【学习笔记】【Pytorch】七、卷积层
学习地址
主要内容
一、卷积操作示例
二、functional.conv2d函数的使用
作用:对几个输入平面组成的输入信号应用2D卷积。
三、torch.Tensor与torch.tensor区别
作用:图片尺寸缩放。
四、nn.Conv2d类的使用
作用:二维卷积层, 输入的尺度是(N, C_in,H,W),输出尺度(N,C_out,H_out,W_out)。
五、卷积公式
一、卷积操作示例
动图演示
博客:RGB彩图卷积过程(易懂)
深度学习基础知识-----多通道卷积计算
注:
- 卷积核的大小是自己设置的,初始参数是自定义的,卷积核上每个位置相当于一个权重w,比如一个3*3的卷积核,就是9个w,训练网络的目的就是学习这9个权值。
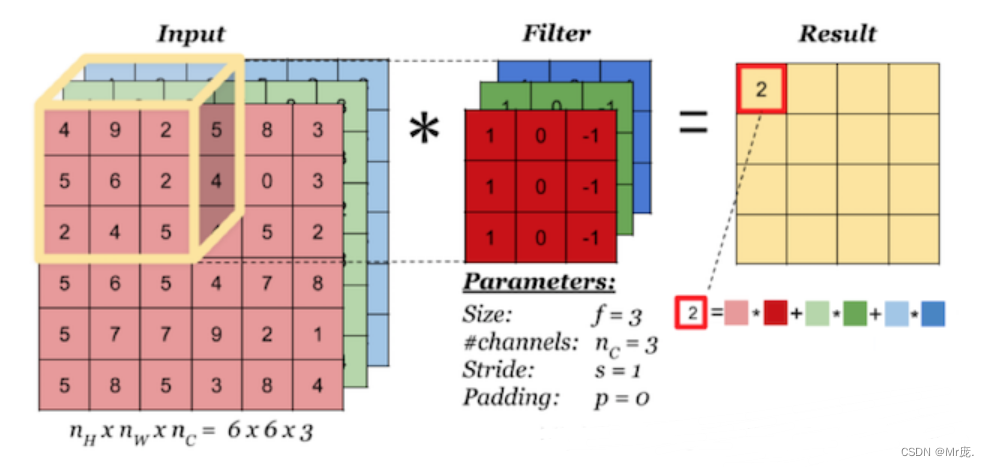
- 以彩色RGB三通道图像为例:
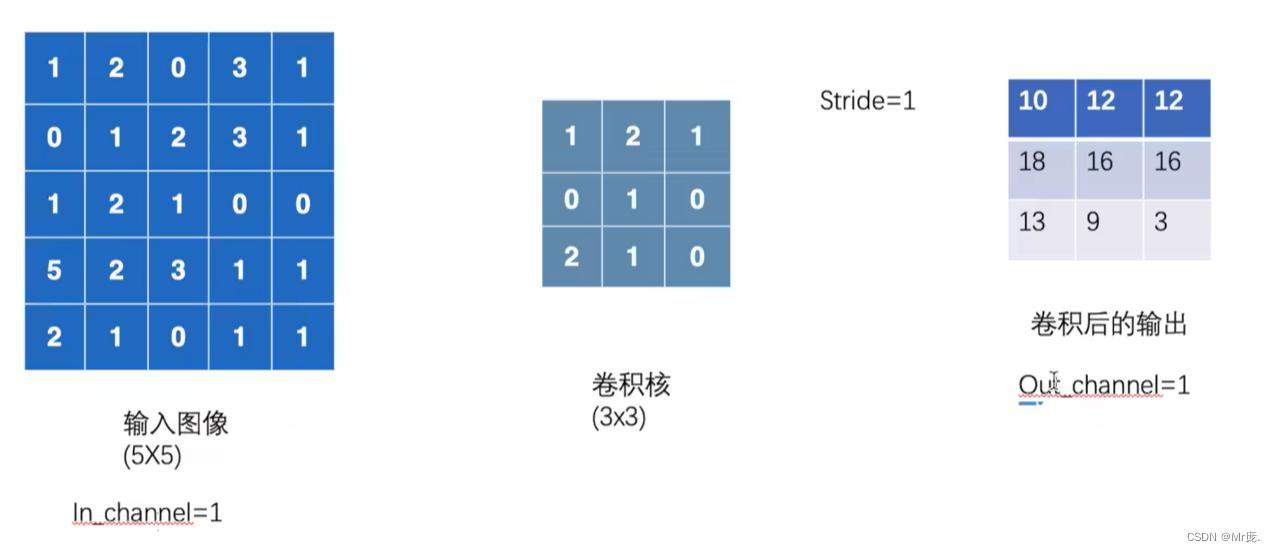
1.一个卷积核(一个Filter)的计算
输入层与卷积核,需要有相同的channel数(即卷积核的通道数和卷积核个数是不同概念,不同通道的卷积核也不一样);
输入层的每个channel 与卷积核对应的channel 进行卷积计算,然后每个 channel 的卷积结果按位相加得到最终的特征图。
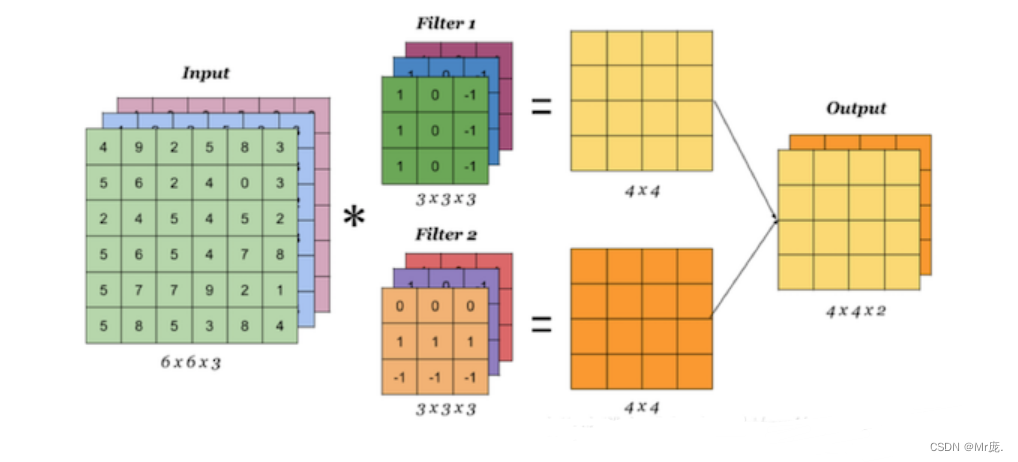
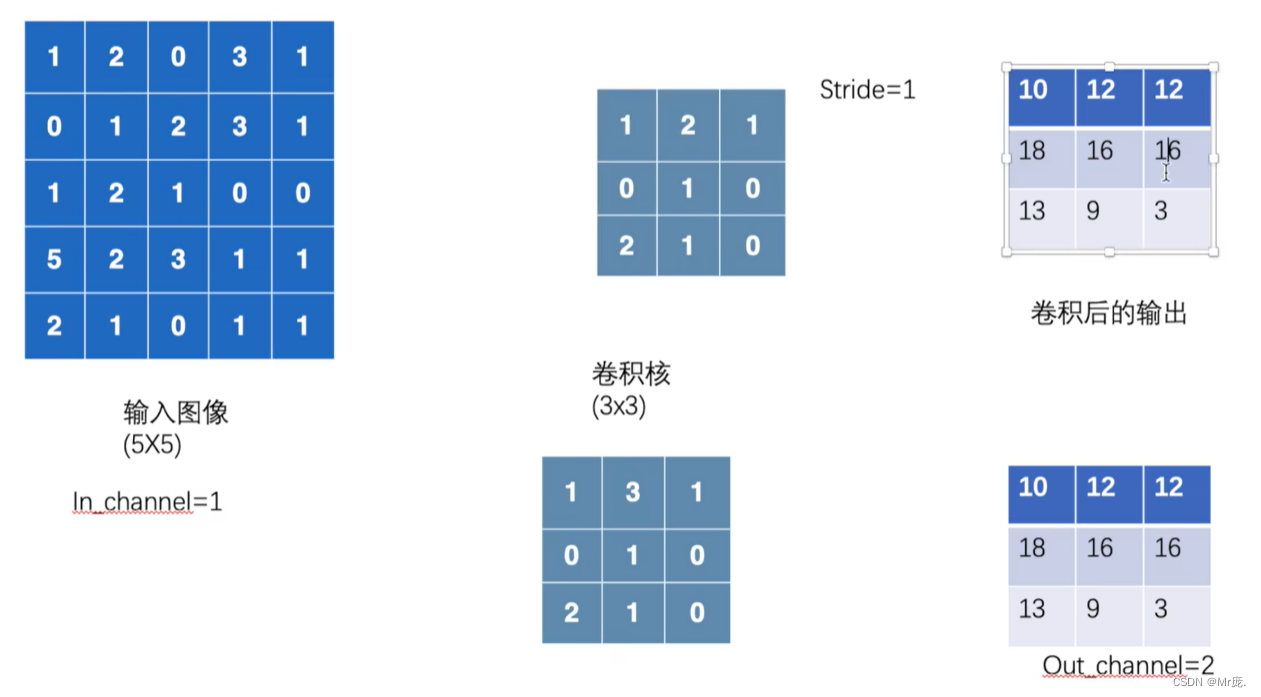
2.多卷积核(多个Filter)的计算(下图以2个Filter为例)
当有多个卷积核时,可以学习到多种不同的特征,对应产生包含多个 channel 的 Feature Map。
卷积层设置2个 filter,输出Feature Map就有两个 channel;
卷积核也可理解为神经元;卷积核内的参数就是权重。
二、functional.conv2d函数的使用
import torch.nn.functional as F
1.使用说明
