目录
1. MapReduce概述
MapReduce是面向大数据并行处理的计算模型、框架和平台:
1. 基于集群的高性能并行计算平台:它允许使用市场上普通的商用服务器构成一个包含数十、数百甚至数千个节点的分布式并行计算集群。
2. 并行计算与运行软件框架:它提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果。
3. 并行程序设计模型与方法:它借助于函数式程序设计语言Lisp的设计思想,提供了一种简便的并行程序设计方法,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口。
MapReduce通过把对数据集的大规模操作分发给网络上的每个节点实现可靠性,每个节点会周期性地返回它所完成的工作和最新的状态。如果一个节点保持沉默超过一个预设的时间间隔,主节点将标记这个节点状态为死亡,并把分配给这个节点的数据发到别的节点上。
2. MapReduce的功能
2.1 数据划分和计算任务调度
系统自动将一个作业待处理的数据划分成很多个数据块,每个数据块对应于一个计算任务,并自动调度计算节点来处理相应的数据块。作业和任务调度功能主要负责分配和调度计算节点,同时负责监控这些节点的执行状态,并负责Map节点执行的同步控制。
2.2 数据/代码互定位
1. 本地化数据处理:一个计算节点尽可能处理其本地磁盘上所分布存储的数据,实现了代码向数据的迁移。
2. 无法本地化数据处理:寻找其他可用节点并将数据从网络上传送给该节点,但将尽可能从数据所在的本地机架上寻找可用节点以减少通信延迟,实现了数据向代码的迁移。
2.3 系统优化
中间结果数据进入Reduce节点前会进行一定的合并处理;一个Reduce节点所处理的数据可能来自多个Map节点,为了避免Reduce计算阶段发生数据相关性,Map节点输出的中间结果需使用一定的策略进行适当的划分处理,以保证相关性数据发送到同一个Reduce节点。
此外,系统还进行一些计算性能优化处理,如对最慢的计算任务采用多备份执行、选最快完成者作为结果。
2.4 出错检测和恢复
以低端商用服务器构成的大规模MapReduce计算集群中,节点硬件出错和软件出错是常态,因此MapReduce需要能检测并隔离出错节点,调度分配新的节点接管出错节点的计算任务。同时,系统还将维护数据存储的可靠性,用多备份冗余存储机制提高数据存储的可靠性,并能及时检测和恢复出错的数据。
3. MapReduce处理流程
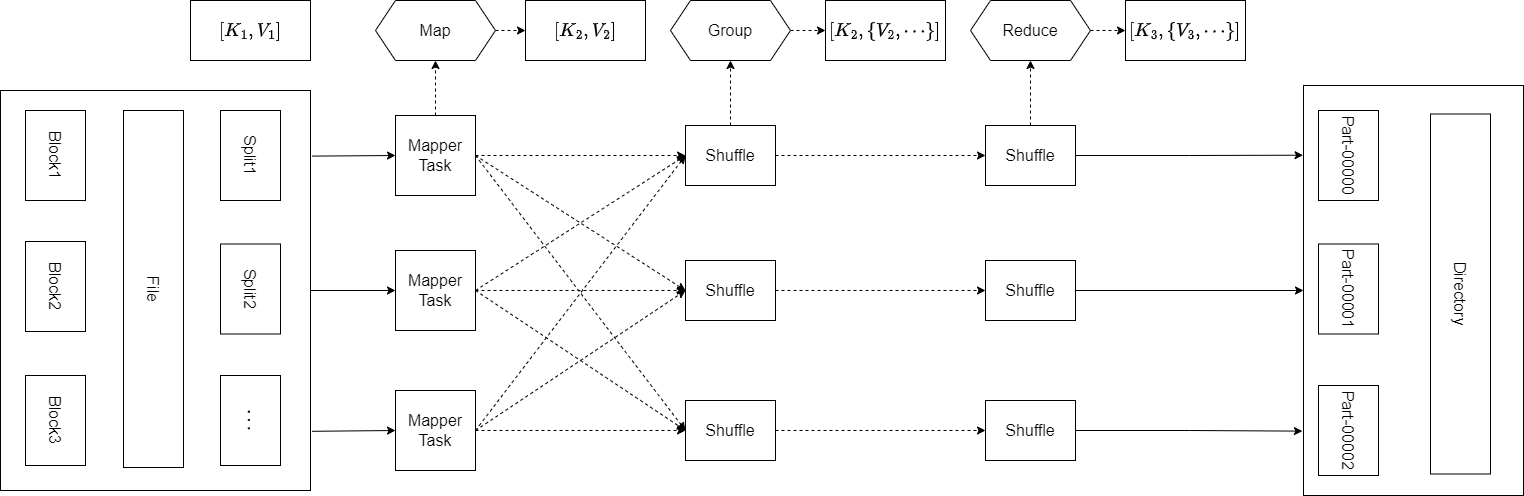
