消息发送
消息生产流程
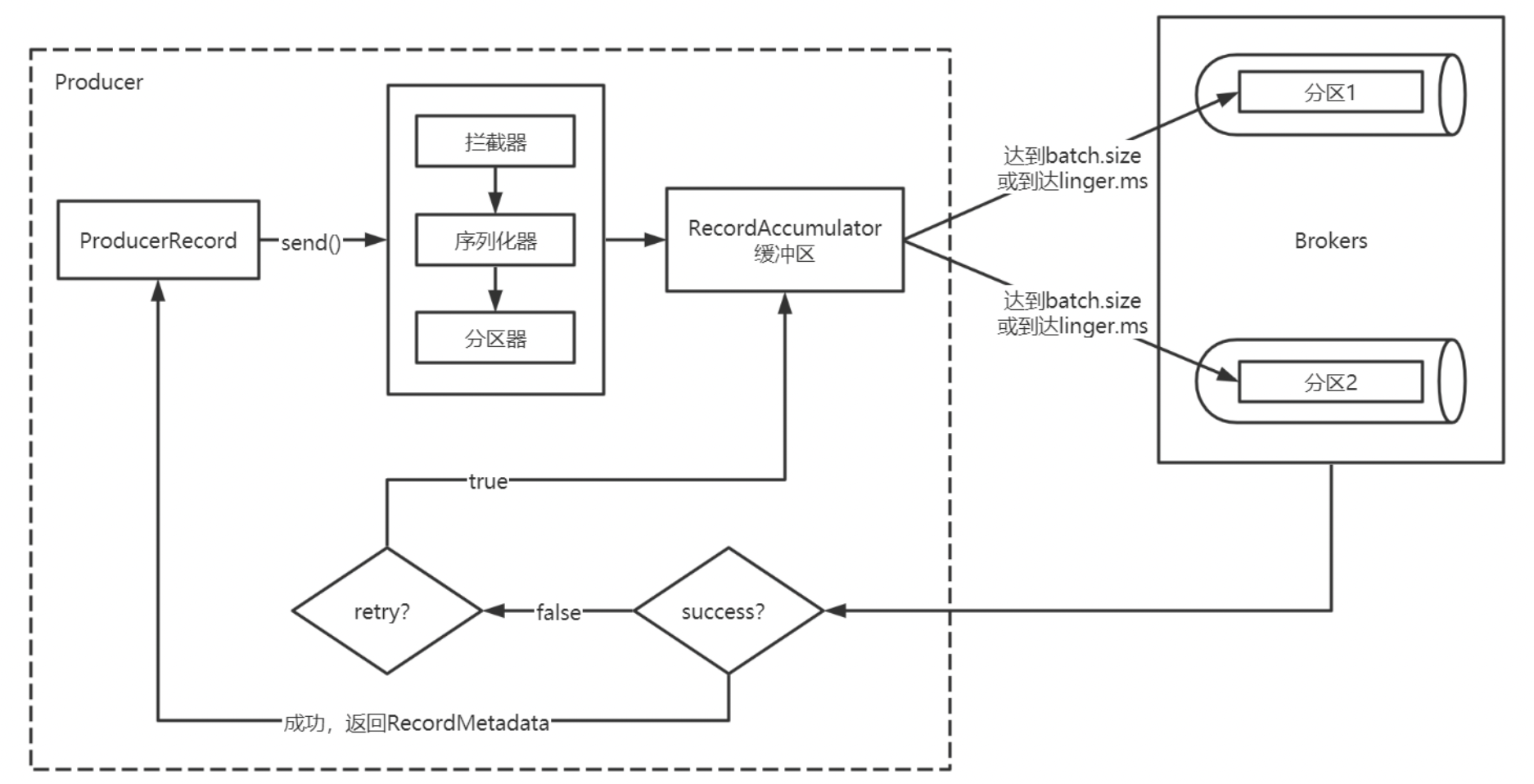
整个流程如下:
- Producer创建时,会创建一个Sender线程并设置为守护线程。
- 生产消息时,内部其实是异步流程;生产的消息先经过拦截器->序列化器->分区器,然后将消息缓存在缓冲区(该缓冲区也是在Producer创建时创建)。
- 批次发送的条件为:缓冲区数据大小达到batch.size或者linger.ms达到上限,哪个先达到就算哪个。
- 批次发送后,发往指定分区,然后落盘到broker;如果生产者配置了retrires参数大于0并且失败原因允许重试,那么客户端内部会对该消息进行重试。
- 落盘到broker成功,返回生产元数据给生产者。
- 元数据返回有两种方式:一种是通过阻塞直接返回,另一种是通过回调返回。
ProducerRecord
在生产发送消息前,会将信息封装成ProducerRecord对象。主要由以下几部分组成:
private final String topic;
private final Integer partition;
private final Headers headers;
private final K key;
private final V value;
private final Long timestamp;
其中主要有要发送的Topic名称,要发送至那个分区,以及要发送的数据和key。
其他的都比较好理解,key的作用是如果key存在的话,就会对key进行hash,然后根据不同的结果发送至不同的分区,这样当有相同的key时,所有相同的key都会发送到同一个分区,我们之前也提到,所有的新消息都会被添加到分区的尾部,进而保证了数据的顺序性。
序列化器
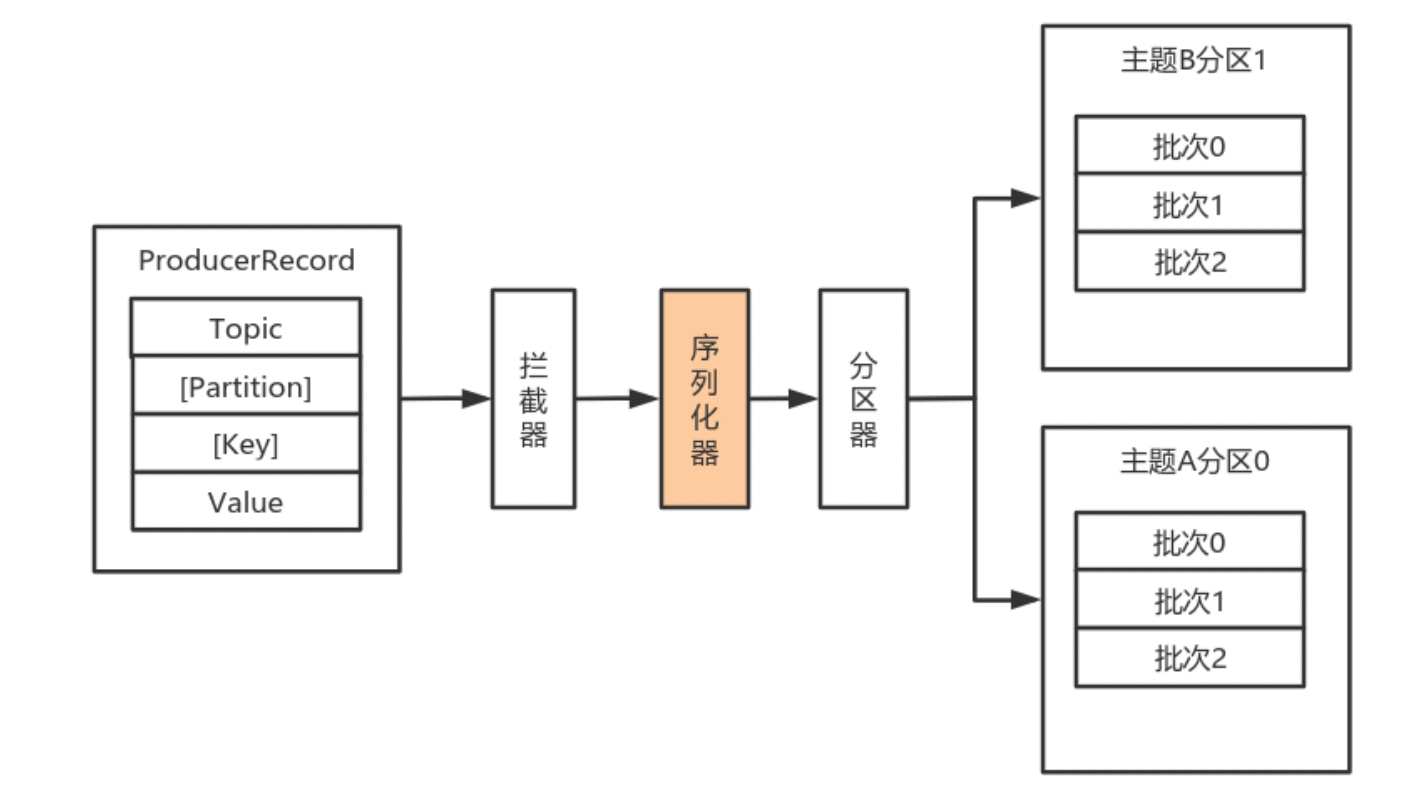
由于Kafka中的数据都是字节数组,在将消息发送到Kafka之前需要先将数据序列化为字节数组。
序列化器的作用就是用于序列化要发送的消息的。
Kafka使用org.apache.kafka.common.serialization.Serializer 接口用于定义序列化器,将泛型指定类型的数据转换为字节数组,如下:
public interface Serializer<T> extends Closeable {
default void configure(Map<String, ?> configs, boolean isKey) {
}
byte[] serialize(String var1, T var2);
default byte[] serialize(String topic, Headers headers, T data) {
return this.serialize(topic, data);
}
default void close() {
}
}
其中kafka提供了许多实现类。
除了上述提供的,还可以自定义序列化器,只要实现Serializer接口即可。
假如我们有如下实体类:
public class User {
private Integer userId;
private String username;
public Integer getUserId() {
return userId;
}
public void setUserId(Integer userId) {
