Java中为什么重写Equals方法要重写HashCode方法
文章目录
为什么?
是为了提高效率,采取重写hashcode方法,先进行hashcode比较,如果不同,那么就没必要在进行equals的比较了,这样就大大减少了equals比较的次数,这对比需要比较的数量很大的效率提高是很明显的,一个很好的例子就是在集合中的使用;
一、Object类中
Object类中的equals方法,底层是通过==来进行比较,所以比较的是对象的内存地址
1、equals方法
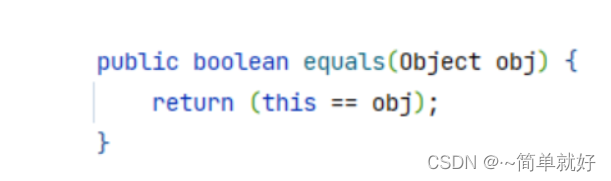
2、hashcode方法

二、set集合如何保证大量数据不能被放入重复的元素呢
- 我们都知道java中的List集合是有序的,因此是可以重复的,而set集合是无序的,因此是不能重复的,那么怎么能保证不能被放入重复的元素呢,但靠equals方法一样比较的话,如果原来集合中以后又10000个元素了,那么放入10001个元素,难道要将前面的所有元素都进行比较,看看是否有重复,这个效率可想而知,速率太慢。
- 因此hashcode就应遇而生了,java就采用了hash表,利用哈希算法(也叫散列算法),就是将对象数据根据该对象的特征使用特定的算法将其定义到一个地址上,那么在后面定义进来的数据只要看对应的hashcode地址上是否有值,那么就用equals比较,如果没有则直接插入,只要就大大减少了equals的使用次数,执行效率就大大提高了。
举例:将1到10放入散列值为5
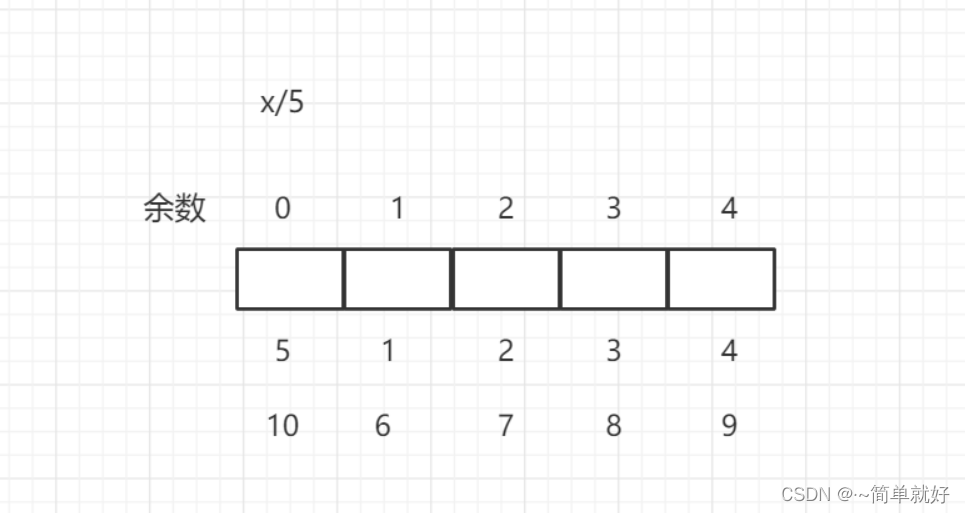
将1-10依次存入,当插入11时,我们先算出余数:11%5=1,
(1)我们先看余数1对应的有没有值,如果没有则直接插入,证明没有相同的值,(此时有1和6)
(2)如果有值,则用equals方法比较两者是否相等,
如果相等则,证明里面有相同的值,如果不相等,则直接存入。(此时1和6与11并不相等,所以没有重复的值)
总结:
同样的比较方法,如果先用hashcode方法比较,如果不相同则直接可以查出里面没有值,如果有hash相同,那么用equals比较。
由此可见,这样可以减少了大量的比较次数,也是我们最终想要达到的效果。
三、代码实现
总结来说就是两点
1.使用hashcode方法提前校验,可以避免每一次比对都调用equals方法,提高效率
2.保证是同一个对象,如果重写了equals方法,而没有重写hashcode方法,会出现equals相等的对象,hashcode不相等的情况,重写hashcode方法就是为了避免这种情况的出现。
1、创建一个Personsa类
public class InitializeDemo {
private static int k = 1;
private static InitializeDemo t1 = new InitializeDemo("t1");
private static InitializeDemo t2 = new InitializeDemo("t2");
private static int i = print("i");
private static int n = 99;
{
print("初始化块");
j=100;
}
public InitializeDemo(String str) {
System.out.println((k++) + ":" + str + " i=" + i + " n=" + n);
++i;
++n;
}
static {
print("静态块");
n=100;
}
private int j = print("j");
public static int print(String str) {
System.out.println((k++) + ":" + str + " i=" + i + " n=" + n);
++n;
return ++i;
}
public static void main(String[] args) {
InitializeDemo test = new InitializeDemo("test");
}
}
2、测试类
public class HashCodeTest {
public static void main(String[] args) {
Personsa person1 = new Personsa("张三",1);
Personsa person2 = new Personsa("张三",1);
System.out.println("两个对象equals比较 " + person1.equals(person2));
Set<Personsa> set = new HashSet<>();
set.add(person1);
System.out.println("person1 hashCode:" + person1.hashCode());
System.out.println("add s1 size:" + set.size());
set.add(person2);
System.out.println("person2 hashCode:" + person2.hashCode());
System.out.println("add s2 size::" + set.size());
}
}
运行结果:
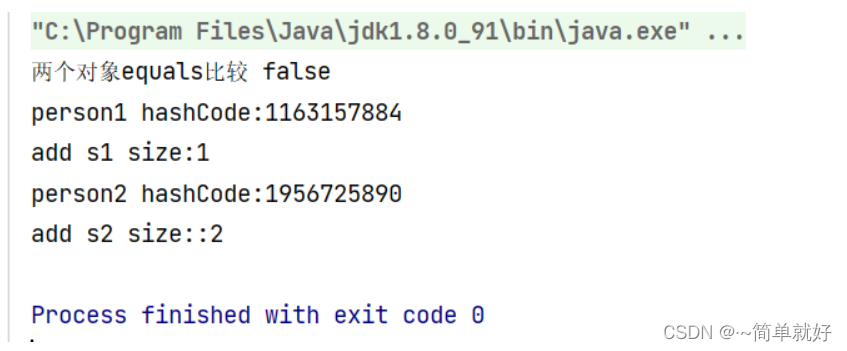
此时的equals比较为false;hashCode值也不相同,由此可见是创建了两个对象
而我们所赋值的成员变量却一样的,学生姓名成员变量都相同时,这两个对象应该是同一个对象才对,所以我们就必须重写equals方法。
3、重写equals方法
然后我们在重写Personsa类中重写equals方法,这个时候就是只需要name属性相同,equals方法就会返回true
@Override
public boolean equals(Object obj) {
if(obj ==null)
return false;
if(obj.getClass()!=getClass())
return false;
return ((Personsa)obj).getName().equals((getName()));
}
输出结果:
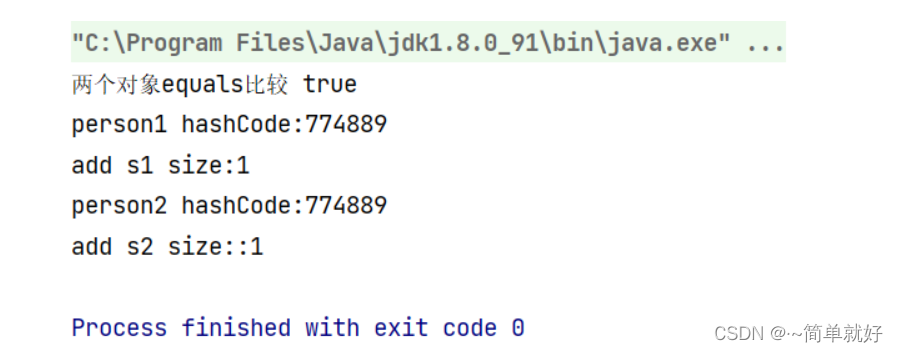
可以看出:此时hashCode值不一样,但是我们重写equals方法,返回值也是true
如果我们定义的只要名称相同,就是定义为同一个对象,那么我们必须重写hashCode方法,
4、重写hashCode方法
@Override
public boolean equals(Object obj) {
if(obj ==null)
return false;
if(obj.getClass()!=getClass())
return false;
return ((Personsa)obj).getName().equals((getName()));
}
@Override
public int hashCode() {
return getName().hashCode();
}
输出结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GUuSl6E7-1661879352377)(C:/Users/ZHANG/AppData/Roaming/Typora/typora-user-images/image-20220831005641990.png)]
此时:我们就已经达到了去重的目的,而且效率翻倍
可以类推,hash类存储结构(HashSet、HashMap等等)添加元素会有重复性校验,校验的方式就是先取hashCode判断是否相等(找到对应的位置,该位置可能存在多个元素),然后再取equals方法比较(极大缩小比较范围,高效判断),最终判定该存储结构中是否有重复元素。
四、总结
- hashCode主要用于提升查询效率,来确定在散列结构中对象的存储地址;
- 重写equals()必须重写hashCode(),二者参与计算的自身属性字段应该相同;
- hash类型的存储结构,添加元素重复性校验的标准就是先取hashCode值,后判断equals();
- equals()相等的两个对象,hashcode()一定相等;
- 反过来:hashcode()不等,一定能推出equals()也不等;
- 重写equals()必须重写hashCode(),二者参与计算的自身属性字段应该相同;
- hash类型的存储结构,添加元素重复性校验的标准就是先取hashCode值,后判断equals();
- equals()相等的两个对象,hashcode()一定相等;
- 反过来:hashcode()不等,一定能推出equals()也不等;
- hashcode()相等,equals()可能相等,也可能不等。