CUDA线程模型
当核函数在主机端启动时,它的执行会移动到设备上,此时设备中会产生大量的线程
并且每个线程都执行由核函数指定的语句。了解如何组织线程是CUDA编程的一个关键部
分。CUDA明确了线程层次抽象的概念以便于你组织线程。这是一个两层的线程层次结
构,由线程块和线程块网格构成,如图2-5所示。
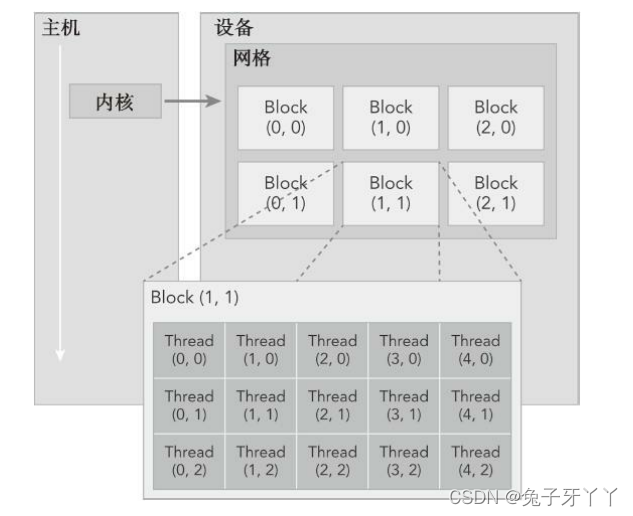
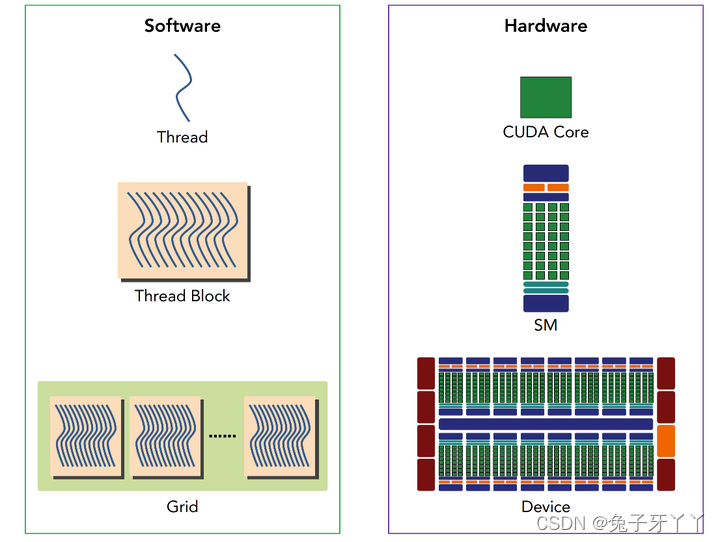
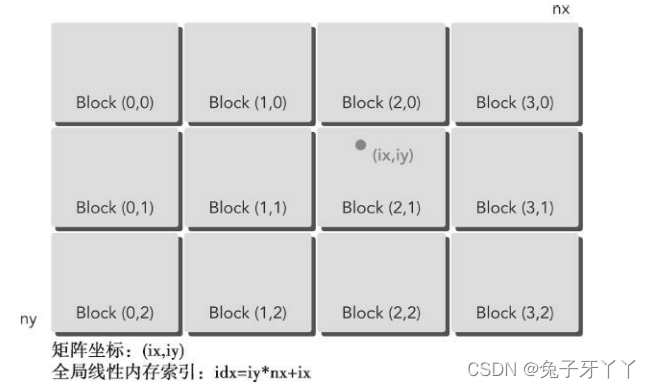
CUDA编程是一个多线程编程,数个线程(Thread)组成一个线程块(Block),所有线程块组成一个线程网格(Grid),如下图所示:
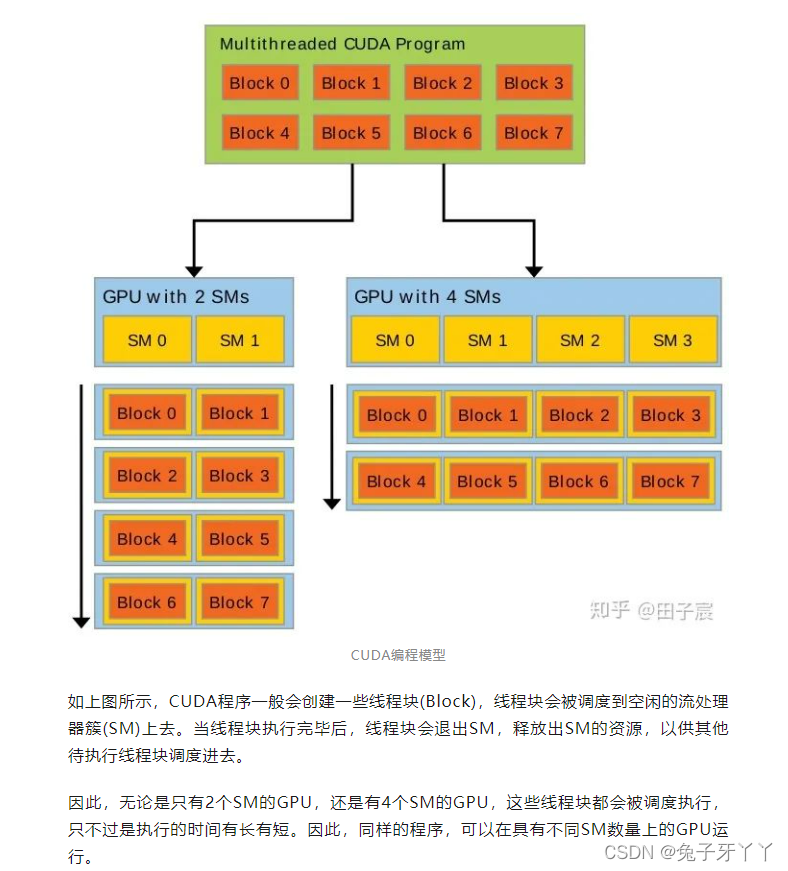
CUDA可以组织三维的网格和块。
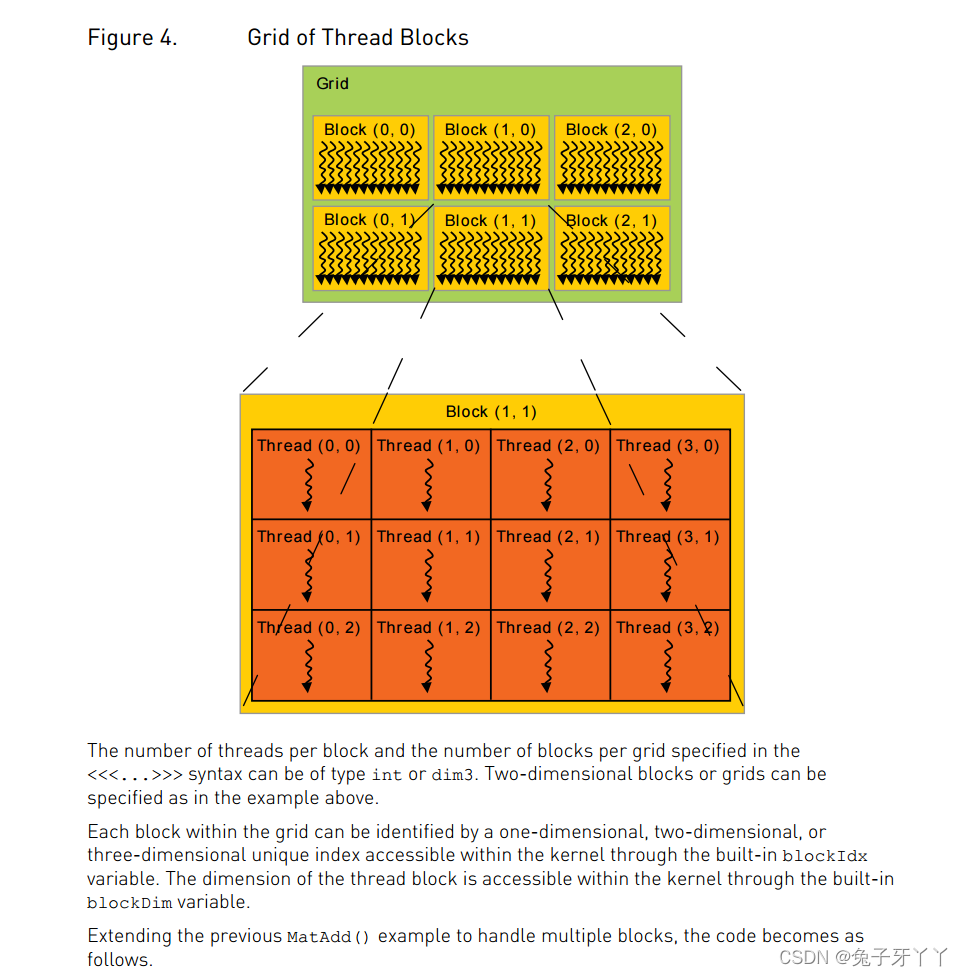
图2-5展示了一个线程层次结构的示例,其结构是
一个包含二维块的二维网格。网格和块的维度由下列两个内置变量指定。
·blockDim(线程块的维度,用每个线程块中的线程数来表示)
·gridDim(线程格的维度,用每个线程格中的线程数来表示)
它们是dim3类型的变量,是基于uint3定义的整数型向量,用来表示维度。当定义一个
dim3类型的变量时,所有未指定的元素都被初始化为1。dim3类型变量中的每个组件可以
通过它的x、y、z字段获得。如下所示。
维度
gridDim.x, gridDim.y, gridDim.z,
blockDim.x, blockDim.y, blockDim.z
索引
blockIdx.x, blockIdx.y, blockIdx.z
threadIdx.x, threadIdx.y, threadIdx.z
checkDimension.cu
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* Display the dimensionality of a thread block and grid from the host and
* device.
*/
__global__ void checkIndex()
{
printf( "gridDim:(%d, %d, %d) blockDim:(%d, %d, %d) threadIdx:(%d, %d, %d) blockIdx:(%d, %d, %d)\n", gridDim.x, gridDim.y, gridDim.z, blockDim.x, blockDim.y, blockDim.z, threadIdx.x, threadIdx.y, threadIdx.z, blockIdx.x, blockIdx.y, blockIdx.z);
