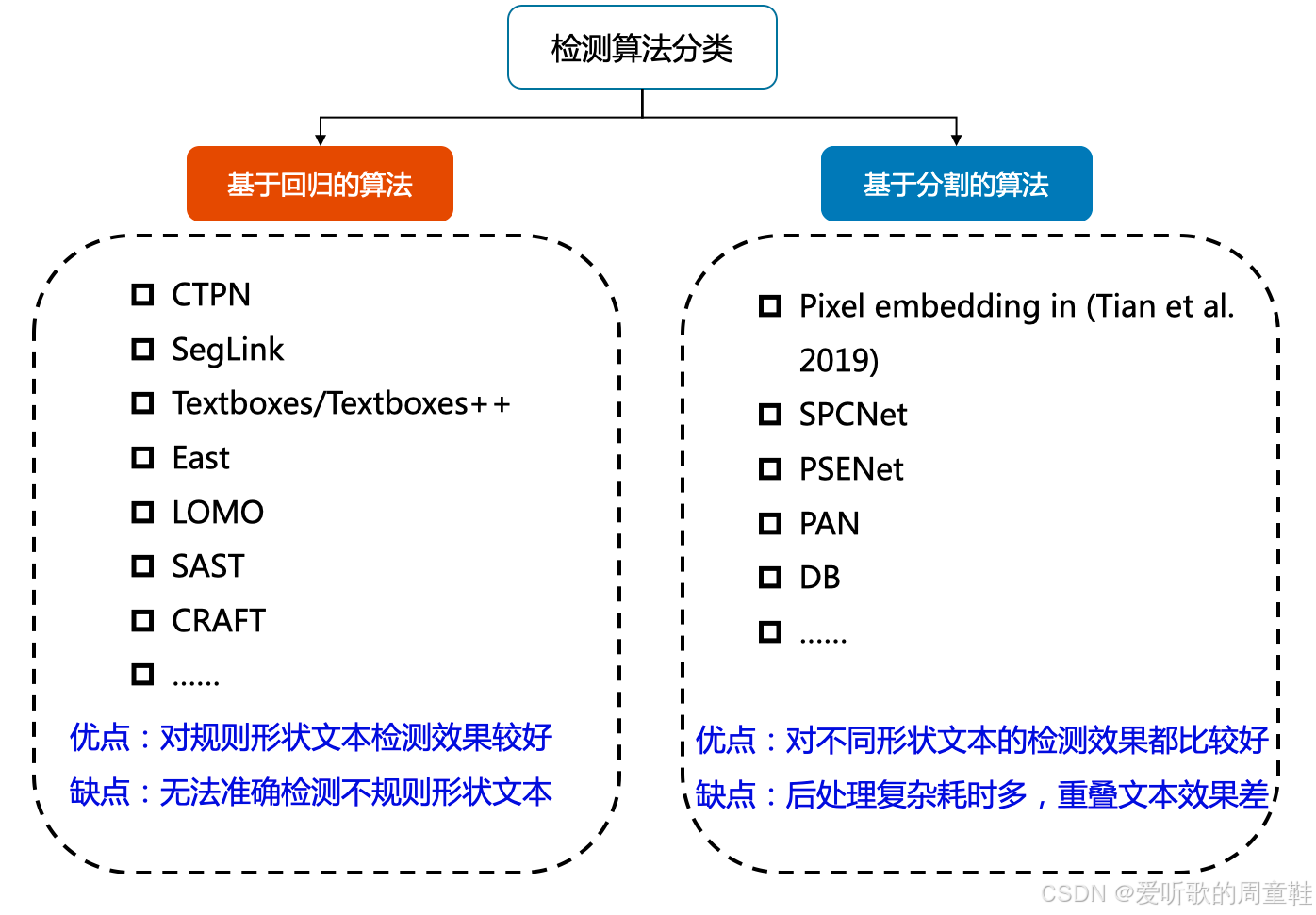
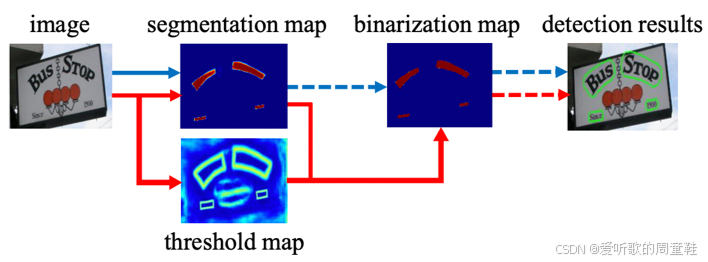
Note:PP-OCRv4 中的文本检测算法是基于分割的算法即 DBNet,因此其后处理比较复杂,这个我们在后续梳理模型的预处理和后处理时能够感受到
文本识别的任务是识别出图像中的文字内容,一般输入来自于文本检测得到的文本框截取出的图像文字区域。文本识别一般可以根据待识别文本形状分为规则文本识别和不规则文本识别两大类。规则文本主要指印刷字体、扫描文本等,文本大致处在水平线位置;不规则文本往往不在水平位置,存在弯曲、遮挡、模糊等问题。不规则文本场景具有很大的挑战性,也是目前文本识别领域的主要研究方向

规则文本识别的算法根据解码方式的不同可以大致分为基于 CTC 和 Sequence2Sequence 两种,将网络学习到的序列特征 转化为 最终的识别结果 的处理方式不同
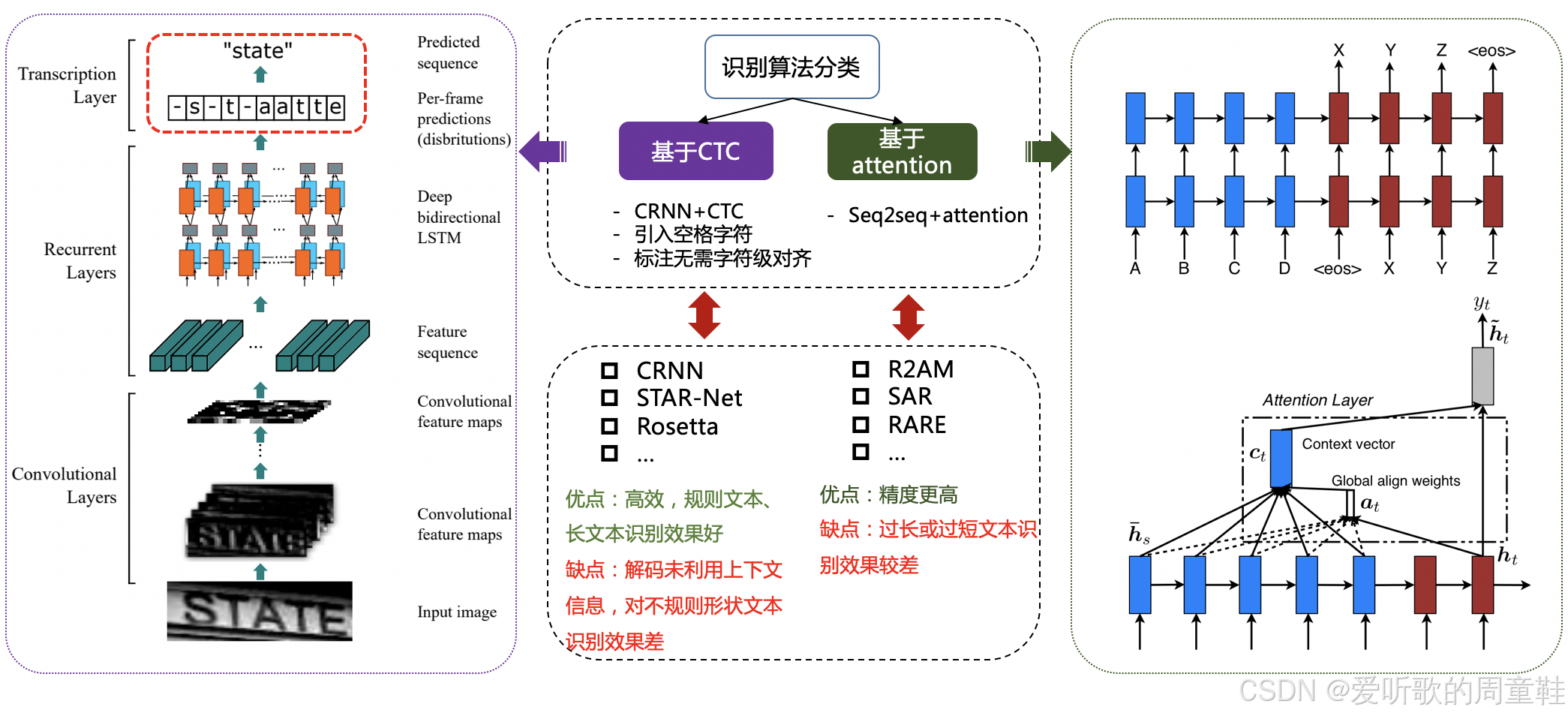
不规则文本的识别算法相比更为丰富,如 STAR-Net 等方法通过加入 TPS 等矫正模块,将不规则文本矫正为规则的矩形后再进行识别;RARE 等基于 Attention 的方法增强了对序列之间各部分相关性的关注;基于分割的方法将文本行的各字符作为独立个体,相比与对整个文本行做矫正后识别,识别分割出的单个字符更加容易

Note:PP-OCRv4 中的文本识别算法是 SVTR
1.2 PaddleOCR
Note:以下内容均 Copy 自:https://github.com/PaddlePaddle/PaddleOCR/README.md
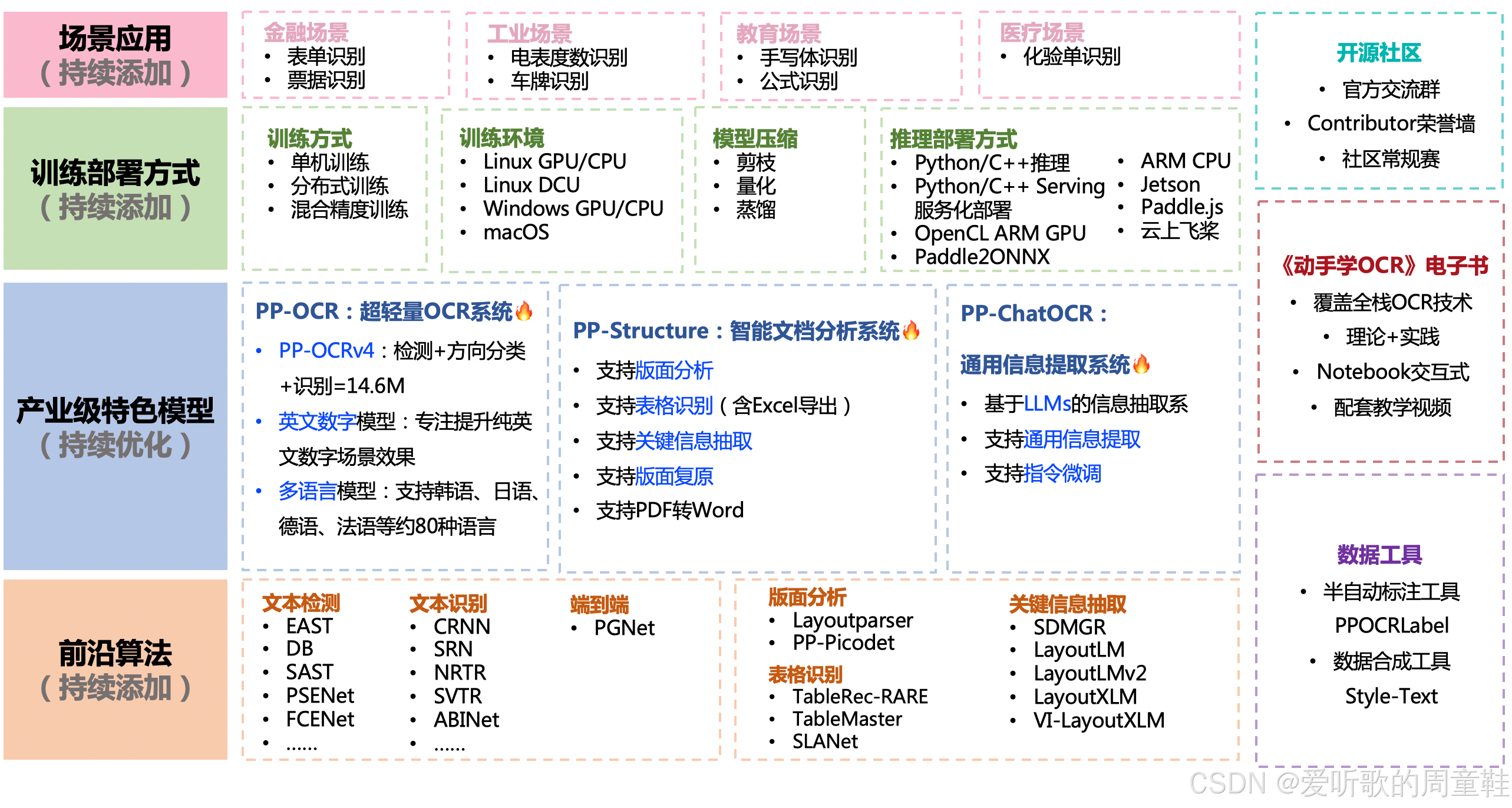
PaddleOCR 是百度深度学习框架 PaddlePaddle 开源的 OCR 项目,旨在打造一套丰富、领先、且实用的 OCR 工具库,助力使用者训练出更好的模型,并应用落地,PaddleOCR 包含丰富的文本检测、文本识别以及端到端算法。
PaddleOCR 支持多种 OCR 相关前言算法,在此基础上打造产业级特色模型 PP-OCR、PP-Structure 和 PP-ChatOCRv2,并打通数据生产、模型训练、压缩、预测部署全流程。
1.3 PP-OCRv4
Note:以下内容均 Copy 自:https://github.com/PaddlePaddle/PaddleOCR/PP-OCRv4_introduction.md
PP-OCR 是 PaddleOCR 开源的通用 OCR 算法,目前已经迭代到第 4 代,PP-OCRv4 在 PP-OCRv3 的基础上进一步升级。整体的框架图保持了与 PP-OCRv3 相同的 pipeline,针对检测模型和识别模型进行了数据、网络结构、训练策略等多个模块的优化,PP-OCRv4系统框图如下所示:
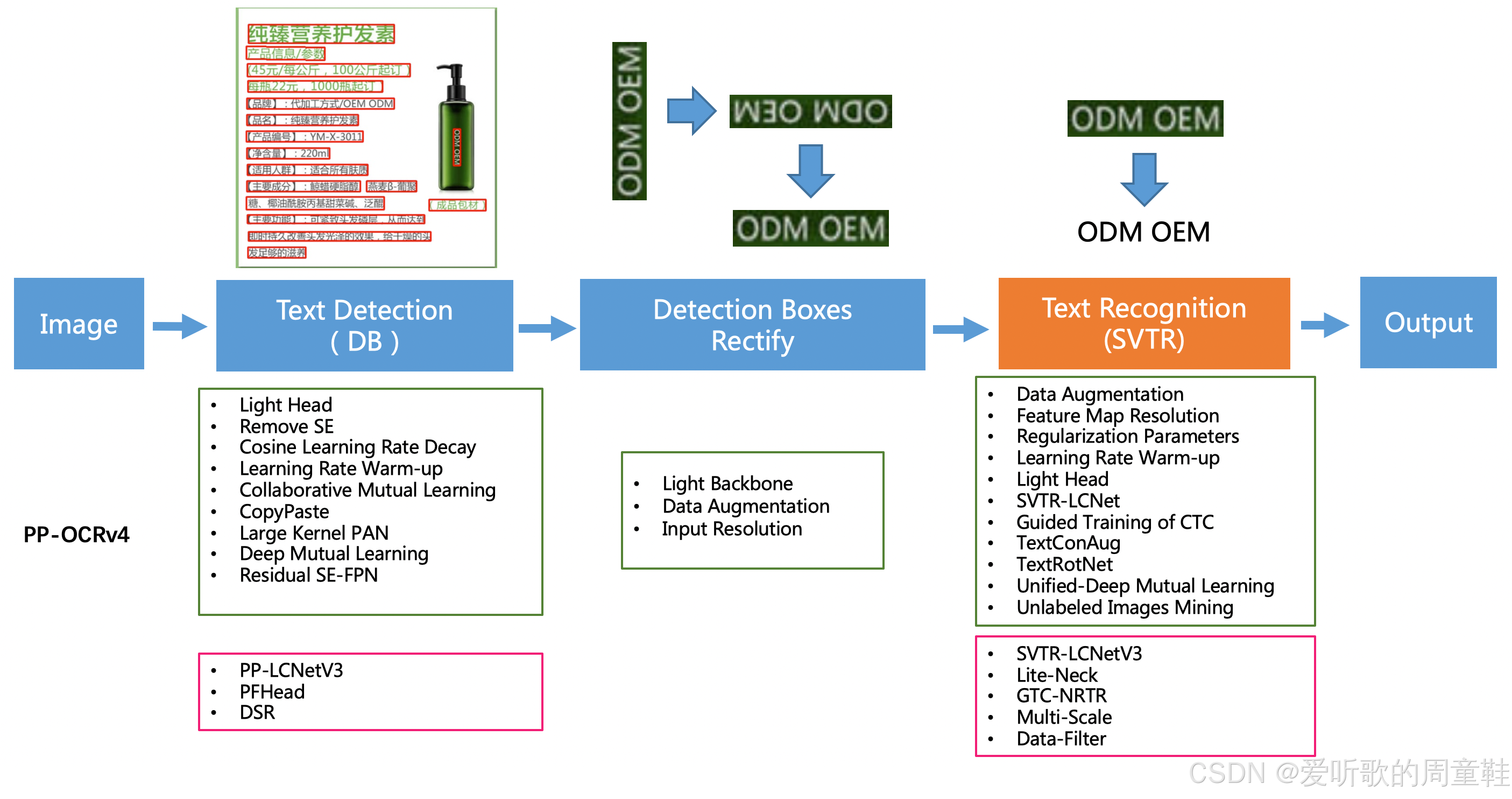
从算法改进思路上看,分别针对检测和识别模型,进行了共 10 个方面的改进:
- 检测模块:
- LCNetV3:精度更高的骨干网络
- PFHead:并行 head 分支融合结构
- DSR: 训练中动态增加 shrink ratio
- CML:添加 Student 和 Teacher 网络输出的 KL div loss
- 识别模块:
- SVTR_LCNetV3:精度更高的骨干网络
- Lite-Neck:精简的 Neck 结构
- GTC-NRTR:稳定的 Attention 指导分支
- Multi-Scale:多尺度训练策略
- DF: 数据挖掘方案
- DKD :DKD 蒸馏策略
更多细节大家可以查看:PP-OCRv4_introduction.md
PP-OCRv4 中还有一个文本方向分类器模块,它主要用于图片非 0° 的场景下,在这种场景下需要对图片里检测到的文本行进行一个转正的操作,如下图所示:

PaddleOCR 内置的文本方向分类器只支持 0° 和 180° 的分类,如果想支持更多角度,可以自己修改算法进行支持
2. 环境配置
在开始之前我们有必要配置下环境,PP-OCRv4 的环境可以通过 doc/quickstart.md 文档中安装
博主这里准备了一个可以运行 demo 和导出 ONNX 的环境,大家可以按照这个环境来,也可以自己参考文档进行相关环境配置
博主的环境安装指令如下所示:
conda create --name paddleocr python=3.9
conda activate paddleocr
pip install shapely scikit-image imgaug pyclipper lmdb tqdm numpy==1.26.4 rapidfuzz onnxruntime
pip install "opencv-python<=4.6.0.66" "opencv-contrib-python<=4.6.0.66" cython "Pillow>=10.0.0" pyyaml requests
pip install paddlepaddle paddleocr paddle2onnx
Note:这个环境博主目前只用于 demo 测试和 ONNX 导出,并不包含训练
为了不必要的错误,博主将虚拟环境中各个软件的版本都罗列出来,方便大家查看,环境如下:
Package Version
---------------------- -----------
anyio 4.4.0
astor 0.8.1
attrdict 2.0.1
Babel 2.15.0
bce-python-sdk 0.9.17
beautifulsoup4 4.12.3
blinker 1.8.2
cachetools 5.4.0
certifi 2024.7.4
charset-normalizer 3.3.2
click 8.1.7
colorama 0.4.6
coloredlogs 15.0.1
contourpy 1.2.1
cssselect 1.2.0
cssutils 2.11.1
cycler 0.12.1
Cython 3.0.10
decorator 5.1.1
et-xmlfile 1.1.0
exceptiongroup 1.2.2
fire 0.6.0
Flask 3.0.3
flask-babel 4.0.0
flatbuffers 24.3.25
fonttools 4.53.1
future 1.0.0
h11 0.14.0
httpcore 1.0.5
httpx 0.27.0
humanfriendly 10.0
idna 3.7
imageio 2.34.2
imgaug 0.4.0
