python作品 运动模糊图像修复算法(上)-CSDN博客
python作品 运动模糊图像修复算法(下)-CSDN博客
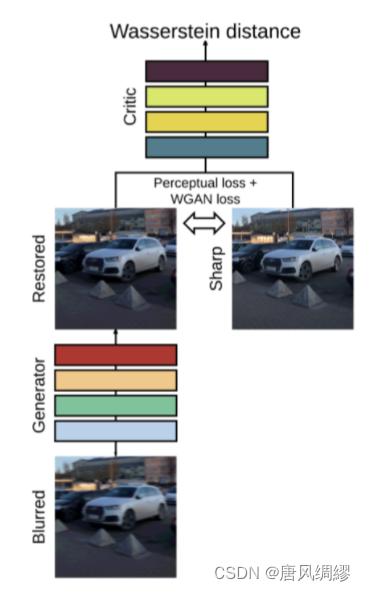
4.1 WGAN和WGAN-GP模型实现
我们选取了基于GAN的WGAN模型。生成器模型是使用残差结构来实现的。其模型的层次结构顺序如下:
(1)通过1层卷积核为7×7、步长为1的卷积变换。保持输入数据的尺寸不变。
(2)将第(1)步的结果进行两次卷积核为3 ×3、步长为2的卷积操作,实现两次下采样效果。
(3)经过5层残差块。其中,残差块是中间带有Dropout层的两次卷积操作。
(4)仿照(1)和(2)步的逆操作,进行两次上采样,再来一个卷积操作。
(5)将(1)的输入与(4)的输出加在一起,完成一次残差操作。
该结构使用“先下采样,后上采样”的卷积处理方式,这种方式可以表现出样本分布中更好的潜在特征。
除了上述生成器外,在训练过程中,还定义了一个判别器(该判别器架构类似于PatchGAN),采用带梯度惩罚项的Wasserstein GAN进行对抗训练。
判别器模型的结构相对比较简单。
(1)通过4次下采样卷积,将输入数据的尺寸变小。
(2)经过两次尺寸不变的1×1卷积,将通道压缩。
(3)经过两层全连接网络,生成判别结果(0还是1)。
WGAN解决的是GAN生成不稳定的问题,但是WGAN在真实的实验过程中依旧存在着训练困难、收敛速度慢的问题。原因是WGAN在处理Lipschitz限制条件时直接采用了weight clipping(减重)因为判别器是一个多层网络,weight clipping很容易会导致梯度消失,如果把clipping threshold(削减阈值)设得稍小,每经过一层网络,梯度就变小一点点,多层之后就会指数衰减;反之,如果设得稍大,多层之后就会指数爆炸。