// printf("threadIdx:(%d, %d, %d)\n", threadIdx.x, threadIdx.y, threadIdx.z);
// printf("blockIdx:(%d, %d, %d)\n", blockIdx.x, blockIdx.y, blockIdx.z);
// printf("blockDim:(%d, %d, %d)\n", blockDim.x, blockDim.y, blockDim.z);
// printf("gridDim:(%d, %d, %d)\n", gridDim.x, gridDim.y, gridDim.z);
}
int main(int argc, char **argv)
{
// define total data element
int nElem = 6;
// define grid and block structure
dim3 block(3);
dim3 grid((nElem + block.x - 1) / block.x);
// check grid and block dimension from host side
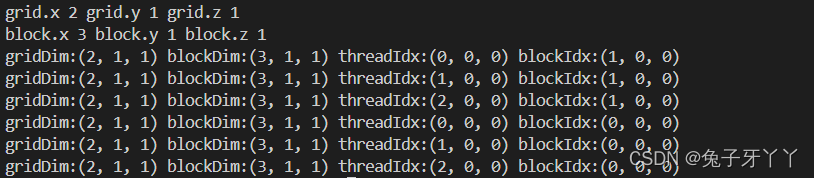
printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);
printf("block.x %d block.y %d block.z %d\n", block.x, block.y, block.z);
// check grid and block dimension from device side
checkIndex<<<grid, block>>>();
// reset device before you leave
CHECK(cudaDeviceReset());
return(0);
}
定义两个block,每个block3个线程
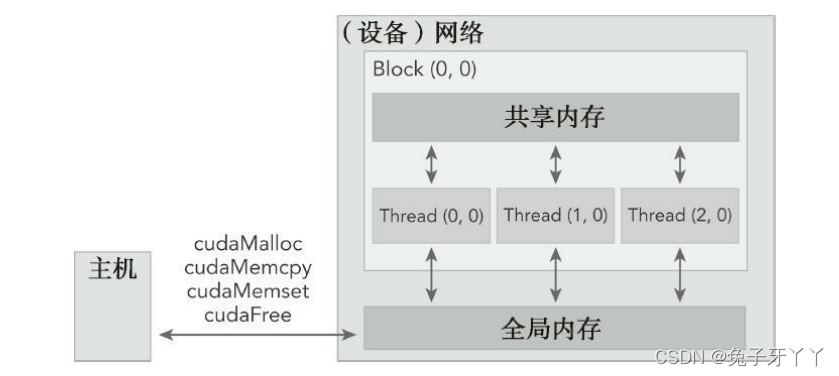
内存管理
由一个内核启动所产生的所有线程统称为一个网格。同一网格中的所有线程共享相同
的全局内存空间。一个网格由多个线程块构成,一个线程块包含一组线程,同一线程块内
的线程协作可以通过以下方式来实现。
sumArraysOnHost.c
#include <stdlib.h>
#include <time.h>
/*
* This example demonstrates a simple vector sum on the host. sumArraysOnHost
* sequentially iterates through vector elements on the host.