importlib_metadata 8.0.0
importlib_resources 6.4.0
itsdangerous 2.2.0
Jinja2 3.1.4
kiwisolver 1.4.5
lanms_neo 1.0.2
lazy_loader 0.4
lmdb 1.5.1
lxml 5.2.2
markdown-it-py 3.0.0
MarkupSafe 2.1.5
matplotlib 3.9.1
mdurl 0.1.2
more-itertools 10.3.0
mpmath 1.3.0
networkx 3.2.1
numpy 1.26.4
onnx 1.16.1
onnx-graphsurgeon 0.5.2
onnx-simplifier 0.4.36
onnxruntime 1.18.1
opencv-contrib-python 4.6.0.66
opencv-python 4.6.0.66
opencv-python-headless 4.10.0.84
openpyxl 3.1.5
opt-einsum 3.3.0
packaging 24.1
paddle2onnx 1.0.6
paddleocr 2.8.1
paddlepaddle 2.6.1
pandas 2.2.2
pdf2docx 0.5.8
pillow 10.4.0
pip 24.0
Polygon3 3.0.9.1
premailer 3.10.0
protobuf 3.20.2
psutil 6.0.0
pyclipper 1.3.0.post5
pycryptodome 3.20.0
Pygments 2.18.0
PyMuPDF 1.19.0
pyparsing 3.1.2
pyreadline3 3.4.1
python-dateutil 2.9.0.post0
python-docx 1.1.2
pytz 2024.1
PyYAML 6.0.1
rapidfuzz 3.9.4
rarfile 4.2
requests 2.32.3
rich 13.7.1
scikit-image 0.24.0
scipy 1.13.1
setuptools 69.5.1
shapely 2.0.5
six 1.16.0
sniffio 1.3.1
soupsieve 2.5
sympy 1.13.1
termcolor 2.4.0
tifffile 2024.7.2
tqdm 4.66.4
typing_extensions 4.12.2
tzdata 2024.1
urllib3 2.2.2
visualdl 2.5.3
Werkzeug 3.0.3
wheel 0.43.0
zipp 3.19.2
3. Demo测试
OK,环境准备好后我们就要开始执行 demo,具体流程可以参照:https://github.com/PaddlePaddle/PaddleOCR/main/doc/inference_ppocr.md
我们一个个来,首先是推理验证测试,教程给的推理脚本如下所示:
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./ch_PP-OCRv3_det_infer/" --cls_model_dir="./cls/" --rec_model_dir="./ch_PP-OCRv3_rec_infer/" --use_angle_cls=true
在这之前我们需要把 PaddleOCR 这个项目给 clone 下来,执行如下指令:
git clone https://github.com/PaddlePaddle/PaddleOCR.git
也可手动点击下载,点击右上角的 Code 按键,将代码下载下来。至此整个项目就已经准备好了。
同时还要下载相关的预训练权重用于 Demo 测试和 ONNX 导出,PP-OCRv4 的预训练权重可以在 PP-OCR 系列模型列表中找到,如下所示:

可以看到 PP-OCRv4 模型主要有推理和训练两个部分,博主这边选择的是红色框的推理模型进行后续的 Demo 测试和 ONNX 导出,大家点击即可进行下载,前面我们提到过 PP-OCRv4 包含检测、方向分类器、识别三个模块,就对应这里的三个模型
大家也可以点击 here 下载博主准备好的源码和权重(注意代码下载于 2024/7/20 日,如果改动请参考最新)
下载好后是三个压缩包,我们需要解压缩,在解压之前我们需要创建好相应的文件夹方便后续模型的指定。在下载好的 PaddleOCR 源码下新建一个 models 文件夹,接着在 models 文件夹下新建 det、cls、rec 三个文件夹分别存放检测模型、方向分类器模型和识别模型
将下载好的压缩包分别放在这三个文件夹下进行解压,解压后完整的目录如下图所示:
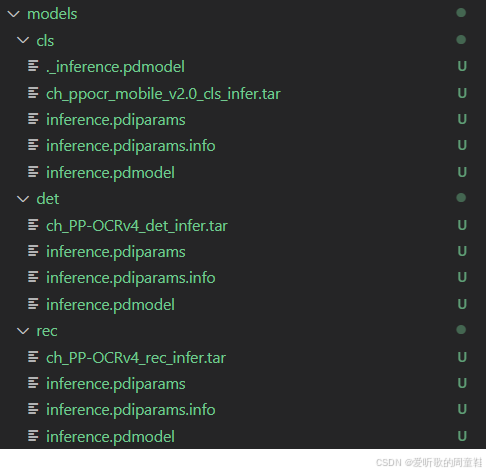
Note:因为是 PaddlePaddle 框架训练出来的模型,所以存储方式可能和我们熟悉的 Pytorch 模型略有不同,大家习惯就好
源码和模型都准备好后,执行如下指令即可进行推理:
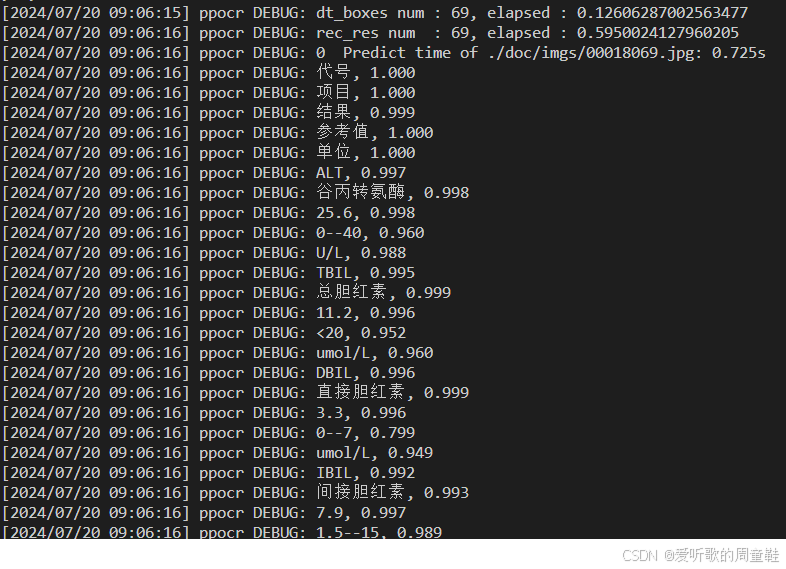
python tools/infer/predict_system.py --use_gpu=False --cls_model_dir=./models/cls --rec_model_dir=./models/rec --det_model_dir=./models/det --image_dir=./doc/imgs/00018069.jpg
部分输出如下图所示:
可以看到模型正常推理了,在 inference.results 文件夹下保存了推理好的图片,如下图所示:
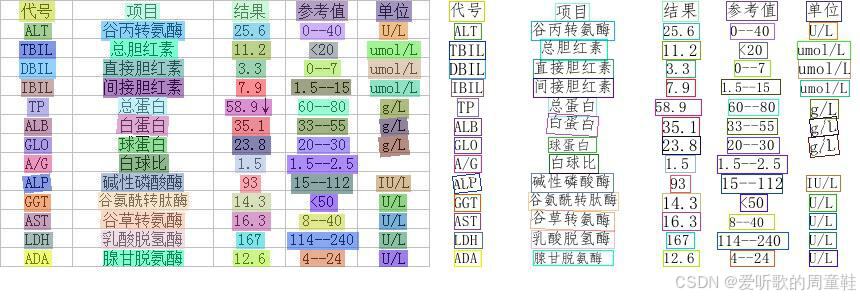
其中左边部分是原图,右边部分是 OCR 模型推理出来的结果,可以看到效果还是不错的,下面我们就开始尝试将 PP-OCRv4 的 ONNX 导出来
4. ONNX导出
PaddleOCR 官方提供了 Paddle2ONNX 工具支持将 PaddlePaddle 模型格式转化到 ONNX 模型格式
ONNX 的导出也可以参照:https://github.com/PaddlePaddle/PaddleOCR/blob/main/deploy/paddle2onnx/readme_ch.md
4.1 检测模型ONNX导出
执行如下脚本即可完成检测模型的 ONNX 导出:
paddle2onnx --model_dir ./models/det --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./models/det/det.onnx --opset_version 16 --enable_onnx_checker True