4.2 python作品 运动模糊图像修复算法(上)-CSDN博客对WGAN的改进:
所以我们对原有的WGAN算法程序进行改进,将WGAN-GP与原有的WGAN算法程序进行整合。WGAN-GP解决了WGAN的问题,而且相比WGAN还缩短了训练时间和预测时间。
4.2.1 改进损失函数

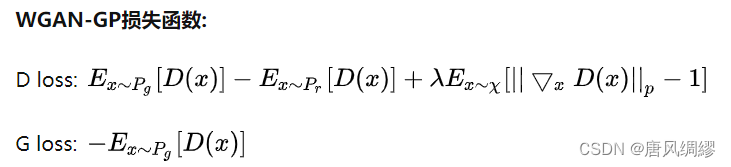
4.2.2 设置一个参数:gradient penalty(梯度惩罚函数)
Lipschitz限制是要求判别器的梯度不超过K,gradient penalty 设置一个额外的loss项来实现梯度与K之间的联系。
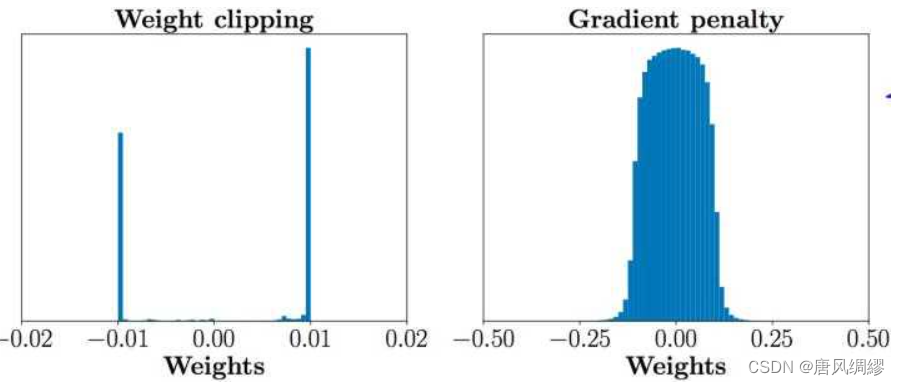
4.3 数据处理
由于在实际中,很难找到一张与模糊图像相对应的清晰图像,而本实验所用的生成对抗网络方法需要清晰图像驱动训练,因此我们需要大量的清晰-模糊图像对作为实验的样本数据。为了得到清晰-模糊图像对,我们按照运动模糊进行实验仿真。
4.3.1 直线模糊数据集
开始阶段,我们用MATLAB程序对图像进行预处理[7]。我们选用公开汽车图片MIT Cars dataset数据集,该数据集包含了516张大小为128*128像素的汽车静态图片。我们通过改变函数参数,生成不同模糊方向、大小的模糊图像,令实验实施更全面。