this.userId = userId;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
}
序列化类:
import com.lagou.kafka.demo.entity.User;
import org.apache.kafka.common.errors.SerializationException;
import org.apache.kafka.common.serialization.Serializer;
import java.io.UnsupportedEncodingException;
import java.nio.Buffer;
import java.nio.ByteBuffer;
import java.util.Map;
public class UserSerializer implements Serializer<User> {
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
// do nothing
}
@Override
public byte[] serialize(String topic, User data) {
try {
// 如果数据是null,则返回null
if (data == null) return null;
Integer userId = data.getUserId();
String username = data.getUsername();
int length = 0;
byte[] bytes = null;
if (null != username) {
bytes = username.getBytes("utf-8");
length = bytes.length;
}
ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + length);
buffer.putInt(userId);
buffer.putInt(length);
buffer.put(bytes);
return buffer.array();
} catch (UnsupportedEncodingException e) {
throw new SerializationException("序列化数据异常");
}
}
@Override
public void close() {
// do nothing
}
}
分区器
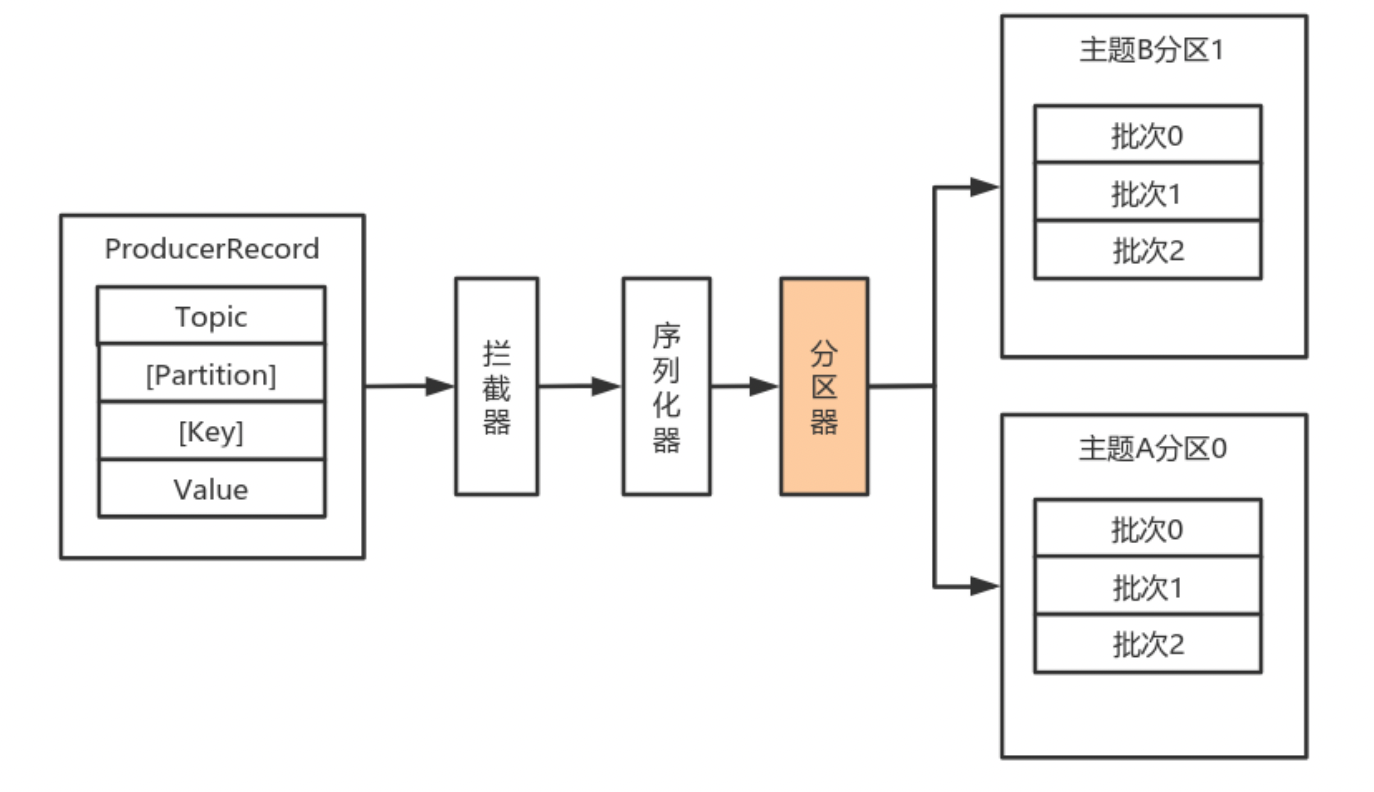
分区器来计算消息该发送到哪个分区中。
默认(DefaultPartitioner)分区计算:
- 如果record提供了分区号,则使用record提供的分区号
- 如果record没有提供分区号,则使用key的序列化后的值的hash值对分区数量取模
- 如果record没有提供分区号,也没有提供key,则使用轮询的方式分配分区号。
也可以自定义分区器,需要
- 首先开发Partitioner接口的实现类
- 在KafkaProducer中进行设置:configs.put(“partitioner.class”, “xxx.xx.Xxx.class”)
拦截器
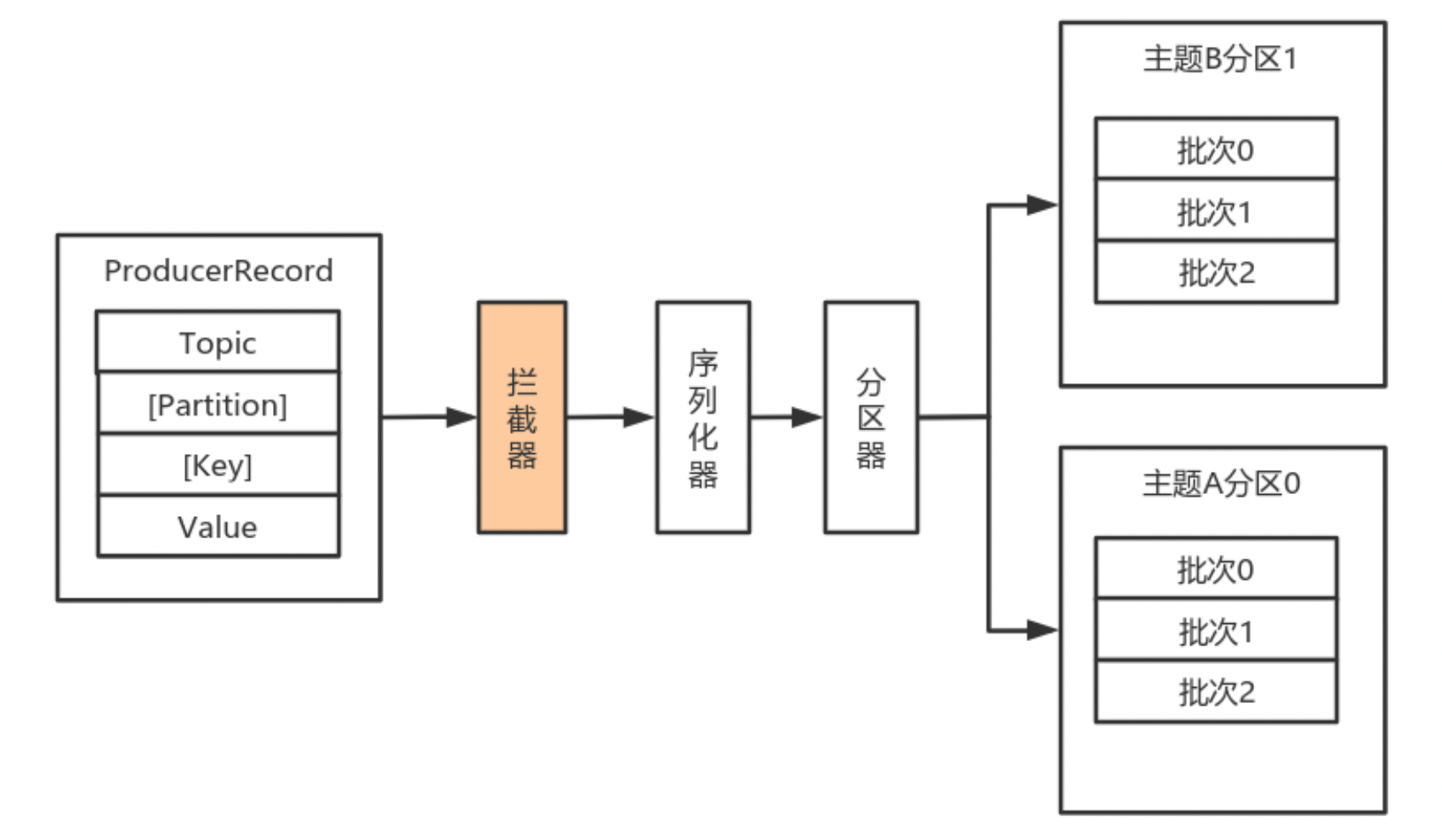
Producer拦截器(interceptor)和Consumer端Interceptor是在Kafka 0.10版本被引入的,主要用于实现Client端的定制化控制逻辑。
对于Producer而言,Interceptor使得用户在消息发送前以及Producer回调逻辑前有机会对消息做一些定制化需求,比如修改消息等。同时,Producer允许用户指定多个Interceptor按序作用于同一条消息从而形成一个拦截链(interceptor chain)。
注意拦截器发生异常抛出的异常会被忽略;此外,也要注意一种情况:如果某个拦截器依赖上一个拦截器的结果,但是当上一个拦截器异常,则该拦截器可能也不会正常工作,因为他接受到的是上一个成功返回的结果,而不是期望的上一个拦截器结果。
Intercetpor的实现接口是org.apache.kafka.clients.producer.ProducerInterceptor,其定义的方法包括:
- onSend(ProducerRecord):该方法封装进KafkaProducer.send方法中,即运行在用户主线程中。Producer确保在消息被序列化以计算分区前调用该方法。用户可以在该方法中对消息做任何操作,但最好保证不要修改消息所属的topic和分区,否则会影响目标分区的计算。
- onAcknowledgement(RecordMetadata, Exception):该方法会在消息被应答之前或消息发送失败时调用,并且通常都是在Producer回调逻辑触发之前。onAcknowledgement运行在Producer的IO线程中,因此不要在该方法中放入很重的逻辑,否则会拖慢Producer的消息发送效率。
- close:关闭Interceptor,主要用于执行一些资源清理工作。
如前所述,Interceptor可能被运行在多个线程中,因此在具体实现时用户需要自行确保线程安全。另外倘若指定了多个Interceptor,则Producer将按照指定顺序调用它们。
自定义拦截器步骤:
- 实现ProducerInterceptor接口
- 在KafkaProducer的设置中设置自定义的拦截器
案例:
消息实体类:
public class User {
private Integer userId;
private String username;
public Integer getUserId() {
return userId;
}
public void setUserId(Integer userId) {
this.userId = userId;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
}
还是用上面的序列化器。
自定义拦截器1:
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.header.Headers;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Map;
public class InterceptorOne implements ProducerInterceptor<Integer, String> {
private static final Logger LOGGER = LoggerFactory.getLogger(InterceptorOne.class);
@Override
public ProducerRecord<Integer, String> onSend(ProducerRecord<Integer, String> record) {
System.out.println("拦截器1 -- go");
// 消息发送的时候,经过拦截器,调用该方法
// 要发送的消息内容
final String topic = record.topic();
final Integer partition = record.partition();
final Integer key = record.key();
final String value = record.value();
final Long timestamp = record.timestamp();
final Headers headers = record.headers();
// 拦截器拦下来之后根据原来消息创建的新的消息
// 此处对原消息没有做任何改动
ProducerRecord<Integer, String> newRecord = new ProducerRecord<Integer, String>(
topic,
partition,
timestamp,
key,
value,
headers
);
// 传递新的消息
return newRecord;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
System.out.println("拦截器1 -- back");
// 消息确认或异常的时候,调用该方法,该方法中不应实现较重的任务
// 会影响kafka生产者的性能。
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
final Object classContent = configs.get("classContent");
System.out.println(classContent);
}
}
自定义拦截器2:
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.header.Headers;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Map;
public class InterceptorTwo implements ProducerInterceptor<Integer, String> {
private static final Logger LOGGER = LoggerFactory.getLogger(InterceptorTwo.class);
@Override
public ProducerRecord<Integer, String> onSend(ProducerRecord<Integer, String> record) {
System.out.println("拦截器2 -- go");
// 消息发送的时候,经过拦截器,调用该方法
// 要发送的消息内容
final String topic = record.topic();
final Integer partition = record.partition();