Note:opset_version 根据官方说明目前支持 7~16 等多个版本,博主设置为 16 目的是尽可能将一些算子融合导出
输出如下:
可以看到 ONNX 模型正常导出了,导出好的 ONNX 保存在 models/det 文件夹下,导出的 ONNX 部分结构如下图所示:
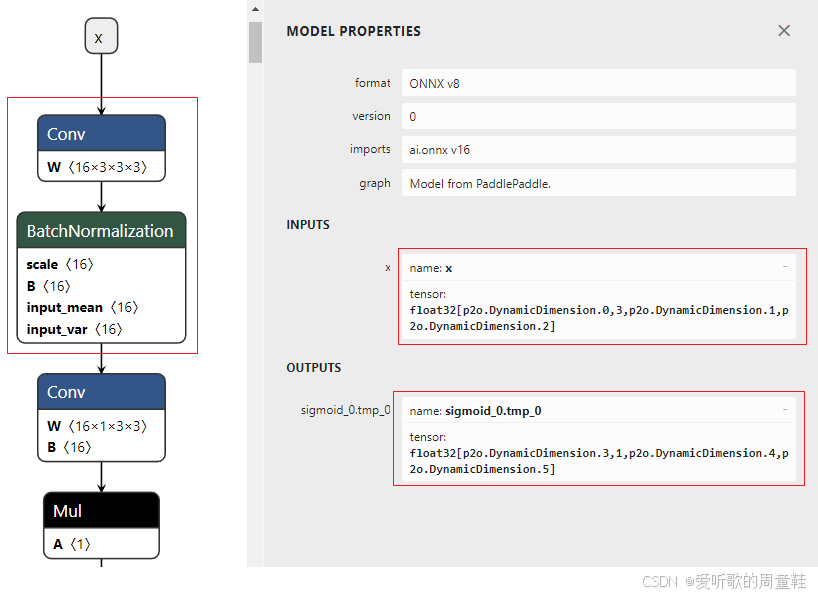
导出的 ONNX 存在一些问题,我们需要修改:
- 宽高不动态
- 宽高固定主要是方便 TensorRT 的推理
- Conv 和 BN 层融合
- 算子融合可以提高计算效率、减少操作数、降低延迟
- 输入输出节点名修改成 images 和 output
- 节点名修改纯粹是因为博主强迫症
我们先来看动态宽高的问题,在 Paddle2ONNX 中官方提供了 Paddle 模型优化工具,修改 Paddle 模型输入 Shape,具体可参考:https://github.com/PaddlePaddle/Paddle2ONNX/tree/develop/tools/paddle
我们在 PaddleOCR 下新建一个 infer_paddle_model_shape.py 脚本文件来修改 Paddle 模型的输入,其代码如下:
import argparse
import paddle
import paddle.base as base
import paddle.static as static
def process_old_ops_desc(program):
for i in range(len(program.blocks[0].ops)):
if program.blocks[0].ops[i].type == "matmul":
if not program.blocks[0].ops[i].has_attr("head_number"):
program.blocks[0].ops[i]._set_attr("head_number", 1)
def infer_shape(program, input_shape_dict):
paddle.enable_static()
OP_WITHOUT_KERNEL_SET = {
'feed', 'fetch', 'recurrent', 'go', 'rnn_memory_helper_grad',
'conditional_block', 'while', 'send', 'recv', 'listen_and_serv',
'fl_listen_and_serv', 'ncclInit', 'select', 'checkpoint_notify',
'gen_bkcl_id', 'c_gen_bkcl_id', 'gen_nccl_id', 'c_gen_nccl_id',
'c_comm_init', 'c_sync_calc_stream', 'c_sync_comm_stream',
'queue_generator', 'dequeue', 'enqueue', 'heter_listen_and_serv',
'c_wait_comm', 'c_wait_compute', 'c_gen_hccl_id', 'c_comm_init_hccl',
'copy_cross_scope'
}
model_version = program.desc._version()
paddle_version = paddle.__version__
major_ver = model_version // 1000000
minor_ver = (model_version - major_ver * 1000000) // 1000
patch_ver = model_version - major_ver * 1000000 - minor_ver * 1000
model_version = "{}.{}.{}".format(major_ver, minor_ver, patch_ver)
if model_version != paddle_version:
print(
"[WARNING] The model is saved by paddlepaddle v{}, but now your paddlepaddle is version of {}, this difference may cause error, it is recommend you reinstall a same version of paddlepaddle for this model".
format(model_version, paddle_version))
for k, v in input_shape_dict.items():
program.blocks[0].var(k).desc.set_shape(v)
for i in range(len(program.blocks)):
for j in range(len(program.blocks[0].ops)):
if program.blocks[i].ops[j].type in OP_WITHOUT_KERNEL_SET:
continue
program.blocks[i].ops[j].desc.infer_shape(program.blocks[i].desc)
def parse_arguments():
parser = argparse.ArgumentParser()
parser.add_argument(
'--model_path',
required=True,
help='Directory path to input model + model name without suffix.')
parser.add_argument(
'--input_shape_dict', required=True, help="The new shape information.")
parser.add_argument(
'--save_path',
required=True,
help='Directory path to save model + model name without suffix.')
return parser.parse_args()
if __name__ == '__main__':
args = parse_arguments()
paddle.enable_static()
input_shape_dict_str = args.input_shape_dict