但这个方法存在缺陷——只能形成直线方向的模糊,无法形成曲线运动模糊的图像。假设相机机位固定,拍摄直线运动的车辆形成的运动模糊,这种模糊属于直线运动模糊,这种情况用该种数据集会有很好的效果。但对于曲线运动的物体,如风车转动、相机拍摄是本身发生曲线运动时,该数据集并不能训练出适应这种曲线运动模糊的情况。

4.3.2 随机轨迹模糊数据集
最终,我们采用了基于随机轨迹的模糊图像生成方法,该方法能够在清晰图像数据集的基础上批量、自动地生成多样化运动模糊的图像数据集。
这种方法遵循 Borac-chi 和 Foi 描述的随机轨迹生成[2]的想法,通过将子像素插值应用于轨迹矢量来生成核。每个轨迹矢量是复值矢量,其对应于在连续域中的2D随机运动之后的对象的离散位置。轨迹生成是通过马尔可夫过程完成的。轨迹的下一个点的位置是基于先前的点速度和位置、高斯扰动、脉冲扰动和确定性惯性分量随机生成的。

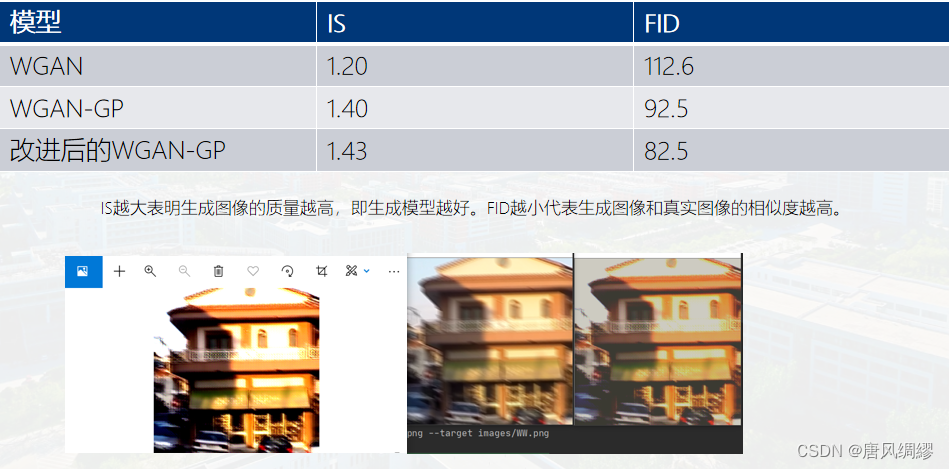
我们将处理之后的模糊图像与真实图像组合成图像对,模型就输入的模糊图像进行处理生成去模糊图像,去模糊图像会结合清晰图像进行计算,得到损失函数。
对比上一个数据集,这个数据集更接近现实生活的情况,训练后的效果也要好很多。
- 基于NOGAN的旧照片修复技术
基本思路如下:
(1)首先以传统方式自行训练生成器,仅使用特征损失(feature loss)。
(2)从中生成图像,并训练critic区分这些输出和真实图像作为基本的二元分类器。
(3)在 GAN设置中一起训练生成器和critic(在这种情况下从目标大小192像素开始)。
这里所有有用的GAN训练只发生在一个非常小的时间窗口内。
有一个转折点,critic似乎已经把所有有用的东西都转移到了生成器上。