final Integer key = record.key();
final String value = record.value();
final Long timestamp = record.timestamp();
final Headers headers = record.headers();
// 拦截器拦下来之后根据原来消息创建的新的消息
// 此处对原消息没有做任何改动
ProducerRecord<Integer, String> newRecord = new ProducerRecord<Integer, String>(
topic,
partition,
timestamp,
key,
value,
headers
);
// 传递新的消息
return newRecord;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
System.out.println("拦截器2 -- back");
// 消息确认或异常的时候,调用该方法,该方法中不应实现较重的任务
// 会影响kafka生产者的性能。
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
final Object classContent = configs.get("classContent");
System.out.println(classContent);
}
}
正常那个运行会打印:
拦截器1 -- go
拦截器2 -- go
拦截器1 -- back
拦截器2 -- back
即发送和回调都是按照链的顺序正序来的。
生产者原理剖析
kafka整个消息发送流程如下图:
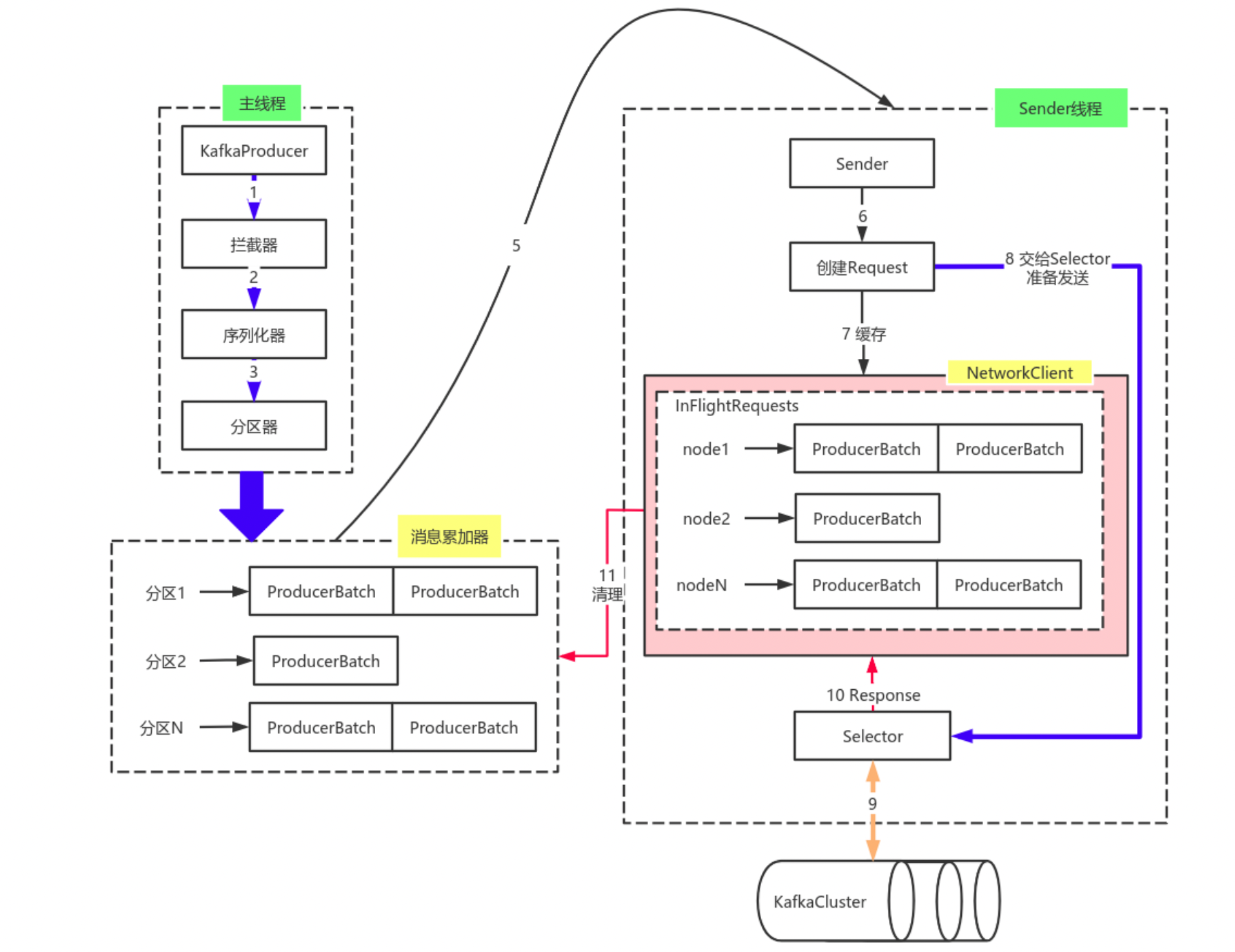
生产消息的所有工作分给了2个线程协作完成:一个是主线程(负责消息的预处理),第二个是发送线程(sender线程负责将发送消息以及接受发送的结果)。
主线程
主线程:负责消息创建,拦截器,序列化器,分区器等操作,并将消息追加到消息收集器消息累加器(RecoderAccumulator)中。
消息累加器
参考:https://mp.weixin.qq.com/s/n8iCJWA13Xz-haZnB8zYFg
消息累加器的作用是缓存消息以便sender线程可以批量发送,进而减少网络传输的资源消耗提升性能。
消息累加器的缓存大小可以通过生产者参数 buffer.memory 配置,默认为32MB。
若主线程发送消息的速度超过sender线程发送消息的速度,会导致消息累加器被填满,这时候再调用生产者客户端的send方法会被阻塞,若阻塞超过60秒(由参数max.block.ms控制),则会抛出异常 BufferExhaustedException 。
消息收集器RecoderAccumulator为每个分区都维护了一个Deque<ProducerBatch> 类型的双端队列。
ProducerBatch 可以理解为是 ProducerRecord 的集合,批量发送有利于提升吞吐量,降低网络影响。
主线程发送的数据由这样的结构保存:首先按照 Topic 进行划分,每个 Topic 会有一个 Map(key:Topic,value:TopicInfo);之后,按照分区进行划分,TopicInfo 里也有一个 Map(key:分区号,value:Deque<ProducerBatch>),每个双端队列会保存多个消息批次。当有消息发送时,会从对应 Topic 、对应分区的双端队列的尾部取出一个批次,判断是否可以将消息追加到后面。这种结构的目的在于:
- 使用字节将更加紧凑,节约空间
- 多个小的消息组成一个批次一起发送,减少网络请求次数提升吞吐量。因为 sender 线程发送消息的基本单位也是批次,它会从双端队列的头部取数据发送。
ProducerBatch 的大小与 batch.size 参数(默认16KB)密切相关。此外,Kafka 生产者使用 BufferPool 实现 ByteBuffer 从而实现对内存的复用。该缓存池只针对特定大小( batch.size指定)的 ByteBuffer进行管理,对于消息过大的缓存,不能做到重复利用。
消息累加器的基本结构如下图所示,红色+绿色区域总大小32MB,一个池中单位 ByteBuffer 大小16KB。
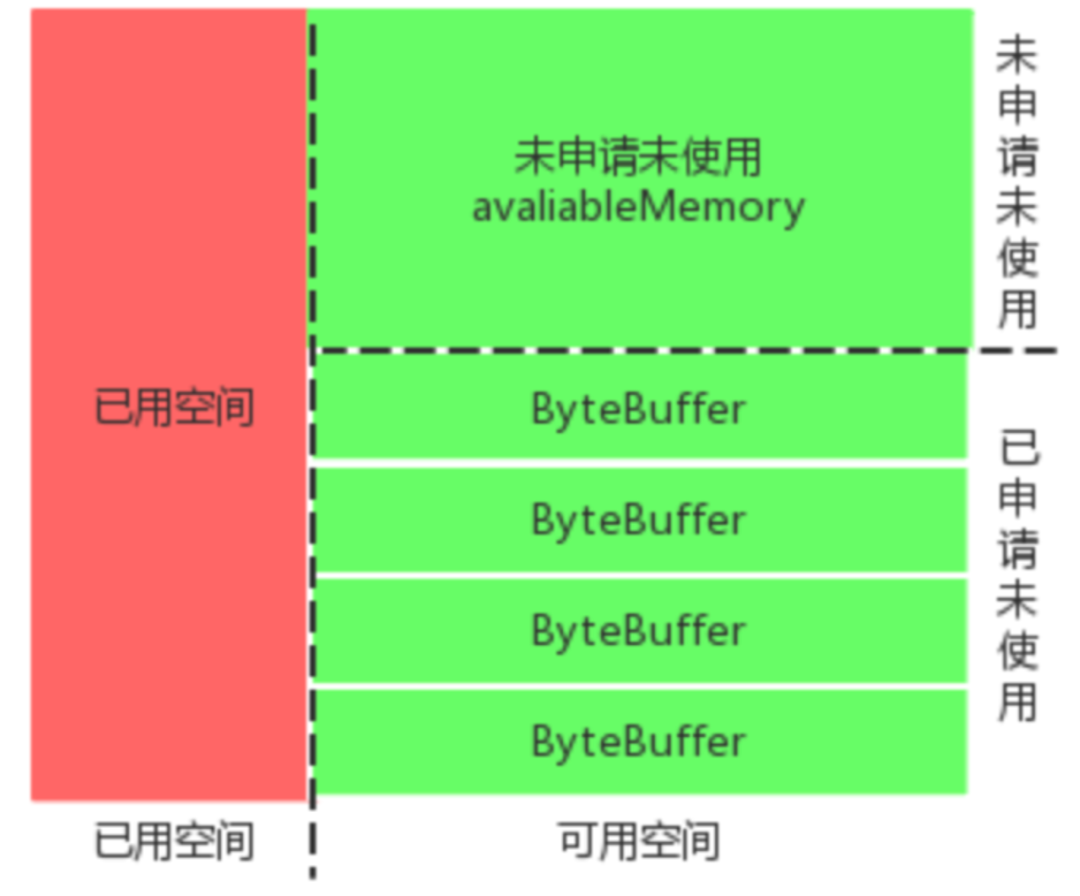
假设刚启动新插入一条消息,对应的 Topic 、对应的 Deque<ProducerBatch> 为空,这时执行allocate方法尝试开辟空间,方法主要过程如下:
- 如果申请空间的大小大于最大空间(
buffer.memory默认32MB),则直接抛出异常; - 操作缓存池之前尝试获取可重入锁,若获取的空间(size)正好等于每个批次预设大小(
batch.size默认16KB),则直接从Deque<ByteBuffer>中取出第一个 ByteBuffer 返回; - 若获取的空间(size)大于批次预设大小,计算剩余的空闲空间,即池中空闲空间+池外空闲空间(nonPooledAvailableMemory)。如果剩余的空闲空间大于size,则进行第4步;如果小于size,则进行第5步;
- 直接使用池外空闲空间分配,若不够再取池内空闲空间,最后返回。
- 将当前线程加入到等待队列(waiters)的尾部,如果等待超时也没有足够的空间,则抛出异常;若中途被唤醒,则进行下一步;
- 中途唤醒后有两种情况,当释放的空间正好等于一个批次大小且自己没有累计获得空间,则获取后返回;否则累计获取释放空间,满足后才会返回。
发送线程
sender 线程从消息累加器获取准备好可以发送消息(等待时候是否超过linger.ms参数设置的时间、或批次个数大于1或第一个批次已满)后,就可以准备消费消息了:
- 遍历每个 Topic 下的分区批次,根据分区 leader,将其处理为
<Node, List<ProducerBatch>的形式, Node 表示集群的broker节点。 - 进一步将
<Node, List<ProducerBatch>转化为<Node, Request>形式,此时才可以向服务端发送数据。 - 在发送之前,Sender线程将消息以
Map<NodeId, Deque<Request>>的形式保存到InFlightRequests中进行缓存,可以通过其获取 leastLoadedNode ,即当前Node中负载压力最小的一个,以实现消息的尽快发出。保存到InFlightRequests中的目的是缓存已经发出去但没收到响应的请求,NodeId 对应一个 broker 节点 id ,也就是一个连接,每个连接最多堆积的未完成请求为5个(max.in.flight.requests.per.connection参数配置)。
