一、大数据
1.1 奇安信2020/5/31
17-20
17. 设循环队列中数组的下标范围是1~n,其头尾指针分别为f和r,则其元素个数为 A r-f B r-f+1 C (r-f)%n D (r-f+n)%n
对于一个循环队列来说,元素个数的计算需要考虑队列是环状结构的特性,即头指针(f)和尾指针(r)可能会绕过数组的末尾重新开始。要准确地计算队列中的元素个数,需要用一种方法来处理这种“循环”的情况。
正确答案:D. (r−f+n)%n
解释
-
什么是循环队列?
想象一下,一个队列就像一个环形的座位圈。你可以从第一个座位开始,一个接一个地坐下去,直到最后一个座位。然后,你会回到第一个座位,再开始新的一圈。循环队列就是这样的环形结构。
-
原理:①循环队列是用一个固定大小的数组来实现的,队列的头指针(f)和尾指针(r)会在数组的范围(1 到 n)内循环移动。②当尾指针r追上头指针f时,队列可能为空或满。③为了区分队列是空还是满,常用的方法是浪费一个数组位置,即定义队列为空的条件为 f==r,队列为满的条件为 (r+1)%n==f
我的理解:就像一只在数组爬行的贪吃蛇,加元素从后面加,尾巴后移,减元素则从前面加,头前移,前后到最后一个位置就到开始位置去了;当头尾相连,要么蛇身体充满了数组,要么身体被吃光了,为了区分,所以规定头尾到一起去了就是空,满则是尾巴再移一格就和头重合。
-
队列中的两个指针,在这个循环队列里,我们有两个指针:头指针(
f):指向队列的第一个元素的位置。尾指针(r):指向队列最后一个元素的下一个位置(也就是一个空位)。
-
用通俗的方式总结
- 选项 D 的公式
(r - f + n) % n可以帮我们计算出循环队列中的元素个数,不管头指针和尾指针在哪里,因为它考虑了所有可能的情况。 -
公式
D. (r - f + n) % n正是这样做的: r - f:直接计算两个指针之间的差值。+ n:因为f在r的后面时需要考虑绕过数组末尾的情况。% n:用来确保计算结果在数组大小范围内。-
如何计算队列中的元素个数?
- 假设我们的队列最多可以放下
n个元素。 - 如果头指针
f在尾指针r的前面(f ≤ r),那么队列中的元素个数就是r - f,很简单对吗? - 如果
f在r的后面(也就是绕过了队列的末尾,f > r),这时候我们需要从r算到f之间的元素个数。因为是循环的,我们需要把数组的大小n加进去来进行计算。
18. 甲,乙,丙三人各自独立地破解密码,三人的成功破解的概率分别是0.5,0.6,0.7,则密码被破解的概率为 A 0.94 B 0.92 C 0.95 D 0.9
三人(甲、乙、丙)各自独立地尝试破解密码。我们要求的是至少有一个人成功破解密码的概率。
解题步骤
-
计算每个人失败的概率:
- 甲失败的概率:1−0.5=0.51 - 0.5 = 0.51−0.5=0.5
- 乙失败的概率:1−0.6=0.41 - 0.6 = 0.41−0.6=0.4
- 丙失败的概率:1−0.7=0.31 - 0.7 = 0.31−0.7=0.3
-
计算三人都失败的概率:
三人独立操作,所以都失败的概率为:
P(都失败)=0.5×0.4×0.3=0.06P(\text{都失败}) = 0.5 \times 0.4 \times 0.3 = 0.06P(都失败)=0.5×0.4×0.3=0.06 -
计算密码被破解的概率:
密码被破解的概率 = 1 - 三人都失败的概率:
P(至少一个成功)=1−P(都失败)=1−0.06=0.94
正确答案
A. 0.94
19.
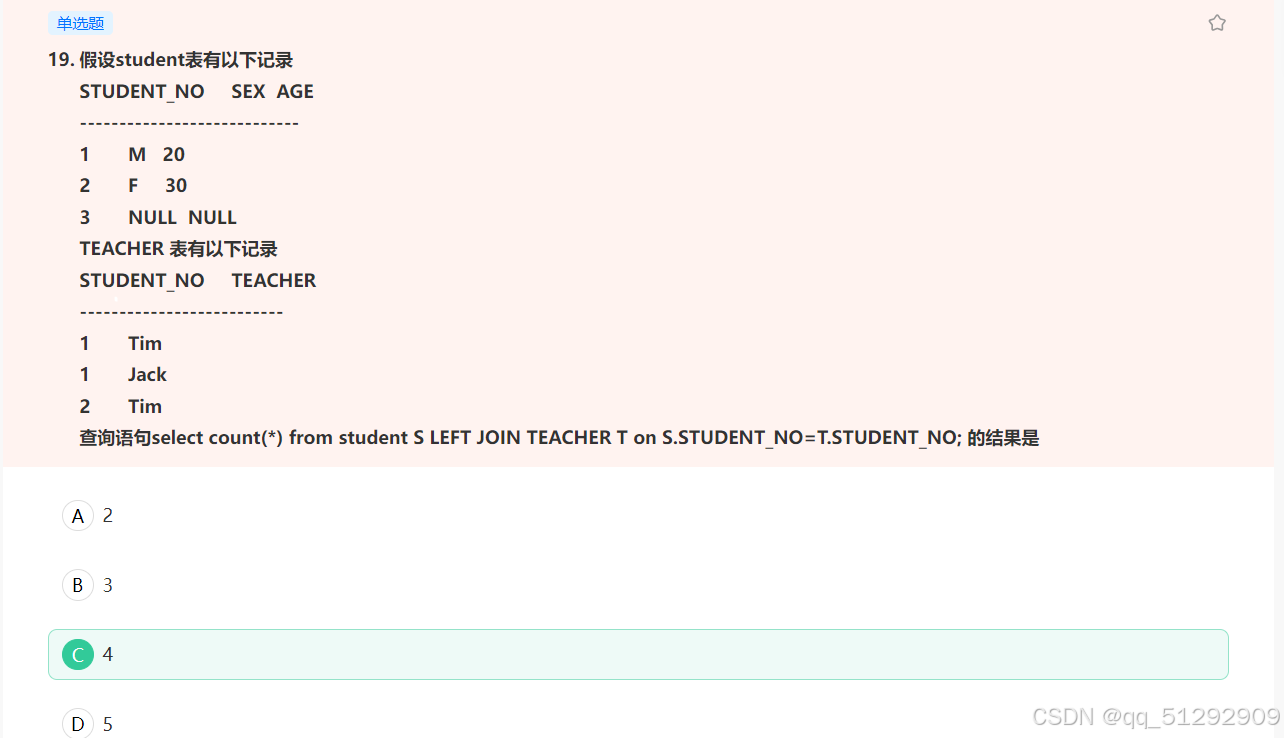
要解答这个问题,我们需要分析 SELECT COUNT(*) 查询的结果。
查询的 SQL 语句是:
SELECT COUNT(*) FROM student S LEFT JOIN teacher T ON S.STUDENT_NO = T.STUDENT_NO;
在这个查询中,我们对 student 表进行 LEFT JOIN 操作,将其与 teacher 表连接。LEFT JOIN 确保了 student 表中的所有记录都会出现在结果中,即使 teacher 表中没有匹配的记录。
我们有以下记录:
-
student表的记录:STUDENT_NO SEX AGE ---------------------------- 1 M 20 2 F 30 3 NULL NULL -
