背景
预训练语言模型已经成为了现代自然语言处理pipeline中的基石,因为其在少量的标注数据上产生更好的结果。随着ELMo、ULMFiT、GPT和BERT的开发,使用预训练模型在下游任务上微调的范式被广泛使用。随后发现预训练语言模型在没有任何额外训练的情况下任务能执行有用的任务,进一步证明了其实用性。此外,根据经验观察,语言模型的性能随着模型的增大而增加(有时是可预测的,有时是突然的),这也导致了模型规模越来越多的趋势。抛开环境的问题,训练大语言模型(LLM)的代价仅有资源丰富的组织可以负担的起。此外,直至最终,大多数LLM都没有公开发布。因此,大多数的研究社区都被排除在LLM的开发之外。这在不公开发布导致的具体后果:例如,大多数LLM主要是在英文文本上训练的。
为了解决这些问题,BigScience团队提出了BigScience Large Open-science Open-access Multilingual Language Model(BLOOM)。BLOOM是在46种自然语言和13种编程语言上训练的1760亿参数语言模型,其是由数百名研究人员合作开发和发布的。训练BLOOM的计算力是由来自于法国公共拨款的GENCI和IDRIS,利用了IDRIS的Jean Zay超级计算机。为了构建BLOOM,对于每个组件进行了详细的设计,包括训练数据、模型架构和训练目标、以及分布式学习的工程策略。BigScience也执行了模型容量的分析。他们的总体目标不仅是公开发布一个能够和近期开发的系统相媲美的大规模多语言的语言模型,而且还记录其开发中的协调过程。
BigScience
在解读论文前,我们先介绍下BigScience团队,BigScience 不是财团(consortium),也不是正式成立的实体。这是一个由HuggingFace、GENCI和IDRIS发起的开放式协作组织,以及一个同名的研究研讨会(workshop)。其主页为 https://bigscience.huggingface.co/。
BigScience发布 BLOOM,旨在为学术界、非营利组织和小型公司的研究实验室能够更好的研究和使用LLM。并且,BLOOM 本身也是由大量的是AI研究人员参与的单个研究项目,同时也是迄今为止最大规模的合作结果。
BLOOM
概述
BLOOM是由BigScience社区开发和发布的,也是第一个开源开放的超过100B的语言模型。BLOOM 本身是变换器网络Transformer解码器(Decoder-Only)模型,在一个称之为ROOTS的语料库上训练出来的176B参数规模【和 GPT-3一样的规模】的自回归语言模型。训练 BLOOM 的算力成本超过300万欧元,由CNRS 和 GENCI提供,训练模型的机器是法国巴黎的Jean Zay超级计算机。BLOOM是在2021年5月至2022年5月的一年时间里完成训练并发布的。初始版本发布于2022年5月19日。目前最新的版本是2022年7月6日发布的1.3版本。
该项目由 Thomas Wolf (Hugging Face 联合创始人兼 CSO) 发起,他敢于与大公司竞争,提出不仅要训练出立于世界上最大的多语言模型之林的模型,还要让所有人都可以公开访问训练结果,圆了大多数人的梦想。BLOOM由来自39个国家的1200多名参与者共同开发,是全球努力的产物。该项目由 BigScience 与 Hugging Face 和法国 NLP社区合作协调,超越了地理和机构的界限。BLOOM不仅是一个技术奇迹,也是国际合作和集体科学追求力量的象征。
参数
| 名称 | BLOOM-176B |
|---|---|
| 参数规模 (params) | 176,247M (176B) |
| 隐变量维度 (dimension) | 14336 |
| 自注意力头的个数 (n heads) | 112 |
| 层数 (n layers) | 70 |
| 词表大小 (Vocab size) | 250,680 |
| 输入序列长度 (sequence length) | 2048 |
| 数据规模词元数量 (n tokens) | 366B |
| 训练时长 (Training GPU-hours) | 1,082,990 (A100) |
训练硬件
- GPU: 384 张 NVIDIA A100 80GB GPU (48 个节点) + 32 张备用 GPU
- 每个节点 8 张 GPU,4 条 NVLink 卡间互联,4 条 OmniPath 链路
- CPU: AMD EPYC 7543 32 核处理器
- CPU 内存: 每个节点 512GB
- GPU 显存: 每个节点 640GB
