使用外部数据库
strapi在默认下是安装了sqlite数据库,并且默认把数据放在.tmp/data.db中,并且被gitignore了
在团队开发中,这个二进制文件如果不被gitignore,即使覆盖或者保留双方都会崩掉,不得不重来。所以最后就变成了单独一个人管理数据库和后台了
配置
官方配置文档
目前本人用的mysql,数据库的配置在config/database.js中
module.exports = ({ env }) => ({
defaultConnection: 'default',
connections: {
default: {
connector: 'bookshelf',
settings: {
client: 'mysql',
host: '数据库ip地址',
port: 3306,
database: 'test',
username: '用户名',
password: '密码',
},
options: {
useNullAsDefault: true,
},
},
},
});
在web管理系统中随便添加一条数据,就可以看到远程的数据库添加了新的表
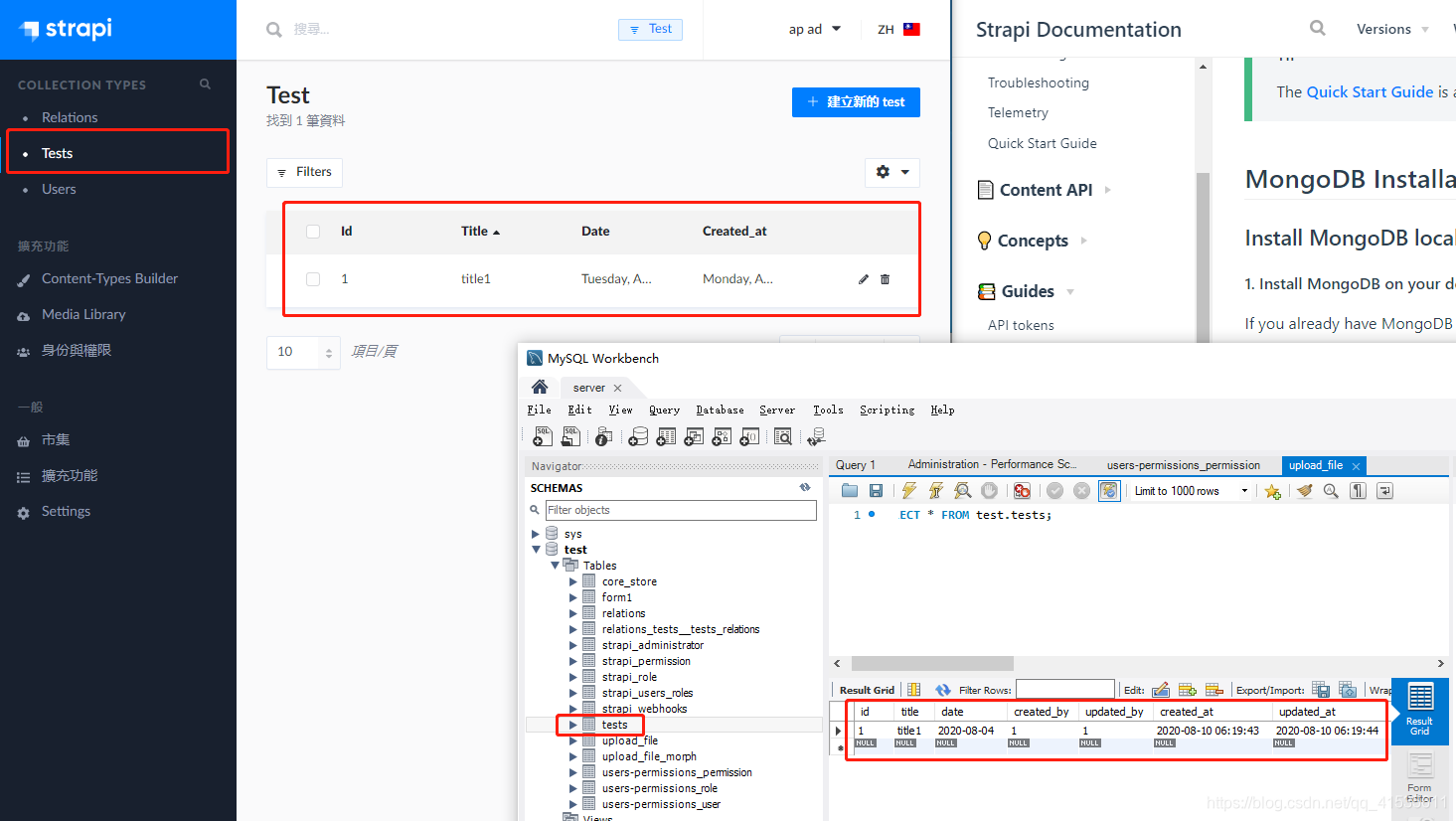
strapi表默认的api
这里官方文档算是写的挺详细的
| Method | 路径 | 说明 |
|---|---|---|
| GET | /{表名} | 获取该表的所有数据 |
| GET | /{表名}/:id | 获取该表对应id的单个数据 |
| GET | /{表名}/count | 获取该表的所有数据总数 |
| POST | /{表名} | 创建该表中一条新数据 |
| DELETE | /{表名}/:id | 删除该表中对应id的单个数据 |
| PUT | /{表名}/:id | 更新该表中一条数据 |
关于通过ajax post/put relation数据的,根据设置一对多/一对一,字段的类型为number[]/number,填入对应数据的id即可
api实体文件
在api文件中,能发现我在第一篇中创建的两张表test和relation同名文件夹,并且2个的文件结构都一样
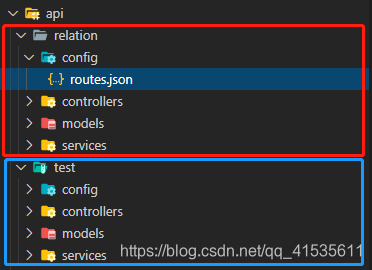
官方文档整理
路由配置 config/routes.json
控制器 controllers/relation.js
数据生命钩子 models/{表名}.js
数据结构 models/relation.settings.json
共享函数文件 services/{表名}.js
实际使用
路由配置
打开json文件能看到以下类似的数据结构:
{
"routes": [
{
"method": "GET",
"path": "/relations",
"handler": "relation.find",
"config": {
"policies": []
}
},
// .....