teacher表的记录:STUDENT_NO TEACHER -------------------------- 1 Tim 1 Jack 2 Tim
在 LEFT JOIN 操作中,我们会有以下结果:
- 对于
student.STUDENT_NO = 1的记录,有两个teacher记录(Tim 和 Jack)。 - 对于
student.STUDENT_NO = 2的记录,有一个teacher记录(Tim)。 - 对于
student.STUDENT_NO = NULL的记录,没有匹配的teacher记录。
因此,结果表将包含以下记录:
STUDENT_NO | SEX | AGE | TEACHER
-----------------------------------
1 | M | 20 | Tim
1 | M | 20 | Jack
2 | F | 30 | Tim
3 | NULL| NULL| NULL
这些记录的总数是 4。
所以,查询语句的结果是:C. 4
20. 将事务写入数据库的命令是 A insert B commit C rollback D delete
在数据库管理系统(DBMS)中,事务是指一系列操作的集合,这些操作要么全部成功,要么全部失败。事务的写入和管理涉及几个关键命令:
insert:用于向数据库表中插入新记录。commit:用于将事务中的所有操作持久化到数据库中,即确认并保存对数据库所做的修改。rollback:用于撤销事务中的所有操作,即取消对数据库所做的修改,将数据库恢复到事务开始之前的状态。delete:用于从数据库表中删除记录。
正确答案:B. commit
解释
insert和delete都是数据操作命令,用于分别插入和删除记录,但它们并不是事务管理的命令。commit是将事务中的所有操作保存到数据库中,确认这些操作正式完成。它是写入事务的关键命令。rollback是用于撤销事务中的操作,不是用来写入事务的。
总结
- 要将事务中的修改保存到数据库中,应该使用
commit命令。
21-25
21. 以下哪些标识可在LINUX系统用于管理用户权限 A 用户ID B 附加用户ID C 组ID D 附加组ID
从管理用户权限的角度来看,选项 A 是绝对正确的:用户ID (UID) 是用来唯一标识和管理用户的主要标识符。
然而,从权限管理的全面角度来看,附加组ID 和组ID 也涉及到权限管理。附加组ID(Supplementary GIDs)帮助确定用户是否属于其他组,从而影响用户的访问权限。组ID(GID)用于标识用户所属的主组,这也是权限管理的一部分。
在一些考试或问题中,可能会要求你仅关注最核心的管理权限标识,即用户ID(UID),特别是在基本问题的背景下。可能的情况是题目特别指定只关注最基本的用户权限标识,这样的话,答案可能只会选 A。
总结:
- 用户ID (UID) 是最直接且核心的用户权限标识符。
- 组ID 和附加组ID 也与权限管理相关,但在特定上下文中可能被认为是附加的或次要的。
所以,虽然从全面的权限管理角度看 A、C、D 都有涉及,单独选择 A 也能反映出最核心的权限管理标识。
22. 下列哪些类是线程安全的 A Vector B HashTable C HashMap D StringBuilder
线程安全的类是指那些在多线程环境下能够正确处理并发访问的类。针对你提到的类,这里是它们的线程安全性分析:
A. Vector
Vector是线程安全的。它的方法都是同步的(通过synchronized关键字),因此在多线程环境下,Vector能够保证数据的正确性。
B. HashTable
Hashtable也是线程安全的。它的所有方法都是同步的,因此它在多线程环境中可以安全地使用。
C. HashMap
HashMap不是线程安全的。如果多个线程同时访问一个HashMap实例,并且至少有一个线程修改了结构(比如添加或删除元素),那么它必须进行外部同步,以避免数据不一致或程序异常。
D. StringBuilder
StringBuilder不是线程安全的。它的设计是为了提高性能,因此没有提供同步机制。如果多个线程并发访问一个StringBuilder实例,它可能会出现不一致的状态。
总结:
- 线程安全的类:A. Vector, B. Hashtable
- 非线程安全的类:C. HashMap, D. StringBuilder