- 节点间连接: 使用 Omni-Path Architecture (OPA) 网卡,网络拓扑为无阻塞胖树
- NCCL - 通信网络: 一个完全专用的子网
- 磁盘 IO 网络: GPFS 与其他节点和用户共享
训练数据
训练数据集ROOTS
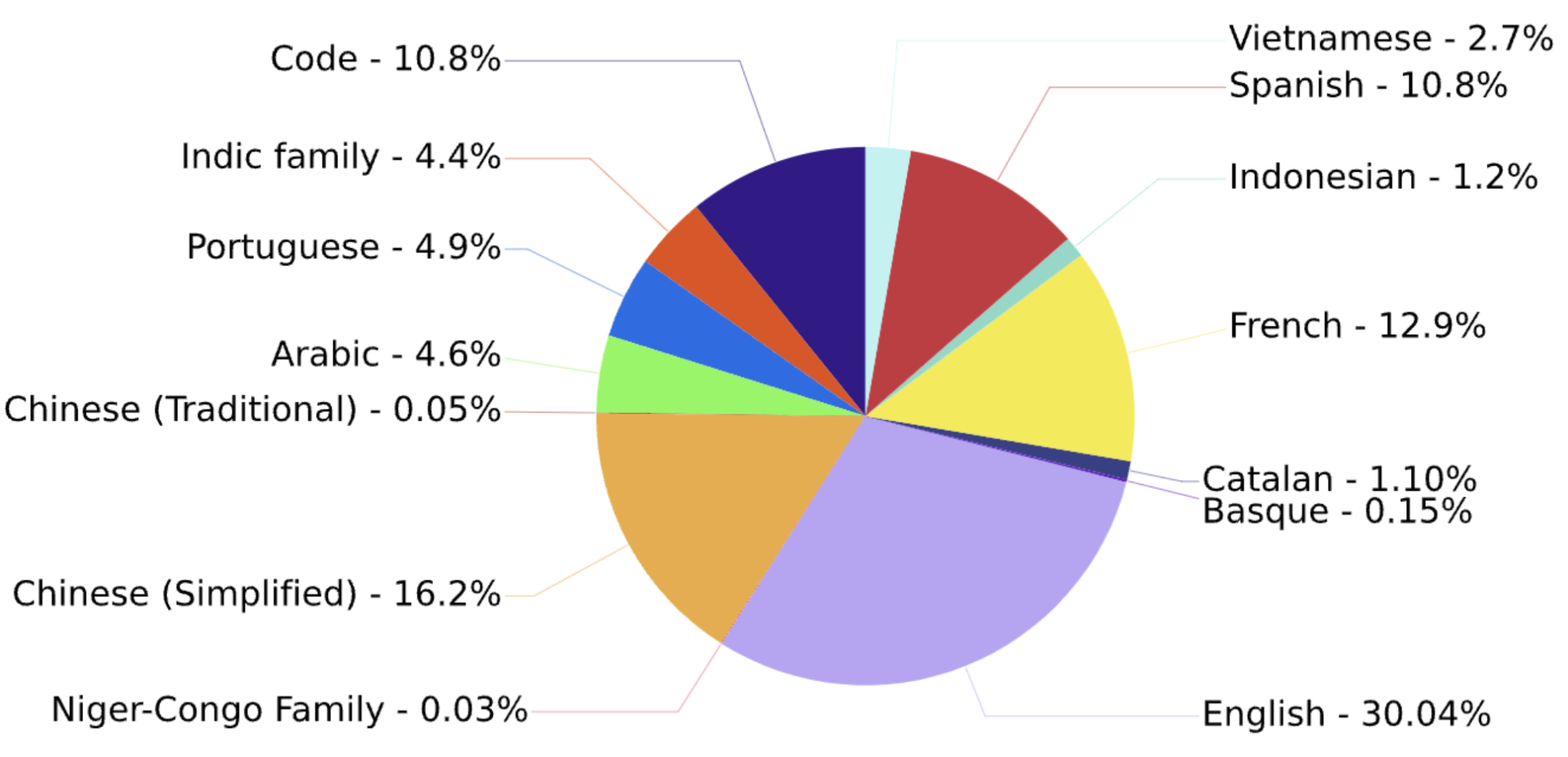
BLOOM在 ROOTS 语料库上训练,该语料库是 59 种语言的498来源的数据集的总和(数据集全部来自HuggingFace),总计 1.61 TB 的文本,包含46 种自然语言和 13 种编程语言。词元(Token)数量为366B。下图给出了所有语言的占比:
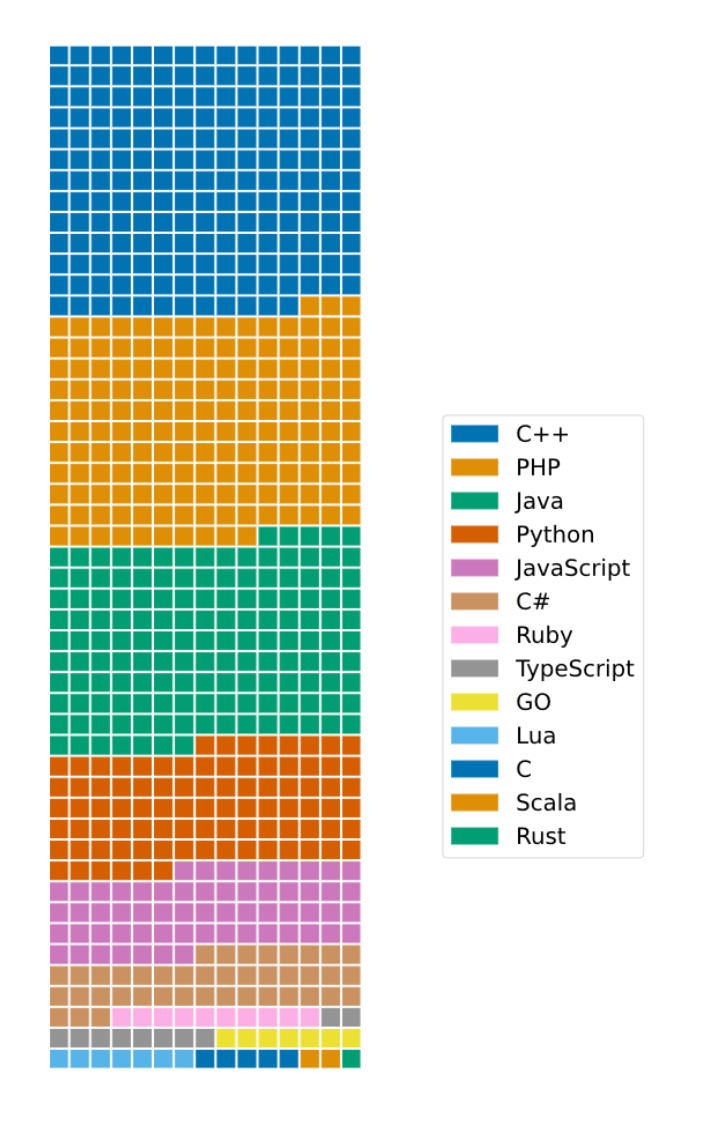
对于编程语言:数据的选择和处理参照 DeepMind 的 AlphaCode。数据的获取利用了Google的BigQuery项目。包含语言为Java,PHP,C++,Python,JavaScript,C#,Ruby,Lua,TypeScript,Go,C,Scala,Rust。语言的分布如下图所示:
训练数据集xP3
这是一个提示数据集,用于多任务提示微调(也称为指令调优),涉及在由通过自然语言提示指定的大量不同任务组成的训练混合体上微调预训练语言模型。原始 P3 数据集被扩展为包括英语以外的语言的新数据集和新任务,例如翻译。 这导致了 xP3,它是 83 个数据集的提示集合,涵盖 46 种语言和 16 个任务。
数据处理
获取到数据后,设计者使用了两种方式处理数据:
- 质量过滤:大规模数据通常由自动化脚本获取,这其中包含了大量的非自然语言文本,如预处理错误、SEO页面或垃圾信息。为了过滤非自然语言,定义了一组质量指标,确保文本是由人类为人类撰写的。这些指标根据每种语言和每个来源的需求进行了调整,通过流利的语言使用者选择参数,并手动检查每个来源以识别非自然语言。这一过程得到了工具的支持,以可视化其影响,从而提高文本的质量和自然度。
- 去重和隐私信息处理:通过两个去重步骤,模型移除了近似重复的文档,确保数据的唯一性和多样性。同时,为了保护隐私,从语料库的OSCAR版本中删除了能够识别的个人身份信息,如社会安全号码,即使这可能导致一些误报,也应用了基于正则表达式的处理。
模型架构
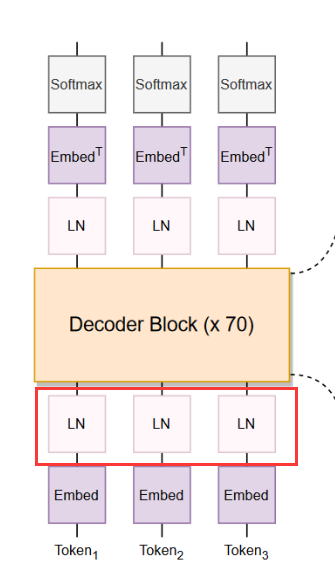
BLOOM的模型架构采用了类似GPT-3的Decoder-Only架构,模型架构如下图所示:

与Transformers架构中的自回归(因果)解码器相比,BLOOM做出了两个改进:
ALiBi 位置嵌入
在Transformer模型中,通常使用位置编码(如绝对位置编码或相对位置编码)来为输入序列的每个元素分配一个位置标识,以便模型能够理解输入序列中元素之间的顺序。然而,这种位置编码往往会增加计算复杂度,特别是在长序列的情况下,位置编码可能不具备良好的泛化能力。
ALiBi提出了一种新的方法来处理自注意力机制中的位置关系,而不依赖于传统的显式位置编码。具体来说,ALiBi通过在计算注意力权重时引入线性偏置,从而将位置的影响直接嵌入到注意力分数的计算中。ALiBi(Attention with Linear Biases)是一种用于改进自注意力机制(self-attention)位置编码(position embedding)的方法,它是由Google Research在2021年提出的。ALiBi的目的是通过引入线性偏置来减少对显式位置嵌入的依赖,从而提高计算效率和模型的泛化能力。
ALiBi的实现是通过修改自注意力机制中的注意力得分计算公式。标准的自注意力机制中的得分计算为:
Attention Score
=
Q
K
T
d
k
\text{Attention Score} = \frac{QK^T}{\sqrt{d_k}}
Attention Score=dkQKT
其中,
Q
Q
Q是查询向量,
K
K
K 是键向量,
d
k
d_k
dk是向量的维度。ALiBi则通过添加一个与位置相关的线性偏置项
B
i
j
B_{ij}
Bij 来修改这一得分:
Attention Score
=
Q
K
T
d
k
+
B
i
j
\text{Attention Score} = \frac{QK^T}{\sqrt{d_k}} + B_{ij}
Attention Score=dkQKT+Bij
这里,
B
i
j
B_{ij}
Bij是一个基于位置的线性偏置,它对不同位置对之间的关系进行建模。通过这种方式,ALiBi将位置嵌入直接整合到了注意力分数中。
通过使用ALiBi位置嵌入:
- 简化了位置编码的设计:传统的Transformer模型需要额外的固定位置编码(例如,正弦和余弦函数生成的编码)或相对位置编码,而ALiBi通过引入线性偏置使得位置关系能够在注意力机制中动态地体现。
- 无参数化的空间扩展:传统的绝对或相对位置编码在处理不同长度的序列时,往往需要重新调整编码的大小,而ALiBi的方法可以无缝适应长序列。
- 增强了模型的泛化能力:通过这种方式,ALiBi能够帮助模型更好地学习和推断不同长度和位置关系的序列,进而提高其泛化性能。
BLOOM 团队认为ALiBi 位置嵌入使用在推断中能够完成更长序列的任务,同时训练时更加平滑,以及对下游任务来说有更好的性能。
具体给出实现:
def build_alibi_tensor(attention_mask, num_heads, dtype) -> mindspore.Tensor:
batch_size, seq_length = attention_mask.shape
# closet_power_of_2是与num_head接近的2的次方
# 例如:num_heads为5/6/7时,closest_power_of_2为4
closest_power_of_2 = 2 ** math.floor(math.log2(num_heads))
# 计算斜率
base = mindspore.Tensor(
2 ** (-(2 ** -(math.log2(closest_power_of_2) - 3))),dtype=mindspore.float32
)
powers = mindspore.ops.arange(1, 1 + closest_power_of_2,dtype=mindspore.int32)
slopes = mindspore.ops.pow(base, powers)
# 注意力头数量不是2的次方
if closest_power_of_2 != num_heads:
extra_base = mindspore.Tensor(
2 ** (-(2 ** -(math.log2(2 * closest_power_of_2) - 3))), dtype=mindspore.float32
)
num_remaining_heads = min(closest_power_of_2, num_heads - closest_power_of_2)
extra_powers = mindspore.ops.arange(1, 1 + 2 * num_remaining_heads, 2, dtype=dtype=mindspore.int32)
slopes =mindspore.ops.cat([slopes, torch.pow(extra_base, extra_powers)], axis=0)
# 相对距离
arange_tensor = ((attention_mask.cumsum(dim=-1) - 1) * attention_mask)[:, None, :]
# alibi会与query和key的乘积相加
# alibi的形状为[batch_size, num_heads, query_length, key_length]
alibi = slopes[..., None] * arange_tensor
return alibi.reshape(batch_size * num_heads, 1, seq_length).to(dtype)
Embedding LayerNorm
这项技术简单直接且有效, 如下图所示,在嵌入层之后立即包含额外的层归一化,这提高了训练稳定性。这一决定在一定程度上受到在最终训练中使用 bfloat16 的影响,它比 float16 更稳定。
在训练一个104B参数模型的初步实验中,研究人员尝试在嵌入层之后立即添加一个额外的层归一化(Layer Normalization),这是根据bitsandbytes17库及其StableEmbedding层的推荐。他们发现这显著提高了训练的稳定性。尽管他们也发现这会惩罚零样本泛化能力,但他们仍然在BLOOM的训练中在第一个嵌入层之后添加了一个额外的层归一化,以避免训练不稳定。需要注意的是,初步的104B实验是在float16精度下进行的,而最终的训练是在bfloat16精度下进行的。自那以后,float16被认为是导致许多大型语言模型(LLMs)训练中出现不稳定性的原因(Zhang et al., 2022; Zeng et al., 2022)。因此,有可能bfloat16精度缓解了对嵌入层归一化的需求。
工程实现
176B BLOOM 模型使用 Megatron-DeepSpeed 进行训练,它结合了两种主要技术:
- DeepSpeed 是一个深度学习优化库,让分布式训练变得简单、高效且有效。
- Megatron-LM 是由 NVIDIA 的应用深度学习研究团队开发的大型、强大的 transformer 模型框架。
DeepSpeed 团队通过将 DeepSpeed 库中的 ZeRO 分片和流水线并行 (Pipeline Parallelism) 与 Megatron-LM 中的张量并行 (Tensor Parallelism) 相结合,开发了一种基于 3D 并行的方案。有关每个组件的更多详细信息,请参见下表。
| 组件 | DeepSpeed | Megatron-LM |
|---|---|---|
| ZeRO 数据并行 | 是 | |
| 张量并行 | 是 | |
| 流水线并行 | 是 | |
| BF16 优化器 | 是 | |
| CUDA 融合核函数 | 是 | |
| 数据加载器 | 是 |
Megatron-DeepSpeed 实现了 3D 并行以允许大模型以非常有效的方式进行训练。
- 数据并行 (Data Parallelism,DP) - 相同的设置和模型被复制多份,每份每次都被馈送不同的一份数据。处理是并行完成的,所有份在每个训练步结束时同步。
- 张量并行 (Tensor Parallelism,TP) - 每个张量都被分成多个块,因此张量的每个分片都位于其指定的 GPU 上,而不是让整个张量驻留在单个 GPU 上。在处理过程中,每个分片在不同的 GPU 上分别并行处理,结果在步骤结束时同步。这就是所谓的水平并行,因为是做的水平拆分。
- 流水线并行 (Pipeline Parallelism,PP) - 模型在多个 GPU 上垂直 (即按层) 拆分,因此只有一个或多个模型层放置在单个 GPU 上。每个 GPU 并行处理流水线的不同阶段,并处理 batch 的一部分数据。
- 零冗余优化器 (Zero Redundancy Optimizer,ZeRO) - 也执行与 TP 相类似的张量分片,但整个张量会及时重建以进行前向或反向计算,因此不需要修改模型。它还支持各种卸载技术以补偿有限的 GPU 内存。
数据集上的评价指标得分
SuperGLUE
SuperGLUE(Super General Language Understanding Evaluation)是一个用于评估自然语言理解(NLU)模型性能的基准测试套件。它由Wang等人于2019年提出,旨在替代早期的GLUE基准,提供更具挑战性的任务,以推动NLU模型的发展。
SuperGLUE包含以下几个主要任务:
- AX-b:一种二元分类任务,用于评估模型对句子对之间关系的理解。
- AX-g:另一种二元分类任务,类似于AX-b,但更具挑战性。
- BoolQ:布尔问答任务,模型需要判断给定的问题是否为真或假。
- CB:文本分类任务,模型需要对给定的句子对进行分类。
- WiC:词义消歧任务,模型需要判断两个句子中的同一个词是否具有相同的含义。
- WSC:代词消解任务,模型需要确定句子中的代词指代的具体对象。
- RTE:文本蕴含任务,模型需要判断一个句子是否蕴含另一个句子。
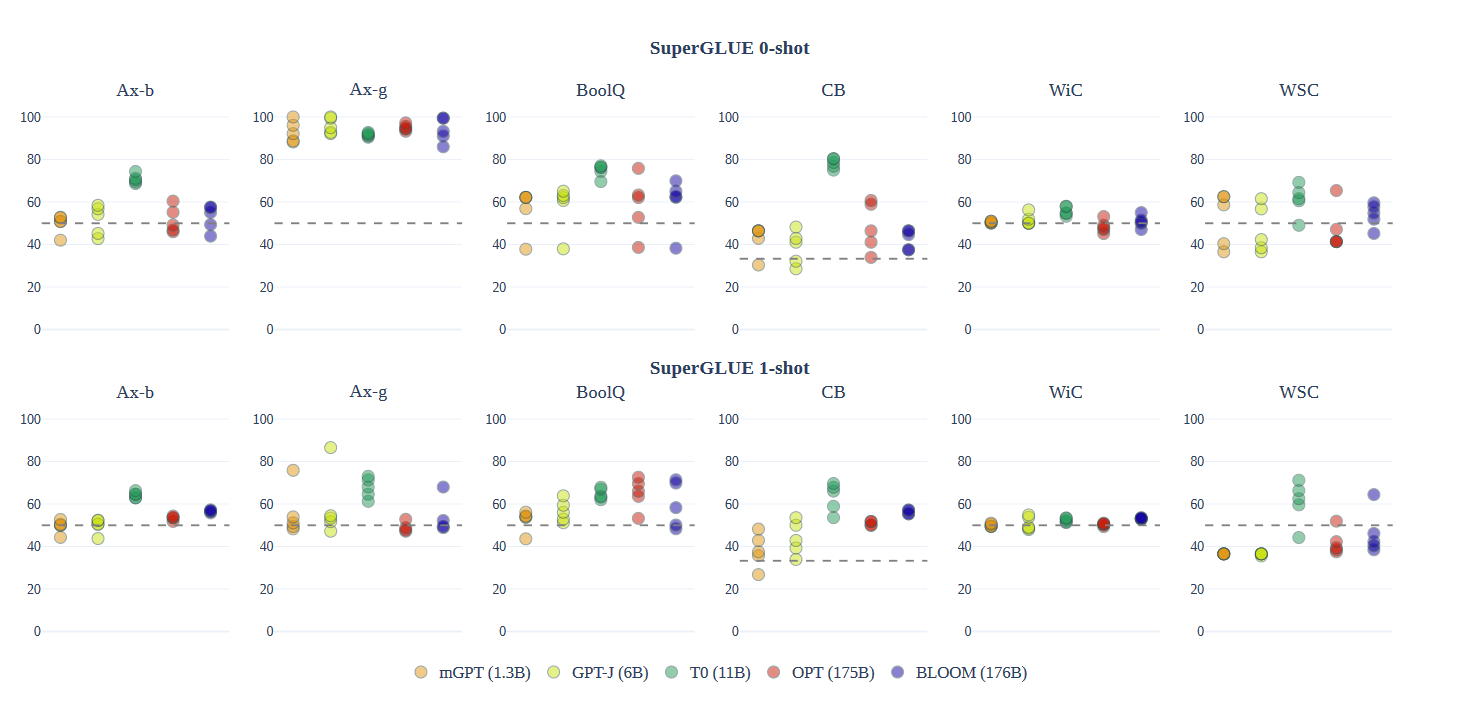
上图展示了在SuperGLUE上的零样本和单样本性能。在两种设置下,在蕴含任务(BoolQ和CB)上,BLOOM、T0、OPT和GPT-J的表现都远高于随机水平。
随着模型从零样本到单样本的转变,所有提示和模型的变异性都减少了,性能略有且不一致地提高。值得注意的是,BLOOM在从零样本到单样本的转变中,性能提升比其他可比模型更大,尽管它在零样本设置中通常落后于OPT,但在单样本设置中与之匹配或超越了OPT,尽管它仅部分地用英语进行了训练。这可能是因为多语言模型在输入和输出语言的上下文更长时,对语言的确定性更高。
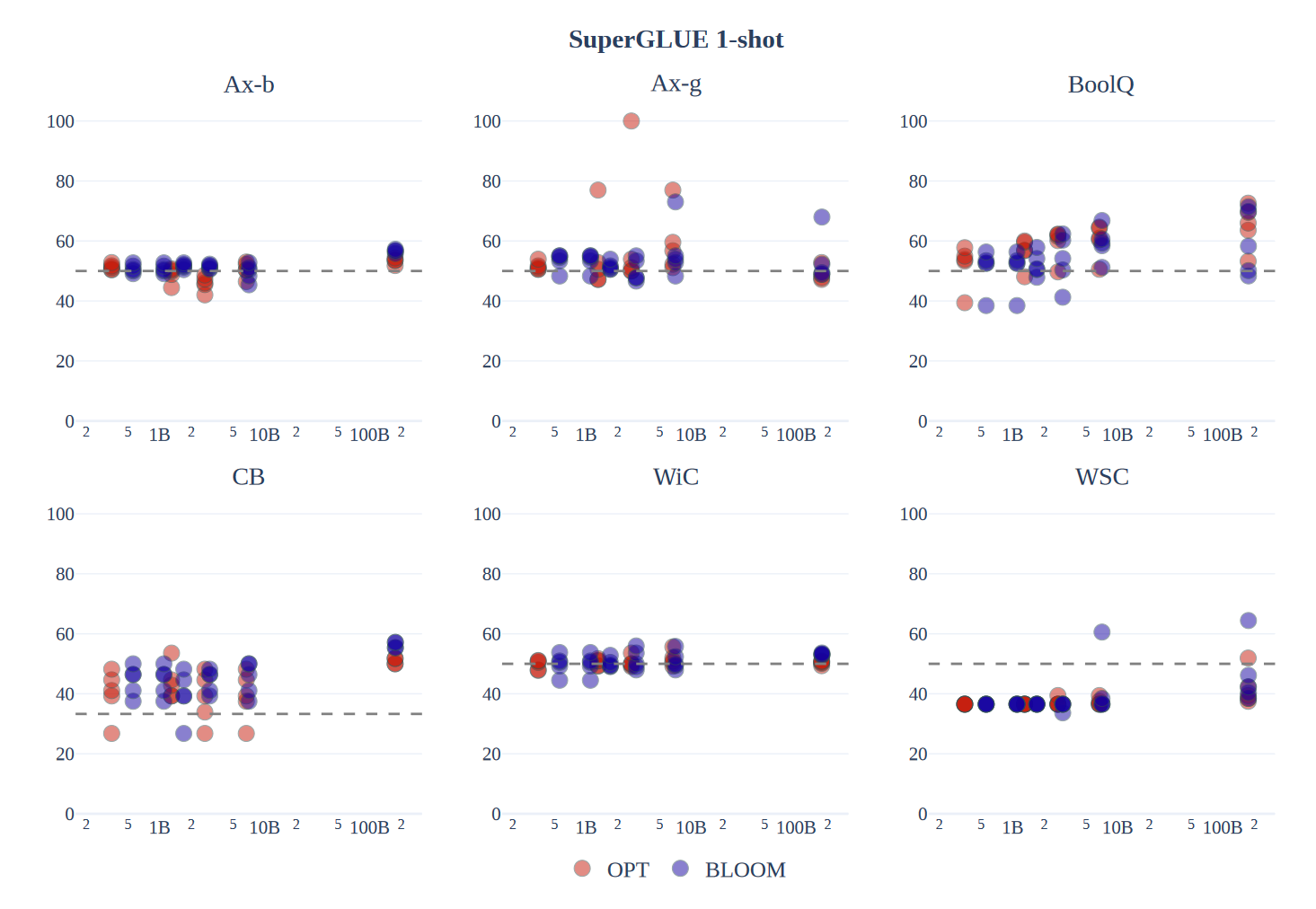
作为基线,论文还测量了相似大小的OPT模型(从350M参数到175B参数)的平均单样本准确率。上图展示了每个提示在每个任务上的准确率随模型规模的变化。OPT和BLOOM模型家族随着规模的增加略有提升,只有超过20亿参数的模型显示出信号,并且在所有任务上没有一致的家族间差异。在单样本设置中,BLOOM176B在Ax-b、CB、WSC和WiC上领先于OPT-175B,并在其他任务上与之匹配,这表明多语言性并不限制BLOOM在零样本设置中对仅英语任务的性能。
机器翻译
WMT数据集
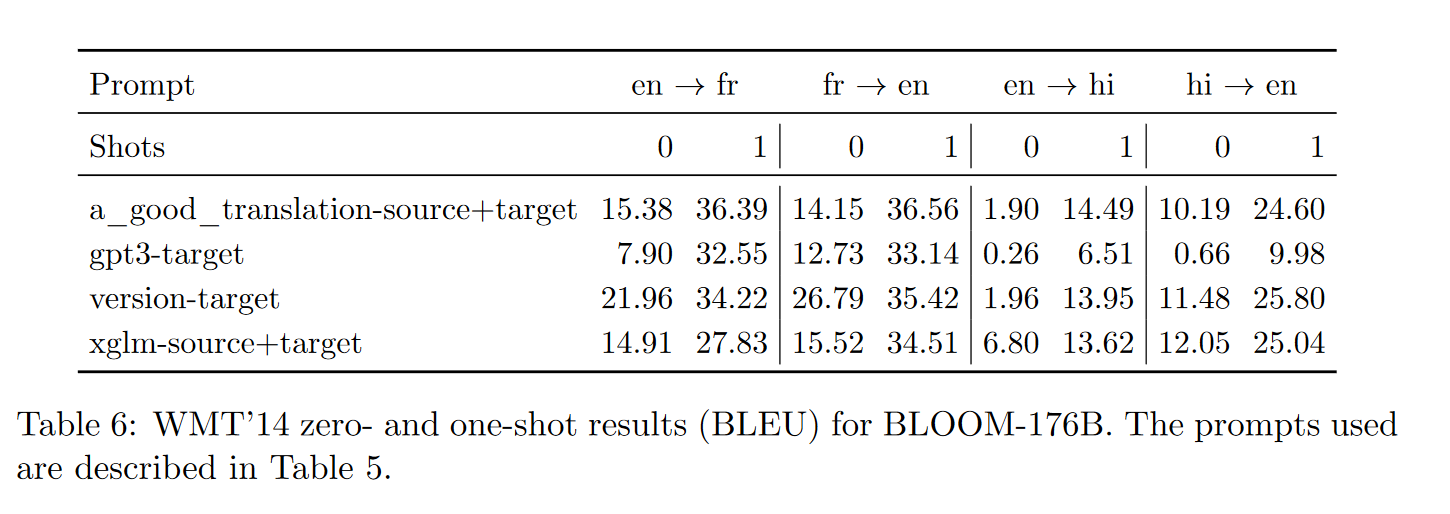
