如果想了解kafka基础架构和生产者架构可以参考 kafka基础和 Kafka进阶_1.生产消息。
一、存储消息介绍
数据已经由生产者Producer发送给Kafka集群,当Kafka接收到数据后,会将数据写入本地文件中。
上图中的本地文件包含三种后缀不用的文件,分别是:

| 后缀 | 文件名 | 作用 |
|---|---|---|
| .log | 数据日志文件 | Kafka系统早期设计的目的就是日志数据的采集和传输,所以数据是使用log文件进行保存的 |
| .index | 数据索引文件 | Kafka的基础设置中,数据日志文件到达1G才会滚动生产新的文件。那么从1G文件中想要快速获取我们想要的数据,效率还是比较低的。数据索引文件就是用来快速获取数据的 |
| .timeindex | 数据时间索引文件 | 某些场景中,我们不想根据顺序(偏移量)获取Kafka的数据,而是想根据时间来获取的数据。kafka就提供了时间索引文件 |
本次主要学习kafka的生产和消费,所以在这里不对数据存储的校验、存储格式、查找方法等做详细记录。
二、副本同步
Kafka中,分区的某个副本会被指定为 Leader,负责响应客户端的读写请求。分区中的其他副本自动成为 Follower,主动拉取(同步)Leader 副本中的数据,写入自己本地日志,确保所有副本上的数据是一致的。
当Leader副本返回响应数据时,除了包含多个分区数据外,还包含了和偏移量相关的数据HW和LSO,副本需要根据场景对Leader返回的不同偏移量进行更新,因为kafka是分布式的,这里就存在数据一致性问题,在介绍数据一致性之前,需要掌握以下几个概念:

- Offset
Kafka的每个分区的数据都是有序的,所谓的数据偏移量,指的就是Kafka在保存数据时,用于快速定位数据的标识,类似于Java中数组的索引,从0开始。 - LSO
起始偏移量(Log Start Offset),每个分区副本都有起始偏移量,用于表示副本数据的起始偏移位置,初始值为0。LSO一般情况下是无需更新的,但是如果数据过期,或用户手动删除数据时,Leader的Log Start Offset可能发生变化,Follower副本的日志需要和Leader保持严格的一致,因此,如果Leader的该值发生变化,Follower自然也要发生变化保持一致。 - LEO
