程序描述:
输入: url链接 权威发布|2021软科中国大学专业排名||就业前景|就业率
输出: 排名信息的屏幕输出
技术路线:requests-bs4定向爬虫
如果信息没有写在代码中,则不能被用来定向,所以我们要检查以下源代码里面是不是有这些信息
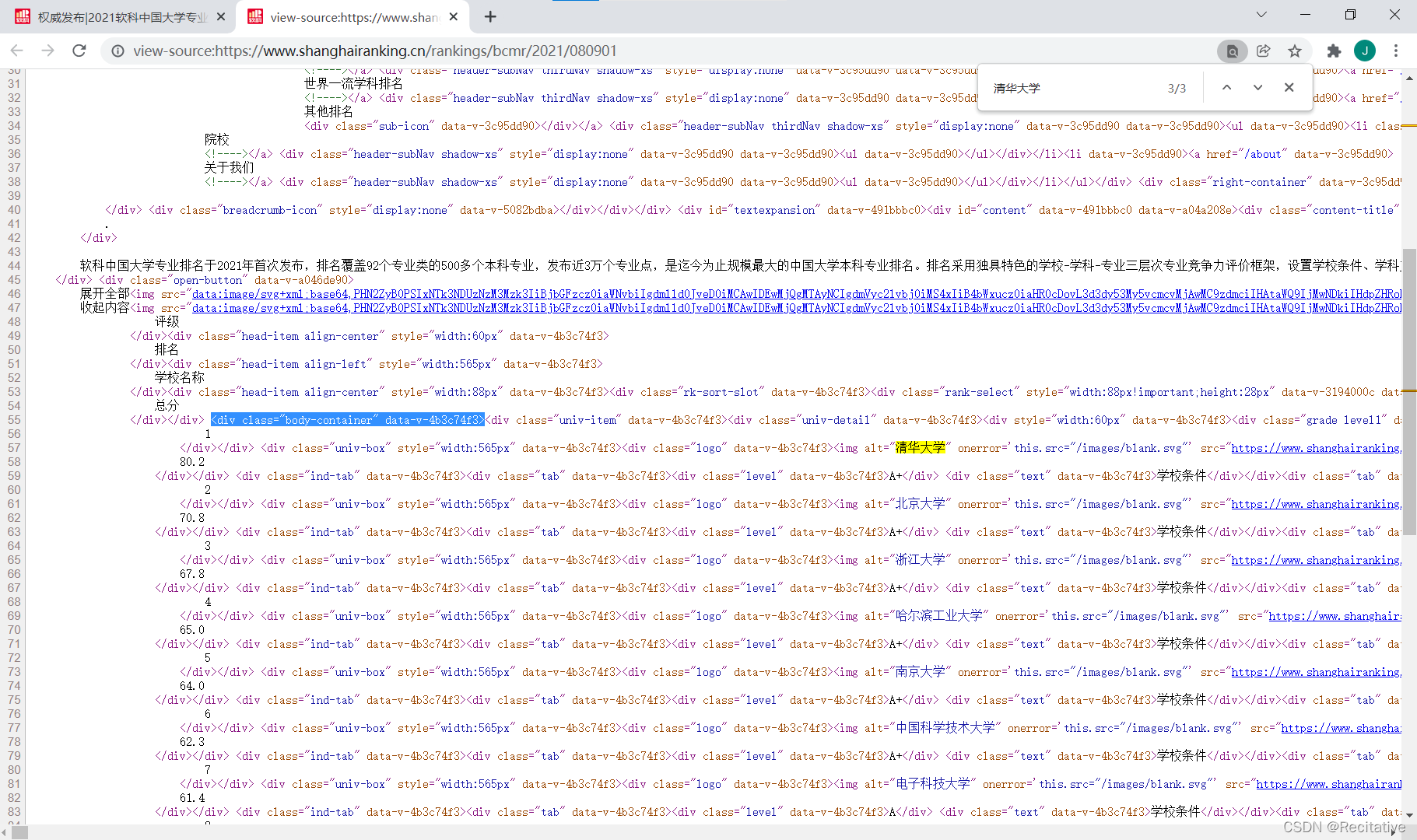
首先获取排名网页内容,getHTMLText()
提取信息到合适的数据结构,fillUnivList()
利用数据结构展示和输出,printUnivList()
首先它的格式
<div class="body-container" data-v-4b3c74f3>
<div class="univ-item" data-v-4b3c74f3="">
<div class="univ-detail" data-v-4b3c74f3="">
<div data-v-4b3c74f3="" style="width:60px">
<div class="grade level1" data-v-4b3c74f3="">
</div>
</div>
<div class="rank-box" data-v-4b3c74f3="" style="width:60px">
<div class="ranking" data-v-4b3c74f3="">
19
</div>
</div>
<div class="univ-box" data-v-4b3c74f3="" style="width:565px">
<div class="logo" data-v-4b3c74f3="">
<img alt="东南大学" class="univ-logo" data-v-4b3c74f3="" onerror='this.src="/images/blank.svg"' src="https://www.shanghairanking.cn/_uni/logo/82819451.png"/>
</div>
<div class="text-box" data-v-4b3c74f3="">
<div data-v-4b3c74f3="" data-v-b80b4d60="">
<div class="tooltip" data-v-b80b4d60="">
<div class="link-container" data-v-b80b4d60="">
<a class="name-cn" data-v-b80b4d60="" href="/institution/southeast-university">
东南大学
</a>
<div class="collection" data-v-b80b4d60="" style="display:none">
<img alt="" data-v-b80b4d60="" src="/_nuxt/img/uncollection.5e124aa.svg"/>
</div>
</div>
<!-- -->
</div>
</div>
<p class="tags" data-v-4b3c74f3="">
一流大学A类/985/211
</p>
</div>
</div>
<div class="region" data-v-4b3c74f3="" style="width:88px">
南京市
</div>
<div class="score" data-v-4b3c74f3="" style="width:73px">
55.5
</div>
</div>
<div class="ind-tab" data-v-4b3c74f3="">
<div class="tab" data-v-4b3c74f3="">
<div class="level" data-v-4b3c74f3="">
A+
</div>
<div class="text" data-v-4b3c74f3="">
学校条件
</div>
</div>
<div class="tab" data-v-4b3c74f3="">
<div class="level" data-v-4b3c74f3="">
B+
</div>
<div class="text" data-v-4b3c74f3="">
学科支撑
</div>
</div>
<div class="tab" data-v-4b3c74f3="">
<div class="level" data-v-4b3c74f3="">
A+
</div>
<div class="text" data-v-4b3c74f3="">
专业生源
</div>
</div>
<div class="tab" data-v-4b3c74f3="">
<div class="level" data-v-4b3c74f3="">
A+
</div>
<div class="text" data-v-4b3c74f3="">