上表给出了BLOOM-176B在零样本和单样本设置下的WMT结果。最佳提示往往是更详细的提示;a_good_translation-source+target、gpt3-target、version-target、xglm-source+target提示中,version-target提示始终表现更好,而gpt3-target和xglm-source+target提示的性能非常差,尤其是在零样本设置下。在单样本设置下,BLOOM在正确的提示下可以执行有能力的翻译,尽管它落后于专门的(监督)模型,如M2M-100(英语→法语的BLEU得分为43.8,法语→英语的BLEU得分为40.4,而BLOOM的BLEU得分分别为34.2和35.4)。观察到的两个主要问题,特别是在零样本设置下,是(i)过度生成和(ii)未生成正确的语言(这是良好翻译的明显前提)。随着少样本示例数量的增加,这两个方面都得到了极大的改善。
DiaBLa数据集
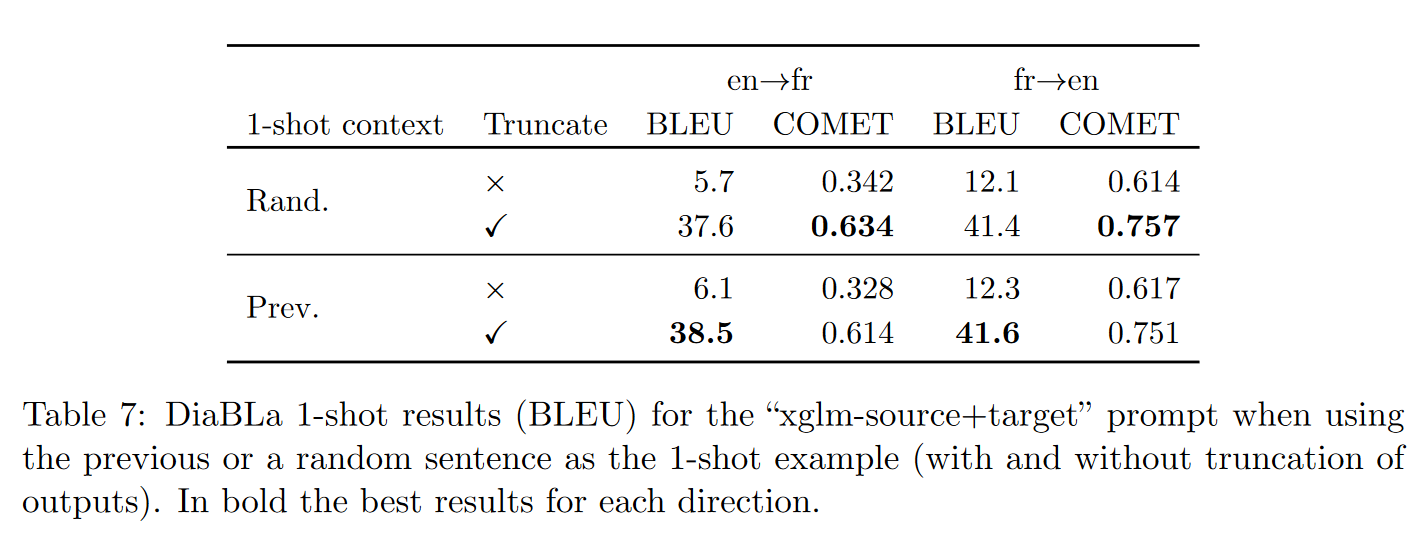
上表展示了使用DiaBLa(一个非正式双语对话的平行数据集)进行语言上下文测试的结果。在单样本上下文中,使用“xglm-source+target”提示,比较了使用随机测试集示例作为单样本示例与使用前一个对话话语的效果。鉴于观察到的过度生成问题,为了独立于过度生成评估预测质量,论文报告了原始输出和应用自定义截断函数后的结果。自动结果并不明确,得分差异不大(BLEU分数在前一个上下文中较高,但COMET分数较低)。尽管如此,预测本身有证据表明模型能够利用单样本示例的上下文来进行翻译选择。
Flores数据集
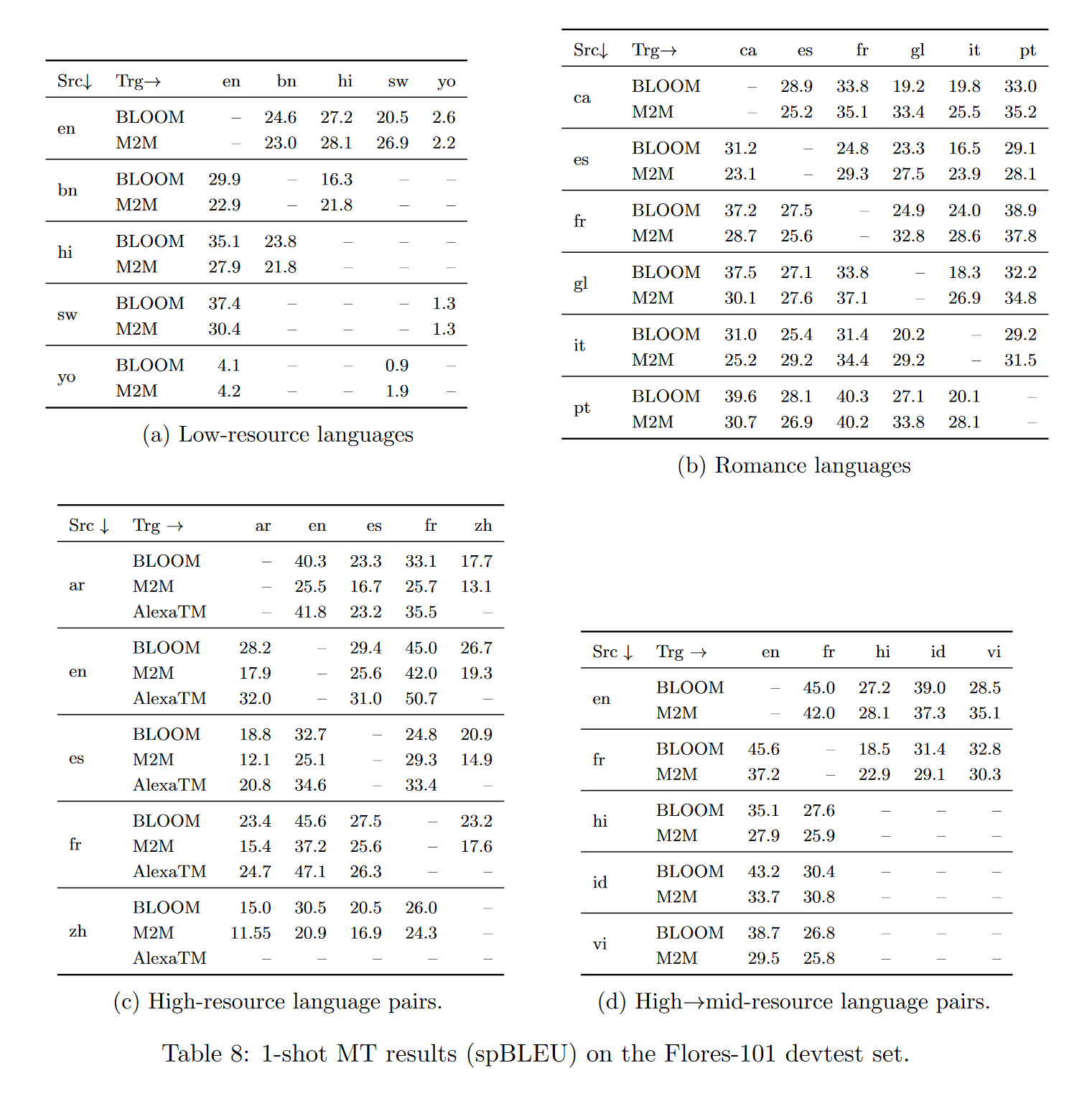
在单样本设置下,使用“xglm-source+target”提示在Flores-101开发测试集上测试了几种语言方向。单样本示例从开发集中随机选取。将结果分为低资源语言对(表8a)、罗曼语族相关语言之间(表8b)、高资源语言对(表8c)和高到中等资源语言对(表8d)。
根据语言在ROOTS中的表示,语言被分类为低资源、中等资源和高资源。与M2M-100模型的监督结果进行比较,该模型的参数为615M。此外,还与高资源语言对的样本AlexaTM结果进行比较。在单样本设置下,高资源语言之间的翻译和从高资源到中等资源语言的翻译结果普遍良好,表明BLOOM具有良好的多语言能力,即使在不同文字之间(如拉丁文(或扩展拉丁文)、中文、阿拉伯文和天城文之间)也是如此。与监督的M2M-100模型相比,结果往往相当,有时甚至更好,并且在许多情况下与AlexaTM的结果相当。
许多低资源语言的翻译质量良好,可与监督的M2M模型相媲美,甚至略好。然而,斯瓦希里语和约鲁巴语之间的翻译结果非常差,这两种语言在BLOOM的训练数据中存在但代表性不足(每种语言<50k个标记)。这与罗曼语(因此是相关语言)之间的翻译结果形成对比,后者的结果普遍良好,包括加利西亚语(glg)的翻译,该语言未包含在训练数据中,但与葡萄牙语(por)等其他罗曼语有许多相似之处。然而,这确实对BLOOM在训练中包含的那些代表性不足的低资源语言的质量提出了质疑。
文本摘要
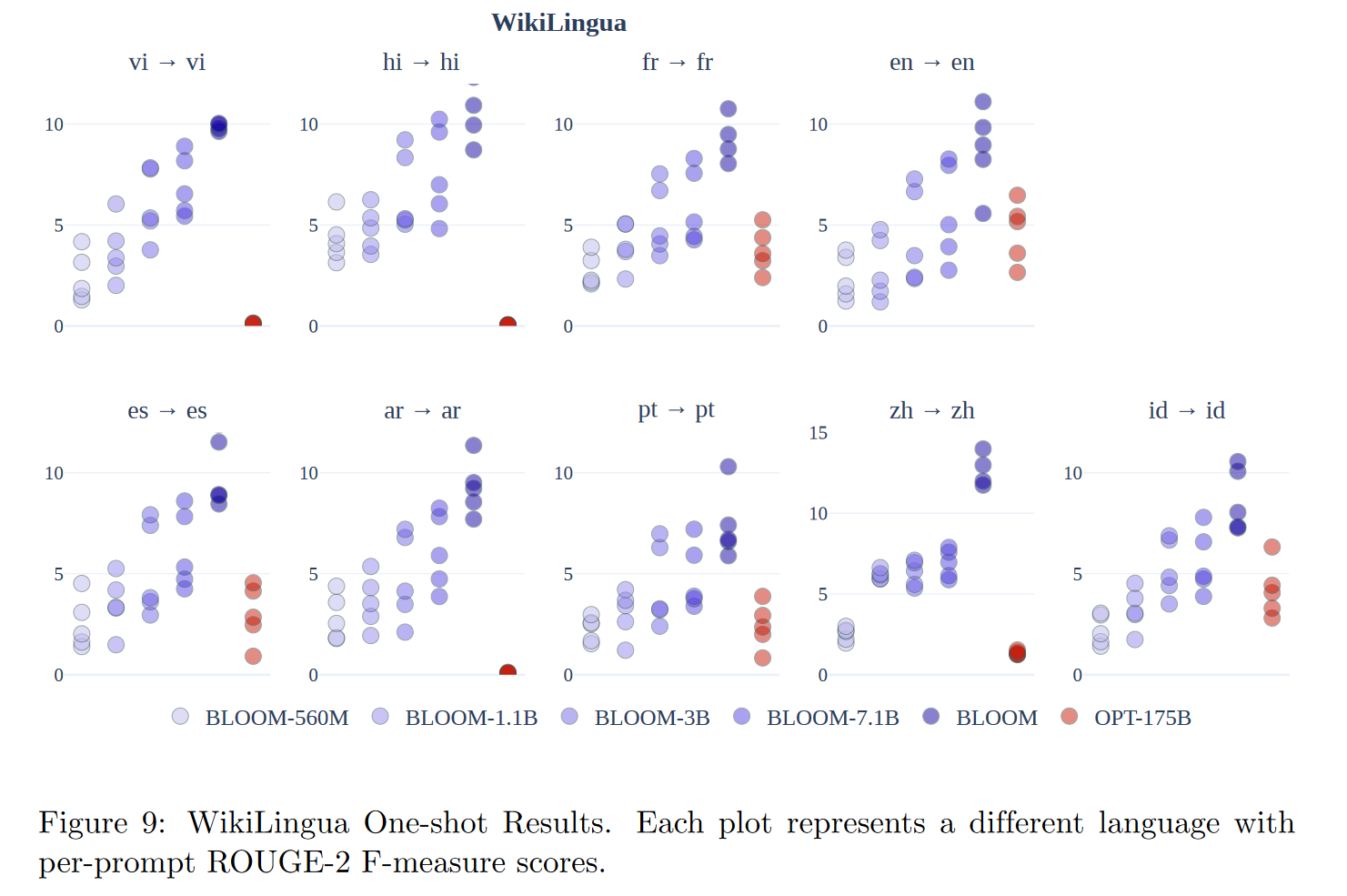
BLOOM在多语言摘要任务上的表现优于OPT,并且随着模型参数数量的增加,性能有所提高。
代码生成
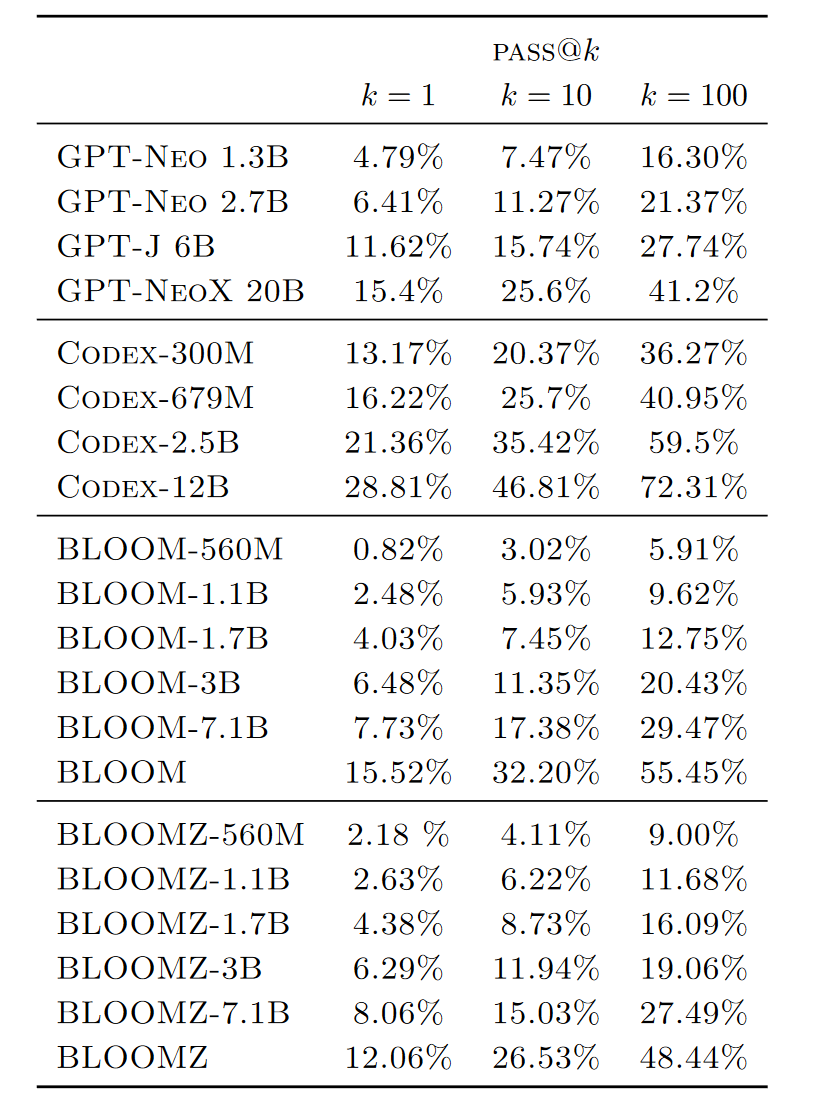
预训练的BLOOM模型的性能与在Pile上训练的类似大小的GPT模型相似。Pile包含英语数据和约13%的代码,这与ROOTS中的代码数据源和比例相似。仅在代码上微调的Codex模型明显强于其他模型。多任务微调的BLOOMZ模型在BLOOM模型上没有显著改进。
多任务微调
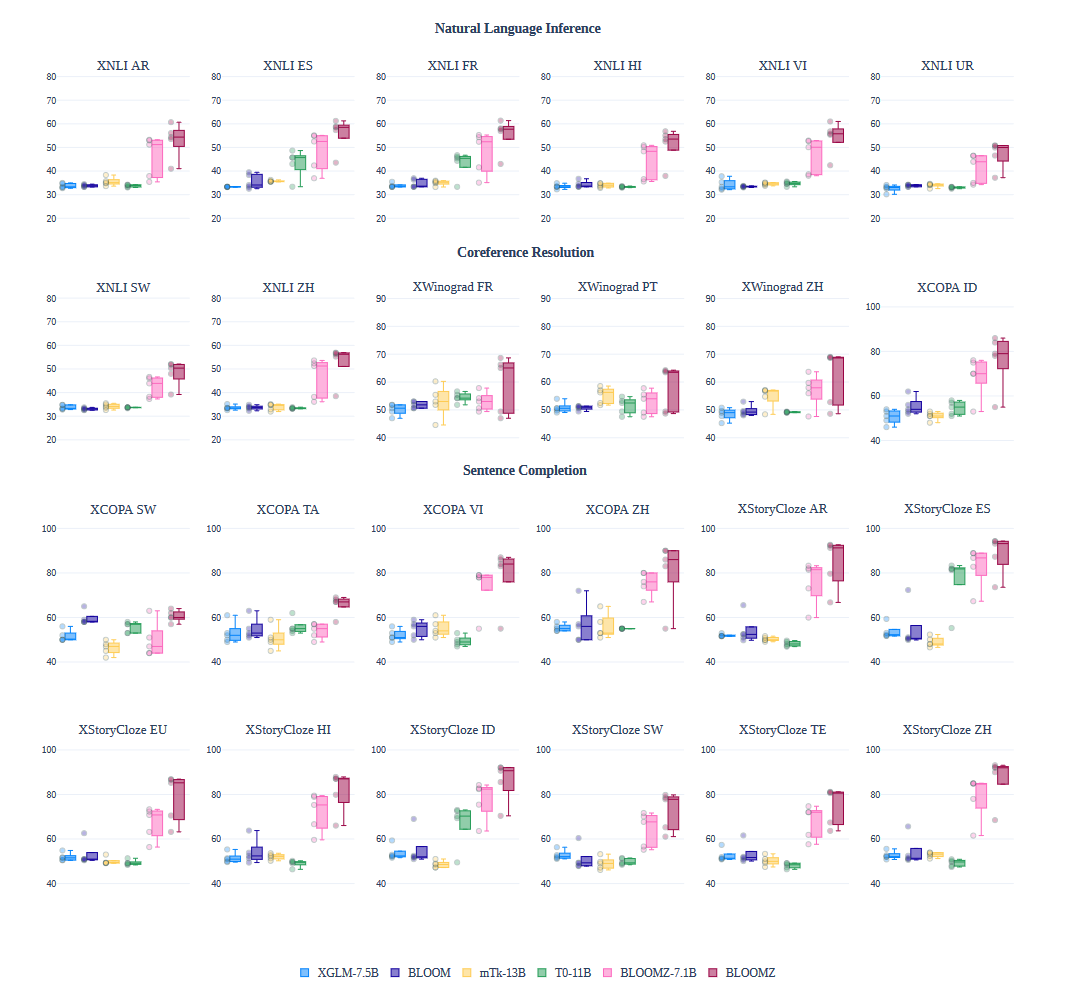
使用xP3语料库对BLOOM模型进行了多语言多任务微调。发现零样本性能显著提高。上图比较了预训练的BLOOM和XGLM模型与多任务微调的BLOOMZ、T0和mTk-Instruct的零样本性能。BLOOM和XGLM在NLI(XNLI)上的性能接近33%的随机基线,在指代消解(XWinograd)和句子补全(XCOPA和XStoryCloze)上的性能接近50%的随机基线。经过多语言多任务微调(BLOOMZ)后,零样本性能在描绘的保留任务上显著提高。尽管T0也是多任务微调的,但由于它是一个单语英语模型,因此在显示的多语言数据集上表现不佳。
使用 MindNLP 进行模型评估
本文代码全部开源,已经上传到代码仓库。