*/
void sumArraysOnHost(float *A, float *B, float *C, const int N)
{
for (int idx = 0; idx < N; idx++)
{
C[idx] = A[idx] + B[idx];
}
}
void initialData(float *ip, int size)
{
// generate different seed for random number
time_t t;
srand((unsigned) time(&t));
for (int i = 0; i < size; i++)
{
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
return;
}
int main(int argc, char **argv)
{
int nElem = 1024;
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *h_C;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
h_C = (float *)malloc(nBytes);
initialData(h_A, nElem);
initialData(h_B, nElem);
sumArraysOnHost(h_A, h_B, h_C, nElem);
free(h_A);
free(h_B);
free(h_C);
return(0);
}
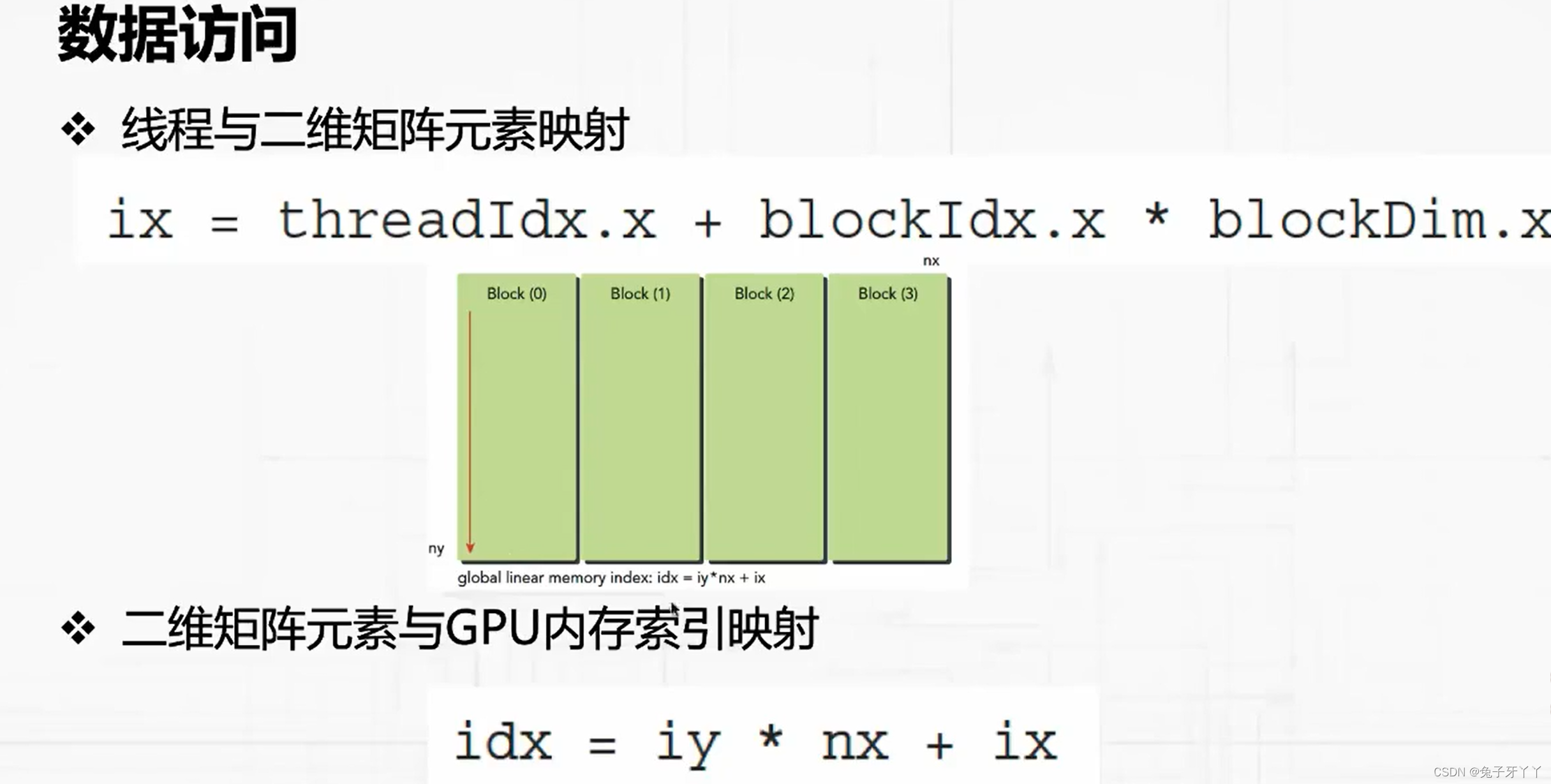
使用块和线程建立矩阵索引
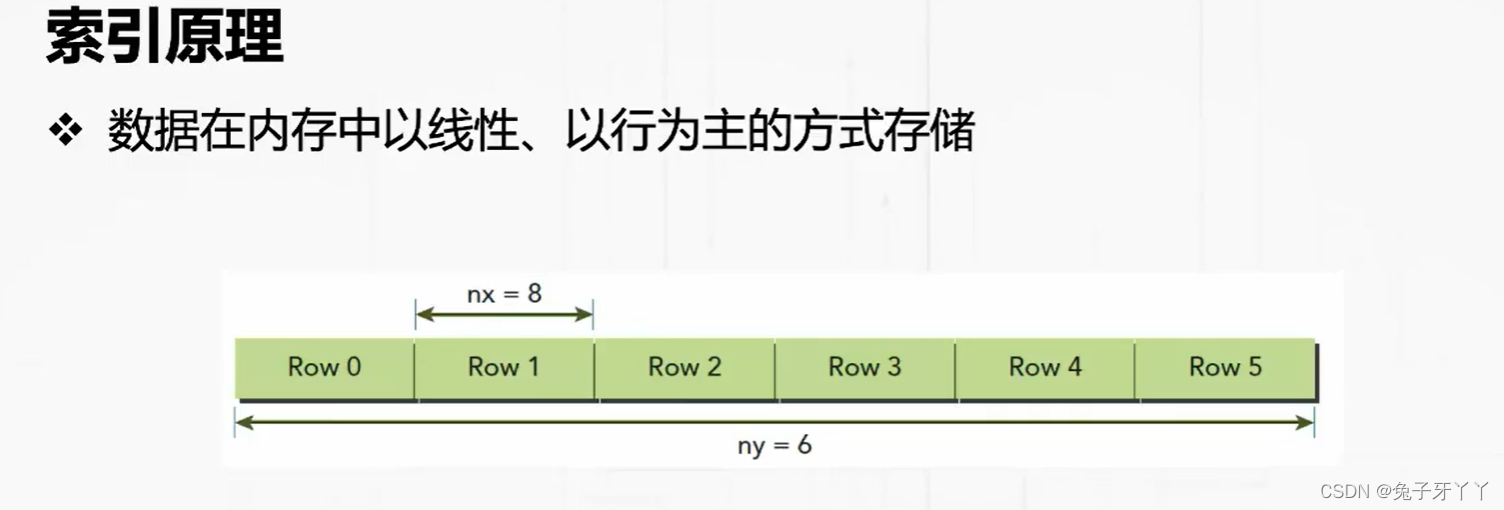
二维索引和映射

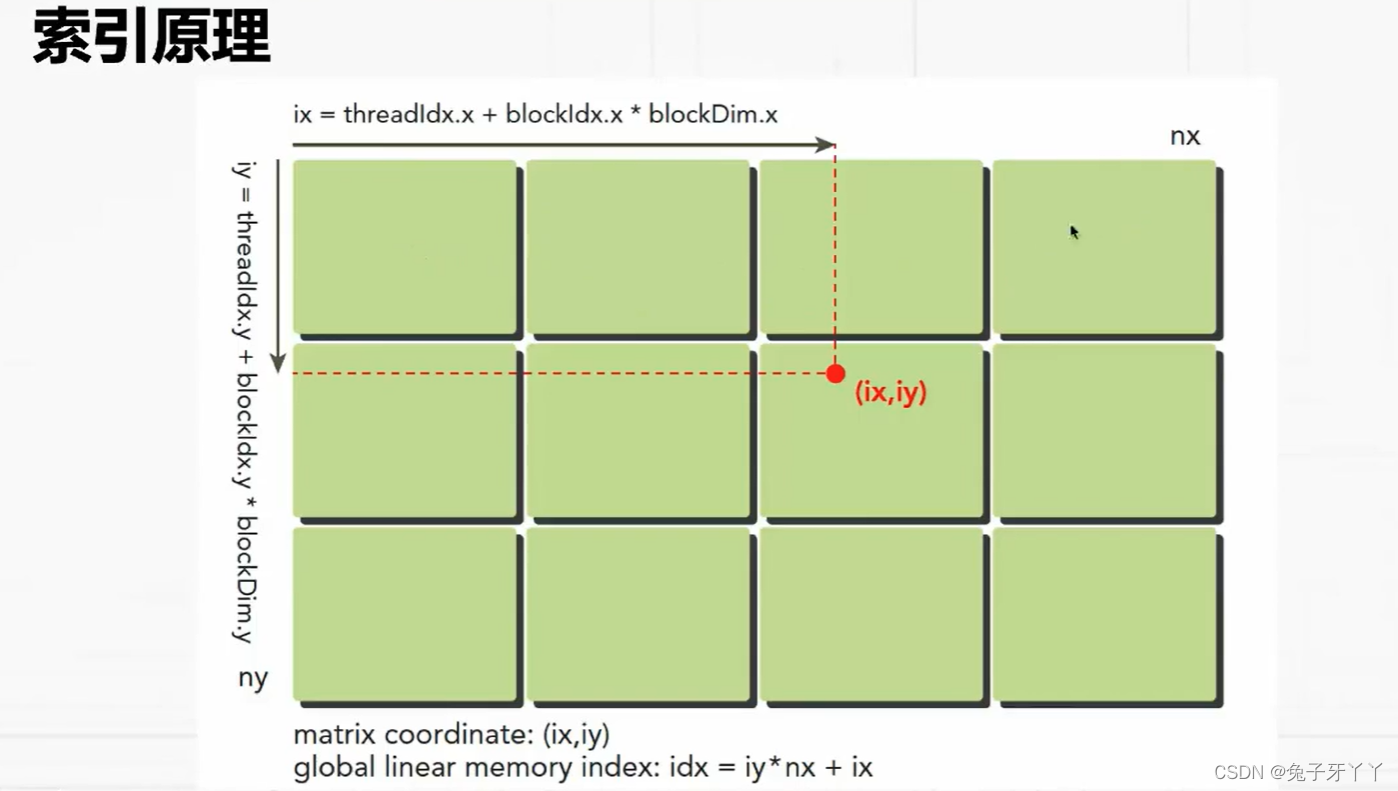
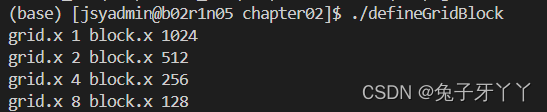
defineGridBlock.cu
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* Demonstrate defining the dimensions of a block of threads and a grid of
* blocks from the host.
*/
int main(int argc, char **argv)
{
// define total data element
int nElem = 1024;
// define grid and block structure
dim3 block (1024);
dim3 grid ((nElem + block.x - 1) / block.x);
printf("grid.x %d block.x %d \n", grid.x, block.x);
// reset block
block.x = 512;
grid.x = (nElem + block.x - 1) / block.x;
printf("grid.x %d block.x %d \n", grid.x, block.x);
// reset block
block.x = 256;
grid.x = (nElem + block.x - 1) / block.x;
printf("grid.x %d block.x %d \n", grid.x, block.x);
// reset block
block.x = 128;
grid.x = (nElem + block.x - 1) / block.x;
printf("grid.x %d block.x %d \n", grid.x, block.x);
// reset device before you leave
CHECK(cudaDeviceReset());
return(0);
}
sumArraysOnGPU-small-case.cu
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* This example demonstrates a simple vector sum on the GPU and on the host.
* sumArraysOnGPU splits the work of the vector sum across CUDA threads on the
* GPU. Only a single thread block is used in this small case, for simplicity.
* sumArraysOnHost sequentially iterates through vector elements on the host.
*/
void checkResult(float *hostRef, float *gpuRef, const int N)
{
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++)
{
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
match = 0;
printf("Arrays do not match!\n");
printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i],
gpuRef[i], i);
break;
}
}
if (match) printf("Arrays match.\n\n");
return;
}
void initialData(float *ip, int size)
{
// generate different seed for random number
time_t t;
srand((unsigned) time(&t));
for (int i = 0; i < size; i++)
{
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
return;
}
void sumArraysOnHost(float *A, float *B, float *C, const int N)
{
for (int idx = 0; idx < N; idx++)
C[idx] = A[idx] + B[idx];
}
__global__ void sumArraysOnGPU(float *A, float *B, float *C, const int N)
{
int i = threadIdx.x;
if (i < N) C[i] = A[i] + B[i];
}
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
// set up device
int dev = 0;
CHECK(cudaSetDevice(dev));
// set up data size of vectors
int nElem = 1 << 5;
printf("Vector size %d\n", nElem);
// malloc host memory
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
initialData(h_A, nElem);
initialData(h_B, nElem);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// malloc device global memory
float *d_A, *d_B, *d_C;
CHECK(cudaMalloc((float**)&d_A, nBytes));
CHECK(cudaMalloc((float**)&d_B, nBytes));
CHECK(cudaMalloc((float**)&d_C, nBytes));
// transfer data from host to device
CHECK(cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_C, gpuRef, nBytes, cudaMemcpyHostToDevice));
// invoke kernel at host side
dim3 block (nElem);
dim3 grid (1);
sumArraysOnGPU<<<grid, block>>>(d_A, d_B, d_C, nElem);
printf("Execution configure <<<%d, %d>>>\n", grid.x, block.x);
// copy kernel result back to host side
CHECK(cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost));
// add vector at host side for result checks
sumArraysOnHost(h_A, h_B, hostRef, nElem);
// check device results
checkResult(hostRef, gpuRef, nElem);
// free device global memory
CHECK(cudaFree(d_A));
CHECK(cudaFree(d_B));
CHECK(cudaFree(d_C));
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
CHECK(cudaDeviceReset());
return(0);
}

块和线程索引
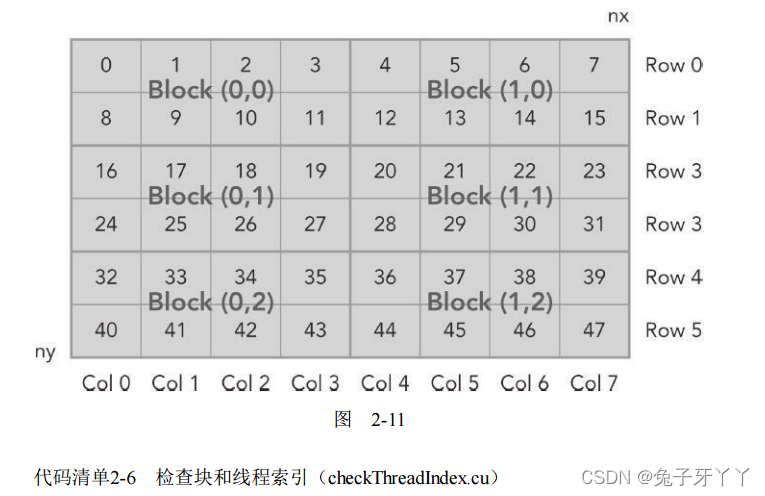
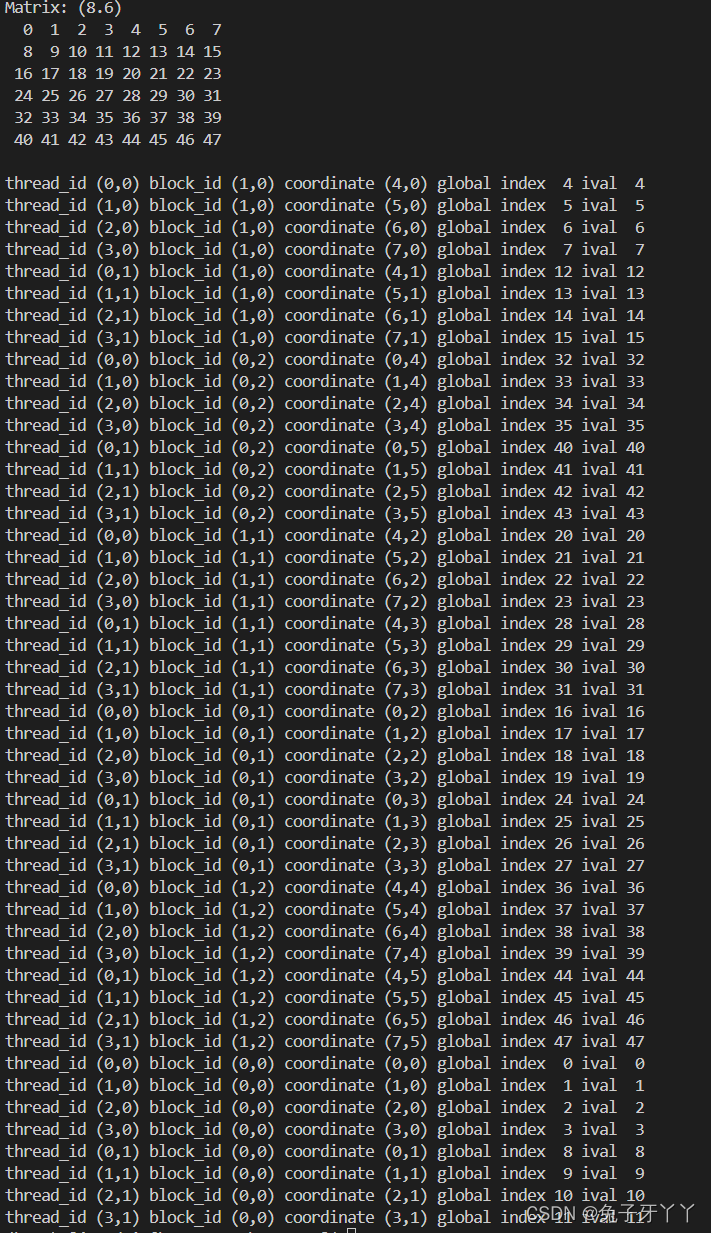
checkThreadIndex.cu
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*使用块和线程建立矩阵索引
* This example helps to visualize the relationship between thread/block IDs and
* offsets into data. For each CUDA thread, this example displays the
* intra-block thread ID, the inter-block block ID, the global coordinate of a
* thread, the calculated offset into input data, and the input data at that
* offset.
*/
void printMatrix(int *C, const int nx, const int ny)
{
int *ic = C;
printf("\nMatrix: (%d.%d)\n", nx, ny);
for (int iy = 0; iy < ny; iy++)
{
for (int ix = 0; ix < nx; ix++)
{
printf("%3d", ic[ix]);
}
ic += nx;
printf("\n");
}
printf("\n");
return;
}
__global__ void printThreadIndex(int *A, const int nx, const int ny)
{
int ix = threadIdx.x + blockIdx.x * blockDim.x;
int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy * nx + ix;
printf("thread_id (%d,%d) block_id (%d,%d) coordinate (%d,%d) global index"
" %2d ival %2d\n", threadIdx.x, threadIdx.y, blockIdx.x, blockIdx.y,
ix, iy, idx, A[idx]);
}
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
// get device information
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
// set matrix dimension
int nx = 8;
int ny = 6;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
// malloc host memory
int *h_A;
h_A = (int *)malloc(nBytes);
// iniitialize host matrix with integer
for (int i = 0; i < nxy; i++)
{
h_A[i] = i;
}
printMatrix(h_A, nx, ny);
// malloc device memory
int *d_MatA;
CHECK(cudaMalloc((void **)&d_MatA, nBytes));
// transfer data from host to device
CHECK(cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice));
// set up execution configuration
dim3 block(4, 2);
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y);
// invoke the kernel
printThreadIndex<<<grid, block>>>(d_MatA, nx, ny);
CHECK(cudaGetLastError());
// free host and devide memory
CHECK(cudaFree(d_MatA));
free(h_A);
// reset device
CHECK(cudaDeviceReset());
return (0);
}
矩阵和block,thread三者之间的关系
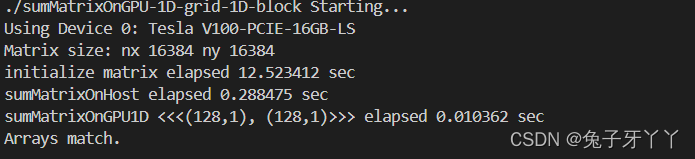
sumMatrixOnGPU-1D-grid-1D-block.cu

#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* This example demonstrates a simple vector sum on the GPU and on the host.
