提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
众所周知,Swin Transformer是计算机视觉的通用backbone,而论文的关键是作者提出了一种基于滑动窗口的自注意力机制(SW-MSA),窗口是如何划分的?为什么要这么去划分呢?划分之后的窗口比原来更多了,计算不会更麻烦吗?
一、窗口如何移动划分的?
将一张图用下图一样的窗口进行切分,就会切分成上图左边的形状;
将这个窗口向右下角移动,如下图所示,就会切分成上图右边的形状;
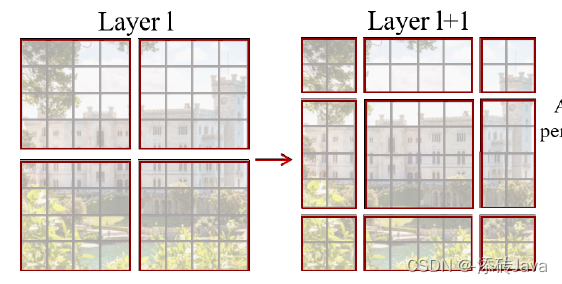
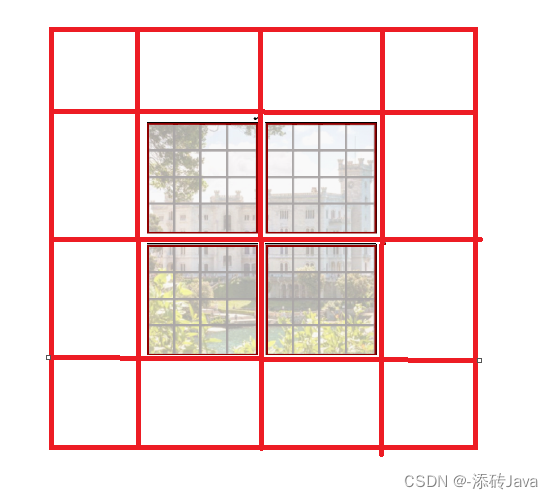
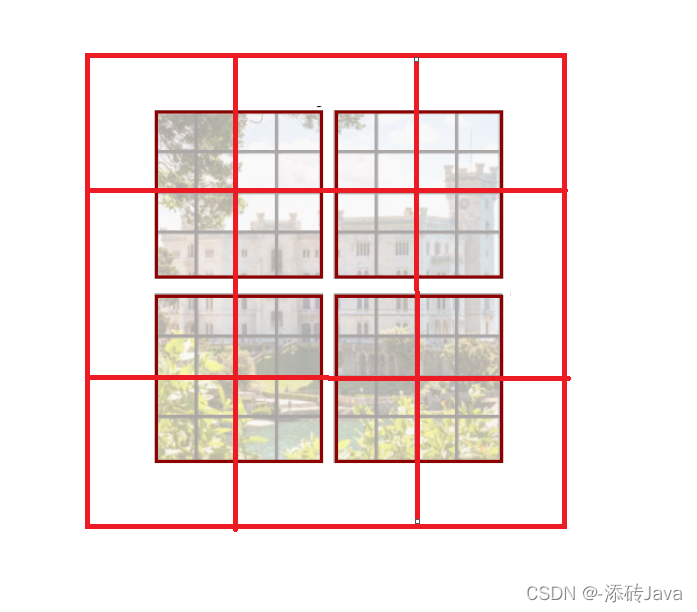
二、为什么要这么划分?
如果仅仅对于左图那样的划分去计算自注意力,那么块与块之间则毫无关联,仅仅会注意到自己的那一块,而和它相邻的块中信息则被忽略了,而再次对图进行右边一样的划分,好处是块与块之间有通信了,让原本被忽略的信息也计算进去了,正如swin transformer block中,对其进行W-MSA之后,再进行一次SW-MSA,这样就建立起了块与块之间的通信,效果也会更好。
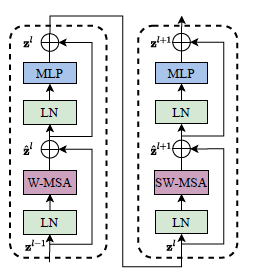
三、 划分之后的窗口比原来更多了,计算不会更麻烦吗?