日志末端位移(Log End Offset),表示下一条待写入消息的offset,每个分区副本都会记录自己的LEO。对于Follower副本而言,它能读取到Leader副本 LEO 值以下的所有消息。 - HW
高水位值(High Watermark),定义了消息可见性,标识了一个特定的消息偏移量(offset),消费者只能拉取到这个水位offset之前的消息,同时这个偏移量还可以帮助Kafka完成副本数据同步操作。
2.1、数据一致性
Kafka的设计目标是:高吞吐、高并发、高性能。为了做到以上三点,它必须设计成分布式的,多台机器可以同时提供读写,并且需要为数据的存储做冗余备份。
上图中的主题有3个分区,每个分区有3个副本,这样数据可以冗余存储,提高了数据的可用性。并且3个副本有两种角色,Leader和Follower,Follower副本会同步Leader副本的数据。一旦Leader副本挂了,Follower副本可以选举成为新的Leader副本, 这样就提升了分区可用性,但是相对的,在提升了分区可用性的同时,也就牺牲了数据的一致性。

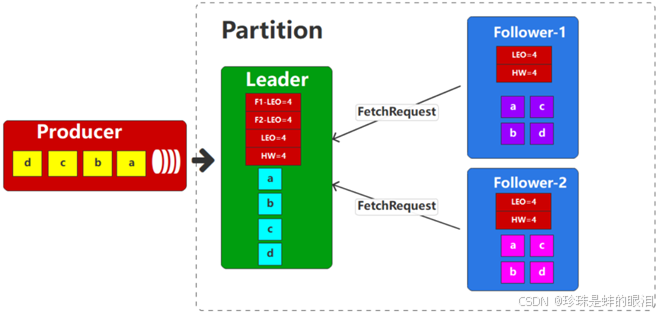
我们来看这样的一个场景:一个分区有3个副本,一个Leader和两个Follower。Leader副本作为数据的读写副本,所以生产者的数据都会发送给leader副本,而两个follower副本会周期性地同步leader副本的数据,但是因为网络,资源等因素的制约,同步数据的过程是有一定延迟的,所以3个副本之间的数据可能是不同的。具体如下图所示:
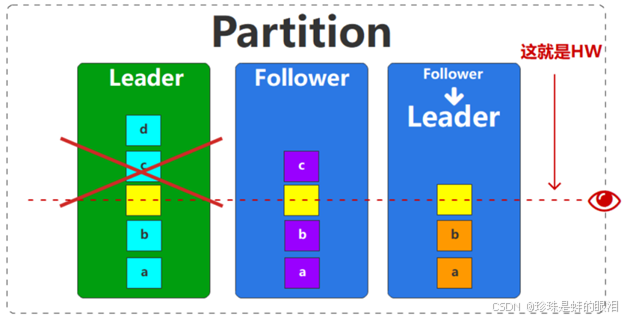
此时,假设leader副本因为意外原因宕掉了,那么Kafka为了提高分区可用性,此时会选择2个follower副本中的一个作为Leader对外提供数据服务(假如选择上面那个,实际是按照ISR中副本的次序选取的)。此时我们就会发现,对于消费者而言,之前leader副本能访问的数据是D,但是重新选择leader副本后,能访问的数据就变成了C,这样消费者就会认为数据丢失了,也就是所谓的数据不一致了。