在这一点之后,图像质量在你能得到的最好的拐点和糟糕的可预测的方式之间摇摆(橙色皮肤、过度红唇等)。
在拐点之后似乎没有有效的训练。
而这一点在于仅对Imagenet数据的1%到3%进行训练。这相当于在192px下进行大约 30-60分钟的训练。
NOGAN方法的性能对比与分析:基于深度学习的图像着色方法. 从大规模的彩色图像学习颜色规律, 然后将其应用在目标 图像中以达到彩色化效果. 有一篇名为的论文通过学习图像的语义相似性来预测用户行为, 从而在用户可控的情况下减少工作量, 但在使用颜色点进行着 色时也会存在误着色. 另一篇名为的论文将带有颜色线条的草图输入生成对抗网络, 使用编码器和解码器网络结构对图像进行特征提取和上采样操作, 使用像素级 L1 距离损失保持着色图像与颜色标记的一致性。名为的文章改进传统的生成对抗网络 (generative adversarial networks, GAN), 用真实图像代替随机噪声输入, 利用U-Net 提取图像特征信息, 使用L1距离损失和 PatchGAN产生更加接近于真实图像的着色结果.该方法克服了需要人为干预的缺点, 但图像的着色效果受图像类别影响较大, 对不在训练样本类别中的图像着色效果不理想。提出将深度学习和参考图像结合的图像着色方法, 对目标图像结构一致的参考图像直接进行颜色迁移, 从大规模的数据中学习颜色对目标图像进行着色, 提高了着色可控性。
我们根据论文以及一些调研,采用了一种名为NOGAN的模型,使用U-Net体系结构对GAN的生成器进行训练,这样,在训练完整的GAN架构之前,模型已经很擅长为图像着色了。然后,只需要少量的这种典型的生成器-识别器GAN训练,以优化生成的图片的“真实性”,NoGAN就能提供与通常的GAN训练相同的好处。但却花费了更少的时间来训练GAN架构。对生成器进行了预先训练,使其利用常规损失函数变得更强大、更快、更可靠。