input_shape_dict = eval(input_shape_dict_str)
print("Start to load paddle model...")
exe = base.Executor(paddle.CPUPlace())
[program, feed_target_names, fetch_targets] = static.io.load_inference_model(args.model_path, exe)
process_old_ops_desc(program)
infer_shape(program, input_shape_dict)
feed_vars = [program.global_block().var(name) for name in feed_target_names]
static.io.save_inference_model(
args.save_path,
feed_vars=feed_vars,
fetch_vars=fetch_targets,
executor=exe,
program=program)
执行如下指令修改:
python infer_paddle_model_shape.py --model_path models/det/inference --save_path models/det/new_inference --input_shape_dict="{'x':[-1,3,960,960]}"
Note:博主这里将检测模型的宽高固定到 960x960,这其实是博主在后续分析检测模型的预处理时得到的信息
执行成功后在 models/det 文件夹下会多出 new_inference.pdiparams 和 new_inference.pdmodel,这是重新修改了输入后的新 Paddle 模型权重,如下图所示:

接着我们拿修改后的 Paddle 模型重新生成下 ONNX,指令如下:
paddle2onnx --model_dir ./models/det --model_filename new_inference.pdmodel --params_filename new_inference.pdiparams --save_file ./models/det/det.onnx --opset_version 16 --enable_onnx_checker True
新生成的 ONNX 如下图所示:
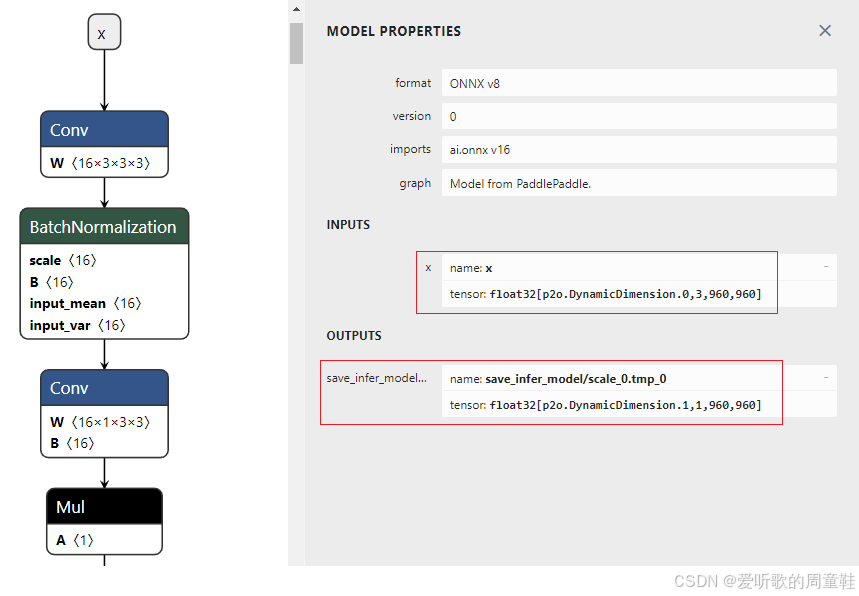
可以看到输入输出都只让 batch 维度动态,宽高固定,符合我们的预期
算子融合我们可以考虑利用 onnx-simplifier 来完成,节点名修改我们用 onnx_graphsurgeon 来操作
onnx-simplifier 是一个专门用于优化和简化ONNX模型的工具,它能够减少模型的复杂性,同时保持模型的计算精度,我们可以使用如下指令进行安装:
pip install onnx-simplifier
onnx_graphsurgeon 是 NVIDIA 提供的一个创建和修改 ONNX 的工具,我们可以使用如下指令进行安装:
python3 -m pip install onnx_graphsurgeon --index-url https://pypi.ngc.nvidia.com
关于 onnx-graph-surgeon 的使用我们在韩君老师的课程中有简单讲过,大家感兴趣的可以看看:三. TensorRT基础入门-onnx-graph-surgeon
我们在 PaddleOCR 下新建一个 onnx_optimizer.py 脚本文件来优化我们的 ONNX 模型,代码如下:(from ChatGPT)
import onnx
import onnxsim
import onnx.helper as helper
def rename_io_names(model_path, new_input_name, new_output_name):
# 加载ONNX模型
model = onnx.load(model_path)
# 获取模型的输入和输出
inputs = model.graph.input
outputs = model.graph.output
# 创建新的输入和输出Tensor, 保留原有属性
new_input = helper.make_tensor_value_info(
new_input_name,
inputs[0].type.tensor_type.elem_type,
[d.dim_param if d.dim_param else d.dim_value for d in inputs[0].type.tensor_type.shape.dim]
)
new_output = helper.make_tensor_value_info(
new_output_name,
outputs[0].type.tensor_type.elem_type,
[d.dim_param if d.dim_param else d.dim_value for d in outputs[0].type.tensor_type.shape.dim]
)
# 替换图中的节点引用
for node in model.graph.node:
for index, inp in enumerate(node.input):
if inp == inputs[0].name:
node.input[index] = new_input_name
for index, out in enumerate(node.output):
if out == outputs[0].name:
node.output[index] = new_output_name
# 替换旧的输入输出名
model.graph.input.remove(inputs[0])
model.graph.output.remove(outputs[0])
model.graph.input.insert(0, new_input)
model.graph.output.insert(0, new_output)
return model
if __name__ == "__main__":
model_onnx = rename_io_names("./models/det/det.onnx", "images", "output")
# 检查导入的onnx model
onnx.checker.check_model(model_onnx)
print(f"Simplifying with onnx-simplifier {onnxsim.__version__}...")