]
}
里面的routes的个数刚好对应默认api的6个,其中
method就是请求的方法path请求的路径handler请求用到的方法,在这里为relation.find,表示会用到在relation文件夹下的controllers/{表名}.js中的find函数。但默认下find函数已经在系统中存在了,所以controllers/{表名}.js中没有find函数config.policies并没有用过,可以自己看文档
一些小技巧
handler中也可以设置test.findFn,由此特性可以创建一个新的空表在里面单独设置path和handler- 欢迎讨论
控制器
路由配置文件的handler就是指向这里module.exports中的函数。
在这里我写个例子:
relation数据
r1和r2aaaa分别关联test表的title1和title2
routes.json

{
"routes": [
{
"method": "GET",
"path": "/relations/testFn",
"handler": "relation.testFn",
"config": {
"policies": []
}
},
// .....
]
}
controllers/relation.js
module.exports = {
async testFn(){
let dataList = await strapi.query('relation').find({retitle:'r2aaaa'})
return dataList
}
};
查询结果
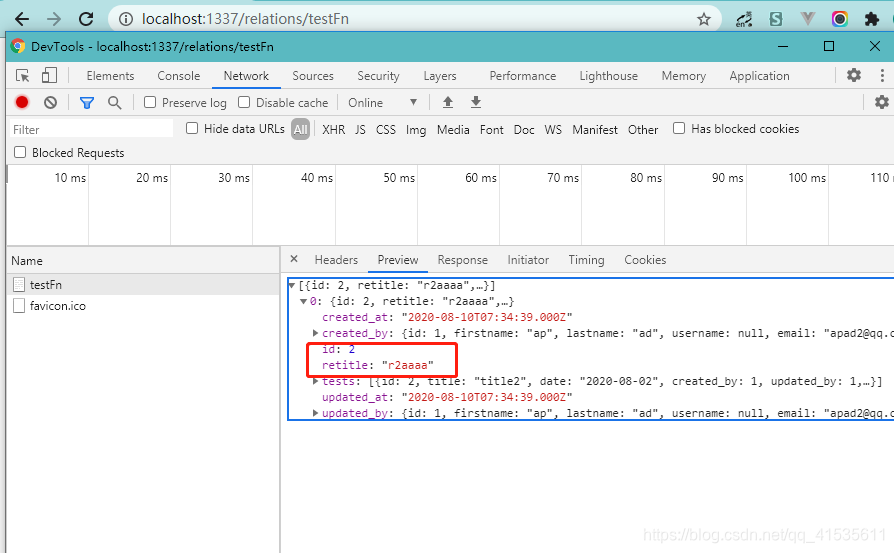
记得去public开放该接口
其中的坑或注意项
relation.js文件中的strapi变量是strapi给每个js文件中混入的全局变量strapi.query('表名')中的表名并不局限本文件夹中,relation中可以查找test表services/{表名}.js就是个可以存我上面relation.js写的方法,该文件用或不用都是可以的
剩下的三个文件
并没有怎么用不清楚哦
query方法
query方法官方文档
简单来说就是过滤排序,如果只是比较简单的过滤用这个比上面写方法要快得多
例子:/relations?id=1,过滤出id === 1的数据
query附带条件
属性后面带_${方法},例子/relations?id_ne=1
| 方法 | 说明 | 说明 |
|---|---|---|
| ne | 不等于 | |
| lt | 小于 | 对比数字/日期类型 |
| gt | 大于 | 对比数字/日期类型 |
| lte | 小于等于 | |
| gte | 大于等于 | |
| in | Included in an array | 包含多个同属性等值过滤,如/relations?id_in=3&id_in=6&id_in=8 |
| nin | Not included in an array | 没用过 |
| contains | 包括 | 一般用于搜索功能 |
| ncontains | 不包括 | |
| containss | 包括,大小写敏感 | |
| ncontainss | 不包括,大小写敏感 | |
| null | Is null or not null | 没用过 |
排序
目前就两种,用法为_sort=${属性}:${排序方式},例子:/relations?_sort=id:ASC;看官网还能多排,但没这个条件用过/users?_sort=email:DESC,username:ASC
- ASC 正排序
- DESC 逆排序
数量限制
大部分用来弄翻页功能的,很简单就全列出来了
例子:/relations?_start=10&_limit=30,这里要说明的是limit这个不设置默认好像是返回列表最大20个,只有设置了-1才返回所有
为api接口上缓存
strapi的后端框架koa并没怎么用,之前都是用的express的apicache,但可以使用转化包把express的中间件使用在koa中
需要的两个库:koa-connect、apicache
配置位置:/config/functions/bootstrap.js
var e2k = require('koa-connect'),
cache = require('apicache').middleware
var midd = e2k(cache('1 minutes'))
module.exports = () => {
strapi.app.use(midd)
};