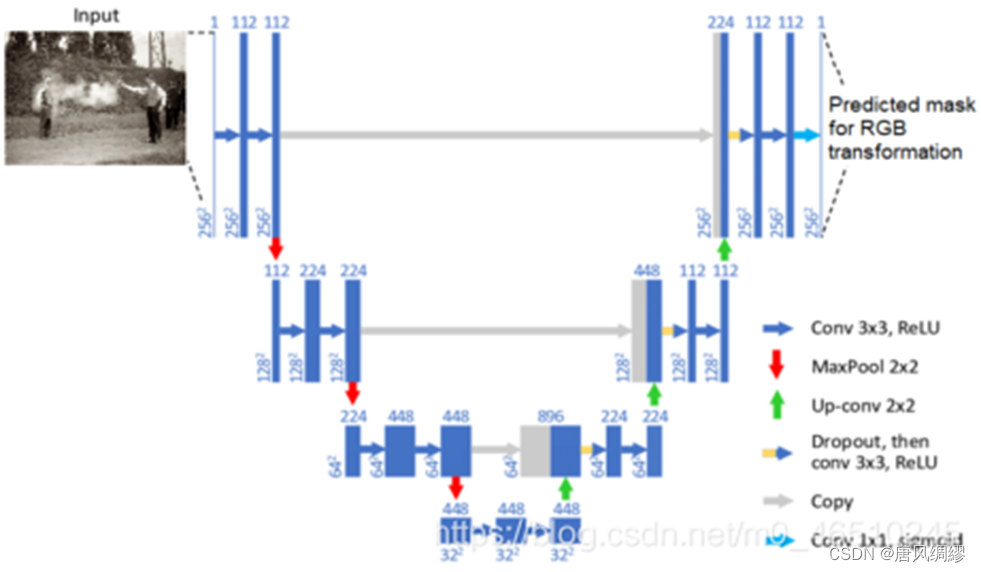
- 基于U2NET的图片背景更换技术
照片更换背景,证件照一键换底更换背景颜色一直都是图像处理的重要应用,但是很多模型的处理效果并不是很好,使用的是U2-NET模型,U2Net是一个两级的嵌入U型网络结构,这是一种新型的网络结构不需要进行预训练,从头训练可以得到很好的结果。而且,这种网络结构实现了在网络层数加深的 同时能够保持较高的分辨率。
优点:
1.利用来自残差U型模块(RSU)的不同尺度不同感受野的混合,能够捕捉来自更多的不同尺度的上下文信息(全局信息)
2.采用RSU中的池化操作,U2Net在不增加计算复杂度的基础上,可以提升整个模型架构的深度。
3.使用这种结构可以从头训练网络而不依赖于图像分类的算法网络
U2net分成了多个block,每个block输出一个loss,那么最后整个模型的loss就是这样的,损失函数如下:
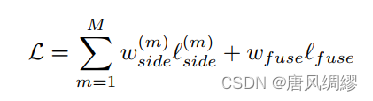
loss计算方法采用的是:standard binary cross-entropy(如下式,即:二值交叉熵)
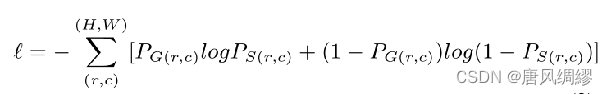
该模型的网络架构如图所示: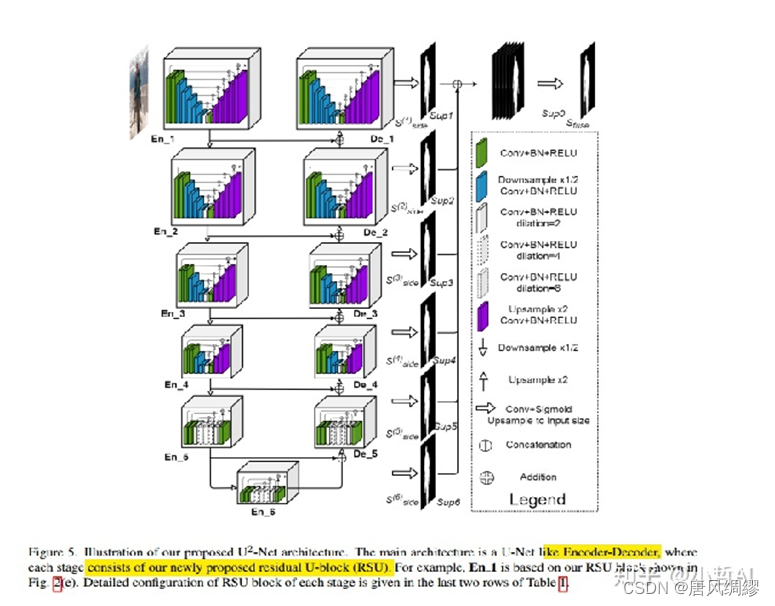
系统和实验数据展示