MapReduce处理流程可以分为三个阶段:Map、Shuffle和Reduce。
Map是映射,负责数据的过滤分发,将原始数据转换成键值对;Shuffle将Map的输出进行排序与分割后再交给Reduce;Reduce是合并,将具有相同key值的value进行处理后再输出新的键值对作为最终结果。MapReduce的处理流程如下图所示。
Map和Reduce操作需要开发人员自己定义相应Map类和Reduce类,而Shuffle是系统自动实现的。Shuffle过程发生在Map和Reduce两端,Map端的Shuffle是对单个Map的结果进行分区、排序、分割,然后将属于同一分区的输出合并在一起并写在磁盘上(分区有序的含义是Map输出的键值对按分区进行排列,具有相同分区值的键值对存储在一起,每个分区里面的键值对又按key值进行升序排列)。Reduce段的Shuffle是从多个Map上拉取属于自己分区的数据,然后在保持数据排序的情况下将多个Map上的数据按照键值进行合并,同时将多个合并后的数据写入磁盘,最后将多个合并后的数据按照键值进行分组来作为Reduce的输入。
4. MapReduce编程基础
Hadoop内置数据类型如下表所示。
| 类型名 | 含义 |
|---|---|
| BooleanWritable | 标准布尔类型 |
| ByteWritable | 单字节数值 |
| DoubleWritable | 双精度浮点数 |
| FloatWritable | 单精度浮点数 |
| IntWritable | 整型 |
| LongWritable | 长整型 |
| Text | 使用UTF-8格式存储的文本 |
| NullWritable | 当<key, value>中的key或value为空时使用 |
| ArrayWritable | 存储属于Writable类型值的数组 |
下面是maven项目中pom.xml中依赖部分的配置。
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.6</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
下面是简单使用Hadoop中内置数据类型的代码。
import org.apache.hadoop.io.ArrayWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.MapWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
public class App {