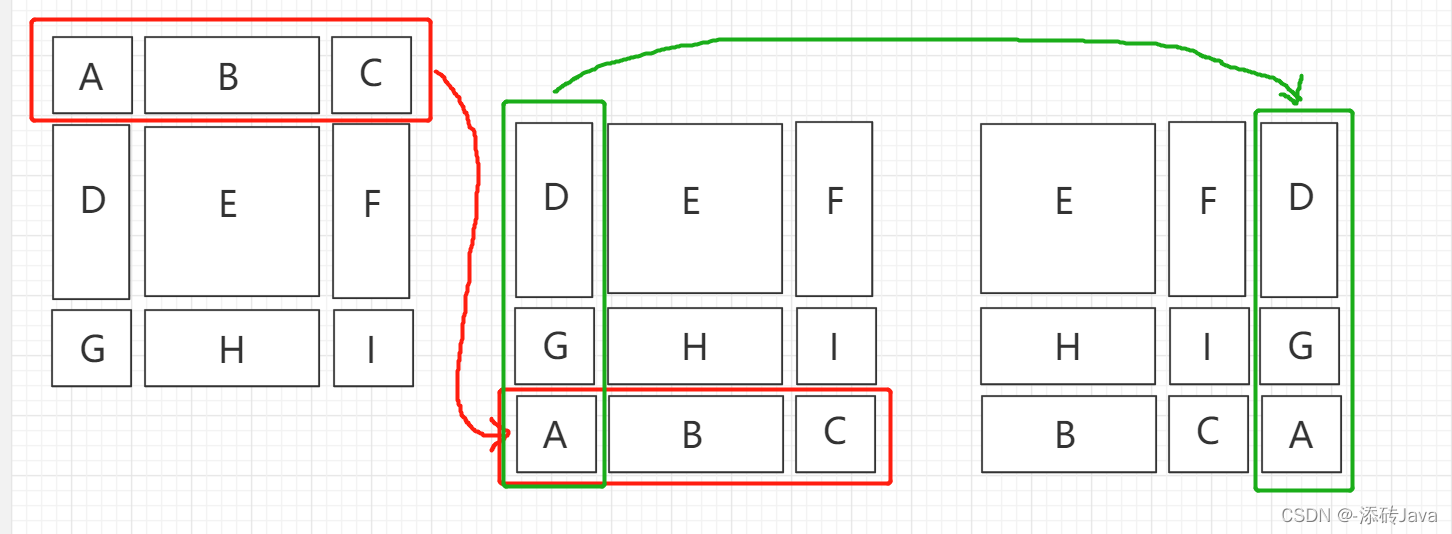
划分之后的问题就是,原来只需要计算四个块,而现在划分了九个块,而且麻烦的是块的大小还不一样,难道为每个块周围扩边,都扩成相同大小的再计算?那这样的话比原来计算量肯定会大一倍不止,此时,就想到了一个办法,对九个块进行循环位移,将上边的三个块移到下边,再将左边的三个块移到右边,这样的话就又成四个块了,如下图所示:
将左边红色的部分移动到中间红色部分的位置,再将中间绿色的部分移动到右边绿色部分的位置,即得到了四个块(画的有点扭曲,凑合看一下哈哈哈)
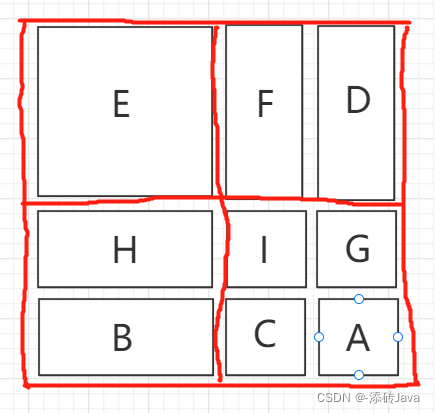
块是分好没问题了,但是又该怎么计算呢,直接去计算四个块吗?可是除了E这个块之外,其他的块都是来自不同的地方呀,F和D、H和B原来都不是相邻的块,更麻烦的是右下角的块,四块来自四个地方,此时就有了一种掩码的方式去计算它们的自注意力。
比如
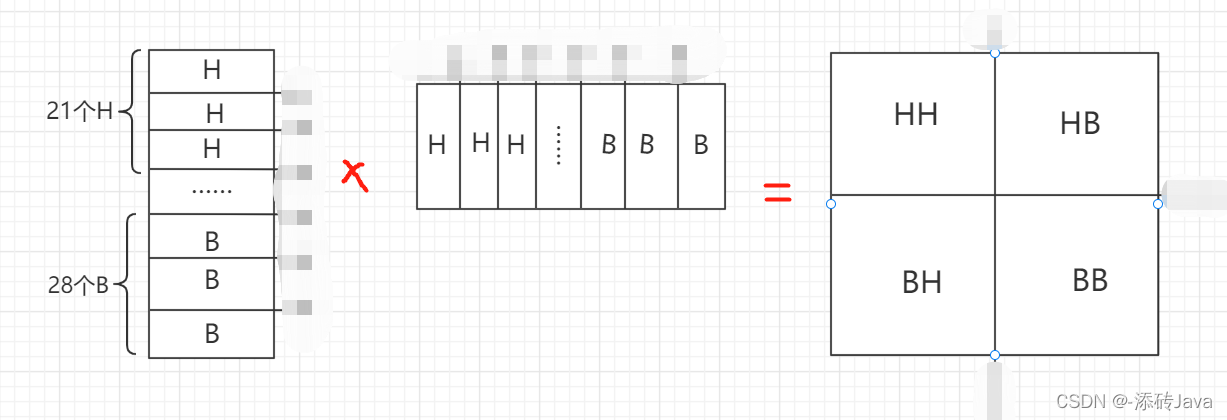