model_onnx, check = onnxsim.simplify(model_onnx)
assert check, "assert check failed"
onnx.save(model_onnx, "./models/det/det.sim.onnx")
执行如下指令优化:
python onnx_optimizer.py
执行成功后在 models/det 文件夹下会多出 det.sim.onnx 模型文件,这是优化后的 ONNX 模型,如下图所示:
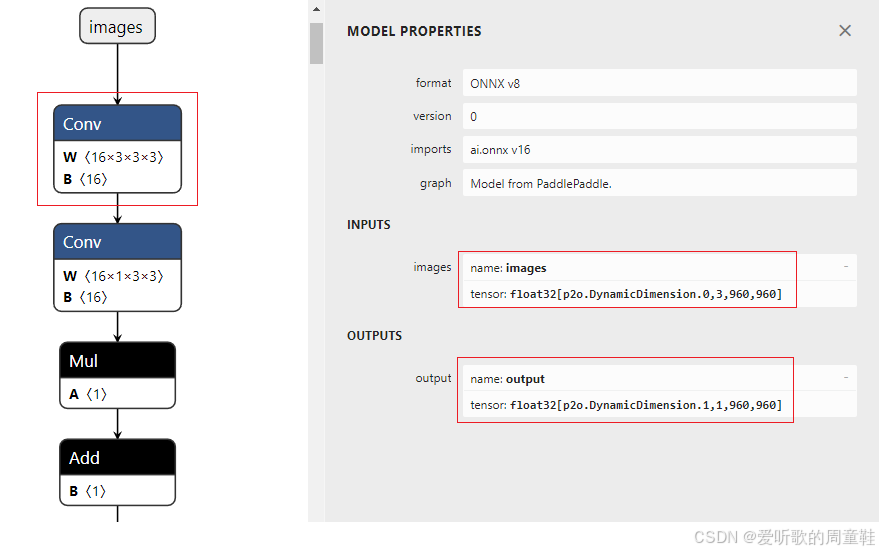
可以看到优化后的 ONNX 模型输入输出节点名完成了修改,Conv+BN 进行了融合,符合我们的预期
至此,检测模型的 ONNX 导出完成,下面我们来看方向分类器模型的 ONNX 导出
4.2 方向分类器模型ONNX导出
执行如下脚本即可完成方向分类器模型的 ONNX 导出:
paddle2onnx --model_dir ./models/cls --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./models/cls/cls.onnx --opset_version 16 --enable_onnx_checker True
Note:opset_version 根据官方说明目前支持 7~16 等多个版本,博主设置为 16 目的是尽可能将一些算子融合导出
输出如下:
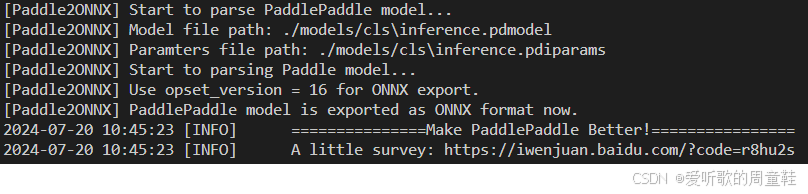
可以看到 ONNX 模型正常导出了,导出好的 ONNX 保存在 models/cls 文件夹下,导出的 ONNX 部分结构如下图所示:
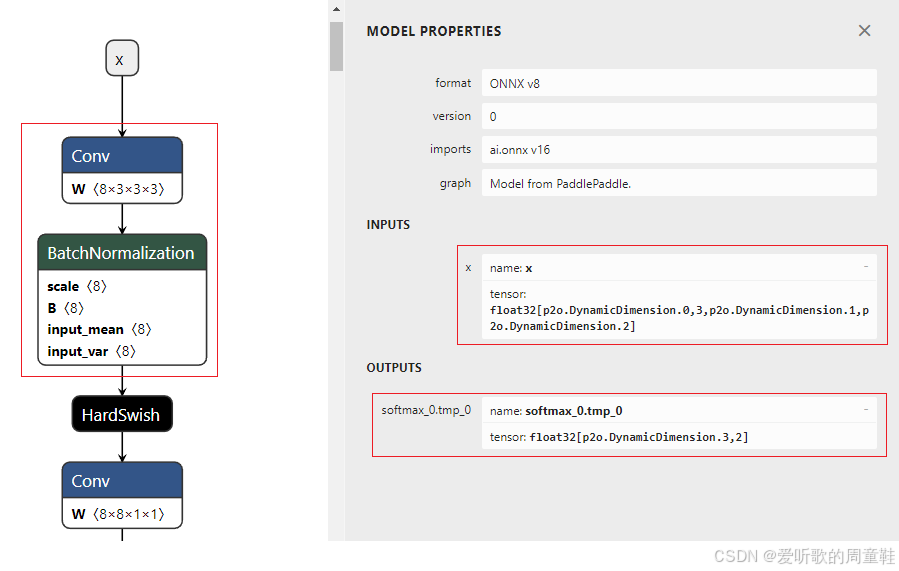
可以看到导出的 ONNX 和检测模型一样存在一些问题,我们需要修改:
- 宽高不动态
- Conv 和 BN 层融合
- 输入输出节点名修改成 images 和 output
利用前面的 infer_paddle_model_shape.py 脚本文件来修改 Paddle 模型的输入
执行如下指令修改:
python infer_paddle_model_shape.py --model_path models/cls/inference --save_path models/cls/new_inference --input_shape_dict="{'x':[-1,3,48,192]}"
Note:博主这里将检测模型的宽高固定到 192x48,这其实是博主在后续分析方向分类器模型的预处理时得到的信息
执行成功后在 models/cls 文件夹下会多出 new_inference.pdiparams 和 new_inference.pdmodel,这是重新修改了输入后的新 Paddle 模型权重,如下图所示:

接着我们拿修改后的 Paddle 模型重新生成下 ONNX,指令如下:
paddle2onnx --model_dir ./models/cls --model_filename new_inference.pdmodel --params_filename new_inference.pdiparams --save_file ./models/cls/cls.onnx --opset_version 16 --enable_onnx_checker True
新生成的 ONNX 如下图所示:
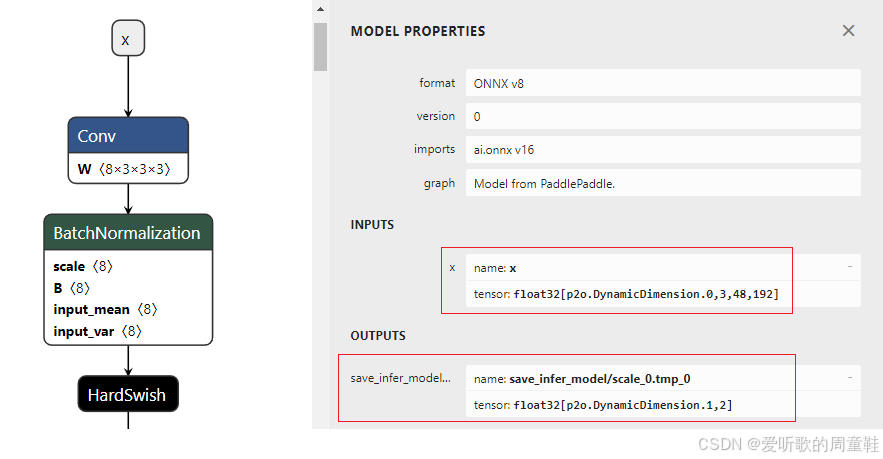
可以看到输入输出都只让 batch 维度动态,宽高固定,符合我们的预期
接着利用前面的 onnx_optimizer.py 脚本文件来优化 ONNX,代码简单修改下:
if __name__ == "__main__":
model_onnx = rename_io_names("./models/cls/cls.onnx", "images", "output")
# 检查导入的onnx model
onnx.checker.check_model(model_onnx)
print(f"Simplifying with onnx-simplifier {onnxsim.__version__}...")