专业就业
</div>
</div>
<div class="tab" data-v-4b3c74f3="">
<div class="level" data-v-4b3c74f3="">
A
</div>
<div class="text" data-v-4b3c74f3="">
专业条件
</div>
</div>
</div>
</div>
</div>所有大学的信息都在<div class="body-container" data-v-4b3c74f3>里面,
单个大学的信息封装在 <div class="univ-item" data-v-4b3c74f3="">里面,
其中,排名信息在 <div class="rank-box" data-v-4b3c74f3="" style="width:60px">中,
大学信息在 <div class="univ-box" data-v-4b3c74f3="" style="width:565px">中,
我们最后要打印的效果类似这样
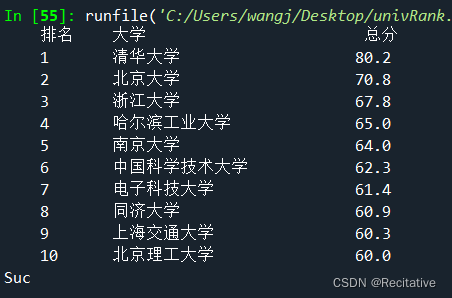
最终确定我们要筛选的为:
Tag = 'div', attrs = 'ranking'
Tag = 'a', attrs = 'name-cn'
Tag = 'div', attrs = 'score'
给出提取的代码
def fillUnivList(ulist,html): # 将提取的html信息放在列表ulist中
soup = BeautifulSoup(html, 'html.parser')
# print(soup.find('div',attrs = 'body-container').prettify())
# 这个print用于检查格式,确定层级
for div in soup.find_all('div',attrs = 'univ-item'):
# 从每个'univitem'中,提取NaviagbleString,并转换为合适的格式
ranking = int(div.find('div',attrs = 'ranking').string)
name = div.find('a',attrs = 'name-cn').string
score = float(div.find('div',attrs = 'score').string)
ulist.append([ranking,name,score])最后所有的代码如下
import requests
from bs4 import BeautifulSoup
def getHTMLText(url): # 获取URL信息,返回html内容
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "HTMLError"
def fillUnivList(ulist,html): # 将提取的html信息放在列表ulist中
soup = BeautifulSoup(html, 'html.parser')
print(soup.find('div',attrs = 'body-container').prettify())
for div in soup.find_all('div',attrs = 'univ-item'):
ranking = int(div.find('div',attrs = 'ranking').string)
name = div.find('a',attrs = 'name-cn').string
score = float(div.find('div',attrs = 'score').string)
ulist.append([ranking,name,score])
def printUnivList(ulist,num): # 将ulist打印
templete_string = "{0:^10}\t{1:{3}<12}\t{2:^10}\t"
# 中文字符utf-8编码空格为 chr(12288)
print(templete_string.format('排名','大学','总分',chr(12288)))
for i in range(num):
univ = ulist[i]
print(templete_string.format(univ[0],univ[1],univ[2], chr(12288)))
print("Suc")
def main():
uinfo = []
url = 'https://www.shanghairanking.cn/rankings/bcmr/2021/080901'
html = getHTMLText(url)
fillUnivList(uinfo, html)
# print(uinfo)
printUnivList(uinfo, 10) # only 10 univ
main()