谈谈你对倒排索引的理解
在聊倒排索引之前,我们需要先了解一下‘索引’概念。
什么是索引呢?
索引是为了加速对表中数据行的检索而创建的一种分散的存储结构。
通俗的来讲索引好比就是新华字段中拼音的首字母还有偏旁,根据拼音的首字母和偏旁能很快的查找到你需要的内容。
索引的作用是什么呢?
保证数据的准确性
唯一的索引值对应着唯一的数据
加快检索速度
索引可以极大的加快检索速度
提高系统性能
索引可以有效提高系统的性能
倒排索引
elasticSearach 为啥要用倒排索引 而不是mysql 中 **B+**树呢?
先看看B+树的结构
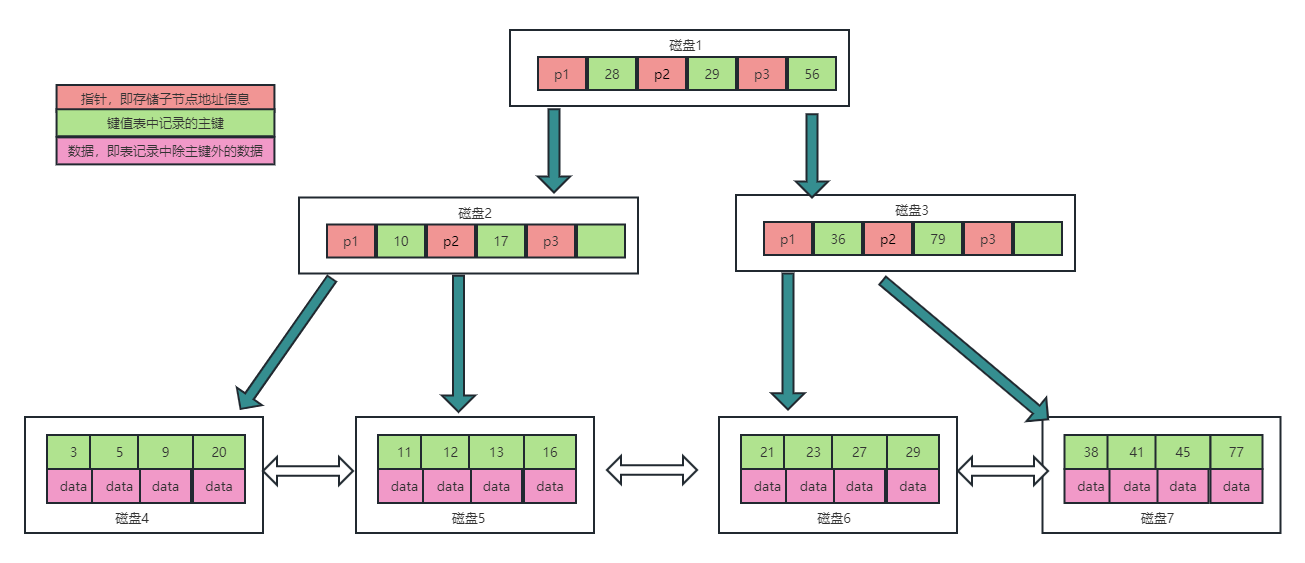
先简单讲一下 B+树
B+树的特征
- 每一个节点是一个dataPage,在mysql中每个dataPage的大小为16K
- 就假如ID为28这个节点来说,单个数据量越大,单个节点里面放的数据量就越少
- 一般都会使用ID作为索引存储,ID字段比较短适合存储。不适用字段多长的字段
- ID的数值越大,树越深。IO越大B+树默认支持千万级别的数据量。
综合上述特征b+树不适用做上亿级别的存储数据结构,就mysql而言左模糊查询会导致索引失效,而去全文去检索。IO压力增大,得不偿失。
下面聊一下倒排索引
倒排索引的组成:
- term index:词典索引
- term dictionary:词典词项
- posting list:倒排表(采用两种的压缩算法 1.FOR(稠密数组) 2.roaring bitmaps(稀疏数组))
举个简单的例子来讲吧
| id | title | desc |
|---|---|---|
| 1 | Welcome to Shanxi! | 欢迎来到陕西 |
| 2 | I like Xi 'an very much | 我很喜欢西安 |
| 3 | I like Xi 'an noodles very much | 我很喜欢吃西安的面 |
以title这一列来讲es根据默认的分词器(以及normzation)分为为以下的此项
Welcome to Shan xi an I like xi an very much noodles
| term index | term dictionary | Posting List |
|---|---|---|
| welcome | 1 | |
| to | 1 | |
| shan | 1 | |
| xi | 1,2,3 | |
| an | 2,3 | |
| i | 2,3 | |
| like | 2,3 | |
| noodles | 3 | |
| very | 2,3 | |
| much | 2,3 |
简单来说正排索引就是根据元素查找文档,倒排索引失根据元素查找文档。