这部分为系统应用功能的前端展示和前后端交互的设计,使用了flask搭建网站,前端使用html+css+js设计,后端使用python完成与前端数据的互通,后端接收前端的数据并分析处理数据,将结果返回前端展示。
flask后端进行了精心严密的设计,使得用户必须严格按照‘登录后才能使用本系统图像处理功能’的规定使用本网站,并且直接在浏览器搜索框中输入某些不符合本网站逻辑规定的网址,会被重定向到经判断处理后的合理网页,比如登录前输入含有用户名的路由“http://127.0.0.1:5000/245312445x”会跳转至原始主页,已有用户登录而这样输入,若当前用户(2453124455)与路由中的用户名不一致,则会跳转至用户主页。
以下主要介绍前端功能的设计和使用。
4.1 系统主页的设计实现
参考了某个主页模板,主页右上角有登录注册的进入系统,注册登录后才可以使用本系统的主体功能,登录后会在右上角显示个人账号(点击此处能弹出的“退出登录”可以退出登陆返回原始主页),网页路由变为以用户账号为起始路由,用以区分不同用户,主体功能页面均以此为路由前缀。
主页登录前后图片对比如下:
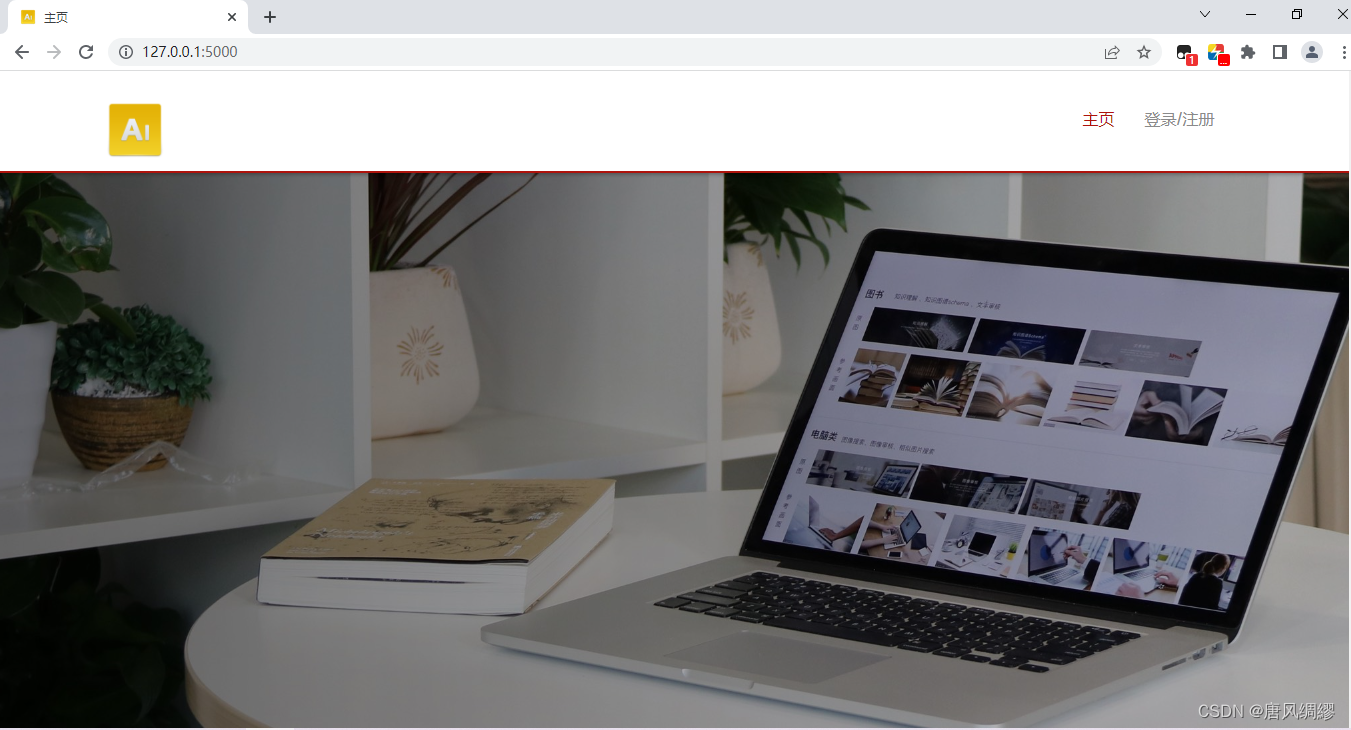

左上角以及网页标题的图标都设计为“AI”,符合我们系统的主题,中间部分是三张轮回播放的插图。
下半部分是图像处理系统的四个功能的进入页面,均需登录后使用,否则跳转至登录界面,每部分功能有贴图展示和功能文字介绍。
最底部三块分别是我们项目的大体介绍,常见问题的解答,我们项目涉及算法的研究现状。

4.2 登录注册功能的实现
这部分有三个功能,分别是登录、注册、找回密码,这三部分可以相互跳转,均可以返回主页;该部分使用了mysql数据库存储用户数据,借助了SQLAlchemy数据库管理模块方便操作数据库。

