python爬虫之selenium自动化操作
需求:操作淘宝去掉弹窗广告搜索物品后进入百度回退又前进
selenium模块的基本使用
问题:selenium模块和爬虫之间具有怎样的关联?
1、便捷的获取网站中动态加载的数据
2、便捷实现模拟登录
什么是selenium模块?
1、基于浏览器自动化的一个模块
selenium使用流程:
1、环境安装:pip install selenium
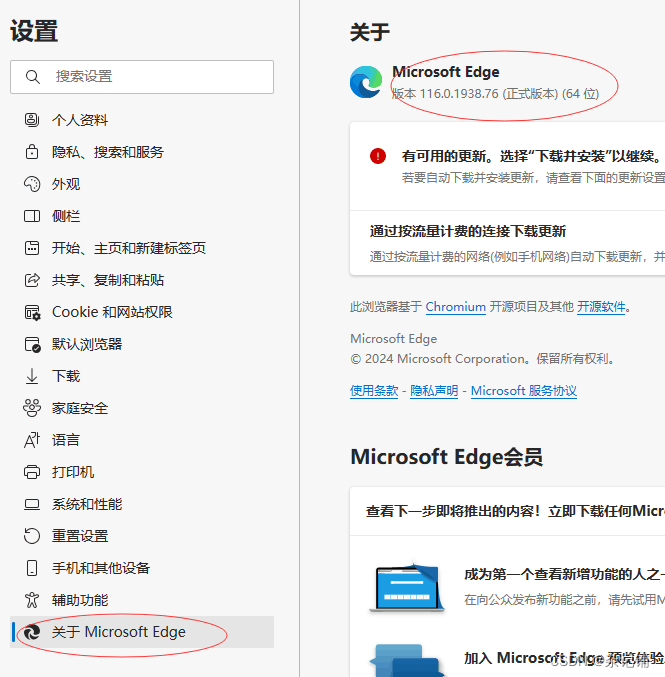
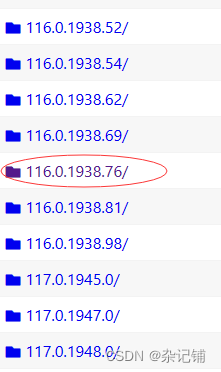
2、下载一个浏览器的驱动程序(edge浏览器为例)
(1)下载路径:edge浏览器驱动
(2)驱动程序和浏览器的映射关系:查看浏览器版本,上面链接找到相对应版本的驱动后下载到爬虫程序所在文件路径中。
3、实例化一个浏览器对象
4、编写基于浏览器自动化的操作代码
(1)发起请求:get(url)
(2)标签定位:find系列的方法
(3)标签交互:send_keys(‘xxx’)
(4)执行js程序:excute_script(‘jsCode’)
(5)前进,后退:back(),forward()
(6)关闭浏览器:quit()
实现代码如下:
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
# selenium 4版本必须要设置浏览器选项,否则会闪退
option = webdriver.EdgeOptions()
option.add_experimental_option("detach", True)
# 实例化浏览器驱动对象,并将配置浏览器选项
# driver = webdriver.Edge(options=option)
#实例化一个浏览器对象(传入浏览器的驱动程序)
bro = webdriver.Edge(options=option)
bro.get('https://www.taobao.com/')
# basic-pop-tmpl-closeBtn
#关闭广告弹窗
guanggao_btn = bro.find_element(By.CLASS_NAME,'basic-pop-tmpl-closeBtn')
guanggao_btn.click()
#标签定位
search_input = bro.find_element(By.ID,'q')
#标签交互
search_input.send_keys('Iphone')
#执行一组js程序
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(2)
#点击搜索按钮
btn = bro.find_element(By.CLASS_NAME,'btn-search')
btn.click()
bro.get('https://www.baidu.com')
sleep(2)
#回退
bro.back()
sleep(2)
#前进
bro.forward()
sleep(5)
bro.quit()