model_onnx, check = onnxsim.simplify(model_onnx)
assert check, "assert check failed"
onnx.save(model_onnx, "./models/cls/cls.sim.onnx")
执行如下指令优化:
python onnx_optimizer.py
执行成功后在 models/cls 文件夹下会多出 cls.sim.onnx 模型文件,这是优化后的 ONNX 模型,如下图所示:
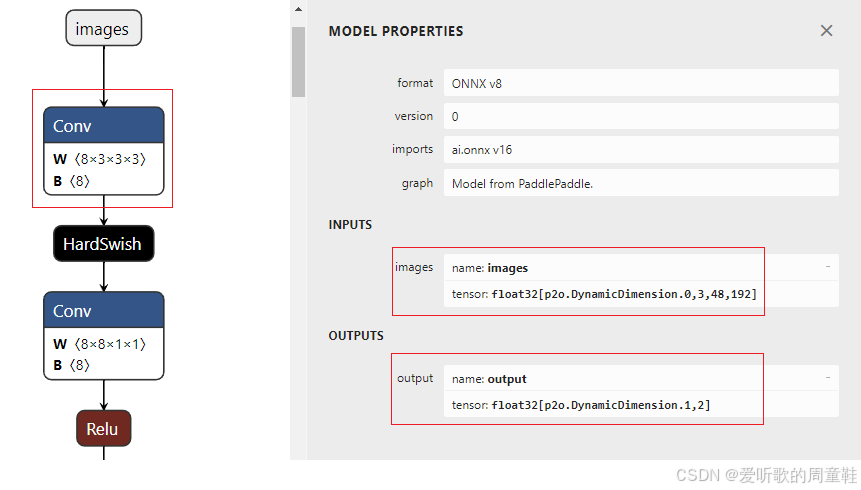
可以看到优化后的 ONNX 模型输入输出节点名完成了修改,Conv+BN 进行了融合,符合我们的预期
至此,方向分类器模型的 ONNX 导出完成,下面我们来看识别模型的 ONNX 导出
4.3 识别模型ONNX导出
执行如下脚本即可完成方向分类器模型的 ONNX 导出:
paddle2onnx --model_dir ./models/rec --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./models/rec/rec.onnx --opset_version 16 --enable_onnx_checker True
Note:opset_version 根据官方说明目前支持 7~16 等多个版本,博主设置为 16 目的是尽可能将一些算子融合导出
输出如下:
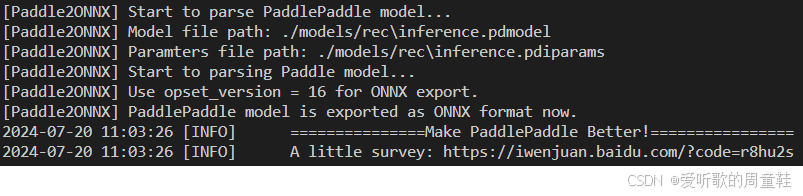
可以看到 ONNX 模型正常导出了,导出好的 ONNX 保存在 models/rec 文件夹下,导出的 ONNX 部分结构如下图所示:
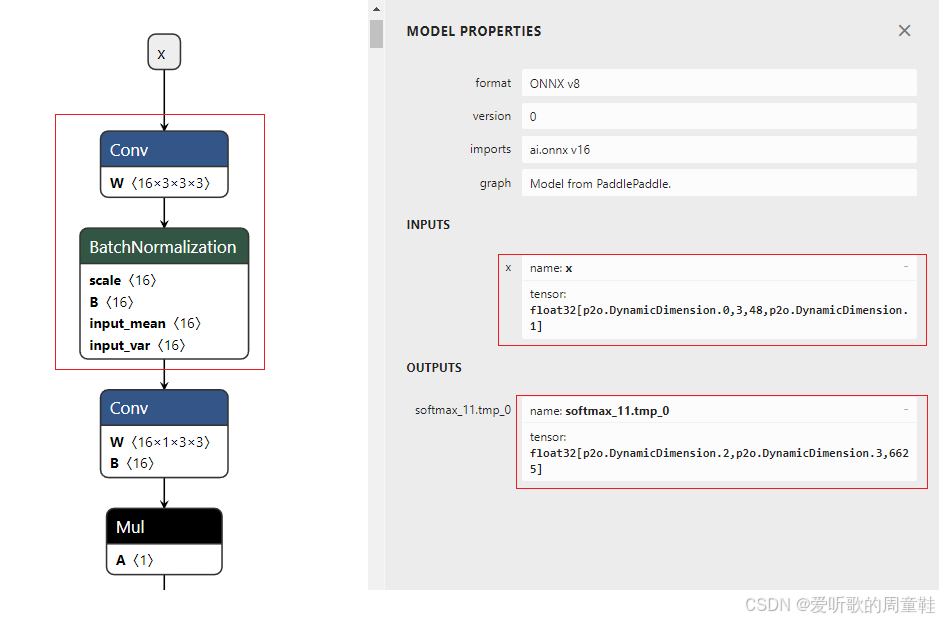
可以看到导出的 ONNX 和检测模型一样存在一些问题,我们需要修改:
- 宽高不动态
- 识别模型比较特殊,它的高度是固定的,但是宽度需要动态,这是因为需要根据不同的文本长度进行 resize,如果固定则会导致长文本识别率不行
- 但是博主这里还是将其长度固定在 640,不固定在 tensorRT 上处理会比较麻烦
- Conv 和 BN 层融合
- 输入输出节点名修改成 images 和 output
利用前面的 infer_paddle_model_shape.py 脚本文件来修改 Paddle 模型的输入
执行如下指令修改:
python infer_paddle_model_shape.py --model_path models/rec/inference --save_path models/rec/new_inference --input_shape_dict="{'x':[-1,3,48,640]}"
Note:博主在后续分析识别模型的预处理时宽度不固定,最小是缩放到 320,但是博主测试发现固定到 320 在长文本识别效果比较差,这里还是固定到 640
执行成功后在 models/rec 文件夹下会多出 new_inference.pdiparams 和 new_inference.pdmodel,这是重新修改了输入后的新 Paddle 模型权重,如下图所示:

接着我们拿修改后的 Paddle 模型重新生成下 ONNX,指令如下:
paddle2onnx --model_dir ./models/rec --model_filename new_inference.pdmodel --params_filename new_inference.pdiparams --save_file ./models/rec/rec.onnx --opset_version 16 --enable_onnx_checker True
输出如下:
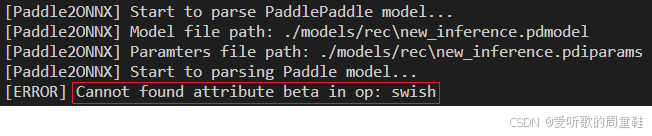
可以看到出现了错误,提示说 Cannot found attribute beta in op: swish 找不到 swish 算子的 beta 属性,在 issues/1167 有人遇到了同样的问题
官方的建议是从源码编译下 Paddle2ONNX,或者在 Linux 系统上尝试最新版本,博主这边也懒得去折腾了,直接拿 onnx_graphsurgeon 操作 ONNX 修改,开干👨🏭
首先我们来解决下动态宽高的问题,新建 static_height.py 脚本文件,其内容如下:(from ChatGPT)
import onnx
import numpy as np
import onnx_graphsurgeon as gs
def static_height():
# 加载 ONNX 模型
input_model_path = 'models/rec/rec.onnx'
output_model_path = 'models/rec/rec.static.onnx'
model = onnx.load(input_model_path)
# 使用 onnx_graphsurgeon 转换模型
graph = gs.import_onnx(model)
# 假设你的输入节点名为 'input',请根据你的模型实际情况调整
for tensor in graph.inputs:
if tensor.name == 'x':
# 将 height 设置为静态的 640,保持 batch size 为动态
print(f"begin modify")
tensor.shape = [gs.Tensor.DYNAMIC, 3, 48, 640]
# 重新构建并导出修改后的模型
graph.cleanup().toposort()
model = gs.export_onnx(graph)
onnx.save(model, output_model_path)
print("Model has been modified and saved.")
if __name__ == "__main__":
static_height()
执行下该脚本文件,执行成功后在 models/rec 文件夹下会生成 rec.static.onnx 模型文件,这是固定宽高后的 ONNX 模型,如下图所示:
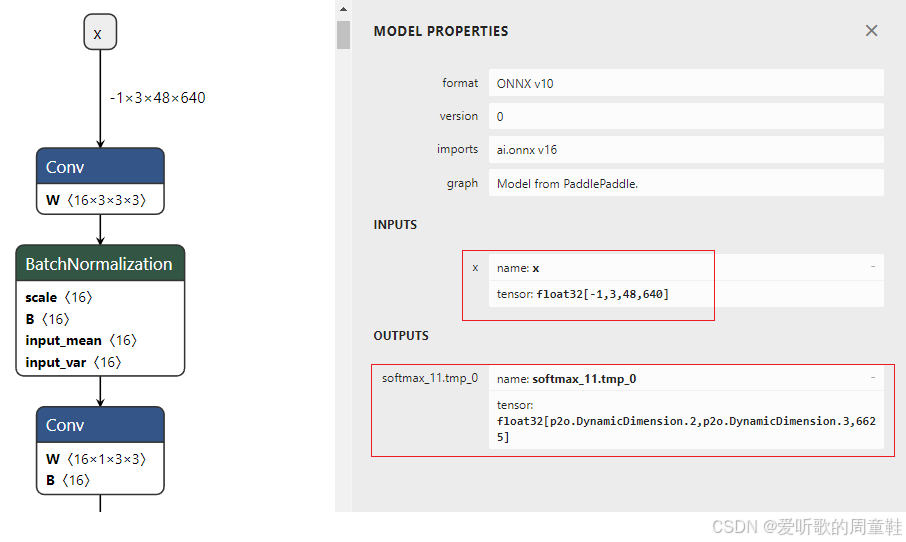
可以看到输入输出都只让 batch 维度动态,宽高固定,符合我们的预期
接着利用前面的 onnx_optimizer.py 脚本文件来优化 ONNX,代码简单修改下:
if __name__ == "__main__":
model_onnx = rename_io_names("./models/rec/rec.static.onnx", "images", "output")
# 检查导入的onnx model
onnx.checker.check_model(model_onnx)
print(f"Simplifying with onnx-simplifier {onnxsim.__version__}...")