【实例化】torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
- 作用:对几个输入平面组成的输入信号应用2D卷积。
- input: 输入张量, (minibatch, in_channels, iH, iW),即tensor_data.shape 应该有四个参数。
- minibatch -即batch_size,每个batch(批次)要加载多少个样本
- in_channels - 输入通道数
- iH、iW - 数据形状
- weight – 卷积核(过滤器)张量 ,(out_channels, in_channels/groups 整除, kH, kW) ,即tensor_data.shape 应该有四个参数。
- bias – 可选偏置张量 (out_channels)
- stride – 卷积核的步长,左移和下移的步长,可以是单个数字或一个元组 (sh x sw)。默认为1。
- padding – 输入上隐含零填充。可以是单个数字或元组。 默认值:0。
- dilation – 核元素之间的间距。默认值:1。
- groups – 将输入分成组,in_channels应该被组数除尽。默认值:1。
2.代码实现
import torch
import torch.nn.functional as F
# 二维张量
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# 3*3的卷积核,二维张量
kernel =torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
# 转化为四维张量,batch_size(数据个数)的大小为1,,通道数是1,数据维度是5*5
input = torch.reshape(input, (1, 1, 5, 5))
# 转化为四维张量,batch_size(数据个数)的大小为1,,通道数是1,数据维度是5*5
kernel = torch.reshape(kernel, (1, 1, 3, 3))
# print(input.shape) == print(input.size())
print(input.shape) # torch.Size([1, 1, 5, 5])
print(kernel.size()) # torch.Size([1, 1, 3, 3])
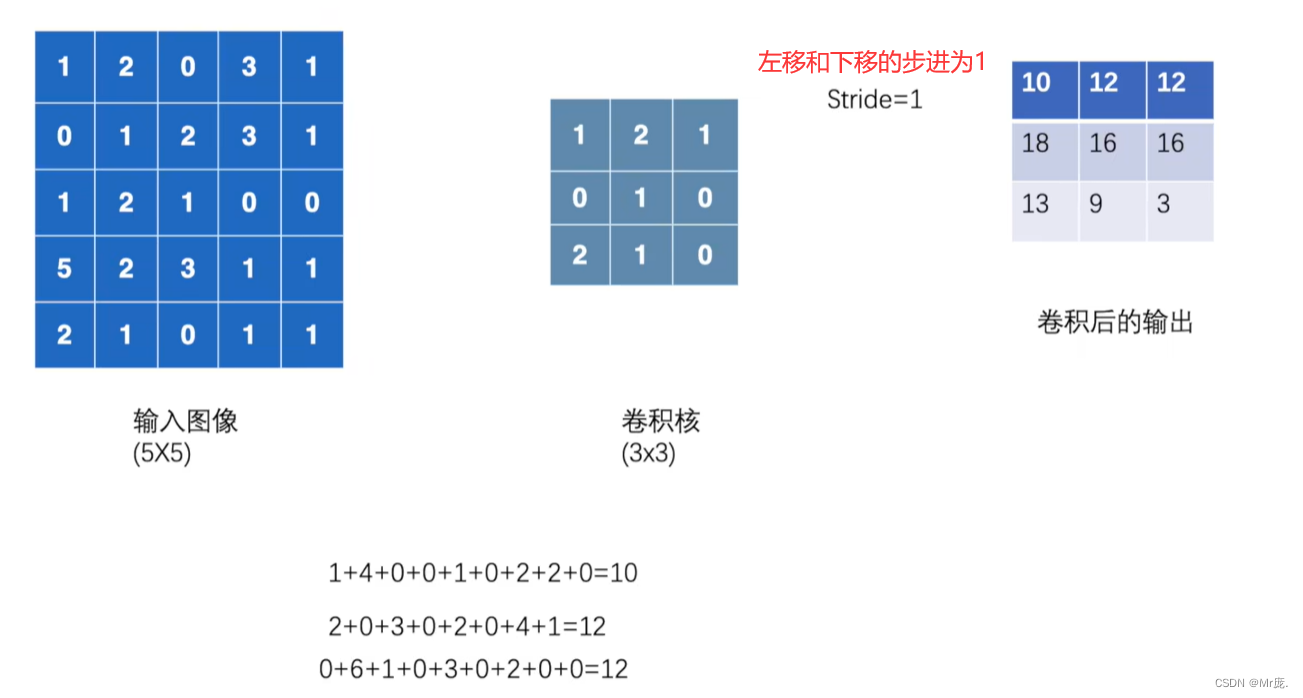
# 上下步进为1的卷积操作
output = F.conv2d(input, kernel, stride=1)
print('\n', output) # 四维张量
# 上下步进为2的卷积操作
output = F.conv2d(input, kernel, stride=2)
print('\n', output) # 四维张量
# 上下步进为1、启用 1层0填充卷积
output = F.conv2d(input, kernel, stride=1, padding=1)
print('\n', output) # 四维张量
控制台输出:
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
tensor([[[[10, 12],
[13, 3]]]])
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
总结:
将二维张量转化为四维张量才能满足torch.nn.functional.conv2d函数的输入要求,转化结果也就是添加了两个[ ]。
三、torch.Tensor与torch.tensor区别
参考:
torch.Tensor()与torch.tensor()
总结:
-
torch.Tensor()是python类,调用torch.Tensor([1,2, 3, 4, 5])来构造一个tensor的时候,会调用Tensor类的构造函数,生成一个单精度浮点类型的张量。它不能指定数据类型,除非转成一个已知数据类型的张量,使用type_as(tesnor)将张量转换为给定类型的张量。
-
torch.tensor()是python的函数,其中data可以是list,tuple,NumPy,ndarray等其他类型,torch.tensor(data)会从data中的数据部分做拷贝(而不是直接引用),根据原始数据类型生成相应的torch.LongTensor torch.FloatTensor和torch.DoubleTensor。通过设置dtype的函数参数值,生成对应类型的张量。
四、nn.Conv2d类的使用
from torch.nn import Conv2d

作用:二维卷积层, 输入的尺度是(N, C_in,H,W),输出尺度(N,C_out,H_out,W_out)。
1.使用说明
【实例化】Conv2d(
in_channels: int,
out_channels: int,
kernel_size: _size_2_t,
stride: _size_2_t = 1,
padding: Union[str, _size_2_t] = 0,
dilation: _size_2_t = 1,
groups: int = 1,
bias: bool = True,
padding_mode: str = ‘zeros’, # TODO: refine this type
device=None,
dtype=None
)
- 作用:创建一个二维卷积层,的实例,卷积核初始参数随机初始化。
- in_channels(int) – 输入信号的通道
out_channels(int) – 卷积产生的通道
kerner_size(int or tuple) - 卷积核的尺寸
stride(int or tuple, optional) - 卷积步长
padding(int or tuple, optional) - 输入的每一条边补充0的层数
dilation(int or tuple, optional) – 卷积核元素之间的间距
groups(int, optional) – 从输入通道到输出通道的阻塞连接数
bias(bool, optional) - 如果bias=True,添加偏置 - 例子:
# 用conv1变量存储一个 Conv2d 实例
# in_channels表示3通道图片数据
# out_channels表示输出通道数(这里3通道变6通道,一般是2个卷积核进行卷积得到的)
conv1 = Conv2d(in_channels=3, out_channels=6,
kernel_size=3, stride=1, padding=0)
- 注:in_channels,彩色就是3,灰度就是1。
【_call_】conv1(x)
例子:
def forward(self, x):
x = self.conv1(x)
return x
2.代码实现
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class Model(nn.Module):
def __init__(self):
super().__init__() # 父类参数初始化
# 用conv1变量存储一个 Conv2d 实例
# in_channels表示3通道图片数据
# out_channels表示输出通道数(这里3通道变6通道,一般是2个卷积核进行卷积得到的)
self.conv1 = Conv2d(in_channels=3, out_channels=6,
kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
dataset = torchvision.datasets.CIFAR10(root="./dataset", train=False,
transform=torchvision.transforms.ToTensor(),
download=True) # 创建一个 CIFAR10 实例
dataloader = DataLoader(dataset=dataset, batch_size=64) # 创建一个 DataLoader 实例
nn_model = Model() # 创建一个 Model 实例
# print(model)
# Model((conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1)))
writer = SummaryWriter("./dataloader_logs") # 创建一个SummaryWriter实例
step = 0
for data in dataloader:
imgs, targets = data
output = nn_model(imgs)
print(imgs.size())
# torch.Size([64, 3, 32, 32]) batch_size=64,in_channels=3,图片尺寸
print(output.shape)
# torch.Size([64, 6, 30, 30]) batch_size=64,out_channels=6,图片尺寸
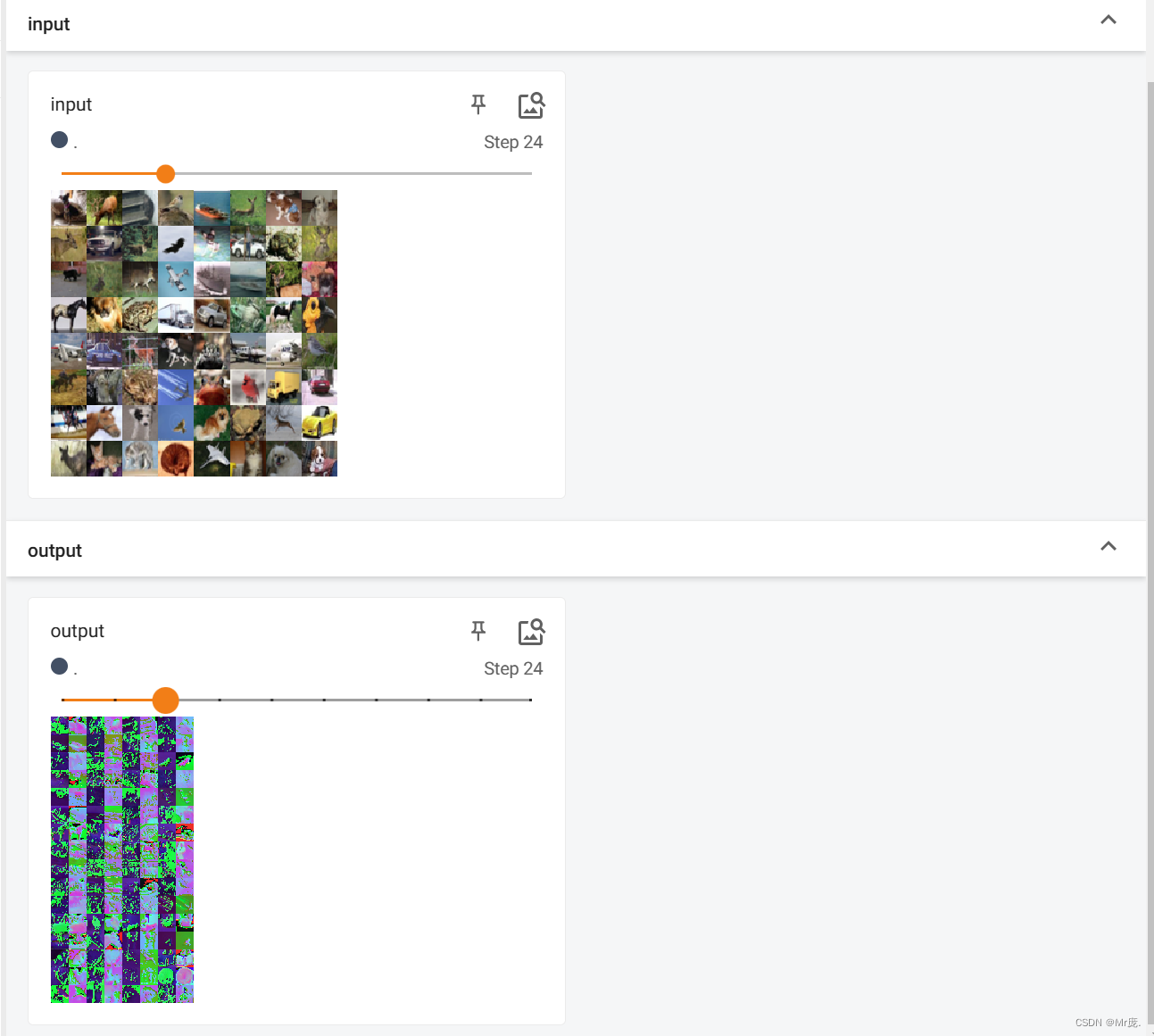
writer.add_images("input", imgs, step)
# 卷积后通道可能会变,因为不能显示6通道的图片,所以使用reshape()转化为3通道图片,-1表示自动设置batch_size
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step += 1
# tensorboard命令:tensorboard --logdir=dataloader_logs --port=6007
输出:
Files already downloaded and verified
torch.Size([64, 3, 32, 32])
torch.Size([64, 6, 30, 30])
torch.Size([64, 3, 32, 32])
torch.Size([64, 6, 30, 30])
....
....
TensorBoard输出:
output的batch_size变成了2*64=128。