在2014年ImageNet大规模视觉识别挑战(ILSVRC14)中,GoogLeNet获得了第一名。作者提出了一个代号为Inception的深度卷积神经网络架构,负责设定分类和检测的新技术状态。GoogLeNet的命名也是为了向早期的LeNet致敬。
在学习了VGG和Alexnet之后接触GoogLeNet之后,很自然的会从网络结构方面先入手,对他们进行比较(毕竟VGG和GoogLeNet是当年ImageNet挑战赛(ILSVRC14)的两大热门,GoogLeNet第一、VGG第二)
还是一样先看看网络构架图吧
这张图是不是还可以,再来看看这张“稍微”长一点的吧!
刚刚看到这张常常的构架图我有点被吓到(没见过世面),但是慢慢去理解会发现还是很清晰明了的。
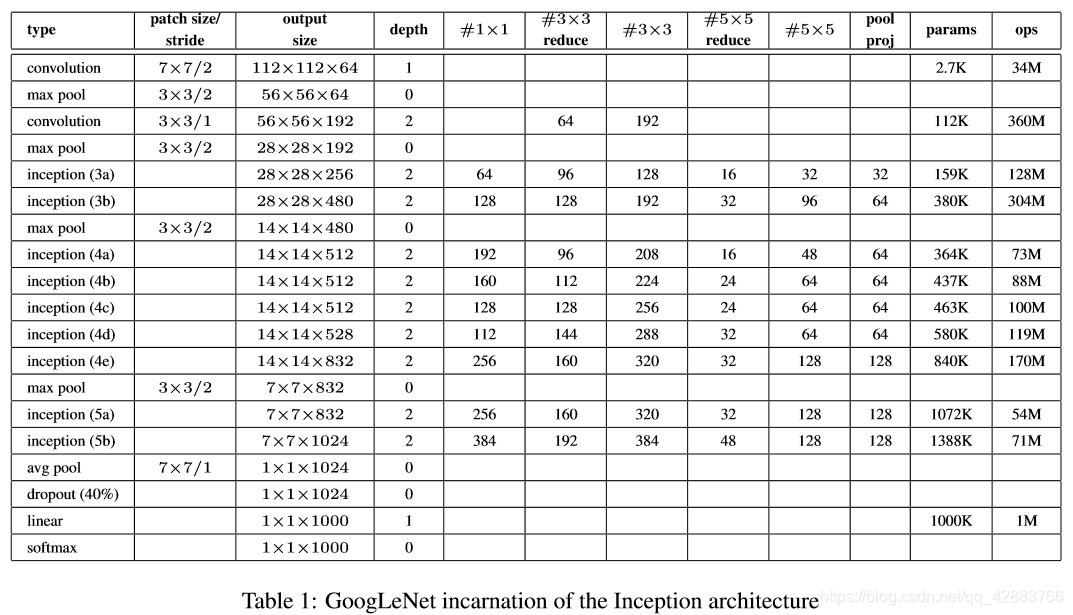
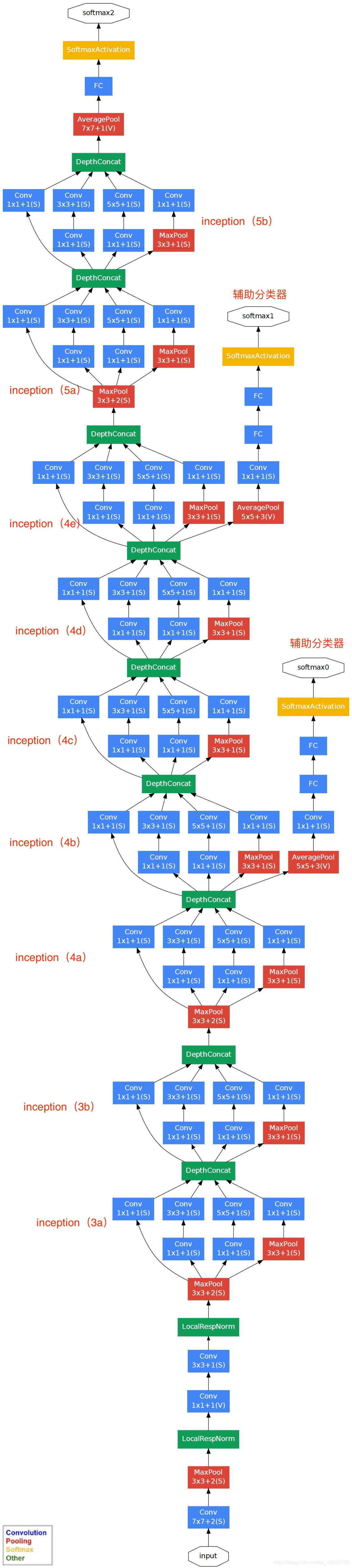
网络的参数和细节在第一张图表中已经很详细了,主要还是看看这个网络有哪些独到的地方吧。
模型性能优越:
首先先回顾一下之前我在学习VGG和Alexnet的过程学习到的一下内容,从Alexnet到VGG,我们明显的感觉到了网络的深度对学习带来的帮助,同时网络参数的减少能给有效的减少计算量提高计算效率,并防止数据过拟合。在我学习GoogLeNet时,先不说他其他方面的大胆尝试和创新,单从结构的深度和参数量相比,就做得非常好了。
做一个直观的对比:
GoogLeNet:参数量500万 网络深度22层
Alexnet:参数量6000万 网络深度8层
VGG:参数量18000万 网络深度最大19层
显而易见GoogLeNet的性能更加优越,在内存和资源有限的情况,GoogLeNet更值得一试。
下面让我看看GoogLeNet实现这些性能优越都做了什么吧~
GoogLeNet的作者提到:
对于像Imagenet这样较大的数据集,最近的趋势是增加层数和层大小同时使用drop解决过拟合问题。
当然众所周知, 提高深度神经网络性能最直接的方法是增加其规模。 这包括增加网络的深度(网络层数)和宽度(每个层的单元数,即神经元数量)。 这是一种简单而安全的训练高质量模型的方法,特别是在提供大量标记训练数据的情况下。 然而,这个简单的解决方案有两个主要缺点。
1.更大的尺寸通常意味着更多的参数,这使得扩大的网络更容易过度拟合,特别是在训练集中标记的例子数量有限的情况下。
2.大大增加了计算资源的使用。深度视觉网络中,如果两个卷积层