生产者参数
除了前面说过的必要的5个参数,如下:
bootstrap.servers:配置生产者如何与broker建立连接。该参数设置的是初始化参数。如果生产者需要连接的是Kafka集群,则这里配置集群中几个部分broker的地址,而不是全部,当生产者连接上此处指定的broker之后,在通过该连接发现集群中的其他节点。key.serializer:要发送信息的key数据的序列化类。设置的时候可以写类名,也可以使用该类的Class对象。value.serializer:要发送消息的value数据的序列化类。设置的时候可以写类名,也可以使用该类的Class对象。acks:默认值:all。- acks=0:生产者不等待broker对消息的确认,只要将消息放到缓冲区,就认为消息已经发送完成。该情形不能保证broker是否真的收到了消息,retries配置也不会生效。发送的消息的返回的消息偏移量永远是-1。
- acks=1:表示消息只需要写到主分区即可,然后就响应客户端,而不等待副本分区的确认。在该情形下,如果主分区收到消息确认之后就宕机了,而副本分区还没来得及同步该消息,则该消息丢失。
- acks=all:leader分区会等待所有的ISR副本分区确认记录。该处理保证了只要有一个ISR副本分区存活,消息就不会丢失。这是Kafka最强的可靠性保证,等效于 acks=-1。
retries:retries重试次数。当消息发送出现错误的时候,系统会重发消息。跟客户端收到错误时重发一样。如果设置了重试,还想保证消息的有序性,需要设置MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1,否则在重试此失败消息的时候,其他的消息可能发送成功了。
还有一些比较重要的参数:
-
client.id:生产者发送请求的时候传递给broker的id字符串。 用于在broker的请求日志中追踪什么应用发送了什么消息。 一般该id是跟业务有关的字符串。 -
retry.backoff.ms:在向一个指定的主题分区重发消息的时候,重试之间的等待时间。 比如3次重试,每次重试之后等待该时间长度,再接着重试。在一些失败的场 景,避免了密集循环的重新发送请求。 long型值,默认100。 -
request.timeout.ms:客户端等待请求响应的最大时长。如果服务端响应超时,则会重发请求,除非达到重试次数。该设置应该比 replica.lag.time.max.ms 要大,以免在服务器延迟时间内重发消息。int类型值,默认: 30000。 -
buffer.memory:生产者可以用来缓存等待发送到服务器的记录的总内存字节。如果记录的发送 速度超过了将记录发送到服务器的速度,则生产者将阻塞 max.block.ms 的时 间,此后它将引发异常。此设置应大致对应于生产者将使用的总内存,但并非 生产者使用的所有内存都用于缓冲。一些额外的内存将用于压缩(如果启用了 压缩)以及维护运行中的请求。long型数据。默认值:33554432。 -
batch.size:当多个消息发送到同一个分区的时候,生产者尝试将多个记录作为一个批来处理。批处理提高了客户端和服务器的处理效率。 该配置项以字节为单位控制默认批的大小。 所有的批小于等于该值。 发送给broker的请求将包含多个批次,每个分区一个,并包含可发送的数 据。如果该值设置的比较小,会限制吞吐量(设置为0会完全禁用批处理)。如果 设置的很大,又有一点浪费内存,因为Kafka会永远分配这么大的内存来参与 到消息的批整合中。 -
