
目录
本地模式(local)搭建
下载flink安装包
https://downloads.apache.org/flink/flink-1.12.2/flink-1.12.2-bin-scala_2.11.tgz
上传至虚拟机并解压

[root@master1 flink]# tar -xzvf flink-1.12.2-bin-scala_2.11.tgz
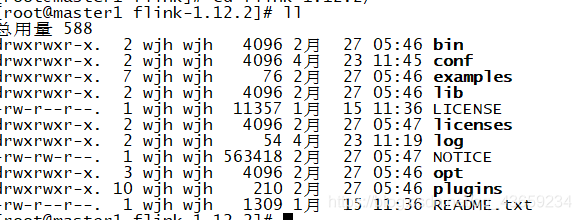
配置环境变量
配置环境变量是为了更好的操作命令
刷新权限
source /etc/profile

启动flink并测试
[root@master1 flink-1.12.2]# start-scala-shell.sh local
其中两端分别为批处理的示例和流式处理的示例
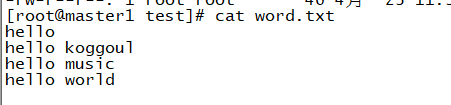
准备一份测试文档
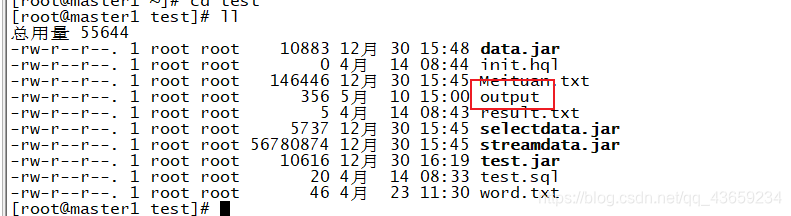
测试结果
测试一下本地能否运行
创建一份test.txt



[root@master1 batch]# flink run WordCount.jar --input /root/test.txt --output /root/test/output/


集群(standalone)模式搭建
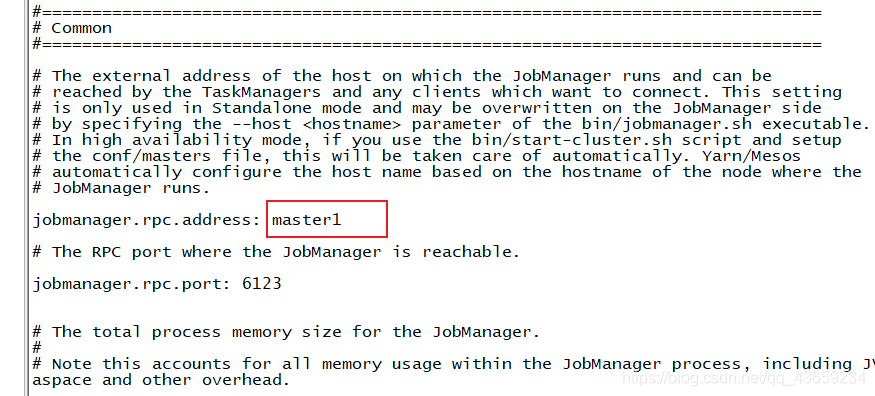
配置flink-conf.yaml和workers文件
!!!如果是使用HA集群其中的masters文件还需要配置
flink-conf.yaml文件


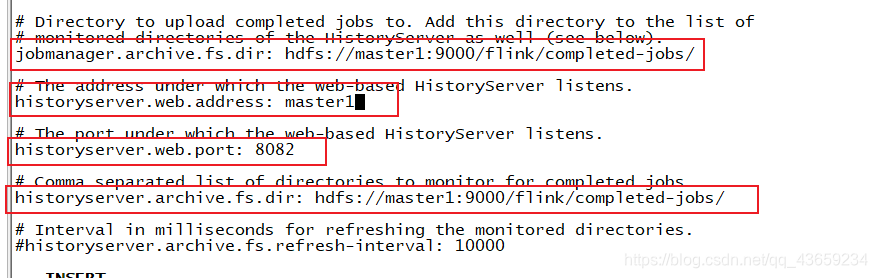
配置历史服务器
在环境变量中加入Hadoop配置文件的信息

由于flink集群的CLASS_PATH下缺少了 HDFS相关的jar会导致historyserver启动不起来
点击下面链接将所需的jar下载并上传至flink的lib文件夹下就行
https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop2-uber/2.6.5-1.8.0/
workers文件

masters文件
分发集群
刷新权限
有安装scala的话把它注释了,避免麻烦
没有的话跳过这个步骤




启动flink集群
启动
启动命令:start-cluster.sh

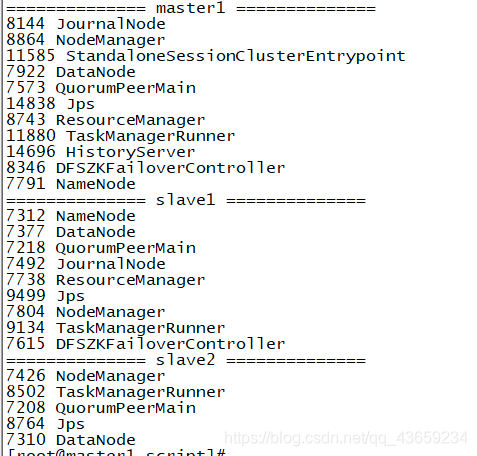
jps查看进程
master1上有两个进程
slave1,2上有一个进程
测试集群
hdfs上测试
[root@master1 batch]# flink run WordCount.jar --input hdfs://master1:9000/test/test.txt --output hdfs://master1:9000/test/output/result.txt

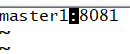
master1:8081页面



!!!碰到的坑
不知道有-和没-有啥区别,我一开始用有-的怎么都不能运行flink的jar包,换成没-就运行有点懵不知道为什么


HadoopHA的问题,master1是standby状态,在flink上指定的是master1但是它是宕机状态,所以不能运行wordcount的jar包