* sumArraysOnGPU splits the work of the vector sum across CUDA threads on the
* GPU. A 1D thread block and 1D grid are used. sumArraysOnHost sequentially
* iterates through vector elements on the host.
*/
void initialData(float *ip, const int size)
{
int i;
for(i = 0; i < size; i++)
{
ip[i] = (float)(rand() & 0xFF ) / 10.0f;
}
return;
}
void sumMatrixOnHost(float *A, float *B, float *C, const int nx,
const int ny)
{
float *ia = A;
float *ib = B;
float *ic = C;
for (int iy = 0; iy < ny; iy++)
{
for (int ix = 0; ix < nx; ix++)
{
ic[ix] = ia[ix] + ib[ix];
}
ia += nx;
ib += nx;
ic += nx;
}
return;
}
void checkResult(float *hostRef, float *gpuRef, const int N)
{
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++)
{
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
match = 0;
printf("host %f gpu %f\n", hostRef[i], gpuRef[i]);
break;
}
}
if (match)
printf("Arrays match.\n\n");
else
printf("Arrays do not match.\n\n");
}
// grid 1D block 1D
__global__ void sumMatrixOnGPU1D(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x; //blockDim=32
if (ix < nx ) //根据nx计算线程id边界
for (int iy = 0; iy < ny; iy++)//每个thread计算每一列的值
{
int idx = iy * nx + ix;
MatC[idx] = MatA[idx] + MatB[idx];
}
}
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
// set up data size of matrix
int nx = 1 << 14;
int ny = 1 << 14;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
printf("Matrix size: nx %d ny %d\n", nx, ny);
// malloc host memory
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
double iStart = seconds();
initialData(h_A, nxy);
initialData(h_B, nxy);
double iElaps = seconds() - iStart;
printf("initialize matrix elapsed %f sec\n", iElaps);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// add matrix at host side for result checks
iStart = seconds();
sumMatrixOnHost(h_A, h_B, hostRef, nx, ny);
iElaps = seconds() - iStart;
printf("sumMatrixOnHost elapsed %f sec\n", iElaps);
// malloc device global memory
float *d_MatA, *d_MatB, *d_MatC;
CHECK(cudaMalloc((void **)&d_MatA, nBytes));
CHECK(cudaMalloc((void **)&d_MatB, nBytes));
CHECK(cudaMalloc((void **)&d_MatC, nBytes));
// transfer data from host to device
CHECK(cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_MatB, h_B, nBytes, cudaMemcpyHostToDevice));
// invoke kernel at host side
int dimx = 128;
dim3 block(dimx, 1);
dim3 grid((nx + block.x - 1) / block.x, 1);
iStart = seconds();
sumMatrixOnGPU1D<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU1D <<<(%d,%d), (%d,%d)>>> elapsed %f sec\n", grid.x,
grid.y,
block.x, block.y, iElaps);
// check kernel error
CHECK(cudaGetLastError());
// copy kernel result back to host side
CHECK(cudaMemcpy(gpuRef, d_MatC, nBytes, cudaMemcpyDeviceToHost));
// check device results
checkResult(hostRef, gpuRef, nxy);
// free device global memory
CHECK(cudaFree(d_MatA));
CHECK(cudaFree(d_MatB));
CHECK(cudaFree(d_MatC));
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
// reset device
CHECK(cudaDeviceReset());
return (0);
}
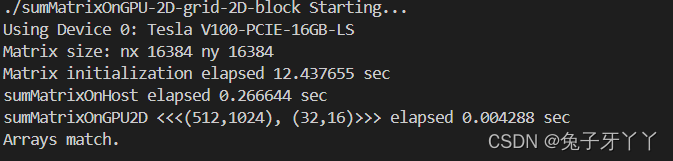
sumMatrixOnGPU-2D-grid-2D-block.cu
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*使用二维网格和二维块对矩阵求和
* This example demonstrates a simple vector sum on the GPU and on the host.