BLOOM MindNLP代码生成评估代码:https://github.com/ResDream/BLOOM2CodeGeneration
我们以Bloom 3B为例,使用MindNLP完成代码生成任务。
数据集
实验思路和论文一致,我们使用HumanEval数据集,HumanEval 数据集是由 OpenAI 开发的一个用于评估代码生成模型的基准数据集。它旨在测试模型在生成正确、高效且可运行的代码方面的能力。HumanEval 数据集包含了一系列编程问题,每个问题都附带了问题的描述、输入输出示例以及一个或多个测试用例。
生成代码
import json
from mindnlp.transformers import AutoModelForCausalLM, AutoTokenizer
import mindspore
from tqdm import tqdm
# 加载模型和分词器
model_path = "bigscience/bloom-7b1"
model = AutoModelForCausalLM.from_pretrained(model_path, ms_dtype=mindspore.float16, mirror="huggingface")
tokenizer = AutoTokenizer.from_pretrained(model_path, mirror="huggingface")
# 读取数据集文件
input_file_path = "./data/human-eval.jsonl"
output_file_path = "./results/human-eval-output.jsonl"
# 定义生成样本的数量
k = 100
# 打开输出文件
with open(output_file_path, "w") as output_file:
# 逐行读取输入文件
with open(input_file_path, "r") as input_file:
lines = input_file.readlines()
for line in tqdm(lines, desc="Generating Code"):
# 解析每一行的JSON数据
data = json.loads(line)
task_id = data["task_id"]
prompt = data["prompt"]
# 生成多个代码样本
for _ in range(k):
inputs = tokenizer(prompt, return_tensors="ms")
outputs = model.generate(
inputs.input_ids,
do_sample=False, max_length=2048,
# temperature=0.8, top_k=2, repetition_penalty=1.5
)
completion = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 构建输出结果
output_data = {
"task_id": task_id,
"completion": completion
}
# 将结果写入输出文件
output_file.write(json.dumps(output_data) + "\n")
print("生成完成,结果已保存到", output_file_path)
Pass@K指标
Pass@k 是一种用于评估代码生成模型性能的指标,特别是在 HumanEval 数据集等基准测试中广泛使用。Pass@k 指标衡量的是在模型生成 k 个候选代码样本中,至少有一个样本能够通过所有测试用例的概率。
定义
给定一个编程问题,模型生成 k 个候选代码样本。Pass@k 的定义如下:
- 通过率:在
k个候选代码样本中,至少有一个样本能够通过所有测试用例的概率。
计算方法
假设模型生成了 k 个候选代码样本,并且每个样本通过所有测试用例的概率为 p。那么 Pass@k 可以通过以下公式计算:
Pass@k
=
1
−
(
1
−
p
)
k
\text{Pass@k} = 1 - (1 - p)^k
Pass@k=1−(1−p)k
其中:
p是单个样本通过所有测试用例的概率。k是生成的候选代码样本数量。
解释
-
高
Pass@k值:表示模型生成的代码样本中,有较高的概率至少有一个样本能够通过所有测试用例。这意味着模型在生成正确代码方面表现较好。 -
低
Pass@k值:表示模型生成的代码样本中,通过所有测试用例的概率较低。这意味着模型在生成正确代码方面表现较差。
对于Pass@k的计算,我们使用如下代码进行计算:
from collections import defaultdict, Counter
from concurrent.futures import ThreadPoolExecutor, as_completed
from typing import List, Union, Iterable, Dict
import itertools
import numpy as np
import tqdm
from human_eval.data import HUMAN_EVAL, read_problems, stream_jsonl, write_jsonl
from human_eval.execution import check_correctness
def estimate_pass_at_k(
num_samples: Union[int, List[int], np.ndarray],
num_correct: Union[List[int], np.ndarray],
k: int
) -> np.ndarray:
"""
Estimates pass@k of each problem and returns them in an array.
"""
def estimator(n: int, c: int, k: int) -> float:
"""
Calculates 1 - comb(n - c, k) / comb(n, k).
"""
if n - c < k:
return 1.0
return 1.0 - np.prod(1.0 - k / np.arange(n - c + 1, n + 1))
if isinstance(num_samples, int):
num_samples_it = itertools.repeat(num_samples, len(num_correct))
else:
assert len(num_samples) == len(num_correct)
num_samples_it = iter(num_samples)
return np.array([estimator(int(n), int(c), k) for n, c in zip(num_samples_it, num_correct)])
def evaluate_functional_correctness(
sample_file: str,
k: List[int] = [1, 10, 100],
n_workers: int = 4,
timeout: float = 3.0,
problem_file: str = HUMAN_EVAL,
):
"""
Evaluates the functional correctness of generated samples, and writes
results to f"{sample_file}_results.jsonl.gz"
"""
problems = read_problems(problem_file)
# Check the generated samples against test suites.
with ThreadPoolExecutor(max_workers=n_workers) as executor:
futures = []
completion_id = Counter()
n_samples = 0
results = defaultdict(list)
print("Reading samples...")
for sample in tqdm.tqdm(stream_jsonl(sample_file)):
task_id = sample["task_id"]
completion = sample["completion"]
args = (problems[task_id], completion, timeout, completion_id[task_id])
future = executor.submit(check_correctness, *args)
futures.append(future)
completion_id[task_id] += 1
n_samples += 1
assert len(completion_id) == len(problems), "Some problems are not attempted."
print("Running test suites...")
for future in tqdm.tqdm(as_completed(futures), total=len(futures)):