linger.ms:该配置设置了一个延迟,生产者不会立即将消息发送到broker,而是等待这么一段时间以累积消息,然 后将这段时间之内的消息作为一个批次发送。该设置是批处理的另一个上限: 一旦批消息达到了 batch.size 指定的值,消息批会立即发送,如果积累的消 息字节数达不到 batch.size 的值,可以设置该毫秒值,等待这么长时间之 后,也会发送消息批。该属性默认值是0(没有延迟)。如果设置 linger.ms=5 ,则在一个请求发送之前先等待5ms。long型值,默认:0。 -
max.request.size:单个请求的最大字节数。该设置会限制单个请求中消息批的消息个数,以免单 个请求发送太多的数据。服务器有自己的限制批大小的设置,与该配置可能不 一样。int类型值,默认1048576。 -
interceptor.classes:指定在生产者接收到该消息,向Kafka集群传输之前,由序列化器处理之前,配置的拦截器对消息进行处理。 -
partitioner.class:实现了接口 org.apache.kafka.clients.producer.Partitioner 的分区 器实现类,默认为DefaultPartitioner。 -
send.buffer.bytes:TCP发送数据的时候使用的缓冲区(SO_SNDBUF)大小。如果设置为0,则使 用操作系统默认的。 -
receive.buffer.bytes:TCP接收缓存(SO_RCVBUF),如果设置为-1,则使用操作系统默认的值。 int类型值,默认32768。 -
security.protocol:跟broker通信的协议:PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL。string类型值,默认:PLAINTEXT。 -
max.block.ms:控制 KafkaProducer.send() 和 KafkaProducer.partitionsFor() 阻塞的 时长。当缓存满了或元数据不可用的时候,这些方法阻塞。在用户提供的序列化器和分区器的阻塞时间不计入。long型值,默认:60000。 -
connections.max.idle.ms:当连接空闲时间达到这个值,就关闭连接。long型数据,默认:540000 -
max.in.flight.requests.per.connection:单个连接上未确认请求的最大数量。达到这个数量,客户端阻塞。如果该值大 于1,且存在失败的请求,在重试的时候消息顺序不能保证。 int类型值,默认5。 -
reconnect.backoff.max.ms:对于每个连续的连接失败,每台主机的退避将成倍增加,直至达到此最大值。 在计算退避增量之后,添加20%的随机抖动以避免连接风暴。 long型值,默认1000。 -
reconnect.backoff.ms:尝试重连指定主机的基础等待时间。避免了到该主机的密集重连。该退避时间 应用于该客户端到broker的所有连接。 long型值,默认50。 -
compression.type:生产者发送的所有数据的压缩方式。默认是none,也就是不压缩。 支持的值:none、gzip、snappy和lz4。 压缩是对于整个批来讲的,所以批处理的效率也会影响到压缩的比例。