题目:SpecInfer: Accelerating Large Language Model Serving with Tree-based Speculative Inference and Verification
链接:https://arxiv.org/abs/2305.09781
本文提出了构建token tree的方式、引入了基于树的并行解码机制。
SSM推理
就是先让小模型,文中成为SSM,生成一个token tree。可以是一个小模型生成一个树,也可以是多个小模型每个生成一个序列,然后把几个序列合成一个树。
关于一个小模型生成一个树(扩展)的细节:
-
对于LLM和SSM,虽然二者单步推理的结果可能不一样,但是LLM的结果往往是在SSM的tok-k个token中。实验表明,对于贪心解码,top-5的命中率为80%-90%,而随机解码能达到97%
-
但是如果使用top-k且不加限制,会导致指数级增长,比如到第三个token时就有个候选。因此,需要指定每一步推理中token扩展的数量,<2,2,1>表示前两次推理时每次扩展两个token,第三次推理时每次扩展一个token,也就是最终会产生个序列。
-
关于扩展的方案,文中提到:从SSM动态扩展令牌树是一个开放的研究问题,超出了本文的范围,我们将其作为未来的工作。
关于多个小模型每个生成序列后合并(融合)的细节:
-
使用文本语料作为输入,让LLM生成token序列。之后使用这些token序列样本对每个SSM进行逐一微调
-
逐一微调的过程是:先微调完一个SSM,然后把SSM的输出与LLM输出相同的样本进行过滤;剩下的样本去微调下一个SSM。这样是为了保证每一个SSM的推理结果能尽可能少的重叠
LLM验证
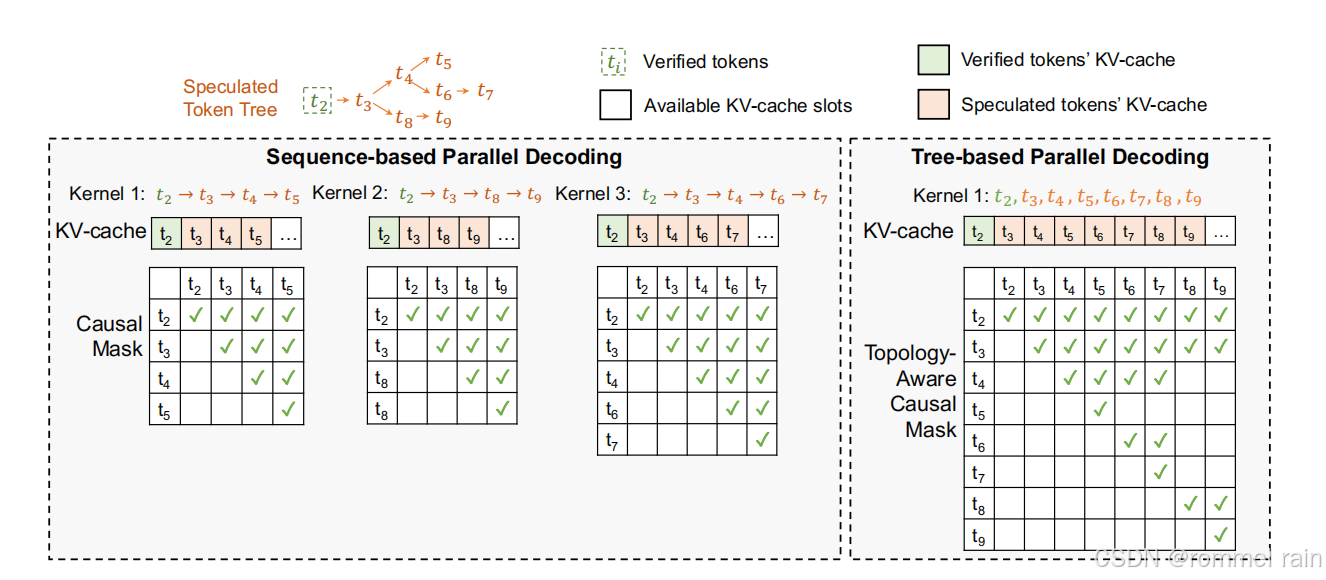
LLM的作用就变成了验证这个token tree。在验证的过程中,使用了基于树的并行解码机制,也就是树状注意力。下面是具体内容:
-
在普通的自注意机制中,每个token在计算对其他token注意力时,会mask掉自己后面的序列,也就是对后面token的注意力为负无穷
-
因此,只要某个token不在自己当前序列的前方,那么就不去注意它
-
下图右边展示了tree attention应该mask掉哪些token。比如,它所在的序列是,所以像这种不和它在同一序列当中的,就不需要考虑注意力。
-
涉及到KV cache,使用深度优先进行更新缓存,也就是对应下图的顺序
文中提及了一些SpecInfer的优点,比如节省访存时间、减少推理延迟,这些优点也是speculative decoding所具备的。有没有其他SD不具备的优点?那就是:对于普通的SD,小模型一次只能预测一个序列,所以每步推理只有一个候选,这会导致LLM验证时拒绝的概率较高;而SpecInfer通过token tree,可以在验证每一步推理时,从多个候选中进行挑选,降低了拒绝概率。
这篇文章感觉相当不错,工作量大(不是实验工作量大,而是创新工作量大),讲述的也清晰完整,后面还有系统设计,对SpecInfer进行了底层优化;最后还给了跑通代码的步骤(虽然放到readme文件里就可以了)