result = future.result()
results[result["task_id"]].append((result["completion_id"], result))
# Calculate pass@k.
total, correct = [], []
for result in results.values():
result.sort()
passed = [r[1]["passed"] for r in result]
total.append(len(passed))
correct.append(sum(passed))
total = np.array(total)
correct = np.array(correct)
ks = k
pass_at_k = {f"pass@{k}": estimate_pass_at_k(total, correct, k).mean()
for k in ks if (total >= k).all()}
# Finally, save the results in one file:
def combine_results():
for sample in stream_jsonl(sample_file):
task_id = sample["task_id"]
result = results[task_id].pop(0)
sample["result"] = result[1]["result"]
sample["passed"] = result[1]["passed"]
yield sample
out_file = sample_file + "_results.jsonl"
print(f"Writing results to {out_file}...")
write_jsonl(out_file, tqdm.tqdm(combine_results(), total=n_samples))
return pass_at_k
实验结果
论文中的结果为:
| Model | PASS@k=1 | PASS@k=10 | PASS@k=100 |
|---|---|---|---|
| BLOOM-3B | 6.48% | 11.35% | 20.43% |
基于MindNLP的复现实验后的结果为:
| Model | PASS@k=1 | PASS@k=10 | PASS@k=100 |
|---|---|---|---|
| BLOOM-3B | 2.44% | 7.32% | 17.6% |
基于HuggingFace的Transformers的复现实验后的结果为:
| Model | PASS@k=1 | PASS@k=10 | PASS@k=100 |
|---|---|---|---|
| BLOOM-3B | 3.05% | 8.53% | 16.5% |
可以看到,使用Transformers和MindNLP的结果相差不大,平均误差只有0.64%。与论文结果出现差距可能是由于提示的差别,并且没有探索BLOOM模型生成代码的最优超参数组(topk,采样方式,温度等)导致的。
总结
BLOOM模型是超大规模语言模型早期的探索。虽然放在现在来看存在一些技术上的不成熟或者不明智的地方,但它为后续的研究和开发奠定了坚实的基础。BLOOM模型的出现标志着人工智能领域在自然语言处理方面迈出了重要的一步,尤其是在处理复杂文本和生成高质量内容方面取得了显著进展。
首先,BLOOM模型的规模和复杂性在当时是前所未有的。它采用了大量的参数和深度学习架构,使得模型能够捕捉到语言中的细微差别和复杂模式。这种大规模的模型设计为后来的百花齐放的开源大模型提供了宝贵的经验,尤其是在如何有效管理和优化大规模参数方面。
其次,BLOOM模型在多语言处理方面也取得了突破。它不仅能够处理英语等主流语言,还能够理解和生成多种非英语语言的文本。这种多语言能力的提升为全球范围内的应用提供了可能性,尤其是在跨文化交流和多语言内容生成方面。
然而,BLOOM模型也存在一些明显的不足。例如,模型的训练成本极高,需要大量的计算资源和时间。此外,模型的生成结果有时会出现不准确或不连贯的情况,尤其是在处理长文本或复杂语境时。这些问题在后续的模型中得到了改进,但BLOOM模型的早期探索为这些改进提供了重要的参考。
总的来说,BLOOM模型虽然在技术上存在一些不成熟的地方,但它的出现推动了超大规模语言模型的发展,为后续的研究和应用开辟了新的道路。随着技术的不断进步,我们有理由相信,未来的语言模型将会更加智能、高效和可靠,为人类社会带来更多的便利和创新。