model_onnx, check = onnxsim.simplify(model_onnx)
assert check, "assert check failed"
onnx.save(model_onnx, "./models/rec/rec.sim.onnx")
执行如下指令优化:
python onnx_optimizer.py
执行成功后在 models/rec 文件夹下会多出 rec.sim.onnx 模型文件,这是优化后的 ONNX 模型,如下图所示:
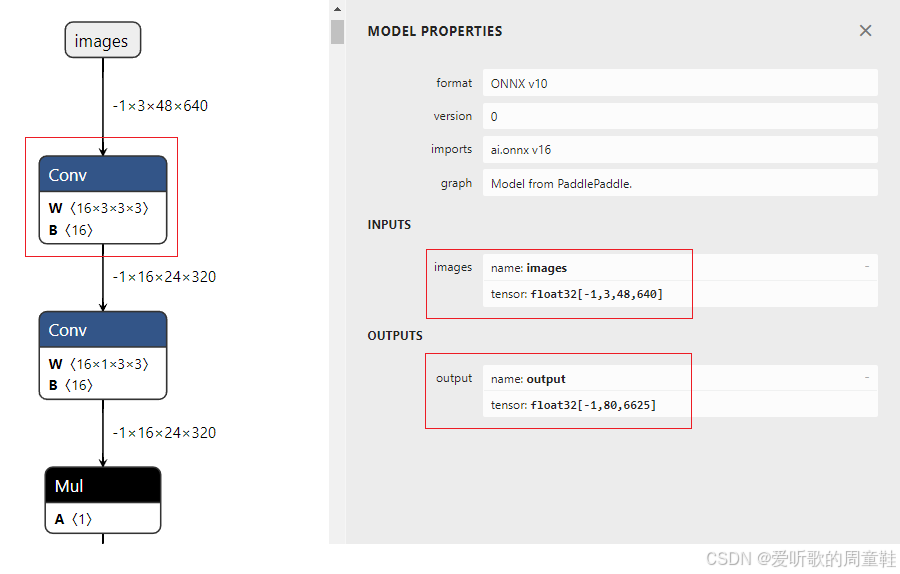
可以看到优化后的 ONNX 模型输入输出节点名完成了修改,Conv+BN 进行了融合,符合我们的预期
这里提前剧透下,之后我们拿这个 ONNX 模型推理时会出现如下的问题:

错误信息为 Node (p2o.Reshape.64) Op (Reshape) [ShapeInferenceError] Target shape may not have multiple -1 dimensions.
这表明在 rec.sim.onnx 模型的 Reshape 操作中,目标形状包含了多个 -1 维度,而 ONNX 规范不允许 Reshape 操作的目标形状中有有个 -1 维度,因为这样会导致 Shape 推断的不确定性
具体我们来看看 rec.sim.onnx 中的 p2o.Reshape.64 节点是不是像上面说的一样:
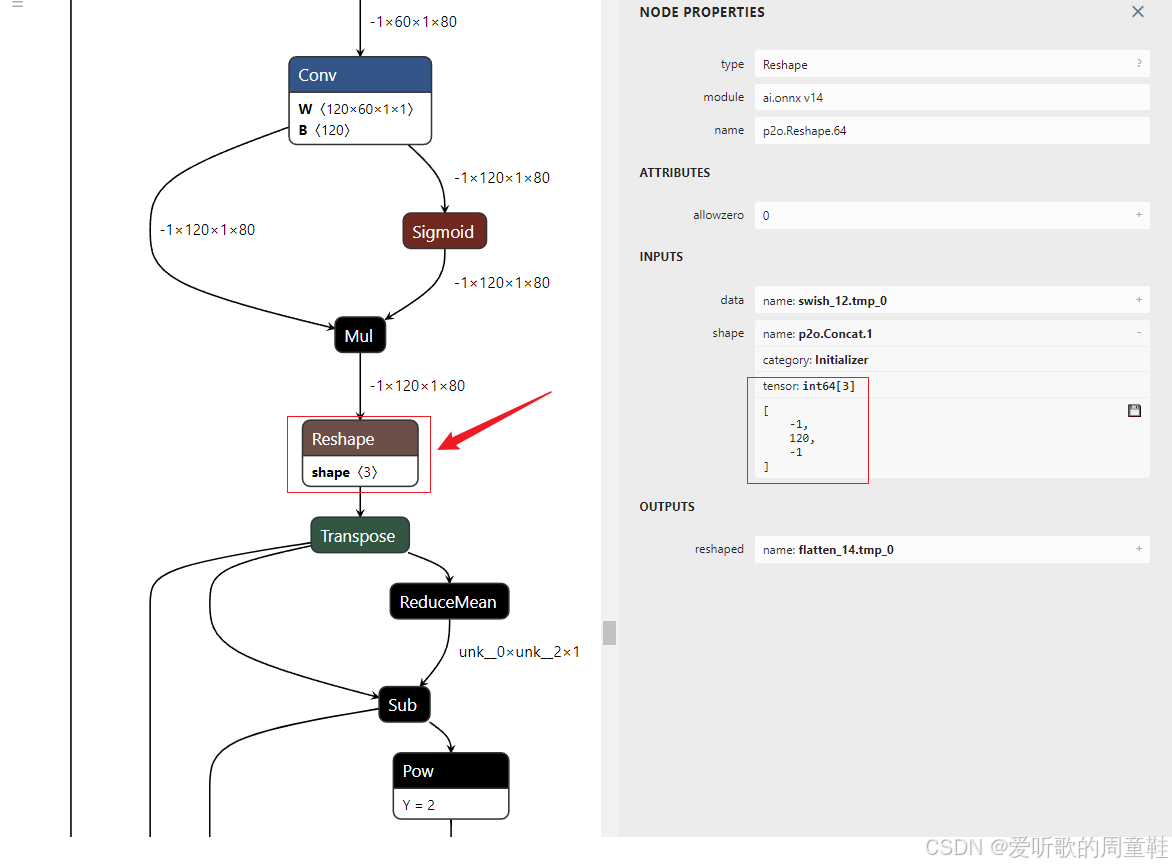
我们可以看到这个 Reshape 节点 shape 的维度是 -1x120x-1,确实是多个 -1 维度,因此我们可以利用 onnx_graphsurgeon 来手动修改,将其修改为只有一个 -1 维度,那另外一个 -1 维度确切的维度是多少呢?🤔
可以猜嘛,从 ONNX 中我们可以看到 Reshape 前的维度是 -1x120x1x80,那后面肯定是 Reshpae 到 -1x120x80 咯,那另一个 -1 维度固定下来就是 80
我们新建一个 shape_static.py 脚本文件来修改这个 onnx,内容如下:(from ChatGPT)
import onnx
import numpy as np
import onnx_graphsurgeon as gs
def shape_static():
# 加载 ONNX 模型
input_model_path = 'models/rec/rec.sim.onnx'
output_model_path = 'models/rec/rec.sim.onnx'
model = onnx.load(input_model_path)
# 使用 onnx_graphsurgeon 转换模型
graph = gs.import_onnx(model)
# 查找并修改指定的 Reshape 节点
for node in graph.nodes:
if node.name == 'p2o.Reshape.64':
# 假设 shape 输入是这个节点的第二个输入
shape_input = node.inputs[1]
# 创建一个新的常量张量,包含新的 shape
new_shape = gs.Constant(name="new_shape_for_reshape", values=np.array([-1, 120, 80], dtype=np.int64))
# 替换旧的 shape 输入
node.inputs[1] = new_shape
# 重新构建并导出修改后的模型
graph.cleanup().toposort()
model = gs.export_onnx(graph)
onnx.save(model, output_model_path)
print("Model has been modified and saved.")
if __name__ == "__main__":
shape_static()
执行下该脚本文件,新的 rec.sim.onnx 模型的 Reshape 节点发生了改变,如下图所示:
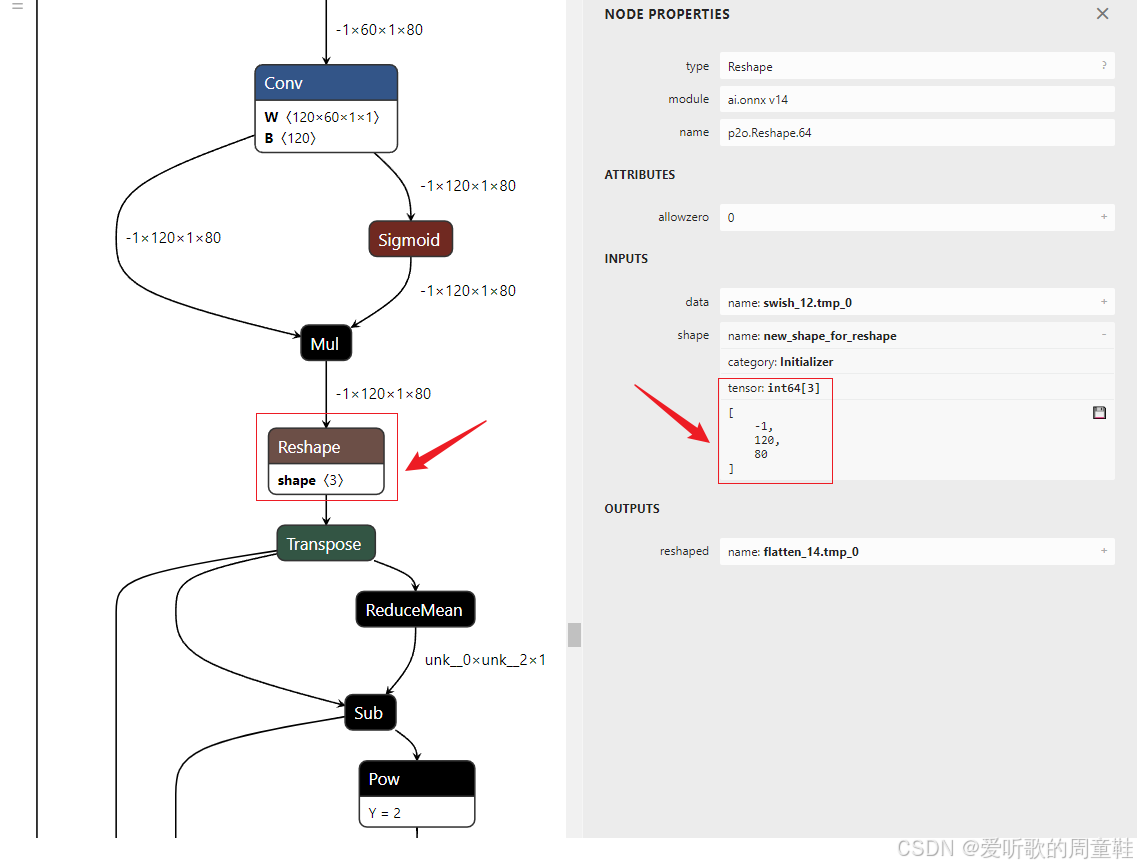
可以看到对应的 shape 被我们修改成了 -1x120x80,符合我们的预期
最后我们再来看下 rec 这个模型的结构,从中我们不难发现如下结构的存在:
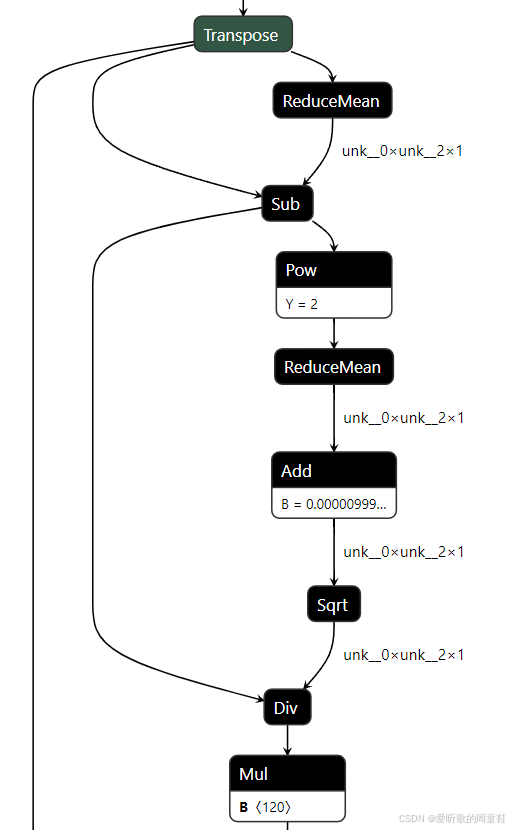
大家有没有很熟悉呢?我们在韩君老师的课程中有讲过这个就是一个典型的 LayerNormalization 算子,大家感兴趣的可以看下:三. TensorRT基础入门-快速分析开源代码并导出onnx
那既然如此为什么它没有作为一个完整的算子导出呢?是不是 Paddle2ONNX 官方不支持呢?我们可以看下官方文档:
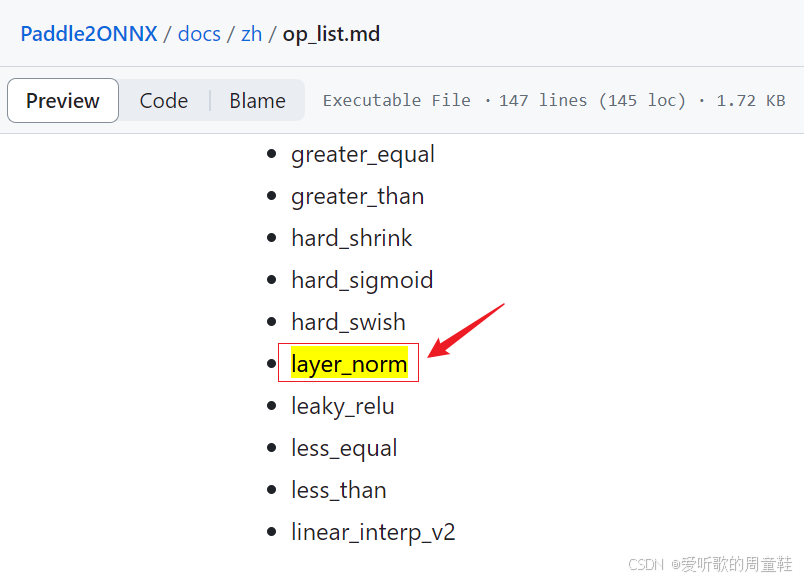
可以看到官方的 op_list 中有支持 layer_norm 节点,而且博主的 opset_version 也设置为了 16,不知道为什么没有导出来,不过也不影响我们后续部署
OK,至此 PP-OCRv4 中的三个模型我们已经全部导出,并修改成了我们期望的样子,下面我们来验证下利用这些 ONNX 模型看能不能正常推理
5. ONNX推理
开始之前大家需要按照上述方式将对应模型的 ONNX 导出,也可以点击 here 下载博主准备好的 ONNX 模型
终端执行如下指令即可:
python tools/infer/predict_system.py --use_gpu=False --use_onnx=True --det_model_dir=models/det/det.sim.onnx --rec_model_dir=models/rec/rec.sim.onnx --cls_model_dir=models/cls/cls.sim.onnx --image_dir=./deploy/lite/imgs/lite_demo.png
输出如下所示:
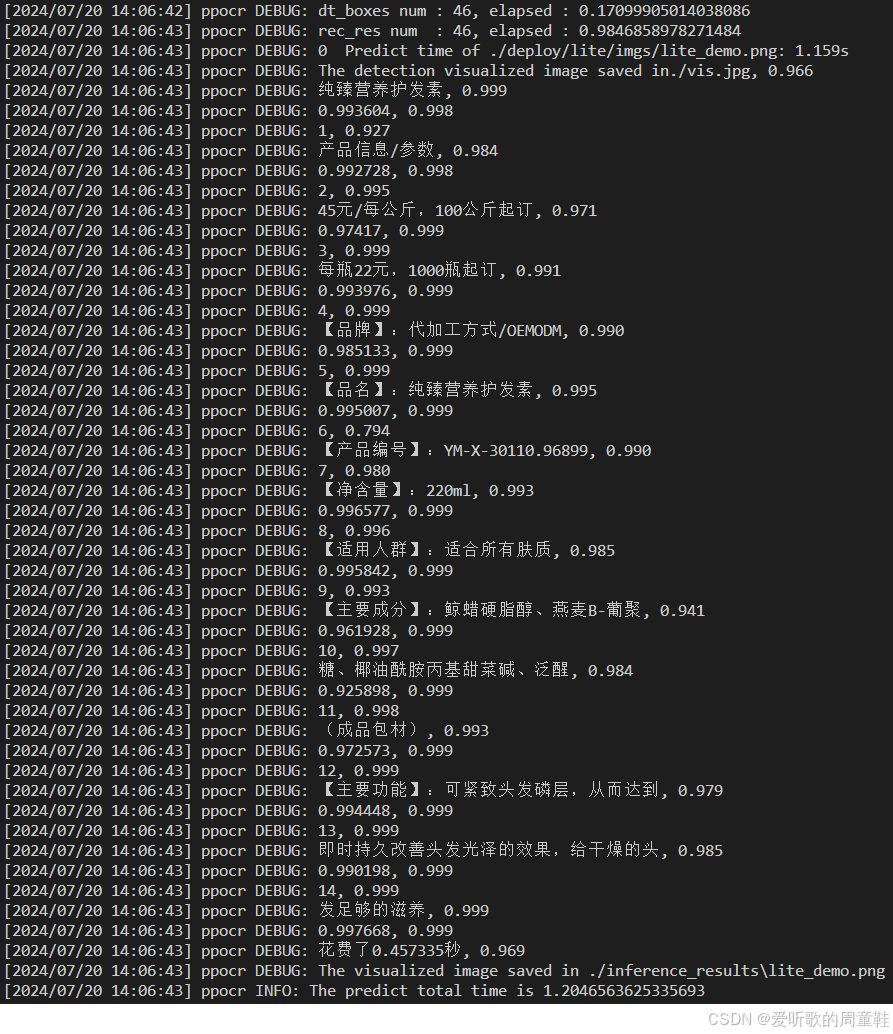
同时 inference_results 文件夹下保存着推理后的图片,如下图所示:

可以看到推理正常,说明我们导出的 ONNX 没有问题
结语
博主在这里针对 PaddleOCR 项目中的 PP-OCRv4 模型进行了 ONNX 导出,主要是利用 Paddle2ONNX 工具,虽然它导出的 ONNX 不是很符合我们的预期,但是使用诸如 onnx-simplifier、onnx_graphsurgeon 等工具总是可以解决我们的问题,不至于说束手无策
OK,以上就是 PP-OCRv4 的 ONNX 导出的全部内容了,下篇我们来梳理下 PP-OCRv4 中三个模型的前后处理,敬请期待😄