目录
前言
Math
System
Runtime
BigInteger
BigDecimal
Object
时间类Api
数据包装类
Arrays
正则表达式
lambda表达式
集合进阶
前言
java 大一的时候学的java基础,后来摆烂都忘了大部分 所以此笔记用于复习 在java中常用到的api 帮助我们解决·需求解决
Math
math是java核心包lang下的类无需引入
常用方法:
- 获取绝对值
Math.abs(-12)
- ceil 向上取整 数轴向正方向取整进1
ps:
System.out.println(Math.ceil(120.2));//121
System.out.println(Math.ceil(120.8));//121
System.out.println(Math.ceil(-12.2));//输出-12.0 不是-13
- floor向下取整 数轴左边(负)方向取整数进1
ps:
System.out.println(Math.floor(-13.2));//-14
System.out.println(Math.floor(13.2));//13
- 四舍五入
Math.round(4.5) - 比较俩个数值的较大值
Math.max(5,8)
底层其实是三元运算符号
public static int max(int a, int b) {
return (a >= b) ? a : b;
}
- 比较a,b的较小值 min(a,b)
底层逻辑类似
public static int min(int a, int b) {
return (a <= b) ? a : b;
}
-获取a的次幂 pow
System.out.println("5的2此方"+Math.pow(5,2));
System.out.println("5的-2此方"+Math.pow(5,-2));//1/5^2
System.out.println("5的1/2此方"+Math.pow(5,0.5));//更号5 但是不建议这样
- 更号运算
- sqrt平方
- cbrt 立方
System.out.println("------------------------");
System.out.println("跟更号4"+Math.sqrt(4));//开平方
System.out.println("8开立方根"+Math.cbrt(8));//立方根
- 随机数(0~1)
System.out.println("0~1之间的随机数值"+Math.random());//[0,1.0)
System.out.println("0~100之间的随机整数值"+Math.floor(Math.random()*100));//[0,100)+1 去掉小数值+1 才是 【0,100】
System
该类也是java核心包中的无需引入
-停止当jvm的进程静态方法exit
System.exit(0);//0正常停止jvm虚拟机 非0异常停止
- 获取当前系统本地时间搓毫秒
时间搓知识:时间搓 从1970 1月1日 0:0:0(时间原点)到现在的毫秒 我国在东八区
有8小时时差,所以是在标准时间搓的基础上加8小时时间毫秒值
System.out.println("当前时间搓:"+System.currentTimeMillis())
ps:该方法是获取当前虚拟机所在系统的时间搓,是在标准时间搓上已经获得计算的
- 数组拷贝
int[] arr1 = new int[10];//空数组
int[] arr2={1,2,3,4,5,6,7,8,9};
/**ps:
* srcpos :数据源索引
* destpos :目标数组索引
* 最后一个参数是拷贝多长
* 细节:1.如果都是基本数据类型 ,俩者的数据类型必须相同
* 2.如果数据源素组和目标数组都是引用类型,那么子类可以赋值给父类 因为应用数据类型拷贝的是数据的内存地址 赋值也是
* person person1 = new person( "John",15);
* person person2 = new person();
* person2=person1;
* person2.age=20;
* System.out.println(person1.age); 此时输出person1的age属性值是20 相同的内存地址 修改了其他引用类使用的值也会发生改变
*/
System.arraycopy(arr2,0,arr1,0,arr2.length);
for (int i = 0; i < arr1.length; i++) {
System.out.println(arr1[i] );//原素组长度为10 比数据源长 所以长出的一位是10
}
RunTime
Lang包下的java运行环境类
- .静态方法获取Runtime的对象
Runtime runtime = Runtime.getRuntime();
- 关闭虚拟机
runtime.exit(0);
System.exit(0)方法关闭虚拟机的底层就是运行环境关闭
public static void exit(int status) {
Runtime.getRuntime().exit(status);
}
- 获取当前系统获取cpu的线程数 availableProcessors
System.out.println("当先环境的运行线程数量:"+runtime.availableProcessors());
- 虚拟机可以获取的最大总内存大小 maxMemory
System.out.println("可以从当先操作系统中获取最多"+runtime.maxMemory()/Math.pow(1024,2)+"个mb内存");
- 获取虚拟机 在当前系统已经获取的内存大小 totalMemory
System.out.println("当前内存消耗:"+runtime.totalMemory()/1024/1024+"MB")
- 当前获取的内存还有多少空闲 freeMemory
System.out.println("当前虚拟机剩余空间大小:"+runtime.freeMemory()/1024/1024+"mb");//说明当前程序消耗内存4mb 消耗内存=totalmemory-freememory
- exec 运行系统指令
try {
Runtime.getRuntime().exec("notepad");//打开系统自带记事本
} catch (IOException e) {
e.printStackTrace();
}
BigInterger
java中的整数 byte 1字节 short 2字 int4字节 long 8b 1b=8bit,所以long可以有64位二进制位存储数字 第一位符号位,但是当long的范围也不够用时 就可以使用 bitInteger上限接近无限
- 实例化BigInteger方法
1.第一种范围构造方法 初始化
ps:bitInteger对象一旦创建内部数据无法改变和String一样
// 实际开发中用于初始化随机数
BigInteger bigInterger = new BigInteger(4, new Random());// Random对象 范围是 【0,2】 , 这里是实例化一个 (pram1的parm2幂此方)-1 范围的随机数 这里是0~15的随机数
2.第二种构造方法 制定初始化数值
ps :bit Innteger是整数初始化的时候这个字符串参数只能写整数
BigInteger b2 = new BigInteger("944444444555555555555555555555555555555555555555555551");//这里范围已经超过long了
3.通过静态方法Valueof实例化
BigInteger b3 = BigInteger.valueOf(99999);//参数的取值是根据long对象的范围决定的
该方法有一小细节:
当初始化值在 -16 ~16 时 采用类似单例模式 只会初始化一个对象 只是赋予引用地址(类似spring中的单列模式)
BigInteger b21 = BigInteger.valueOf(13);
BigInteger b22 = BigInteger.valueOf(13);
System.out.println(b21==b22);
结果:
一般建议使用第二个构造方法实例化 ,范围大无局限

- 加法
bitInteger的数据操作都是返回一个新的BigInteger对象
BigInteger bigInterger = new BigInteger(4, new Random())
BigInteger radd = bigInterger.add(BigInteger.valueOf(5))
- 减法
System.out.println(b21.subtract(BigInteger.valueOf(5)))
- 乘
BigInteger multiply = b21.multiply(BigInteger.valueOf(5));
System.out.println(multiply);
- 除法取商 divide
BigInteger divide = b21.divide(BigInteger.valueOf(5));
System.out.println(divide);
- 除法取余 divideAndRemainder
该方法返回的是一个BigInteger的数组,该数组在源码中长度为2
索引0是商,索引1是余数

BigInteger[] x = b21.divideAndRemainder(BigInteger.valueOf(5));
System.out.println("商是:"+x[0]+"余数"+x[1]);
- 次幂
BigInteger pow = b2.pow(2);
- 较大值 和较小值
ps:比较是方法返回最大值 和较小值 不是新建对象
BigInteger moremax = b2.max(b21);
BigInteger min = b2.min(BigInteger.valueOf(15));
- 和其他整数类型的转换
BigInteger bigIntegerdemo = new BigInteger("55555");
int i = bigIntegerdemo.intValue();
long l = bigIntegerdemo.longValue();
double d= bigIntegerdemo.doubleValue();
System.out.println("int:"+i);
System.out.println("long:"+l);
System.out.println("double:"+d);
运行结果:

BigDecimal
和BigInteger一样都是为了解决数据类型的范围或者精度缺陷而使用的数据类,有着相同的特点,创建后不可改变,且运算对象是返回一个崭新的数据,构造方法和操作方法都大体相同
当使用小数进行加减乘除时候 计算机转换为二进制时候会出现精度损失 所以才需要该api
用于高精度的运算,比如基金,银行等高数据精度运算
- BigDecimal 的实例化
1.通过double类型的小数创建对象 ps:精度会出现误差
BigDecimal b = new BigDecimal(0.01);
System.out.println(b);
误差较大 ,不适用
2. 构造方法传递字符串
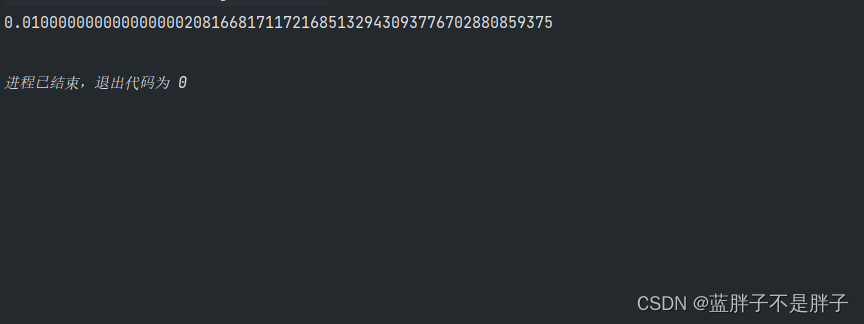
BigDecimal b2 = new BigDecimal("0.00001");//精度过高时候会采用16精
System.out.println(b2);
3.通过静态方法实列化对象
BigDecimal b3 = BigDecimal.valueOf(10.00005);
System.out.println(b3);
- 加
System.out.println("加法:"+b2.add(BigDecimal.valueOf(12.5)));
- 减
System.out.println("减法:"+b2.subtract(BigDecimal.valueOf(12.5)));
- 乘
System.out.println("乘法:"+b2.multiply(BigDecimal.valueOf(12.5)));
- 除
System.out.println("除法(只取余商):"+b2.divide(BigDecimal.valueOf(12.5)));
System.out.println("除法商:"+b2.divideAndRemainder(BigDecimal.valueOf(12.5))[0]+":::除法余:"+b2.divideAndRemainder(BigDecimal.valueOf(12.5))[1]);//和BigInteger一样返回是个数组
- 除法规定小数点后几位
/**
* @param1 被除数
* @param2 保留小数点后几位
* @param3 表示小数点精度最后一位四舍五入规则up表示原理数轴0的方向进1 down反之 ,ceil向正方向进1,floor表示精度向负方向进1,half_up 数学中的标准的=四舍五入 ,
*/
System.out.println("保留小数点三位除法:"+b4.divide(BigDecimal.valueOf(3),3,BigDecimal.ROUND_UP));
System.out.println(b2.max(BigDecimal.valueOf(12.5)));
System.out.println(b2.min(BigDecimal.valueOf(12.5)));
Object
Object是所有类的超类 其中有几个常用方法
- tostring
当输出实例化对象的时候默认调用的就是toString
源码:
输出类名和hash值
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
实际开发中我们重写该方法输出成员属性:
@Override
public String toString() {
return "student{" +
"score=" + score +
'}';
}
- equals 比较俩个对象(引用类型)是否相等
源码:
public boolean equals(Object obj) {
return (this == obj);
}
// 对于基础类型的变量和常量:变量和引用存储在栈中,常量存储在常量池中。
//引用对象内存申请在堆中 地址在栈 地址指向内存
//equals方法实际就是==比较俩个对象的地址
student s1 = new student();
s1.age=4;s1.name="test";s1.score=79;
student s2 = new student();
s2.age=4;s2.name="test";s2.score=79;
//俩个实例化对象地址不同 false
System.out.println("调用equals方法比较"+s1.equals(s2));//ideal重写写后可以比较属性 true euals本来比较的是引用地址
输出结果:

- 对象克隆 对象拷贝
User Originuser = new User("user1", "{等级:200,攻击力:100,防御:20}", 1656,Signs);
try {
User clone2 = (User)Originuser.clone();
System.out.println("原来对象u1"+Originuser);
System.out.println("克隆对象u2"+clone2);
System.out.println(Originuser==clone2);//克隆的是属性 内存地址不通
//PS:细节这种克隆为浅克隆当对象中有引用数据时候 clone的是内存地址 基本数据类型 拷贝数据值·引用类型拷贝地址值
clone2.Signs[8]=999;
System.out.println("这种克隆方式是浅克隆,引用对象克隆的是地址,所以克隆对象修改了引用属性,原对象也会改变"+Originuser.Signs[8]);
System.out.println(Originuser.Signs==clone2.Signs);//clone方法浅克隆的弊端 无法独立操作
// 深克隆会将所有属性都是进行数值克隆 引用对象也是 而Object的clone是浅克隆 深clone需要自己改写
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
- Obects 对象操作的工具类
常用方法能做到见名知意 不多做论述
java中表示时间的类
时间类在Jdk8做了 次更新 ,所以分二段讲解
1.jdk8之前
- Date时间类 时间的计算标准是格林威治时间 变为现在的时间标准
Date now=new Date();//空参数 表示当前时间
System.out.println("当前时间"+now);
输出格式
传参制定时间 对象(已过时)

Date currentTime = new Date(2008,5,30,11,32);
源码
@Deprecated
public Date(int year, int month, int date, int hrs, int min) {
this(year, month, date, hrs, min, 0);
}
构造参数为0L时候 就是时间原点
System.out.println("时间原点"+new Date(0L));//设置0L就是时间原点

- 时间格式化器 SimpleDateFormat
1.用于格式化Date对象
MM表示月 HH表示24的小时
System.out.println("当前时间:"+new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒 EE").format(new Date()))
官方文档:
2.用于解析文本时间 (要求格式符号必须对得上)
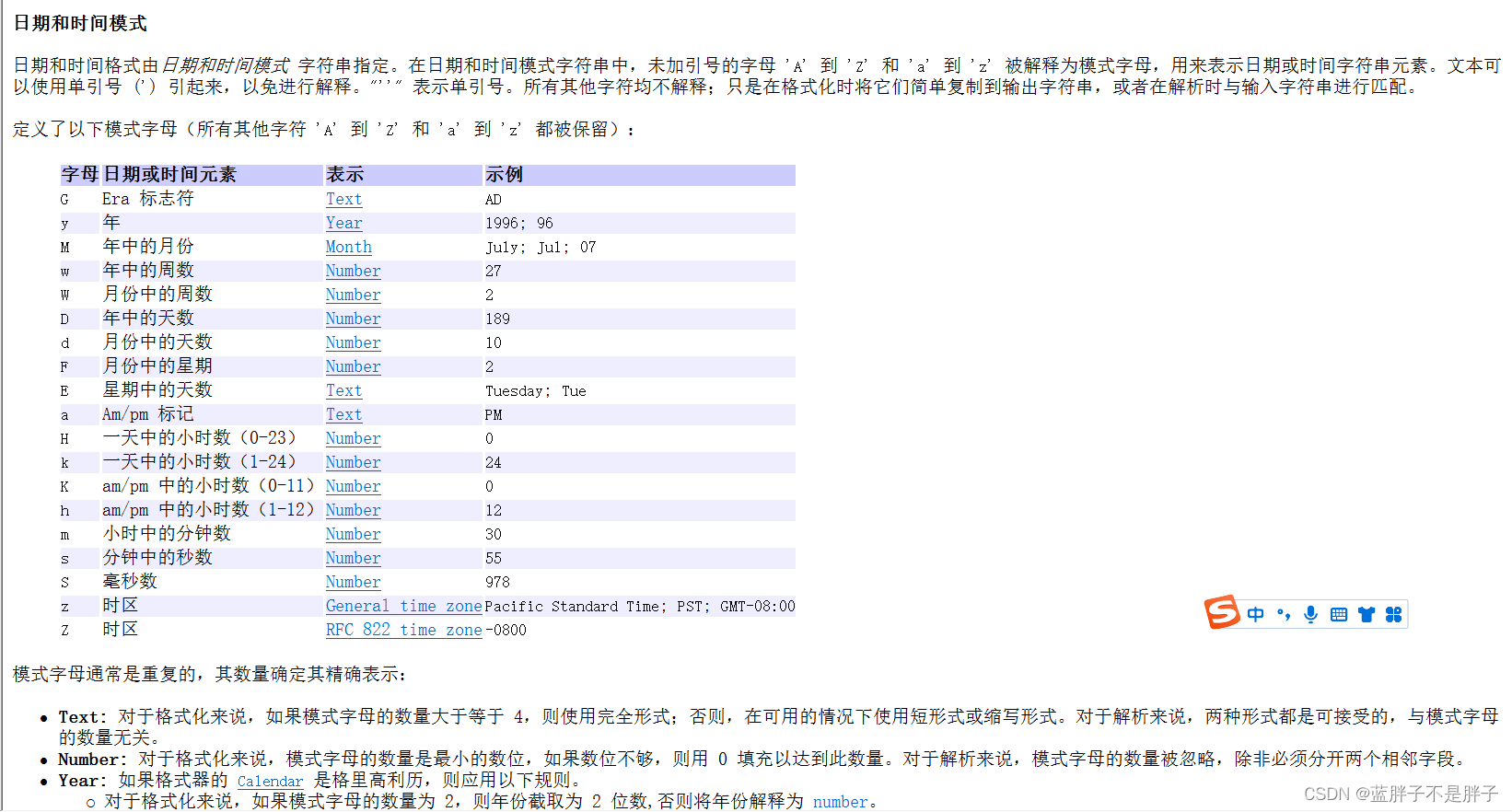
//作用2解析字符串时间
try {
Date date = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse("2013-07-24 23:11:11");//解析的时间又恢复原始的时间格式
System.out.println("解析的时间"+date);
} catch (ParseException e) {
e.printStackTrace();
}
- Calendar 日历类
System.out.println("==========================演示日历类 ==============");
Calendar calendar = Calendar.getInstance();//抽象类只能通过抽象类获取
System.out.println("当前是几月?"+calendar.get(Calendar.MONTH)+1);//根据系统所在的时区域不同获取日历对象 月:0-11 周日到-周六:1-7 周日是第一天
System.out.println(calendar.get(Calendar.DAY_OF_MONTH));
System.out.println("当前是本周"+(calendar.get(Calendar.DAY_OF_WEEK)-1)//0纪元 1年 2月 3一年的几周 4一月的第几周
);
);
该类的核心方法是 get 获取日历的各项数据 ,参数封装在了Calendar自身中
值得注意的是:月份是0-11,而在国外 周日才是一周的开始 所以 周日对应代码1 周一到周日:234561
2.jdk8 时间类
- zoneId类 表示时区
获取时区
ZoneId zoneId = ZoneId.systemDefault();//当前系统时区域
Set<String> availableZoneIds = ZoneId.getAvailableZoneIds();//获取所有时区
//获取指定时区
ZoneId of = ZoneId.of("America/Antigua");
- instant 时间搓类 所有的操作都是返回一个新的instant对象
该对象获取的是标准时间搓
1.now 当前时间搓(标准)
Instant instant = Instant.now();//2.1获取当前时间搓 标准到时间原点的时间搓 需要+8小时
System.out.println("当前的标准时间搓:"+instant);
2.atZone (指定时区的时间搓)
ZonedDateTime time = instant.atZone(ZoneId.of("Asia/Aqtau"));
System.out.println("制定的硅谷时间 搓为:"+time);
3.is 进行时间前后判断
Instant now1 = Instant.ofEpochMilli(0L);//该方法是获取实例化时间
Instant now2 = Instant.ofEpochMilli(1000L);//时间圆点+1s
boolean r = now1.isBefore(now2);
System.out.println("now1是否在now2之前:"+r);
System.out.println("now2是否在now1之后:"+now2.isAfter(now1));
4.时间搓进行运算
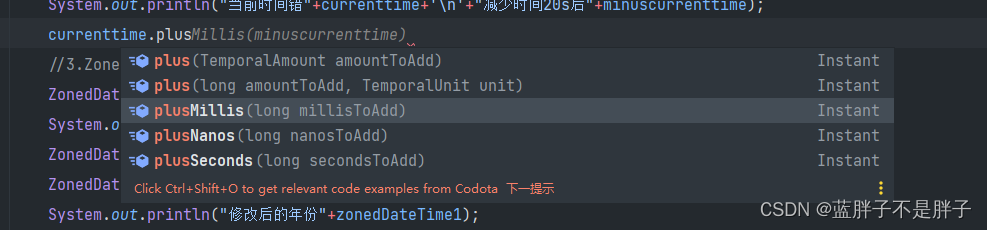
Instant currenttime = Instant.now();
Instant minuscurrenttime = currenttime.minusMillis(20000L);
System.out.println("当前时间错"+currenttime+'\n'+"减少时间20s后"+minuscurrenttime);
minus 减法,plus 则是加
5.带时区的时间搓
//.ZoneFateTime 带时区的时间类
ZonedDateTime now3 = ZonedDateTime.now();
System.out.println("获取带时区的时间对象"+now3);
ZonedDateTime zonedDateTime = now3.withMonth(1);//3.1with 修改某部分为固定数值
ZonedDateTime zonedDateTime1 = now3.withYear(2035);
System.out.println("修改后的年份"+zonedDateTime1);
- 格式化时间类
/**
* DateTimeFormatter 用于时间的格式化和解析
*/
//1.ofPattern
//获取时间对象
ZonedDateTime nowdate = Instant.now().atZone(ZoneId.of("Asia/Shanghai"));//指定时区 什么地方的应用对应时区不同
//解析/格式化
String date = DateTimeFormatter.ofPattern("yyyy年MM月dd日 HH:mm:ss").format(ZonedDateTime.now()); //用法和simpleDateFormatter一样
// String date = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss").format(nowdate); //用法和simpleDateFormatter一样
System.out.println("格式化的时间"+date);
是不是感觉特别繁琐 ,但是相对于之前增加的is方法可以进行对时间的判断
- 日历类
- localDate 系统时区的年月日期
System.out.println("当前系统所在年份日期"+LocalDate.now());
- LocalDate.of() 指定年月
System.out.println("申明指定时间"+LocalDate.of(2005,5,13));
3.localTime 当前分秒 使用场景秒杀活动纳秒级别
System.out.println("当前系统所时分秒"+LocalTime.now());
4.LocalDateTime 年月时分秒都详细包含
System.out.println("当前系统详细时间:"+LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy年MM月dd日 :HH时mm分ss秒")))
上面三个日历类都可以进行minus,plus,isxx,get等操作
-
时间比较工具类
1.Duration 时间间隔 s 纳秒
Duration duration = Duration.between(LocalTime.now(), LocalTime.of(5, 25, 29));
System.out.println(duration);
System.out.println("间隔了多少小时:"+duration.toHours());//砖换间隔
2.Period 年月日 时间单位
Period period = Period.between(LocalDate.now(), LocalDate.of(2005, 11, 29));//参数2减去参数1
System.out.println("间隔多少年{}"+period.getYears());
/3.ChronoUnit所有时间单位的间隔
通过静态方法选择时间单位
ChronoUnit.HOURS.between();
ChronoUnit.SECONDS.between();
可以这样使用因为底层使用到了枚举
mysql中的timestamp类型和java中的localdatetime刚好对应

基本数据的包装类
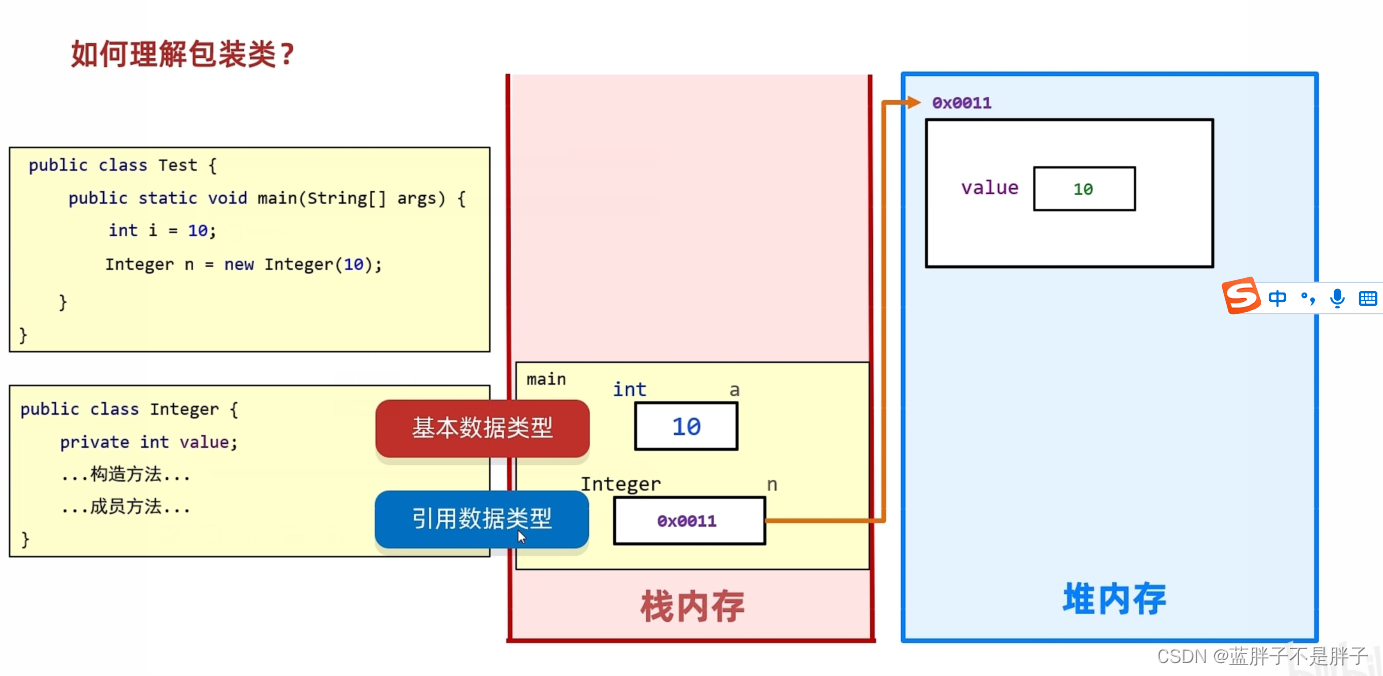
- 何为包装类 如何理解
包装类和引用对象一样,是把基础数据类型,封装在一个对象中的类.好处是可以传参更广,且集合只能存储引用类型
并且可以对基本数据类型进行各进制的封装 - 各个数据类型的包装类
处理int 和char 其他的包装类都是首字母大写,接下来演示Integer 作为代表
- 实例化 获取对象的方式

主要是构造方法和静态方法
但是俩种方式有区别 代码演示:
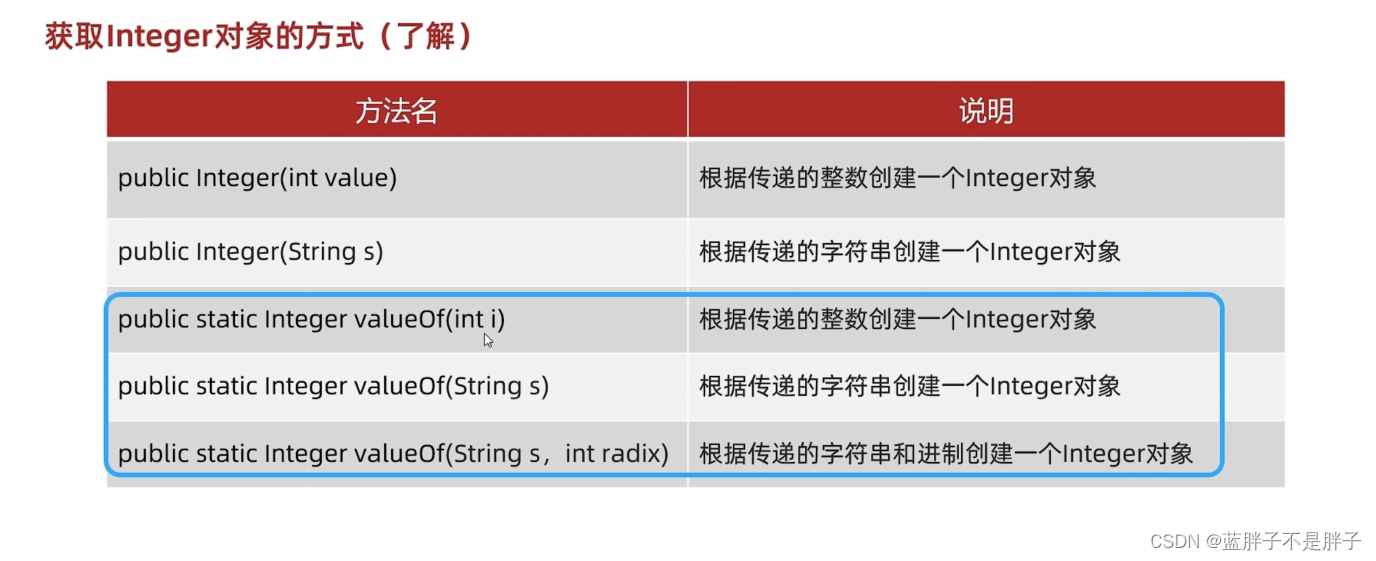
Integer i1 = Integer.valueOf("127");
Integer i2 = Integer.valueOf("127");
System.out.println(i1==i2);
Integer i3 = Integer.valueOf("128");
Integer i4 = Integer.valueOf("128");
System.out.println(i3==i4);
//创建新空间 地址肯定不同
Integer integer = new Integer("127");
Integer integer2 = new Integer("127");
System.out.println(integer==integer2);
输出结果:

可以通过==进行比较内存地址发现,其中new申请内存空间的方式实例化,肯定地址不同 而静态方法,127为什么俩个对象地址相同呢
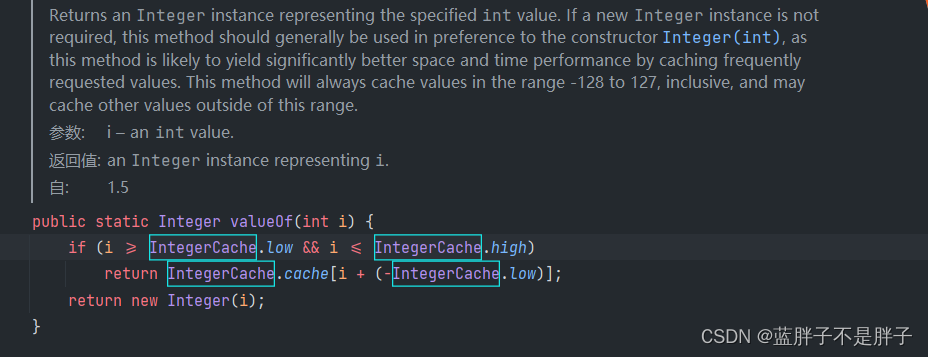
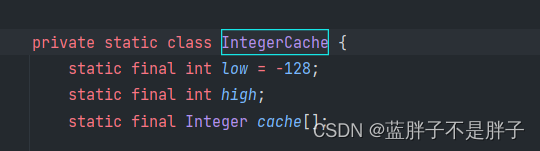
查看源码
发现范围在IntegerCache(缓存)的高地范围之间是直接返回 缓存
high被设计成127,这样在-128 到127这个常用区间运算,数据无须重复申请内存.
- 运算
int i3 = i2.intValue()+ i1.intValue();
因为引用对象无法直接运算 ,只能转为基本类型运算,这样代码量过于冗杂,所以jdk5以后实现了自动装箱(包装)和自动拆箱(数据转换),可以理解包装类就是数据本身了,大大便利了开发
- 自动装箱拆箱
ArrayList<Integer> arrayList1=new ArrayList<>();
Integer a=8;//可以直接申明数据
arrayList1.add(1);//默认int 和Integer是一种数据处理方式
arrayList1.add(a);
arrayList1.add(Integer.valueOf("2"));
arrayList1.add(3);
Integer x = arrayList1.get(0);
int y = arrayList1.get(0);//可以转换
System.out.println(x);
System.out.println(y);
ps:之前练习用到Scanner的next方法,说一下nest方法遇到空格和回车停止输入,nextline只有回车才停止输入,所以建议Scanner工具默认nextline方法控制台输入
- 包装转换进制

Arrays 数组工具类
属于util包下的工具类,简化数组开发,以下是常用方法
- tostring 将数组转换为字符串输出
Integer[] array = {2,45,44,34,6,78};
System.out.println("默认升序排序:"+Arrays.toString(array));
- (重点) sort 排序
Arrays.sort(array); //默认升序排序
也可以选择重载的方法自己书写排序规则() ,第二个参数是函数式接口 使用匿名内部类方式实例化对象,然后重写函数
/**
*重写的 Comparator(比较器) 中的compare(比较方法)
* @param1 a1表示无序序列中的便利的每一个参数 表示要插入的数据
* @param2 a2表示已经排好的有序序列中的便利的每一个参数 表示已经经过排序的数据
* @return 返回值值是负数 a1放在当a2之前,反之之后
*/
Arrays.sort(array, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;//降序排序
}
});
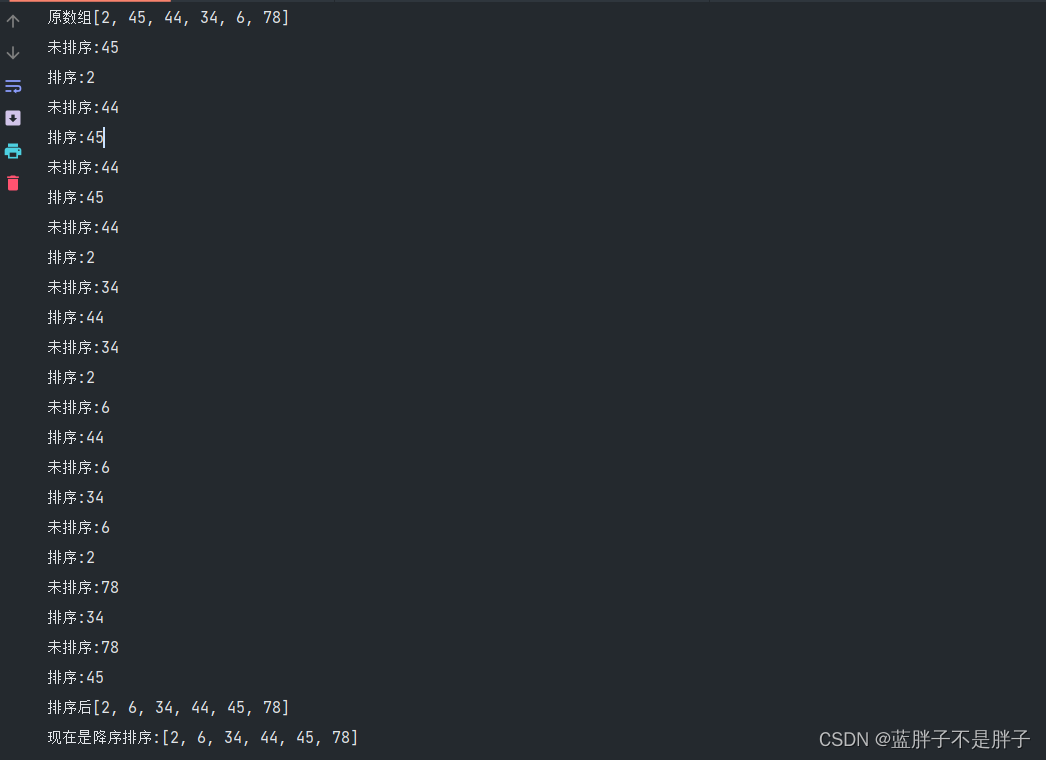
验证并且输出o1,o2
Integer[] array = {2,45,44,34,6,78};
Arrays.sort(array, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
System.out.println("未排序:"+o1);
System.out.println("排序:"+o2);
return o1-o2;//升序排序 也就是 sort参数的默认排序
}
});
输出结果:
采用快速排序算法,参数一-参数2升序,反之降序
- binarySearch 查找元素
细节:1.二分查找 要求数组有序升序 2.存在元素返回索引, 不存在返回-应在位置插入点-1
负应在位置插入点-1什么意思呢?代码演示如下
System.out.println("原数组"+Arrays.toString(array));
int i = Arrays.binarySearch(array, 10);
System.out.println("二分查找,该元素10应该在在索引"+i+"的位置");

返回值-3 为什么呢?因为采用二分查找,10如果存在应该在6和34之间,也就是索引2 ,变为负数-1,所以返回-2-1=-3.
- 数组拷贝 copyof 数组拷贝
Integer[] copy = Arrays.copyOf(array, 8);//参数1 元素组,参数2 拷贝后长度
System.out.println(Arrays.toString(copy));//跟拷贝长度有关 1.范围=原长度全部拷贝 2.大于全部范围则拷贝的数组补齐默认值(null)
原数组没有到达长度8所以补默认值

- copyofRange 数组拷贝(限定范围)
/**
* 细节该方法拷贝数组范围[) 俗记 包头不包尾
*/
Integer[] ofRange = Arrays.copyOfRange(array, 0, 5);
System.out.println("拷贝结果:"+Arrays.toString(ofRange));
所以输出结果不报阔索引5的数据

- fill 填充
System.out.println("====================fill 数组填充================================");
Arrays.fill(array,0,2,100);//表示填充0-2部分 填充值100 也是包头不包尾巴
Arrays.fill(array,1000);//全填充

- 数组转集合 asList
List<Integer> x = Arrays.asList(array);
正则表达式
当java中判断一个字符串是否满足我们需要的需求,我们会采用正则表达式(regex)。
比如判断一个字符串是否为QQ号,就可以使用字符串的matches方法进行判断
满足规则返回true 否则返回false
String qq="2613867717";
//1.使用正则表达式 限制字符串格式
System.out.println(qq.matches("[1-9]\\d{5,19}"));
- 正则表达式规则

首先在做练习之前先了解转义字符
\(此处是打了俩个反斜杠,Markdown语法也会识别转义字符,单个反斜杠不可可见),在转义字符后边的字母会改变原本的字符意思,\n(换行),\t(空格)等…以上都是打了俩个反斜杠才表示一个反斜杠(速记双反斜杠才是单反斜杆的作用,单反斜杠本身就被识别转义)
比如:输出反斜杠
System.out.println("\\");
这样才是单一斜杠

- 正则表达式能看懂,并且按照要求改写就行 细节如下
1.[] 表示一个字符
2.- 表示字符范围
3.()限定范围比如,&&表示交集,|表示并集
[1-9]\d{16}(\d|x|X)
这里表示的就是 1-9其中一个数字开头,跟16个数字,在拼接任意数字或者X或x,如果不加()
限定范围 则代表整个|符号前和|符号后进行或运算.
4.一般预定义字符和数量词混用
比如\d{5,10} 表示字符串必须满足5个以上,10个数字已下的规则
- Idea中正则表达式的插件 –any-rule
1.插件下载 Setting ->plugin 搜索下载
2.插件的使用 申明空白字符串 右击鼠标 点击anyrule 进行选择 然后更改
3.进行演示
这里选择身份证号
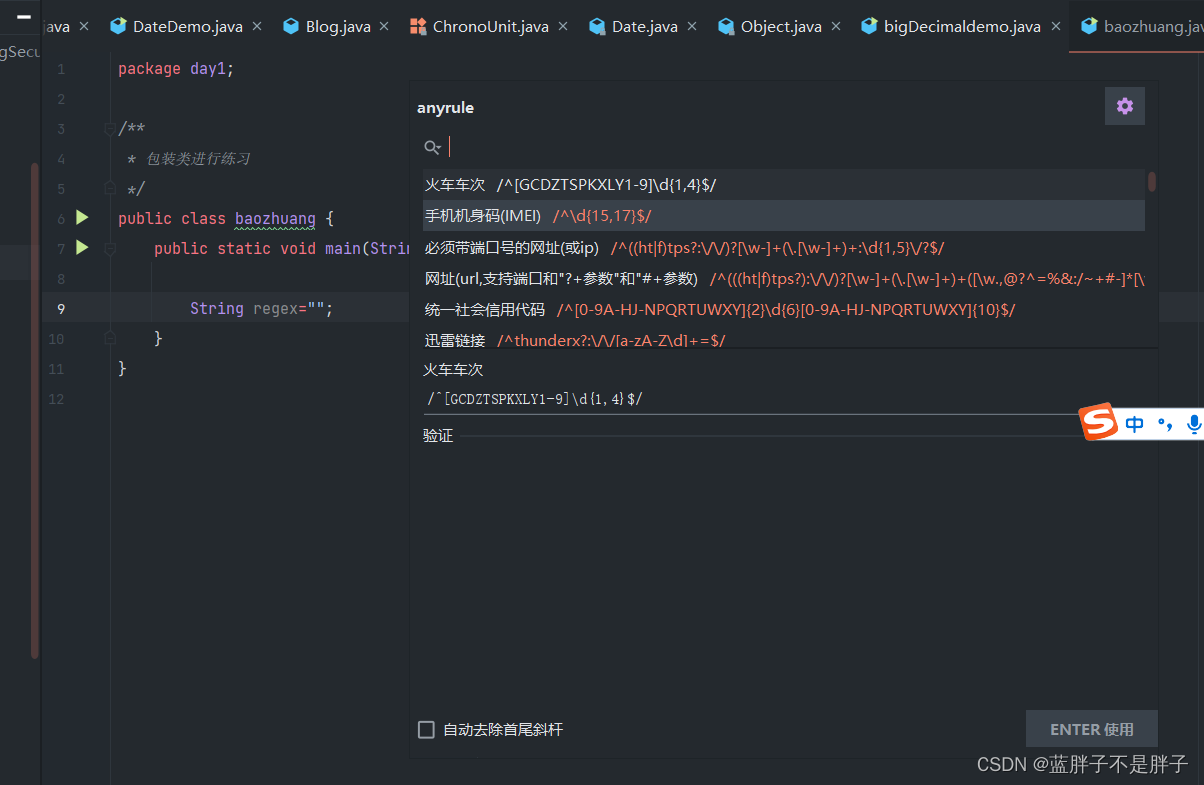
String regex="/^[1-9]\d{7}(?:0\d|10|11|12)(?:0[1-9]|[1-2][\d]|30|31)\d{3}$/";
这样肯定报错,/^ 和$/ 是正则表达式的开始和结束符号 ,JAVA自动底层编译 ,在讲单个反斜杠\,改成双斜杠;
//我这里选择的是一代身份证 anyrule有三代身份证 可以改成三代身份证自行验证
String regex="[1-9]\\d{7}(?:0\\d|10|11|12)(?:0[1-9]|[1-2][\\d]|30|31)\\d{3}";
lambda表达式
lambda表达式的作用一般是用于简化匿名内部类做参数的书写
代码演示:
原来需要匿名内部类实现
Arrays.sort(ar, new Comparator<Integer>() {
//匿名内部类 无需特意实列化一个对象重写需要的方法
// Lambda表达式就是对匿名内部类的简化 无需new对象 在逐个改写 直接(参数)->{方法题}
@Override
public int compare(Integer o1, Integer o2) {
return o1 - o2;
}
});
lambda表达式优化后:
俩种:当重写的方法体只有一行代码时候,可以省略return 和方法体{},以及;
Arrays.sort(ar, (Integer o1, Integer o2) -> { return o1 - o2;});
Arrays.sort(ar, ( o1, o2) -> o2 - o1 );
格式分析
参数由原来的匿名内部类,转变为(参数)->{ }的格式,因为使用匿名内部类的目的式为了实列化接口的方法,lambda表达式跳过面向对象的过程,可以直使用参数
//只需要 专注于方法的改写 ,无需在关注接口及实现类本身
(Integer o1, Integer o2) -> {
return o1 - o2;
}
使用细节
1.lambda 表达式可以用来简化匿名内部类的书写
2.Lambda表达式只能简化函数式接口的匿名内部类写法
3.函数式接口:
仅有一个抽象方法的接口叫函数式接口,接口上可添加@FunctionalInterface
4.当方法体只有一行代码时,可以省略 return ,;,{},且必须同时省略
Arrays.sort(ar, (o1, o2) -> { return o1 - o2;});
简化为:Arrays.sort(ar, ( o1, o2) -> o2 - o1 );
5.参数类型可以省略,当参数只有一个时,()也可以省略
比如这里我们自定义函数式接口
public static void mehod1(Swim s) { //参数是实例化该函数式接口
s.swimming();
}
interface Swim{
public abstract void swimming();
}
调用 :
mehod1(()-> System.out.println("lambda式输出自定义接口"));
总结
得益于函数式接口只有一个抽象方法,所以lambda表达式简化的就是申请接口内存空间,选择重写方法的过程只有是重写抽象方法只有一个,所以参数类型也可以省略(相对应),lambda表达式基本格式在形参需要函数式接口的地方无需再实例化(参数)->{方法体}
集合进阶
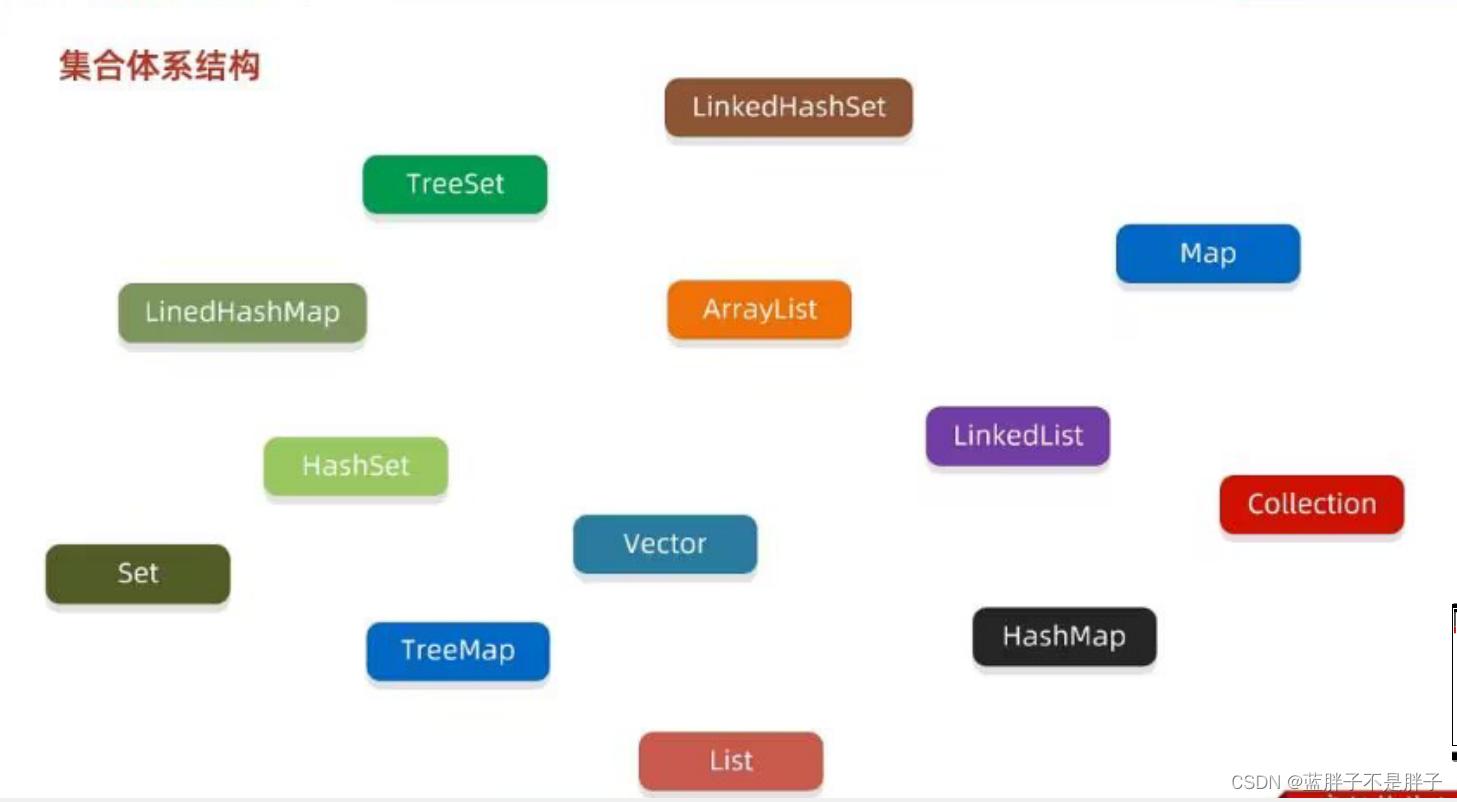
集合体系
集合体系庞大
总体大类可以分为单列集合List,Set和双列集合Map
集合大类虽然繁多,单都是继承了顶级接口根据数据结构不同改写的子类,应该按数据接口记忆即可
泛型
在使用集合之前需要了解使用泛型
泛型是jdk5 中引入的特性 用于在编译阶段(java 的泛型其实是个伪泛型 , 只在编译时期有效)约束操作数据,并且进行检查
格式:<数据类型>
只支持引用类型
- 使用场景
ArrayList<Integer> List = new ArrayList<>();//泛型约束
如果指明泛型,那么集合可以存储任意类型
ArrayList arrayList = new ArrayList();//不约束 可以存储任意数值 等同于 ArrayList<Object> list=new ArrayList<>();
arrayList.add(45);
arrayList.add("我真的帅啊");
arrayList.add(3.14);
arrayList.add('G');
System.out.println(arrayList);
因为取出来的数据是Object,这样集合里储存的数据本身的特点无法发挥,如果要使用某个引用类型特有特性IObject多态的弊端
没办法调用集合中自子类内有的数据 比如 Integer.length,Integer.valueOf(o.toString)
Integer的转toHexString(),就算强转 由于原素对象类型不同个数多
很麻烦,或者自定义数据类型无法使用其特定方法,所以需要约束.
泛型的使用
1.泛型类 不确定类中某个变量的时候
格式:修饰符 class 类名{},<>里面的字母任意,代表不确定的类
比如mapper,list 源码
在比如自定义泛型类
/**
* 这样就可以自定义仁和引用类型作用变量
* @param <e>记录数据类型
*/
class girl<e>{
private Object[] o=new Object[10];
private int size=0;
public Boolean add(e element){
o[size]=element;
size++;return true;
}
public <t> t get1(t index){
return index;
}
public <t> void addAll(ArrayList<t> list,t ...e){
for (int i = 0; i < e.length; i++) {
list.add(e[i]);
}
}
public e get(Integer index){
return (e)o[index];
}
}
- 泛型方法
当方法参数/返回值不确定的时候,但是类的变量属性都确定,所以只用限定方法
public static <t> t get1(t index){
return index;
}
girl girl = get1(new girl<>());
3.泛型接口
/**
* 使用泛型接口的方法
*1.实现类给给出具体限制
* class mylist implements List<String>{}
* 2.实现类 继续延续泛型 等创建对象时候决定
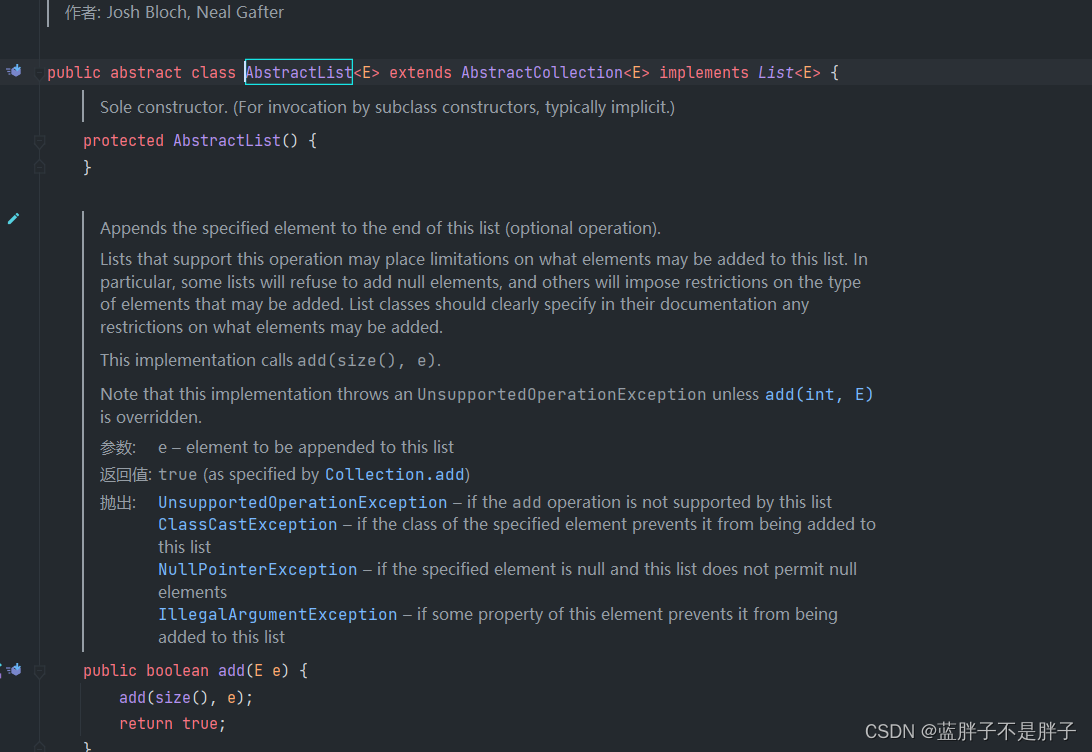
* public class ArrayList<E> extends AbstractList<E>
* implements List<E>, RandomAccess, Cloneable, java.io.Serializable
*/
class mylist implements List<String>{
@Override
public int size() {
return 0;
}
@Override
public boolean isEmpty() {
return false;
}
@Override
public boolean contains(Object o) {
return false;
}
@Override
public Iterator<String> iterator() {
return null;
}
@Override
public Object[] toArray() {
return new Object[0];
}
@Override
public <T> T[] toArray(T[] a) {
return null;
}
@Override
public boolean add(String s) {
return false;
}
@Override
public boolean remove(Object o) {
return false;
}
@Override
public boolean containsAll(Collection<?> c) {
return false;
}
@Override
public boolean addAll(Collection<? extends String> c) {
return false;
}
@Override
public boolean addAll(int index, Collection<? extends String> c) {
return false;
}
@Override
public boolean removeAll(Collection<?> c) {
return false;
}
@Override
public boolean retainAll(Collection<?> c) {
return false;
}
@Override
public void clear() {
}
4.(重点)通配符
/**
*1. 泛型不具备继承性 泛型限定的申明类型 只能传入该类型 以及子类也
* 2.泛型通配符 ? 也表示一个不确定类型的变量
* 进行类型的限定
* ? extends E 表示可以传递e和e所有的子类
* ? super E 表示可以传递e和e所有的父类
* 应用场景 如果定义类,方法,接口的时候,如果类型不确定,就可以使用定义泛型类,方法,接口
* 应用场景 如果定义类,方法,接口的时候,如果类型不确定,但是数据范围是一个继承体系,就可以使用定义泛型通配符
*
*/
代码实现:
设计了一个方法只允许animal和子类传递
public static void method(ArrayList<? extends animal> list){
};// 此时表示限定的范围必须是E以及所有子类
cat是animal的子类
method(new ArrayList<cat>());
method(new ArrayList<animal>());
关于泛型的细节
1.数据可以继承,泛型不行
public static void me2(Collection<animal> animalArrayList){
System.out.println("参数是一个annimal的泛型集合,那么集合就只能传递这个泛型的集合,传递其他,哪怕子类约束的泛型不能·");
/**
* 泛型比作具有型号限制,集合接口,类比作容器外貌,限制的什么型号就是什么型号 没有继承关系 ,装对应型号的东西,和什么样的外貌无关
* 数据具有继承关系 所以容器本身可以选择不同的具有继承关系的容器,但是储存的数据,和容器本身可以继承
* 限定的数据比作内容,可以装和内容相似的子类
*/
}
要求什么类型的泛型集合,就只能是什么类型的泛型集合,但是数据可以继承,只要是同泛型,该集合的子类也可以满足,和集合类型,数据类型无关,只和泛型本身有关
泛型不可继承,所以传入该方法只能是这个泛型,数据集合可以继承,所以集合子类也可以
me2(new HashSet<animal>());
me2(new ArrayList<animal>());
数据可以继承,所以泛型约定数据的子类也可以存入容器
ArrayList<cat> lihuacats = new ArrayList<>();
lihuacat lihuacat = new lihuacat();
farmacat farmacat = new farmacat();
lihuacats.add(lihuacat);
lihuacats.add(farmacat);// 泛型不能继承 但是数据可以 泛型定义的数据类型,集合可以添加该类以及子类类型
2.泛型同集合一样,只能储存引用类型
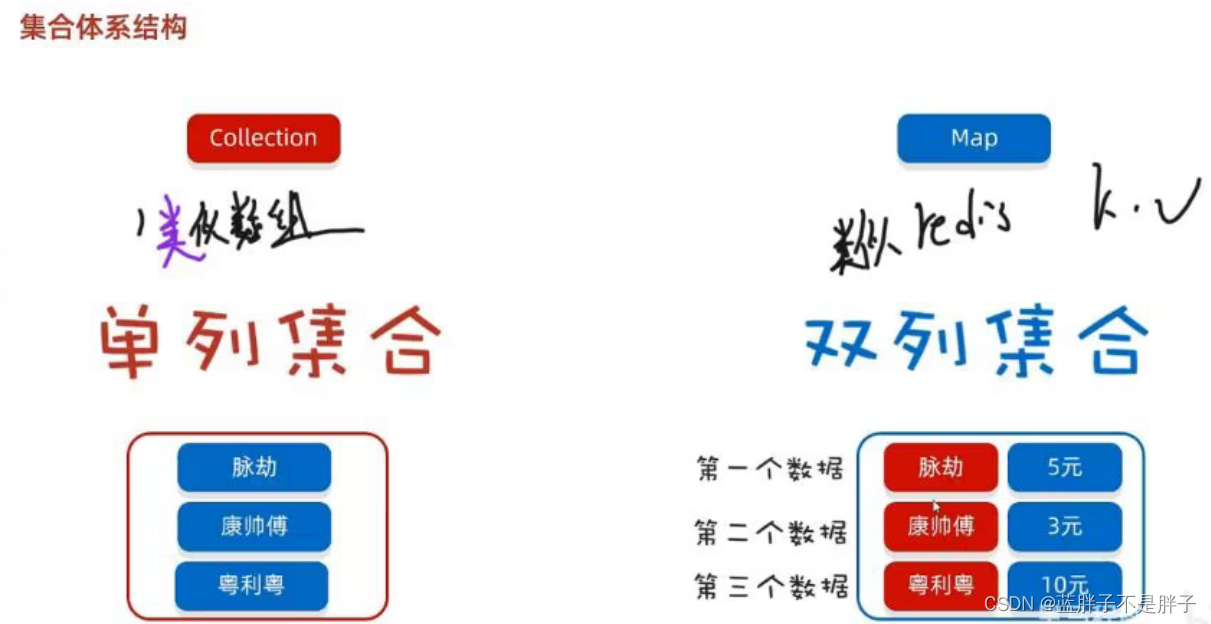
collecon
所有单列集合的祖宗接口 ,所有方法都可以被单列集合继承使用,其子接口
List集合具有:索引,可重复,有序储存特点
set集合具有:无索引,不可重复,无序储存的特点
因为collection是单列集合顶级接口,所以因为共性,储存也是无序
常用方法
- add
//因为是个接口 我们无法直接实例化对象,只能实例化子类 所以这里采用多态形式
Collection<Integer> collection=new ArrayList<Integer>();
boolean b = collection.add(15);
System.out.println("由于数据结构无索引,无法get只能直接输出"+collection)
- 集合清空 clear
System.out.println("clear 清空集合");
collection.clear();
System.out.println("执行clear后"+collection);
清空后只剩下个[]空集合
- remove(Object o) 移除元素
boolean remove = collection.remove(123)
- 查询集合是否包含某元素
/**
* 底层是根据equals 方法进行比较,只能比较引用对象
* 如果是自定义对象需要重写equals方法比较属性值
*/
System.out.println("该15元素是否存在于集合中 :"+collection.contains(15));
System.out.println("该123元素是否存在于集合中 :"+collection.contains(123));
- isempty 是否为空
boolean empty = collection.isEmpty();
- iterator获取迭代器
迭代器是java在集合便利中专门书写的接口,在便利中使用
Iterator<Integer> iterator = collection.iterator();//2.1获取迭代器
集合的便利
- 迭代器方式
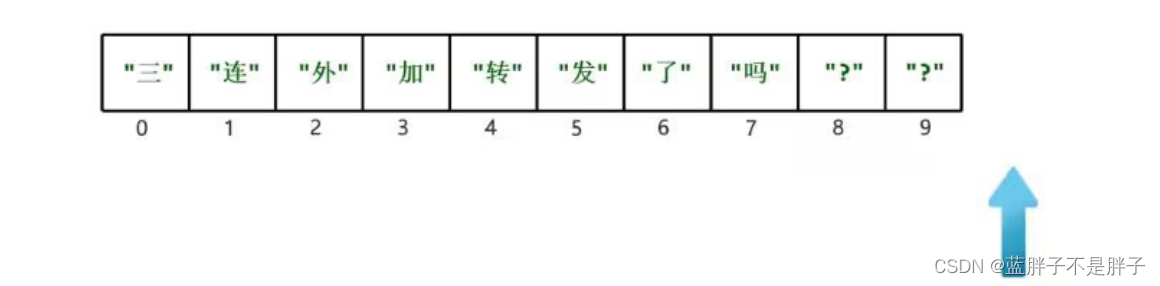
迭代器是一种通过创建指针(默认在0索引位置)方式逐个便利指向数据便利,核心方法
1.hasNext();当前指针是否具有数据
2.iterator.next();返回当前指向数据,并且指针向后移1
代码演示
Iterator<Integer> iterator = collection.iterator();//2.1获取迭代器
//判断迭代器当前(初始)位置是否有元素 类似0索引
while(iterator.hasNext()){ //iterator.next();获取集合当前元素的值 迭代器并且指向下一个元素
//如果初始位置有元素 开始迭代遍历
Integer integer = iterator.next(); //遍历完后 这个迭代器的位置已经移动到集 合末尾 并且不会复位 需要再次遍历只能在获取一个迭代器
System.out.println("遍历结果::"+integer);
}
使用细节:
1.迭代器床架后默认是在0索引,因为next方法索引移动到下一位置,所以当指针到最后一位后,不会复原,如果需要再次便利,只能再次使用集合创建迭代器
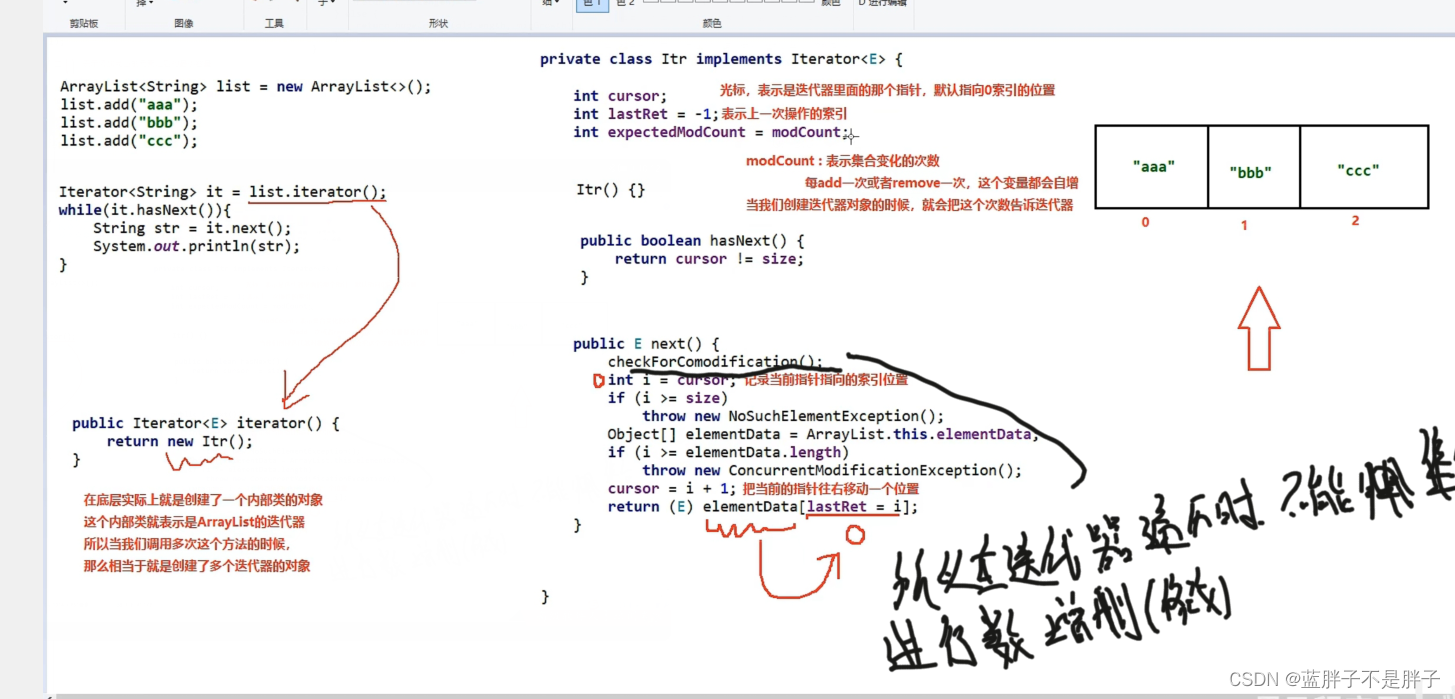
2.在便利过程中,不能使用集合的数据操作方法对集合进行操作,会报异常
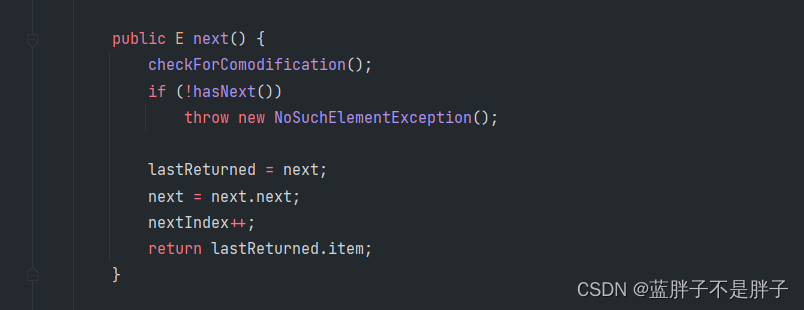
原因是便利的核心方法中有一个类似乐观锁机制来记录修改数据次数,在子类LinkedList原码可以提现(checkForComodifiction就是检查次数的方法)
3.便利的时候不要在方法体中使用来此next,当最后一个数据已经被返回,但是第二个next方法继续获取指针数据,由于此时指向的地址已经跳转到末尾+1,所以抛出异常
4.如果真的需要在便利过程中删除数据,只能使用iterator的封装修改方法
- 增强for循环便利
无索引接口无法采用fori方式循环
for (Integer i: collection) {//泛型装的内容:集合 底层就是迭代器 适用于所有单列集合包括数组
i=5555;
System.out.println(i);
}
System.out.println("即使逐个改变i 原集合不会改变"+collection);
细节:增强for 是将集合/数组元素 逐个赋值 给第三方变量,所以改变第三方变量的值 原集合数值不变
- 通过foreach方法创建匿名内部类的方法便利
collection.forEach(new Consumer<Integer>() {
@Override
public void accept(Integer integer) {
}
});
collection.forEach(i->System.out.print(i));
List分支
Collection的子接口,在父接口的方法上,融合自己的索引特性,方法轻微改变
常用方法
- add
相较于父接口,多了索引于是添加便可以根据索引添加.默认方法是添加到末尾,但是可以添加到指定位置原索引进行后移
List<String> list = new ArrayList<>();//顶级接口通过创建子类实现
list.add(0,"我是第一位");
list.add("我是第二位");
list.add(2,"我是第三位");
list.add(3,"我是四位");
list.add( 2 ,"添加到那个索引 原索引的位置以此向后移");
System.out.println(list);
- remove 根据索引删除
子接口特性重载以后,根据索引删除 返回删除得值
System.out.println("通过索引返回删除的数据 ::"+list.remove(2));
细节:当集合存储Integer时候,只传递一个数字4,会删除元素4?还是索引4,因为自动装箱的存在,在这里会很模糊,实际是按照传递的索引处理,java会选择形参和实参相同的方法,如果手动装箱数字4,才会特意去删除这个元素
返回元素内容,参数按照索引处理:
Integer remove1 = list2.remove(4);
手动装箱后,返回Boolean值,参数按照元素处理
Integer integer = Integer.valueOf(4);//手动装箱
//此时 形参和实参相同才是按照元素删除
boolean b = list2.remove(integer);
- set 修改
String s = list.set(0, "哈哈哈我被修改咯,返回修改前的元素");
List的便利方式
因为List多了索引特性相较于原来的三种增加了以下
- fori形式
for(int i=0;i<listdemo1.size();i++){
System.out.println("fori::"+listdemo1.get(i));
}
- 列表迭代器
ListIteractor是iteractor的子接口,迭代器 便利的时候可以删除元素 如果需要迭代的时候添加只能是列表迭代器
ListIterator<String> iterator1 = listdemo1.listIterator();//迭代器iterator的子接口】
while (iterator1.hasNext()) {
String next = iterator1.next();
if ("bbb".equals(next)) {
iterator1.add("qqq");
}
System.out.println("列表迭代器正向便利::"+ next);
}
- 继承的便利方式不变
//1.继承的迭代器便利
ArrayList<String> listdemo1 = new ArrayList<>();
listdemo1.add("aaa");
listdemo1.add("bbb");
listdemo1.add("ccc");
listdemo1.add("ddd");
Iterator<String> iterator = listdemo1.iterator();
while (iterator.hasNext()) {
System.out.println("迭代器便利::"+iterator.next());
}
//2.增强for便利
for(String S:listdemo1){
System.out.println("for便利::"+s);
}
//3.lambda
listdemo1.forEach(i-> System.out.println( "lambda(匿名内部类)::"+i));
ArrayList源码分析
之前演示集合接口,是通过多态的方式申明Arraylist,Array数组,如名字一般ArrayList是实现了基于动态数组的数据结构,是List最基本的实现类.
查看源码:
空参构造就是创建了一个空数组
数组长度默认是10


private static final int DEFAULT_CAPACITY = 10;
底层添加元素:在执行前会进行素组自增
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
附上完整黑马笔记便于复习:

`
这里特意说明,在使用iteractor(迭代器便利),for(底层也是迭代器)便利时,不能使用数组的方法进行修改数组,是因为底层有类似乐观锁的机制;
//源码在执行便利的时候会调用checkForComodification()检查集合修改次数和创建迭代器时候是否一致
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
iteractor完整流程笔记:
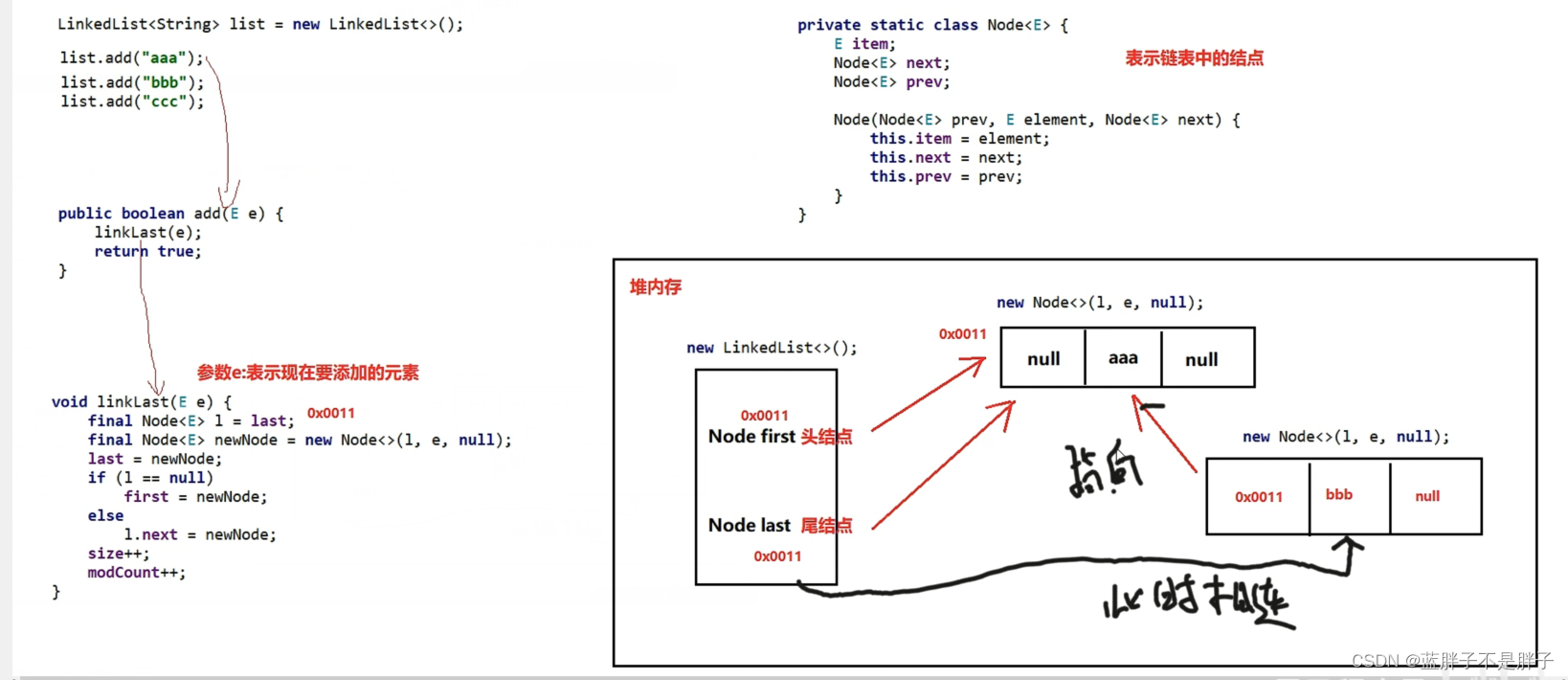
LinkedList源码分析
LinkedList底层是使用链表方式数据结构的集合,由于数据存储结构的特点,LinkedList结合了双链表的特点,储存不在是数组而是链表,以结点为单位存储数据
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
除了拥有一般链表增加是默认集合尾部添加
由于双链表对头尾增删方便的特点,还增加了以下方法
- 尾结点添加
ist1.addLast("最后一位置添加");
- 头结点添加
list1.addFirst("第一位添加");
- 删除首
list1.removeFirst();
- 删除尾
list1.removeLast();
源码笔记:
Set系列
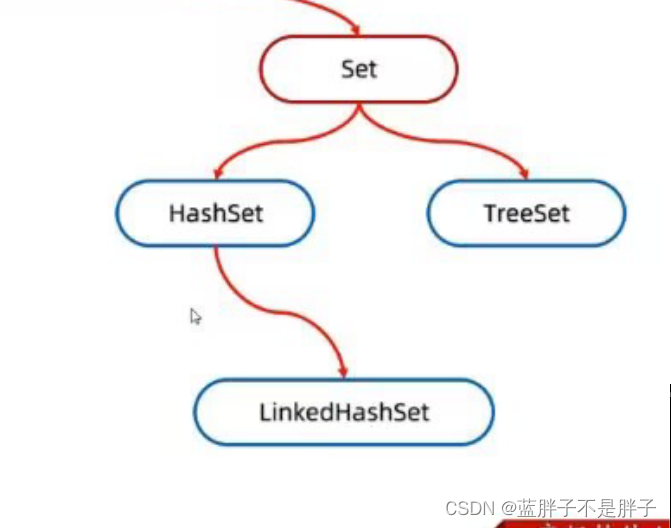
Set
特点
1.无序
2.无索引
3.不重复
因为Set是顶级接口继承Collection,所以方法无任何改变,以下代码实现
/**
* 系列顶级接口set继承 Collection 所以方法都一样
*/
//实例化
Set<String> sets = new HashSet<>();//接口无法实例化,通过多态 子类的实例化来创建对象
//1. add 注意和list collection的区别 不可重复 add会返回false
sets.add("a");
boolean r = sets.add("a");
System.out.println("第二次添加结果::"+r);
sets.add("b");
sets.add("c");
//2. remove
sets.remove("a");
//3. addAll
ArrayList<String> list = new ArrayList<>();
list.add("listA");
list.add("listB");
list.add("listC");
sets.addAll(list);
//将有序集合 添加到无序集合中输出发现数据无序排序验真了无序性
System.out.println(sets);
//4.便利
//4.1迭代器
Iterator<String> it = sets.iterator();
while(it.hasNext()){
String s = it.next();
System.out.println("便利的数据::"+s);
}
//4.2 增强for
for (String set : sets) {
System.out.println("sets :: "+ set);
}
//4.3lambda
sets.forEach(s-> System.out.println("lambda :: "+s));
HashSet
hashset作为set接口最基础的实现类特点和顶级接口一致,由于底层结合hash算法,更能解析set的特点
/**
* 特点 :无序 不重复,无索引 故此 和顶级接口 方法特点一至于 是set的 基础实现 主要眼界源码
* 哈希值::对象的整数表现形式
* 1.如果没有重写hashcode,不同对象打印的哈希值是不同的,都是地址转换为整数 (原生Object的hash方法)
* 2.重写hashcode,不同对象只要属性值相同,计算的哈希值就是一样的
* 3.小部分情况会出现地址不同,哈希值一样的情况(hash碰撞)
* hash值是set底层判断是否重复的一个标准,底层会调用equals方法
* 如果set里面存储自定义对象 一定要重写equals,hashcode,JAVA其他类·重写好了
*/
底层(jdk8后一样的元素直接不计算,而是挂在相同数据的位置)
1通过元素的地址计算而成的hash值来决定存储位置,所以无法通过索引获取
2.每个数据的hash值不同,无法保证有序
3.底层储存时候会调用equals方法比较,所以无重复
源码验证:
1.添加时先通过内置map存放数据,作为map的key,保证了其无重复性
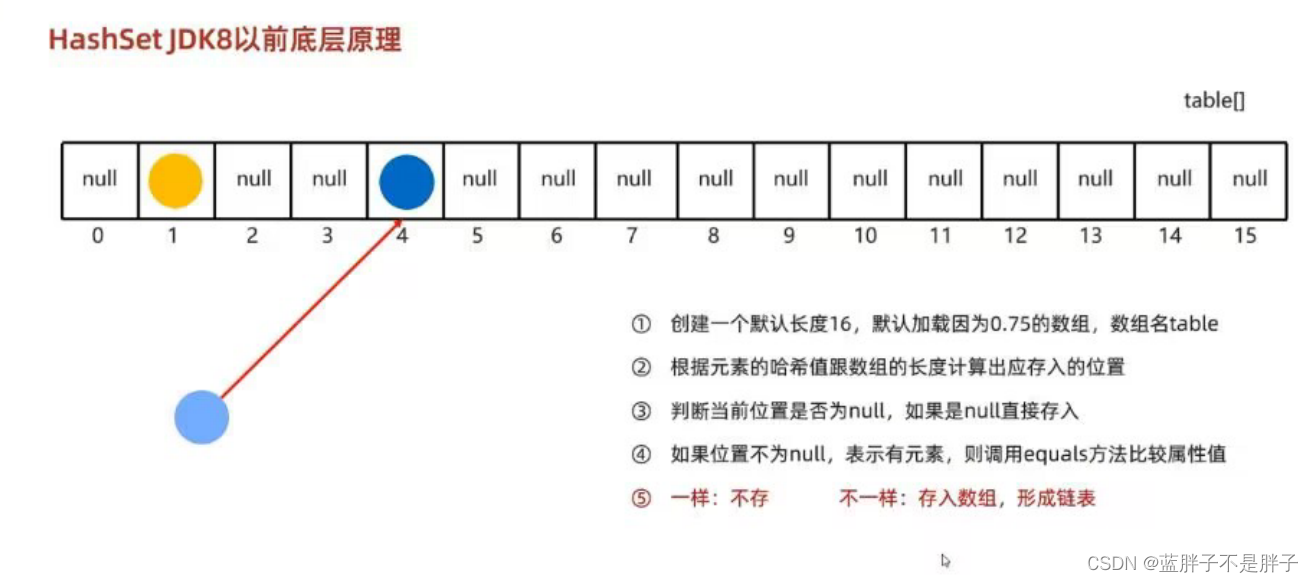
2.我们熟知的map kv结构,key无重复,底层多次调用equals比较
4.Hash和linkedset储存自定义类必须改写Hahcode和equals

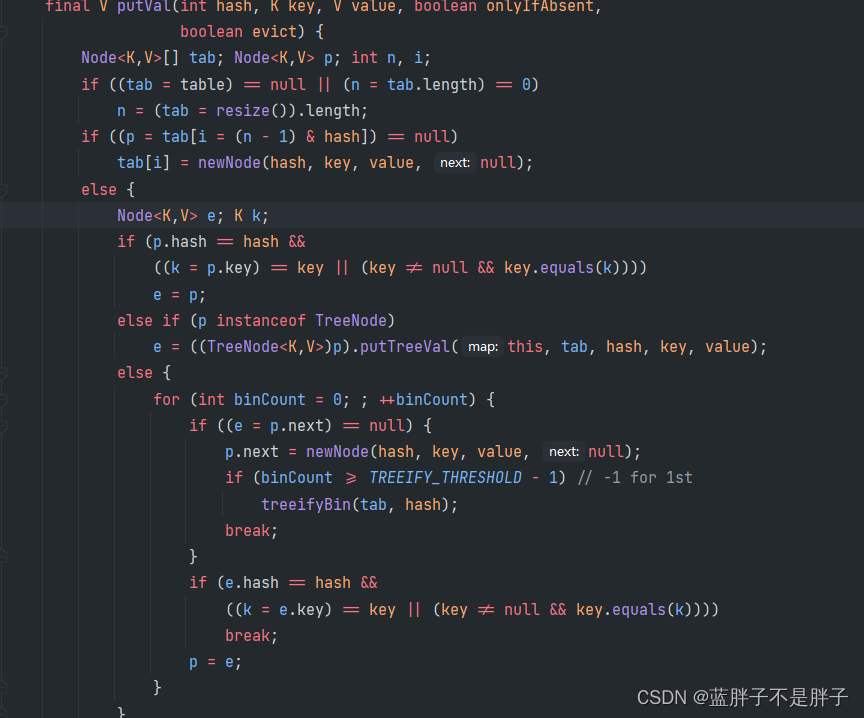
由于底层根据equals去重,hashcode决定存储地址,在实际开发中,存储基本数据的包装类,之所以做到了按照数据去重,而不是按照对象内存地址(如果是对象内存地址每个对象都不能不同,但数据大小一样肯定不符合要求),是因为java底层改写了equals,和hashcode方法,根据数据大小值计算hashcode和进行比较.
linkedHashset
在hashset的基础上,底层又使用了双链表结构存储数据的顺序, 使得数据具有无索引,不重复,有序的特点 .
代码验证
/**
* 特点 :有序 不重复,无索引
* 有序 :链表方式存储和读取 一致
* 不重复:底层的equals和hashcode就行判断
* 无索引:没有索引
* 原理 :在底层数据结构hash表的,每个元素多了双链表 机制记录储存顺序 ,不等于索引顺序
*/
LinkedHashSet<Student> linkedset = new LinkedHashSet<>();
System.out.println(linkedset.add(s1));
System.out.println(linkedset.add(s2));
System.out.println(linkedset.add(s3));
System.out.println(linkedset.add(s4));
System.out.println(linkedset);
// 虽然有序 但是 如果没有顺序读取要求 默认还是hashset ,减少底层运算时间
结果确实是按照存入顺序进行保存的
底层:
源码:
其实也可以发现set和map底层相似,至少set的源码依赖map

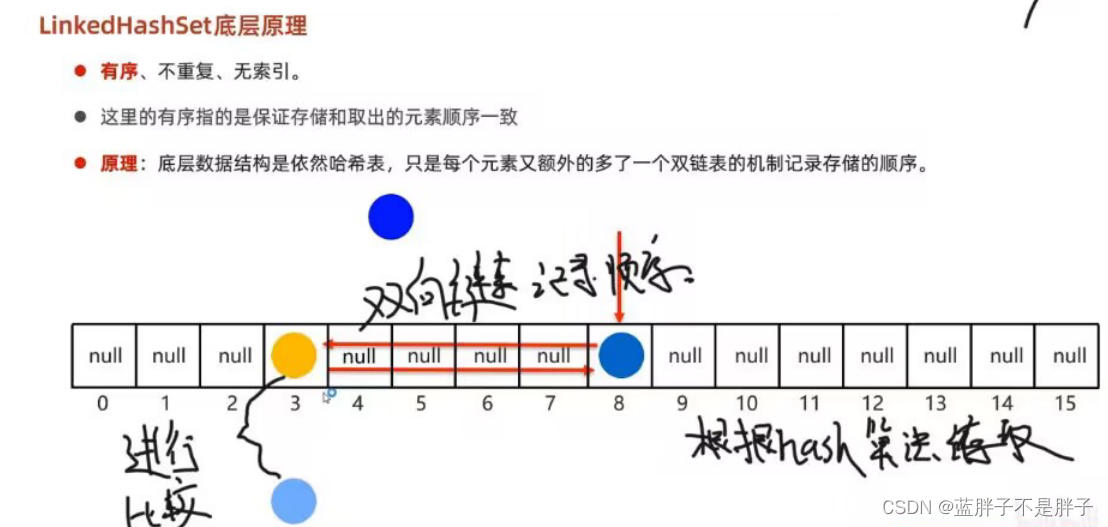

特点原理:
无重复:底层会调用equals方法比较
有序:底层加入了链表记录数据录入顺序
无索引:数据底层根据hash算法存储,而不是根据地址连续存

Treeset
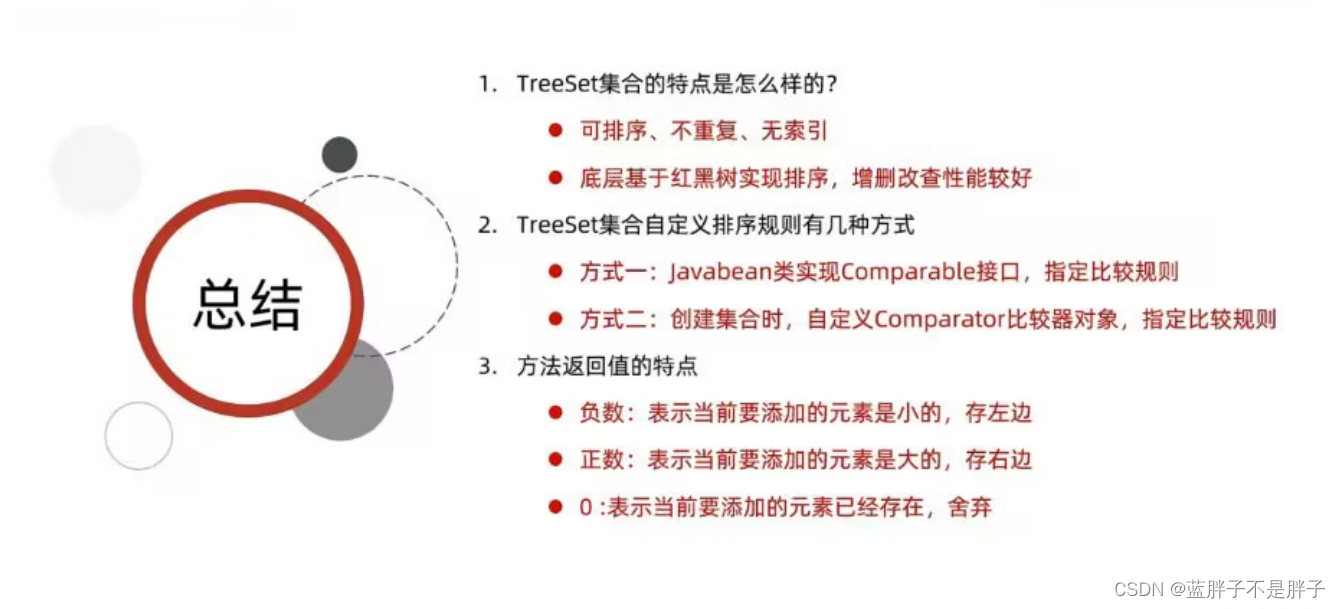
treeSet 底层融入了红黑树(是一种类似二叉排序树的数据结构)数据结构储存 ,所以具有排序功能 ,增删改查性能良好.
TreeSet特点
1.底层数据结构加入了红黑树,数据可以排序
2.无重复
3.无索引
无重复和无索引和hash,equals无关,而是tree数结构具有排序算法
代码验证
System.out.println("使用案列 保存整数 并且排序");
TreeSet<Integer> treeSet = new TreeSet<>();
treeSet.add(5);
treeSet.add(3);
treeSet.add(2);
treeSet.add(4);
treeSet.add(1);
System.out.println(treeSet);//实现排序
输出结果
当存储基本数据类型时,根据大小升序,如果是自定义类型呢
所以treeset可以改变排序规则
1.储存的数据实现排序接口

TreeSet<Student> Studentreesets = new TreeSet<>();
Student ss1 = new Student("Jack", 21, 2002);
Student ss2 = new Student("jerry", 19, 2012);
Student ss3 = new Student("mark", 26, 2005);
Studentreesets.add(ss1);
Studentreesets.add(ss2);
Studentreesets.add(ss3);
for (Student student : Studentreesets) {
System.out.println(student);
}
定义对象实现比较接口 Comparable
class Student implements Comparable<Student>{//1.不知道比较规则参数时候 该类也要定义位置变量泛型 2. 如果已经明确就可以直接指明泛型
private String name;
private int age;
private int Id;
public Student() {
}
public Student(String name, int age, int id) {
this.name = name;
this.age = age;
Id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getId() {
return Id;
}
public void setId(int id) {
Id = id;
}
/**
* compreto 方法 指定排序规则
* @param o
* @return
*/
@Override
public int compareTo(Student o) {
//这里演示根据年龄升序排序 this本类代表要存入的元素·,o代表已经在红黑树的元素 一开始 是红黑树的根节点 一开始传入的数据成为根节点
//return 负数,认为要存入的比较小放左边
//return 正数,认为要存入的比较大放右边
//return 0,一样大舍弃
/**
* 和Arrays中的sort方法一样的算法 this=o1表示未排序的,这里传入的o等同于sort第二个参数02表示已经排序好了
* 速记: 升序算法= 未排序的元素-已经排序好的元素
* 反之降序=排序好-未排序
*/
System.out.println("已经排序好::"+o.name);
System.out.println("本对象::"+this.name);
return this.getAge() - o.getAge();
}
}
重点是实现了接口的抽象方法定义规则
return 负数,认为要存入的比较小放左边
return 正数,认为要存入的比较大放右边
return 0,一样大舍弃
和Arrays.sort方法算法类似
升序:未排序的元素-已经排序的参数
降序:排序好的-未排序
/**
* compreto 方法 指定排序规则
* @param o
* @return
*/
@Override
public int compareTo(Student o) {
//这里演示根据年龄升序排序 this本类代表要存入的元素·,o代表已经在红黑树的元素 一开始 是红黑树的根节点 一开始传入的数据成为根节点
//return 负数,认为要存入的比较小放左边
//return 正数,认为要存入的比较大放右边
//return 0,一样大舍弃
/**
* 和Arrays中的sort方法一样的算法 this=o1表示未排序的,这里传入的o等同于sort第二个参数02表示已经排序好了
* 速记: 升序算法= 未排序的元素-已经排序好的元素
* 反之降序=排序好-未排序
*/
System.out.println("已经排序好::"+o.name);
System.out.println("本对象::"+this.name);
return this.getAge() - o.getAge();
}
虽然这里可以让Treeset可以保存引用对象时候排序,但是如果需要改写对基本数据类型包装类排序就只能使用第二个方法排序了(不能改写jdk源码).
有参构造指定排序规则
演示 排序规则是根据字符串对象长度升序排序,一样长就根据ASCII表升序
System.out.println("第二种方法是通过在建立集合的时候创建 比较器对象指定规则,有参构造");
TreeSet<String> students1 = new TreeSet<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
//o1 未排序
//o2 已经排序好
int i = o1.length() - o2.length();
return i==0?o1.compareTo(o2):i;
}
});
总结: