【论文速递】CVPR2022 - 多少观察才足够?用于轨迹预测的知识蒸馏
【论文原文】:How many Observations are Enough?Knowledge Distillation for Trajectory Forecasting
获取地址:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9879765
博主关键词: 轨迹预测,知识蒸馏,少量输入
推荐相关论文:
-无
摘要:
准确预测未来的人类位置是现代视频监控系统的一项基本任务。当前最先进的模型通常依赖于过去跟踪位置的“历史记录”(例如,3到5秒)来预测未来位置的合理序列(例如,最多5秒)。我们认为这种通用模式忽略了实际应用的关键特征:由于输入轨迹的收集涉及机器感知(即检测和跟踪),因此在拥挤的场景中可能会累积不正确的检测和碎片错误,从而导致跟踪漂移。在这种情况下,模型将被馈送损坏和嘈杂的输入数据,从而致命地影响其预测性能。在这方面,我们专注于在仅使用少量输入观察时提供准确的预测,从而潜在地降低与自动感知相关的风险。为此,我们构思了一种新颖的蒸馏策略,允许将知识从教师网络转移到学生网络,后者提供更少的观察结果(只有两个)。我们表明,一个适当定义的教师监督可以让学生网络的表现与需要更多观察的最先进方法相当。此外,对常见轨迹预测数据集的广泛实验突出表明,我们的学生网络可以更好地推广到看不见的场景。
关键词 :轨迹预测,知识蒸馏,少量输入。
简介:
行人轨迹预测通过利用个人轨迹信息和行人之间的相互影响来预测未来路径。这项任务在高级监视系统[24],行为分析[32],入侵检测[39],智能车辆和自主系统[4],[37]中有几个实际应用。
虽然最近的一些工作侧重于为这项任务量身定制的新型深度网络架构[14],[15],[20],[35],[49],[52],但我们认为轨迹预测器的推理阶段尚未得到彻底解决和研究。通常,数据驱动的模型在跟踪轨迹的大型公共数据集上进行训练和评估,这些轨迹通过人工干预进行优化,以纠正遗漏的检测和身份切换。然而,这个过程在推理时是不可行的:因此,跟踪系统必须自动提取条件预测所需的输入轨迹。
在这方面,广泛采用的8-12协议[1],[15],[20],[22],[34],[48],[52](即8个输入时间步长和12个预测时间步长),需要以2.5 FPS收集数据,并没有为上述情况提供很大的修正余地。 在实时应用中,视觉跟踪系统可能会为这种长度的序列提供不准确的观察[12]:遮挡、错误检测和非刚性形状变形会带来不平凡的问题。
为了克服上述限制,一种可能的解决方案是减少输入轨迹的长度,以尽量减少跟踪关联误差。基于这一直觉,本文提出了一种基于知识蒸馏[18]的方法,该方法恢复了通过更多的输入观测获得的相同信息的可靠代理。我们表明,它允许有效的推理模式,需要的样本比训练模式少。我们还证明,在较短的输入轨迹上正确调节模型提供了更大的空间来跨不同的实验设置进行泛化。
从技术角度来看,这项工作通过部署师生范式[18]来实现我们的想法:训练学生网络使用较少的输入观察来模仿教师的行为。每个网络都设计了一个基于变压器的架构,通过注意力机制考虑空间和时间相互作用。为了处理有限数量的观察结果,我们提出了一种蒸馏程序,该程序同时作用于变压器架构的编码器和解码器堆栈。最后,我们的目标函数考虑了地面真实数据和蒸馏损失,以方便地匹配教师和学生的内部表示。
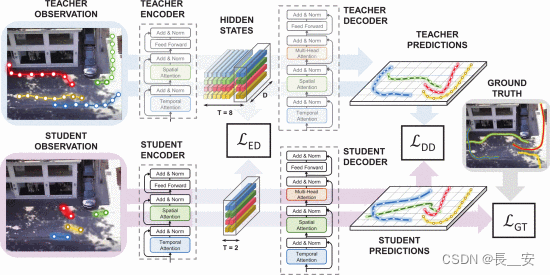
我们的贡献如下:i)据我们所知,这是首次尝试深入分析当前轨迹预测模型通常采用的评估协议的有效性(在推理时);ii)我们引入了一种新的蒸馏策略,以减少输入轨迹的长度,同时保持预测的准确性;iii)我们探索学生适应和转移其知识的能力,以在人类动力学和场景交互方面表现出不同复杂程度的场景。事实上,实验强调,构建一个可靠的轨迹预测系统是可能的,在推理时,每个行人只有 2 个观察(即最后两个)的观测值。这只能通过深思熟虑地利用全局知识来实现,这些知识可以从训练数据中推断出来并提炼到推理模型中。
【论文速递 | 精选】