* sumArraysOnGPU splits the work of the vector sum across CUDA threads on the
* GPU. A 2D thread block and 2D grid are used. sumArraysOnHost sequentially
* iterates through vector elements on the host.
*/
void initialData(float *ip, const int size)
{
int i;
for(i = 0; i < size; i++)
{
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
return;
}
void sumMatrixOnHost(float *A, float *B, float *C, const int nx,
const int ny)
{
float *ia = A;
float *ib = B;
float *ic = C;
for (int iy = 0; iy < ny; iy++)
{
for (int ix = 0; ix < nx; ix++)
{
ic[ix] = ia[ix] + ib[ix];
}
ia += nx;
ib += nx;
ic += nx;
}
return;
}
void checkResult(float *hostRef, float *gpuRef, const int N)
{
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++)
{
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
match = 0;
printf("host %f gpu %f\n", hostRef[i], gpuRef[i]);
break;
}
}
if (match)
printf("Arrays match.\n\n");
else
printf("Arrays do not match.\n\n");
}
// grid 2D block 2D
__global__ void sumMatrixOnGPU2D(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
// set up data size of matrix
int nx = 1 << 14;
int ny = 1 << 14;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
printf("Matrix size: nx %d ny %d\n", nx, ny);
// malloc host memory
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
double iStart = seconds();
initialData(h_A, nxy);
initialData(h_B, nxy);
double iElaps = seconds() - iStart;
printf("Matrix initialization elapsed %f sec\n", iElaps);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// add matrix at host side for result checks
iStart = seconds();
sumMatrixOnHost(h_A, h_B, hostRef, nx, ny);
iElaps = seconds() - iStart;
printf("sumMatrixOnHost elapsed %f sec\n", iElaps);
// malloc device global memory
float *d_MatA, *d_MatB, *d_MatC;
CHECK(cudaMalloc((void **)&d_MatA, nBytes));
CHECK(cudaMalloc((void **)&d_MatB, nBytes));
CHECK(cudaMalloc((void **)&d_MatC, nBytes));
// transfer data from host to device
CHECK(cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_MatB, h_B, nBytes, cudaMemcpyHostToDevice));
// invoke kernel at host side
int dimx = 32;
int dimy = 16;
dim3 block(dimx, dimy);
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y);
iStart = seconds();
sumMatrixOnGPU2D<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU2D <<<(%d,%d), (%d,%d)>>> elapsed %f sec\n", grid.x,
grid.y,
block.x, block.y, iElaps);
// check kernel error
CHECK(cudaGetLastError());
// copy kernel result back to host side
CHECK(cudaMemcpy(gpuRef, d_MatC, nBytes, cudaMemcpyDeviceToHost));
// check device results
checkResult(hostRef, gpuRef, nxy);
// free device global memory
CHECK(cudaFree(d_MatA));
CHECK(cudaFree(d_MatB));
CHECK(cudaFree(d_MatC));
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
// reset device
CHECK(cudaDeviceReset());
return (0);
}
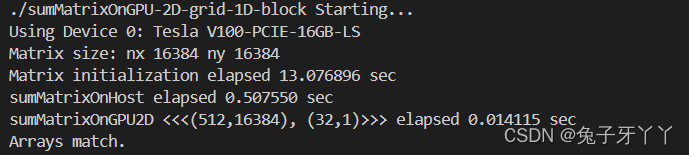
sumMatrixOnGPU-2D-grid-1D-block.cu

#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* This example demonstrates a simple vector sum on the GPU and on the host.
* sumArraysOnGPU splits the work of the vector sum across CUDA threads on the
* GPU. A 1D thread block and 2D grid are used. sumArraysOnHost sequentially
* iterates through vector elements on the host.
*/
void initialData(float *ip, const int size)
{
int i;
for(i = 0; i < size; i++)
{
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
return;
}
void sumMatrixOnHost(float *A, float *B, float *C, const int nx,
const int ny)
{
float *ia = A;
float *ib = B;
float *ic = C;
for (int iy = 0; iy < ny; iy++)
{
for (int ix = 0; ix < nx; ix++)
{
ic[ix] = ia[ix] + ib[ix];
}
ia += nx;
ib += nx;
ic += nx;
}
return;
}
void checkResult(float *hostRef, float *gpuRef, const int N)
{
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++)
{
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
match = 0;
printf("host %f gpu %f\n", hostRef[i], gpuRef[i]);
break;
}
}
if (match)
printf("Arrays match.\n\n");
else
printf("Arrays do not match.\n\n");
}
// grid 2D block 1D
__global__ void sumMatrixOnGPUMix(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = blockIdx.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
// set up data size of matrix
int nx = 1 << 14;
int ny = 1 << 14;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
printf("Matrix size: nx %d ny %d\n", nx, ny);
// malloc host memory
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
double iStart = seconds();
initialData(h_A, nxy);
initialData(h_B, nxy);
double iElaps = seconds() - iStart;
printf("Matrix initialization elapsed %f sec\n", iElaps);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// add matrix at host side for result checks
iStart = seconds();
sumMatrixOnHost(h_A, h_B, hostRef, nx, ny);
iElaps = seconds() - iStart;
printf("sumMatrixOnHost elapsed %f sec\n", iElaps);
// malloc device global memory
float *d_MatA, *d_MatB, *d_MatC;
CHECK(cudaMalloc((void **)&d_MatA, nBytes));
CHECK(cudaMalloc((void **)&d_MatB, nBytes));
CHECK(cudaMalloc((void **)&d_MatC, nBytes));
// transfer data from host to device
CHECK(cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_MatB, h_B, nBytes, cudaMemcpyHostToDevice));
// invoke kernel at host side
int dimx = 32;
dim3 block(dimx, 1);
dim3 grid((nx + block.x - 1) / block.x, ny);
iStart = seconds();
sumMatrixOnGPUMix<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU2D <<<(%d,%d), (%d,%d)>>> elapsed %f sec\n", grid.x,
grid.y,
block.x, block.y, iElaps);
// check kernel error
CHECK(cudaGetLastError());
// copy kernel result back to host side
CHECK(cudaMemcpy(gpuRef, d_MatC, nBytes, cudaMemcpyDeviceToHost));
// check device results
checkResult(hostRef, gpuRef, nxy);
// free device global memory
CHECK(cudaFree(d_MatA));
CHECK(cudaFree(d_MatB));
CHECK(cudaFree(d_MatC));
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
// reset device
CHECK(cudaDeviceReset());
return (0);
}
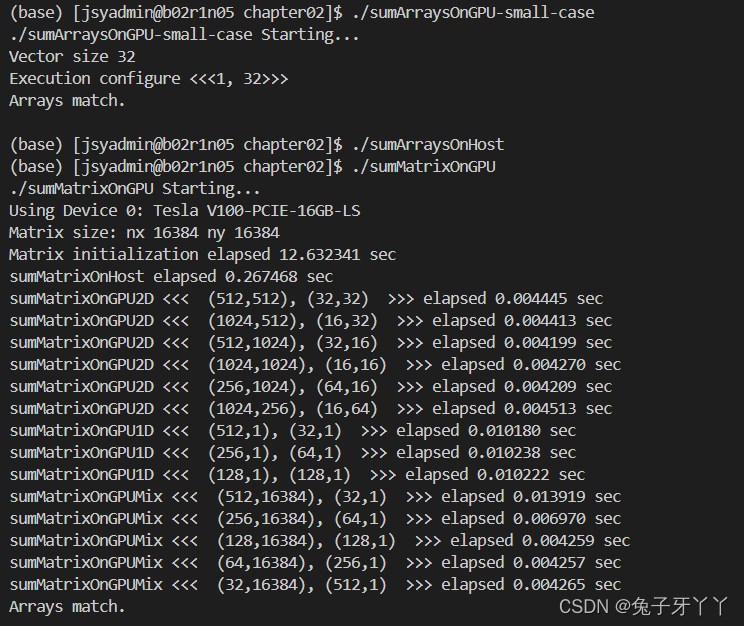
sumMatrixOnGPU.cu
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* This example demonstrates a simple vector sum on the GPU and on the host.