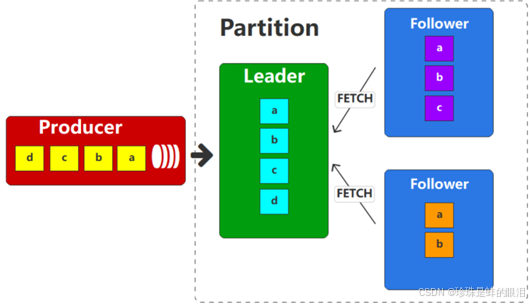
为了提升数据的一致性,Kafka引入了高水位(HW)机制,Kafka在不同的副本之间维护了一个水位线的机制(其实也是一个偏移量的概念),消费者只能读取到水位线以下的的数据。这就是所谓的木桶理论:木桶中容纳水的高度,只能是水桶中最短的那块木板的高度。这里将整个分区看成一个木桶,其中的数据看成水,而每一个副本就是木桶上的一块木板,那么这个分区(木桶)可以被消费者消费的数据(容纳的水)其实就是数据最少的那个副本的最后数据位置(木板高度)。也就是说,消费者一开始在消费Leader的时候,虽然Leader副本中已经有a、b、c、d 这4条数据,但是由于高水位线的限制,所以也只能消费到a、b这两条数据。
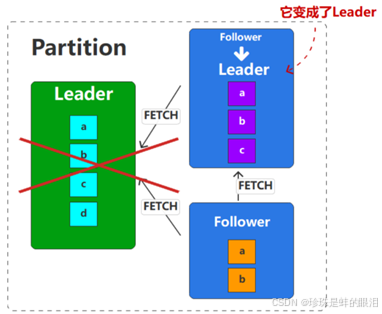
这样即使leader挂掉了,但是对于消费者来讲,消费到的数据其实还是一样的,因为它能看到的数据是一样的,也就是说,消费者不会认为数据不一致。
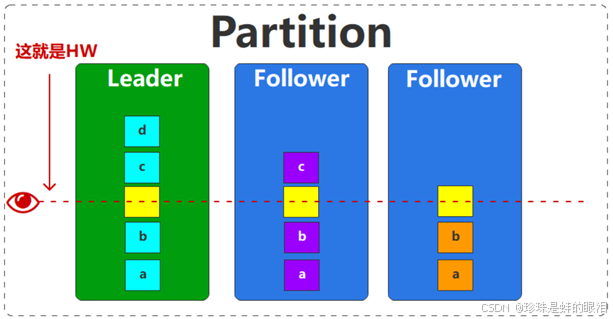
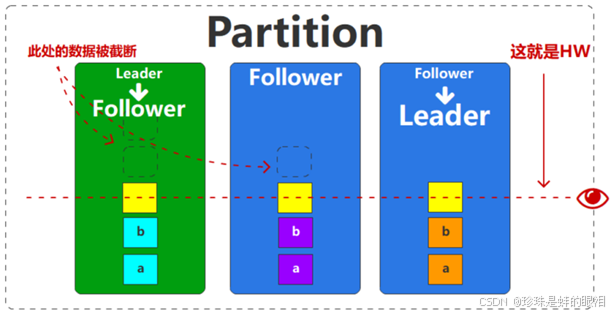
不过也要注意,因为follower要求和leader的日志数据严格保持一致,所以就需要根据现在Leader的数据偏移量值对其他的副本进行数据截断(truncate)操作。
2.2、HW在副本之间的传递
HW高水位线会随着follower的数据同步操作,而不断上涨,也就是说,follower同步的数据越多,那么水位线也就越高,那么消费者能访问的数据也就越多。接下来,我们就看一看,follower在同步数据时HW的变化。
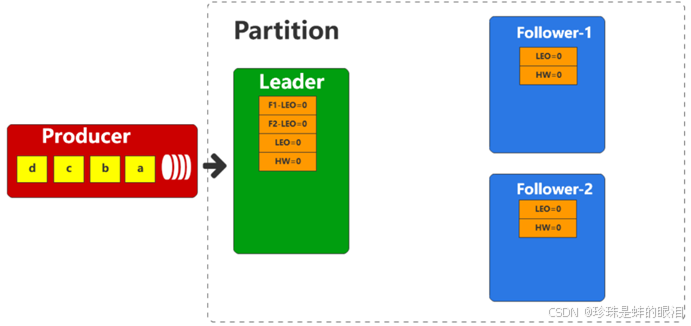
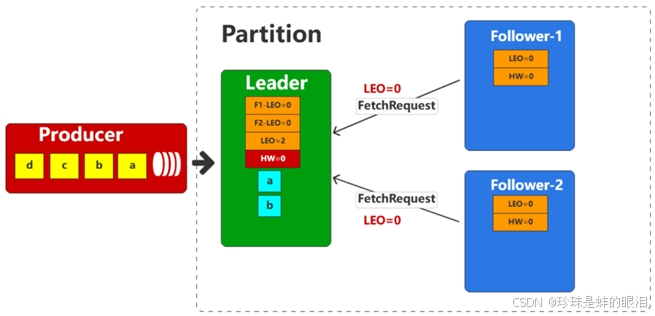