public static void testText() {
System.out.println("testText");
Text text = new Text("hello hadoop!");
System.out.println(text.getLength());
System.out.println(text.find("ll"));
System.out.println(text.toString());
}
public static void testArrayWritable() {
System.out.println("testArrayWritable");
ArrayWritable arr = new ArrayWritable(IntWritable.class);
IntWritable year = new IntWritable(2025);
IntWritable month = new IntWritable(1);
IntWritable day = new IntWritable(29);
arr.set(new Writable[] {year, month, day});
System.out.printf("year=%s, month=%s, day=%s%n", arr.get()[0], arr.get()[1], arr.get()[2]);
}
public static void testMapWritable() {
System.out.println("testMapWritable");
MapWritable map = new MapWritable();
Text k1 = new Text("name");
Text v1 = new Text("tonny");
Text k2 = new Text("password");
map.put(k1, v1);
map.put(k2, NullWritable.get());
System.out.println(map.get(k1).toString());
System.out.println(map.get(k2).toString());
}
public static void main(String[] args) {
testText();
testArrayWritable();
testMapWritable();
}
}
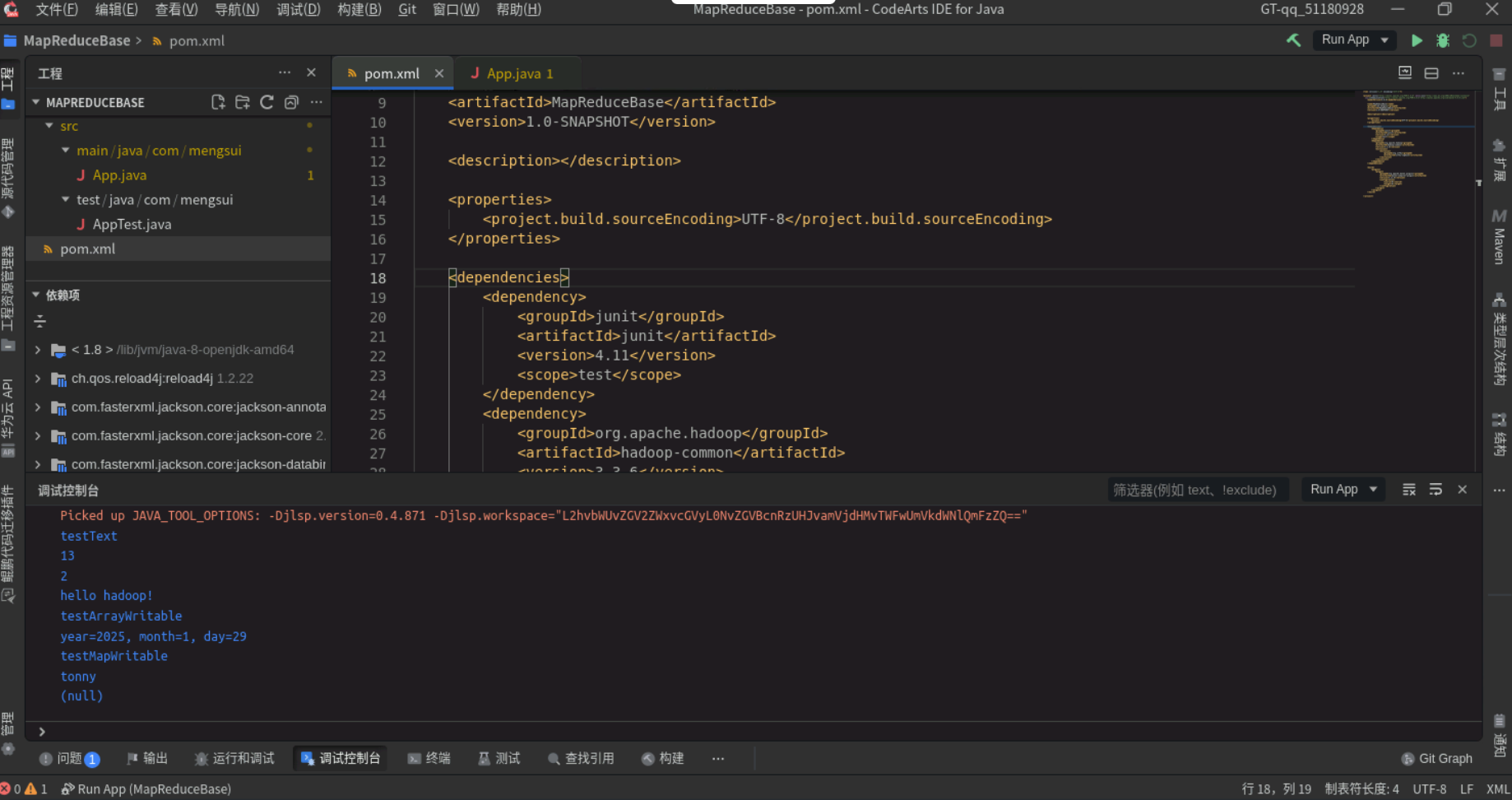
运行结果如下。
参考
吴章勇 杨强著 大数据Hadoop3.X分布式处理实战