* The performance of a variety of CUDA thread configurations is tested using
* the sumMatrixOnGPU2D, sumMatrixOnGPU1D, and sumMatrixOnGPUMix kernels.
* sumArraysOnHost sequentially iterates through vector elements on the host.
*/
void initialData(float *ip, const float ival, int size)
{
for (int i = 0; i < size; i++)
{
ip[i] = (float)(rand() & 0xFF) / 100.0f;
}
return;
}
void sumMatrixOnHost(float *A, float *B, float *C, const int nx, const int ny)
{
float *ia = A;
float *ib = B;
float *ic = C;
for (int iy = 0; iy < ny; iy++)
{
for (int ix = 0; ix < nx; ix++)
{
ic[ix] = ia[ix] + ib[ix];
}
ia += nx;
ib += nx;
ic += nx;
}
return;
}
void printMatrix(float *C, const int nx, const int ny)
{
float *ic = C;
for (int iy = 0; iy < ny; iy++)
{
for (int ix = 0; ix < nx; ix++)
{
printf("%f ", ic[ix]);
}
ic += nx;
printf("\n");
}
return;
}
void checkResult(float *hostRef, float *gpuRef, const int N)
{
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++)
{
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
match = 0;
printf("host %f gpu %f\n", hostRef[i], gpuRef[i]);
break;
}
}
if (match)
printf("Arrays match.\n\n");
else
printf("Arrays do not match.\n\n");
}
// grid 2D block 2D
__global__ void sumMatrixOnGPU2D(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}
// grid 1D block 1D
__global__ void sumMatrixOnGPU1D(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
if (ix < nx )
for (int iy = 0; iy < ny; iy++)
{
int idx = iy * nx + ix;
MatC[idx] = MatA[idx] + MatB[idx];
}
}
// grid 2D block 1D
__global__ void sumMatrixOnGPUMix(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = blockIdx.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
// set up data size of matrix
int nx = 1 << 14;
int ny = 1 << 14;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
printf("Matrix size: nx %d ny %d\n", nx, ny);
// malloc host memory
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
double iStart = seconds();
initialData(h_A, 2.0f, nxy);
initialData(h_B, 0.5f, nxy);
double iElaps = seconds() - iStart;
printf("Matrix initialization elapsed %f sec\n", iElaps);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
iStart = seconds();
sumMatrixOnHost(h_A, h_B, hostRef, nx, ny);
iElaps = seconds() - iStart;
printf("sumMatrixOnHost elapsed %f sec\n", iElaps);
float *d_MatA, *d_MatB, *d_MatC;
CHECK(cudaMalloc((void **)&d_MatA, nBytes));
CHECK(cudaMalloc((void **)&d_MatB, nBytes));
CHECK(cudaMalloc((void **)&d_MatC, nBytes));
CHECK(cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_MatB, h_B, nBytes, cudaMemcpyHostToDevice));
int dimx = 32;
int dimy = 32;
dim3 block(dimx, dimy);
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y);
iStart = seconds();
sumMatrixOnGPU2D<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU2D <<< (%d,%d), (%d,%d) >>> elapsed %f sec\n",
grid.x, grid.y, block.x, block.y, iElaps);
// adjust block size
block.x = 16;
grid.x = (nx + block.x - 1) / block.x;
grid.y = (ny + block.y - 1) / block.y;
iStart = seconds();
sumMatrixOnGPU2D<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU2D <<< (%d,%d), (%d,%d) >>> elapsed %f sec\n",
grid.x, grid.y, block.x, block.y, iElaps);
// adjust block size
block.y = 16;
block.x = 32;
grid.x = (nx + block.x - 1) / block.x;
grid.y = (ny + block.y - 1) / block.y;
iStart = seconds();
sumMatrixOnGPU2D<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU2D <<< (%d,%d), (%d,%d) >>> elapsed %f sec\n",
grid.x, grid.y, block.x, block.y, iElaps);
block.y = 16;
block.x = 16;
grid.x = (nx + block.x - 1) / block.x;
grid.y = (ny + block.y - 1) / block.y;
iStart = seconds();
sumMatrixOnGPU2D<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU2D <<< (%d,%d), (%d,%d) >>> elapsed %f sec\n",
grid.x, grid.y, block.x, block.y, iElaps);
block.y = 16;
block.x = 64;
grid.x = (nx + block.x - 1) / block.x;
grid.y = (ny + block.y - 1) / block.y;
iStart = seconds();
sumMatrixOnGPU2D<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU2D <<< (%d,%d), (%d,%d) >>> elapsed %f sec\n",
grid.x, grid.y, block.x, block.y, iElaps);
block.y = 64;
block.x = 16;
grid.x = (nx + block.x - 1) / block.x;
grid.y = (ny + block.y - 1) / block.y;
iStart = seconds();
sumMatrixOnGPU2D<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU2D <<< (%d,%d), (%d,%d) >>> elapsed %f sec\n",
grid.x, grid.y, block.x, block.y, iElaps);
block.x = 32;
grid.x = (nx + block.x - 1) / block.x;
block.y = 1;
grid.y = 1;
iStart = seconds();
sumMatrixOnGPU1D<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU1D <<< (%d,%d), (%d,%d) >>> elapsed %f sec\n",
grid.x, grid.y, block.x, block.y, iElaps);
block.x = 64;
grid.x = (nx + block.x - 1) / block.x;
block.y = 1;
grid.y = 1;
iStart = seconds();
sumMatrixOnGPU1D<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU1D <<< (%d,%d), (%d,%d) >>> elapsed %f sec\n",
grid.x, grid.y, block.x, block.y, iElaps);
block.x = 128;
grid.x = (nx + block.x - 1) / block.x;
block.y = 1;
grid.y = 1;
iStart = seconds();
sumMatrixOnGPU1D<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU1D <<< (%d,%d), (%d,%d) >>> elapsed %f sec\n",
grid.x, grid.y, block.x, block.y, iElaps);
// grid 2D and block 1D
block.x = 32;
grid.x = (nx + block.x - 1) / block.x;
block.y = 1;
grid.y = ny;
iStart = seconds();
sumMatrixOnGPUMix<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPUMix <<< (%d,%d), (%d,%d) >>> elapsed %f sec\n",
grid.x, grid.y, block.x, block.y, iElaps);
block.x = 64;
grid.x = (nx + block.x - 1) / block.x;
block.y = 1;
grid.y = ny;
iStart = seconds();