首先,初始状态下,Leader和Follower都没有数据,所以和偏移量相关的值都是初始值0,而由于Leader需要管理follower,所以也包含着follower的相关偏移量(LEO)数据。
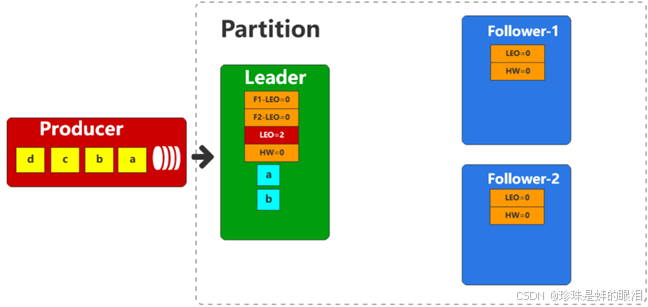
生产者向Leader发送两条数据,Leader收到数据后,会更新自身的偏移量信息。
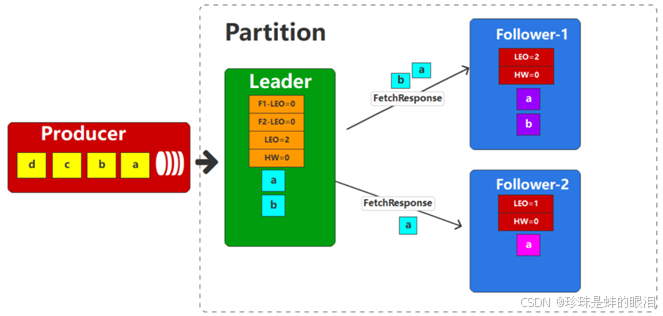
接下来,Follower开始同步Leader的数据,同步数据时,会将自身的LEO值作为参数传递给Leader。此时,Leader会将数据传递给Follower,且同时Leader会根据所有副本的LEO值更新HW。
由于两个Follower的数据拉取速率不一致,所以Follower-1抓取了2条数据,而Follower-2抓取了1条数据。Follower在收到数据后,会将数据写入文件,并更新自身的偏移量信息。
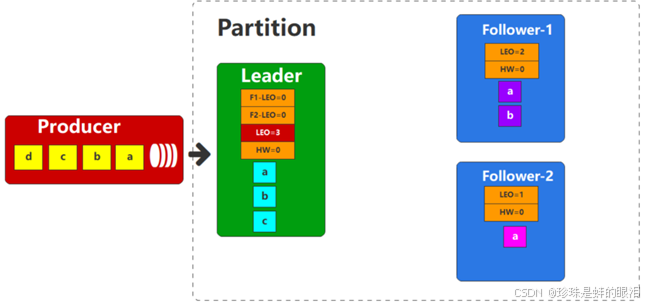
接下来Leader收到了生产者的数据C,那么此时会根据相同的方式更新自身的偏移量信息
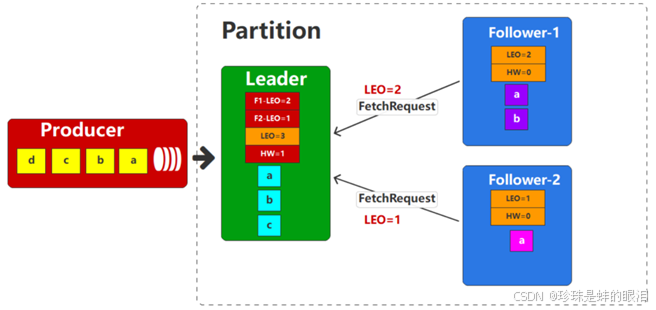
follower接着向Leader发送Fetch请求,同样会将最新的LEO作为参数传递给Leader。Leader收到请求后,会更新自身的偏移量信息。
此时,Leader会将数据发送给Follower,同时也会将HW一起发送。
Follower收到数据后,会将数据写入文件,并更新自身偏移量信息
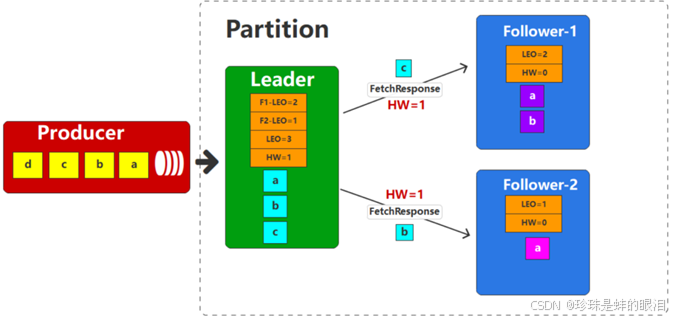
因为Follower会不断重复Fetch数据的过程,所以前面的操作会不断地重复。最终,follower副本和Leader副本的数据和偏移量是保持一致的。
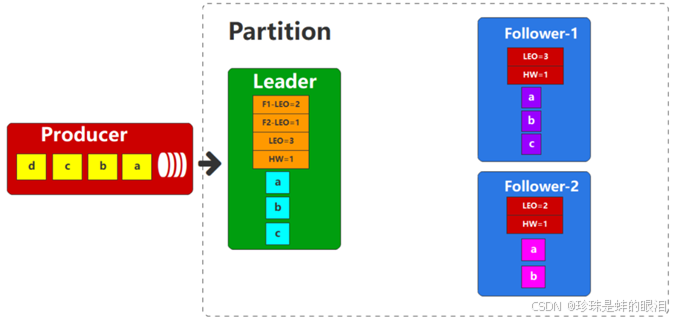
上面演示了副本列表ISR中Follower副本和Leader副本之间HW偏移量的变化过程,但特殊情况是例外的。比如当前副本列表ISR中,只剩下了Leader一个副本的场合下,是不需要等待其他副本的,直接推高HW即可。