H和B这一块的计算,展平之后进行计算如下图:
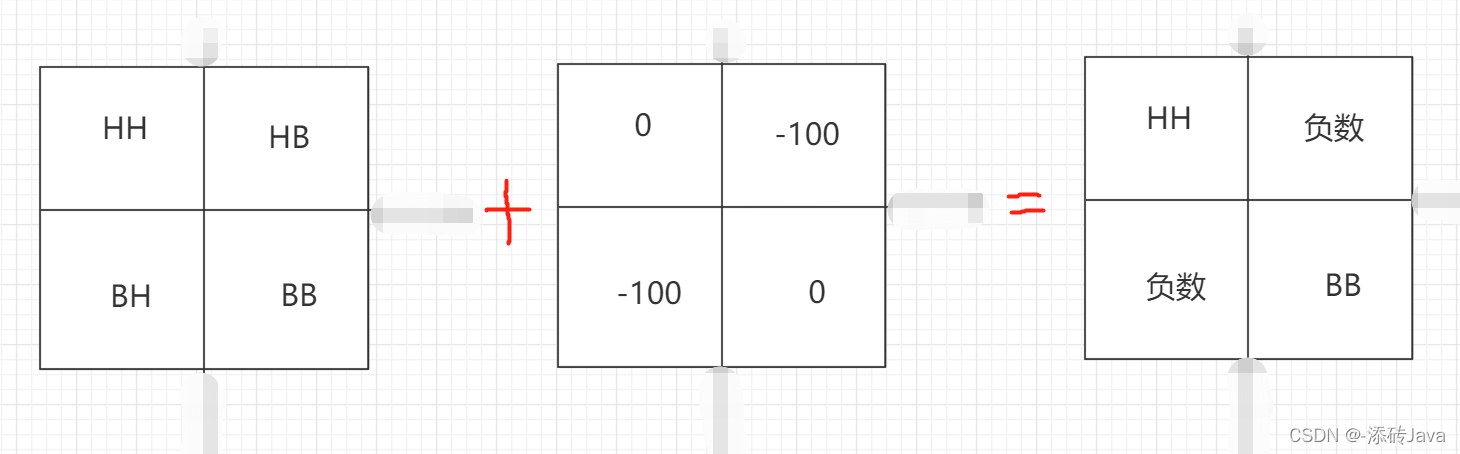
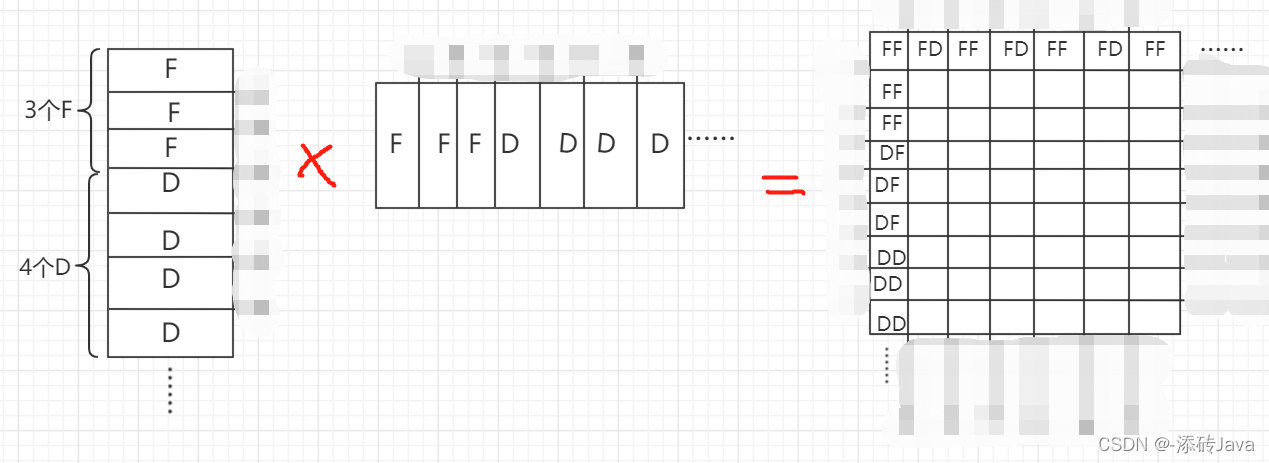
为什么是21个H,28个B呢?因为一个patch是77的大小,移动窗口的时候呢是移动patch/2的距离,也就是移动了3,所以H块的大小为73,B的大小为7*4,展平之后再乘以自身的转置,则得到了右边模板的结果,结果中HH和BB是我们想要的,但HB和BH是不想要的,因为B来自不同的地方并不是H的相邻块,此时就需要掩码来进行操作
对计算出的结果矩阵加上如图所示的模板,则会得到右边的结果,再对其进行sigmod激活函数之后,就得到我们想要的结果了。
而对于F和D块,方法类似,但展平的矩阵是条纹状的,得到的结果矩阵是网格式的,将其加上对应的模板即可,如下图:
总结
以上内容全是自己的理解所得,图也都是自己画的,画的不好请见谅,有不对的地方可以指出来互相学习