sumMatrixOnGPUMix<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPUMix <<< (%d,%d), (%d,%d) >>> elapsed %f sec\n",
grid.x, grid.y, block.x, block.y, iElaps);
block.x = 128;
grid.x = (nx + block.x - 1) / block.x;
block.y = 1;
grid.y = ny;
iStart = seconds();
sumMatrixOnGPUMix<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPUMix <<< (%d,%d), (%d,%d) >>> elapsed %f sec\n",
grid.x, grid.y, block.x, block.y, iElaps);
block.x = 256;
grid.x = (nx + block.x - 1) / block.x;
block.y = 1;
grid.y = ny;
iStart = seconds();
sumMatrixOnGPUMix<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPUMix <<< (%d,%d), (%d,%d) >>> elapsed %f sec\n",
grid.x, grid.y, block.x, block.y, iElaps);
block.x = 512;
grid.x = (nx + block.x - 1) / block.x;
block.y = 1;
grid.y = ny;
iStart = seconds();
sumMatrixOnGPUMix<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPUMix <<< (%d,%d), (%d,%d) >>> elapsed %f sec\n",
grid.x, grid.y, block.x, block.y, iElaps);
CHECK(cudaMemcpy(gpuRef, d_MatC, nBytes, cudaMemcpyDeviceToHost));
checkResult(hostRef, gpuRef, nxy);
CHECK(cudaFree(d_MatA));
CHECK(cudaFree(d_MatB));
CHECK(cudaFree(d_MatC));
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
return (0);
}
计时
事件的创建和销毁
事件(Event)可以被压入流中以监视流的运行情况,或者用于精确计时。
如果向stream 0压入事件,则当压入事件前向所有流压入的任务完成后,事件才被触发。
cudaEvent_t start, stop; //创建
cudaEventCreate(&start);
cudaEventCreate(&stop);
...
cudaEventDestroy(start); //销毁
cudaEventDestroy(stop);
cudaEventRecord(start, 0); //记录事件(将事件压入流),流0则代表所有流完成任务后事件才会被触发
for (int i = 0; i < 2; ++i) {
cudaMemcpyAsync(inputDev + i * size, inputHost + i * size, size, cudaMemcpyHostToDevice, stream[i]);
MyKernel<<<100, 512, 0, stream[i]>>>(outputDev + i * size, inputDev + i * size, size);
cudaMemcpyAsync(outputHost + i * size, outputDev + i * size, size, cudaMemcpyDeviceToHost, stream[i]);
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop); //获取两个事件发生的时间差(ms)
sumArraysOnGPU-timer.cu
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* This example demonstrates a simple vector sum on the GPU and on the host.
* sumArraysOnGPU splits the work of the vector sum across CUDA threads on the
* GPU. Only a single thread block is used in this small case, for simplicity.
* sumArraysOnHost sequentially iterates through vector elements on the host.
* This version of sumArrays adds host timers to measure GPU and CPU
* performance.
*/
void checkResult(float *hostRef, float *gpuRef, const int N)
{
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++)
{
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
match = 0;
printf("Arrays do not match!\n");
printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i],
gpuRef[i], i);
break;
}
}
if (match) printf("Arrays match.\n\n");
return;
}
void initialData(float *ip, int size)
{
// generate different seed for random number
time_t t;
srand((unsigned) time(&t));
for (int i = 0; i < size; i++)
{
ip[i] = (float)( rand() & 0xFF ) / 10.0f;
}
return;
}
void sumArraysOnHost(float *A, float *B, float *C, const int N)
{
for (int idx = 0; idx < N; idx++)
{
C[idx] = A[idx] + B[idx];
}
}
__global__ void sumArraysOnGPU(float *A, float *B, float *C, const int N)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) C[i] = A[i] + B[i];
}
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
// set up data size of vectors
int nElem = 1 << 24;
printf("Vector size %d\n", nElem);
// malloc host memory
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
double iStart, iElaps;
// initialize data at host side
iStart = seconds();
initialData(h_A, nElem);
initialData(h_B, nElem);
iElaps = seconds() - iStart;
printf("initialData Time elapsed %f sec\n", iElaps);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// add vector at host side for result checks
iStart = seconds();
sumArraysOnHost(h_A, h_B, hostRef, nElem);
iElaps = seconds() - iStart;
printf("sumArraysOnHost Time elapsed %f sec\n", iElaps);
// malloc device global memory
float *d_A, *d_B, *d_C;
CHECK(cudaMalloc((float**)&d_A, nBytes));
CHECK(cudaMalloc((float**)&d_B, nBytes));
CHECK(cudaMalloc((float**)&d_C, nBytes));
// transfer data from host to device
CHECK(cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_C, gpuRef, nBytes, cudaMemcpyHostToDevice));
// invoke kernel at host side
int iLen = 512;
dim3 block (iLen);
dim3 grid ((nElem + block.x - 1) / block.x);
iStart = seconds();
sumArraysOnGPU<<<grid, block>>>(d_A, d_B, d_C, nElem);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumArraysOnGPU <<< %d, %d >>> Time elapsed %f sec\n", grid.x,
block.x, iElaps);
// check kernel error
CHECK(cudaGetLastError()) ;
// copy kernel result back to host side
CHECK(cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost));
// check device results
checkResult(hostRef, gpuRef, nElem);
// free device global memory
CHECK(cudaFree(d_A));
CHECK(cudaFree(d_B));
CHECK(cudaFree(d_C));
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
return(0);
}
errorCheck.cu
#include "../common/common.h"
#include<stdio.h>
int main()
{
float *gpuMemory = NULL;
ErrorCheck(cudaMalloc(&gpuMemory,100*sizeof(float)),__FILE__,__LINE__);
ErrorCheck(cudaFree(gpuMemory),__FILE__,__LINE__);
ErrorCheck(cudaFree(gpuMemory),__FILE__,__LINE__);
ErrorCheck(cudaDeviceReset(),__FILE__,__LINE__);
return 0;
}
cudaDeviceSynchronize()
cudaDeviceSynchronize()函数用于等待当前设备上所有的任务完成。在CUDA程序中,GPU和CPU是异步执行的,因此在某些情况下,我们需要等待GPU完成任务后再执行CPU的任务。这时,需要使用cudaDeviceSynchronize()函数。
__syncthreads()
功能是确保在某个线程块中的所有线程在执行到这个函数之前都已完成它们之前的所有指令。一旦所有线程都到达这个同步点,它们才可以继续执行__syncthreads()之后的指令。这个函数只能在设备代码(如CUDA内核)中使用。