登录需要正确填写用户名和密码,登录成功会跳转至登录后的主页,否则报用户名或密码错误的提示。

注册需要输入用户名和密码,以及确认密码,获取验证码然后填写验证码,逻辑判断为所有项都要填写,用户名为QQ号,用户名不能已在数据库中存在,密码必须为6-18位的包含数字、字母、特殊字符在内的每种至少一个的字符串,密码和确认密码填写的内容必须一致,注册前需要先获取验证码,验证码会发到与用户名对应的QQ邮箱,要保证QQ邮箱可以使用,这样才能收到验证码,填写正确的验证码完成注册,跳转登录页面,同时在数据库中存储新增用户的信息,否则会报相对应错误的提示。

同时可以找回密码或者说是修改密码,设计和逻辑判断与注册页面大体一致,只是将密码填写项改为了新密码,判断逻辑改为用户名必须已存在于数据库,成功更改
后会跳转登录,同时在数据库中更新该用户的密码信息。
4.3 图像处理系统的实现
这部分分为图像处理的四个功能,也是系统应用的主体部分。
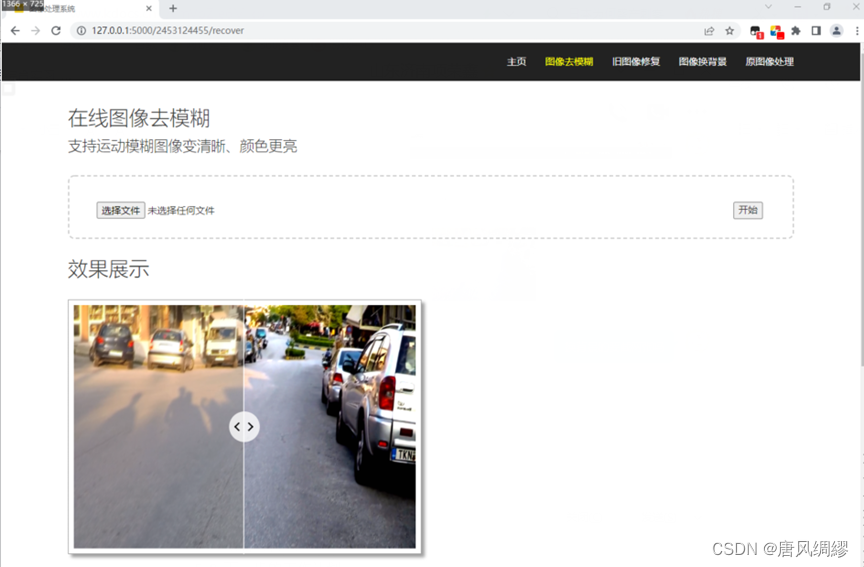
第一个功能是图像去模糊,基于wgan、wgan-gp,我们改进了这两种算法,应用到我们的功能预测上,处理运动中拍摄的模糊图片将其变清晰、色彩更明亮。
使用过程为从本地选择文件上传作为原图片,上传的文件必须符合主要的图片类型比如png、jpg、jpeg等等。

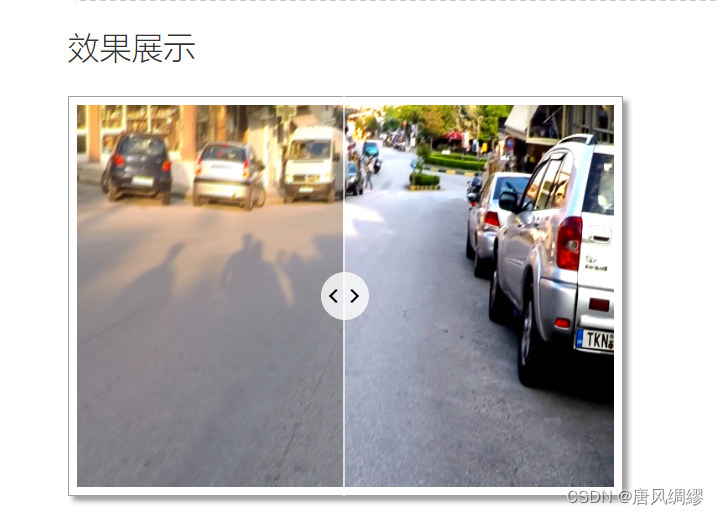
然后点击开始按钮开启预测(不预先上传图片无法生成结果图,其余功能同理),会在下方的效果展示栏同时展示原图片和预测去模糊后的图片,图片中间有滑动部件可以移动,用来展示不同区域大小的原图和结果图。
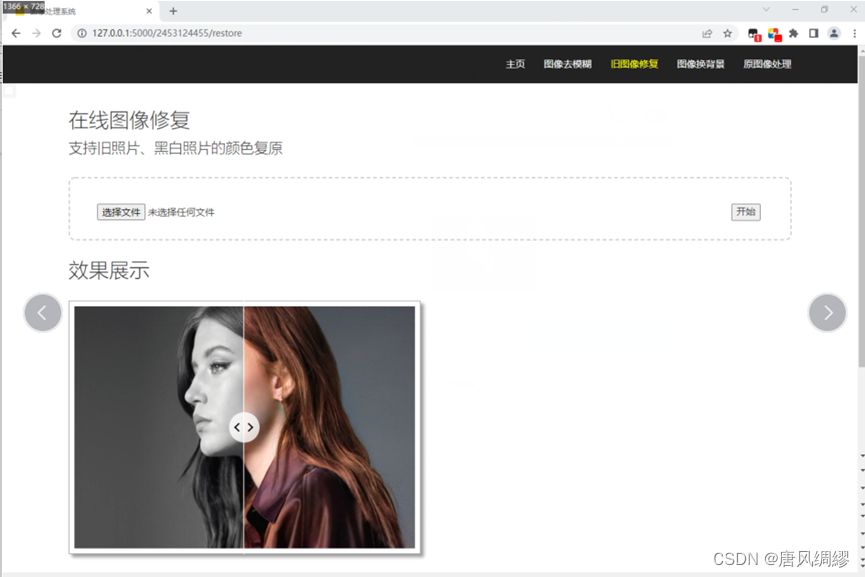
第二个功能是旧图像修复,基于no-gan,处理旧照片和老照片即RGB值偏黑色的图片将其变为彩色图片,使用方法和效果展示同第一个功能图像去模糊。
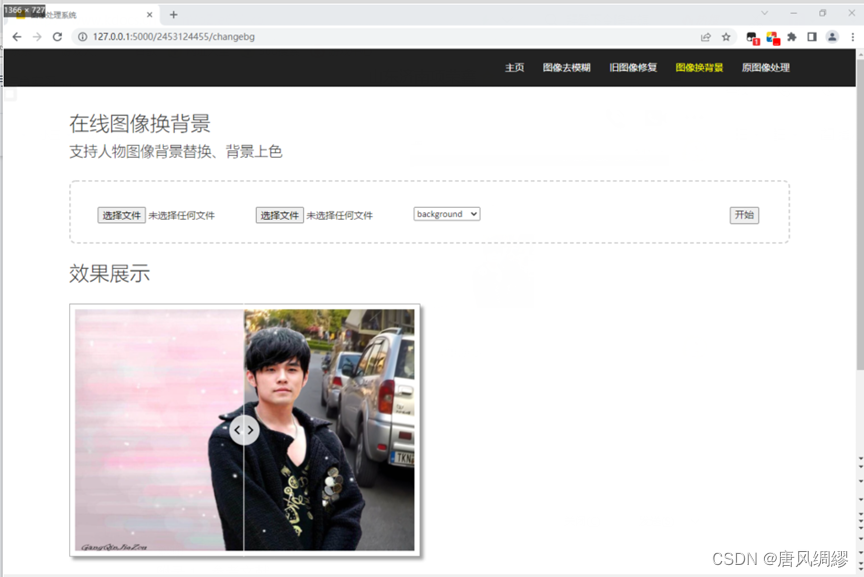
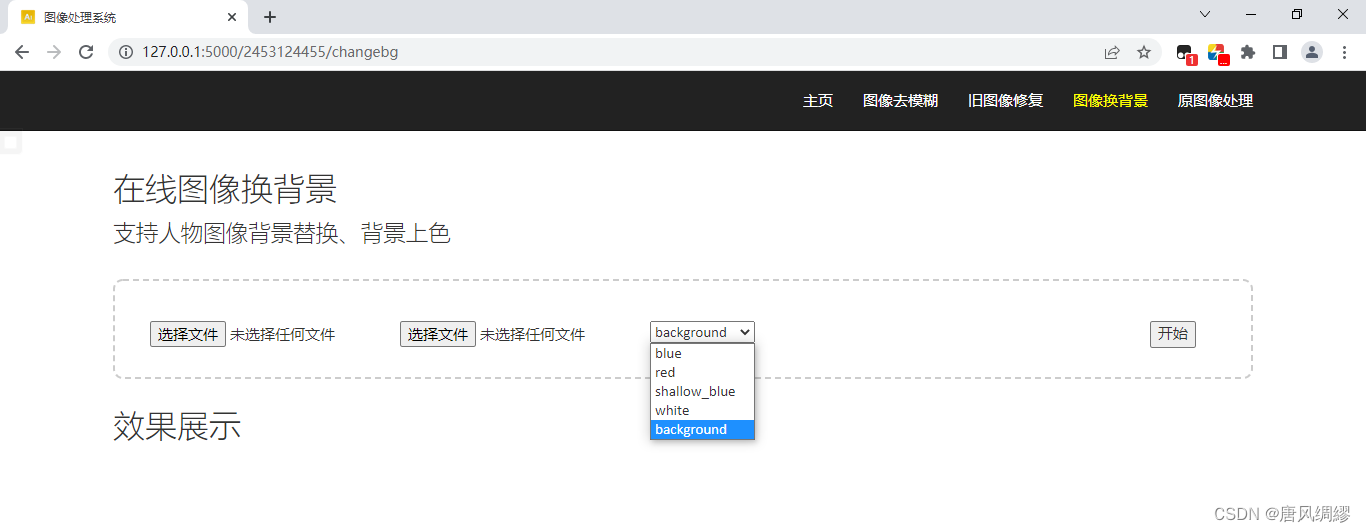
第三个功能是图像换背景,基于U2-Net,处理含有人像的图片,提取其中的人像部分,赋予不同RGB值用以区分图片其它部分的背景,生成人像模板图片。
然后根据模板图片,保留原图中人像部分的色彩RGB,而背景部分用选定的颜色或背景图中对应位置的色彩RGB值填充,生成最终的结果图。
使用过程是第一个选择文件是上传原图,第二个为上传背景图,第三个选择框可以选择四种颜色背景和自定义背景图,选择颜色作为背景不必上传背景图,选择“background”必须上传背景图,点击开始后出现相应效果展示。
第四个功能是图像的旋转和亮度调节功能,借助Python的PIL库对图像进行一些基本处理。
使用过程为第一个按钮为上传原图,第二个选择框可以选择不操作或选择五种不同的图片旋转方式,第三个输入框输入预期相对于原图的亮度,输入的亮度必须为介于0.2-100的数值,这个范围之外的数值亮度调节效果不佳,0-1是将图片调暗,大于1是将图片调亮,1相当于亮度不改变;并且每次点击开始、生成效果图前应当保证结果图与原图有变化,即选择框和输入框不能同时为‘不操作’和‘1’,否则不予处理。
第五章 系统测试
QT界面测试: