【系列目录】本系列所有文件分章节内容的目录文章请参考:【源码研读系列】目录
【实验代码】本系列所有实验设计的源码都以上传 Gitee码云和GitCode 平台。GitCode代码项目地址:GitCode;在Gitee主页搜索“机器白学”,所有项目中的“YOLO源码实验”就是本系列所有实验代码。Gitee代码项目地址:Gitee
【前情回顾&预告】在上一篇博文中记录了统一训练、验证、测试、导出、超参数调优等等功能的模型基类——Model,文章链接:Engine.model.py.Model。该类在使用验证功能时是直接调用的已经定义好的验证器实例validator。
本文在此基础上,进入其模型验证逻辑,详细分析验证器类的构建运行逻辑,从验证器 validator 的基类定义文件开始——Engine.validator.py.BaseValidator(先从验证器而不是训练器开始分析是因为,训练过程中也要进行验证并记录损失,训练最后也会最终验证评估模型表现)
该基类定义了YOLO所有任务模式、训练或推理都通用的验证逻辑和统计指标。
验证器基类最关键的两个部分就是:1.定义了验证数据加载、数据前处理、推理、后处理等的标准验证流程;2.定义预测框匹配算法,用于统计“类别正确,框与真实框近似重叠”的预测。

一、validator.BaseValidator类
1.类方法总览
BaseValidator 作为一个基类方法,其主要的功能是理清整个验证数据的流程逻辑,因此其内部很多具体的方法在此处(基类中)是没有定义的。如下图所示。这些方法都在继承的子类中具体定义,这么做的好处是使得验证器基类具有很好的扩展自定义性。

为了减少篇幅简化内容,这里暂不讨论这些需要自定义的方法,待之后博文记录其具体子类再详细分析,先将注意力集中在BaseValidator类实现的YOLO验证器的“逻辑”上——该类主要代码功能在初始化__init__和调用方法__call__中。
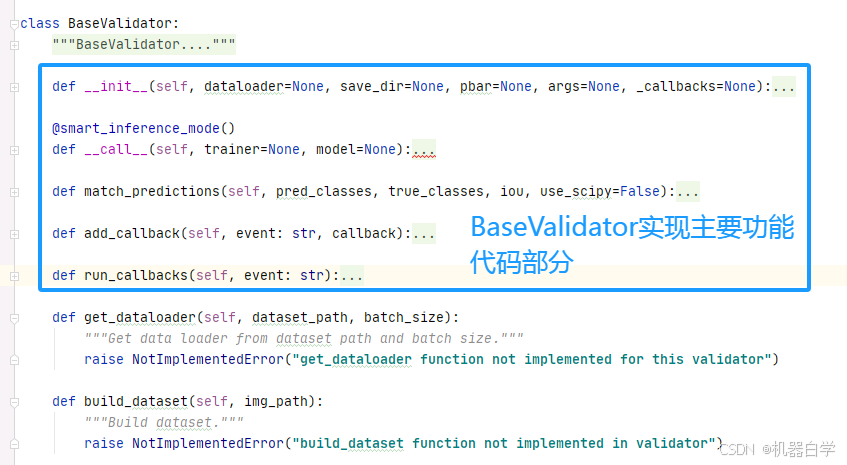
2.__ini__:基础验证器类初始化
首先BaseValidator的类初始化方法,定义了创建验证器实例最基本需要传入的配置参数,以及在运行验证器中会使用到的一些全局的属性信息。
下面表格记录 BaseValidator 验证器基类初始化传入参数及其含义(都是关键字参数)。
| dataloader | 服务验证集的数据加载器,可以参考之前文章中介绍了YOLO的数据加载器是如何定义和使用的。 |
| save_dir | 验证结果和可视化的保存地址 |
| pbar | 传入一个基于tqdm库的进度条,用于可视化验证过程进度 |
| args | 定义验证器中的配置参数 |
| _callbacks | 用于保存各种恢复、回调函数的字典 |
初始化中另一部分就是定义了一些重要的类属性,用于后续操作的结果保存和各个方法间访问传递信息。下图一图总览。

有了上述信息后就可以先测试实例化一个YOLO的验证器。首先要创建一个数据集加载迭代器传入验证器类,这部分具体参考之前关于YOLO无限数据集加载迭代器部分。
from ultralytics.engine.validator import BaseValidator
from ultralytics.cfg import cfg2dict
from ultralytics.data.dataset import YOLODataset
from ultralytics.data.build import build_dataloader
# 自定义验证器
class My_Validator(BaseValidator):
def __init__(self, dataloader=None, save_dir=None, pbar=None, args=None, _callbacks=None):
super().__init__(dataloader, save_dir, pbar, args, _callbacks)
if __name__=='__main__':
# 数据加载器dataloader
# 数据集生成
cocoyaml = './coco8/coco8.yaml'
cfg = cfg2dict(cocoyaml)
imgpath = './coco8/images'
dataset = YOLODataset(imgpath, data=cfg, task='detect', augment=False)
dataloader = build_dataloader(dataset=dataset, batch=4, workers=0, shuffle=False)
val = My_Validator(dataloader=dataloader)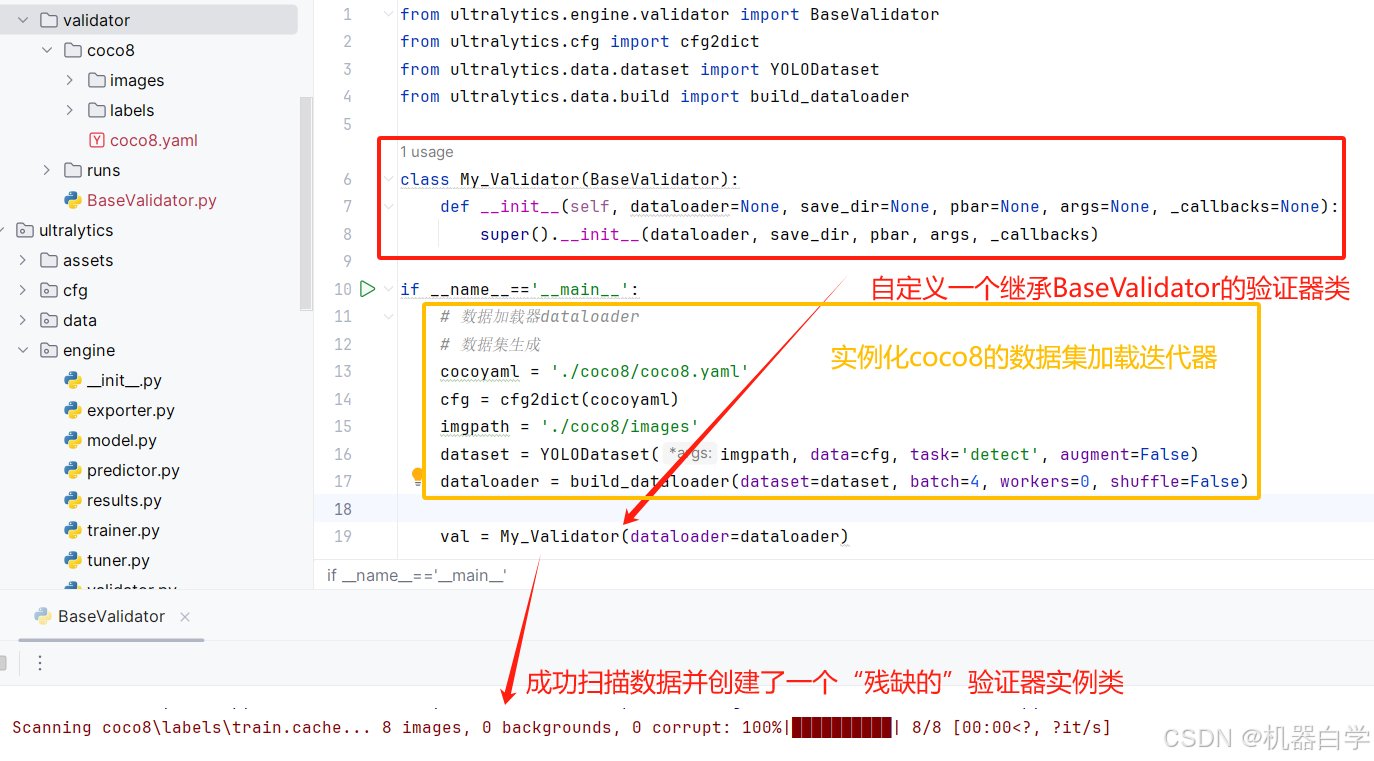
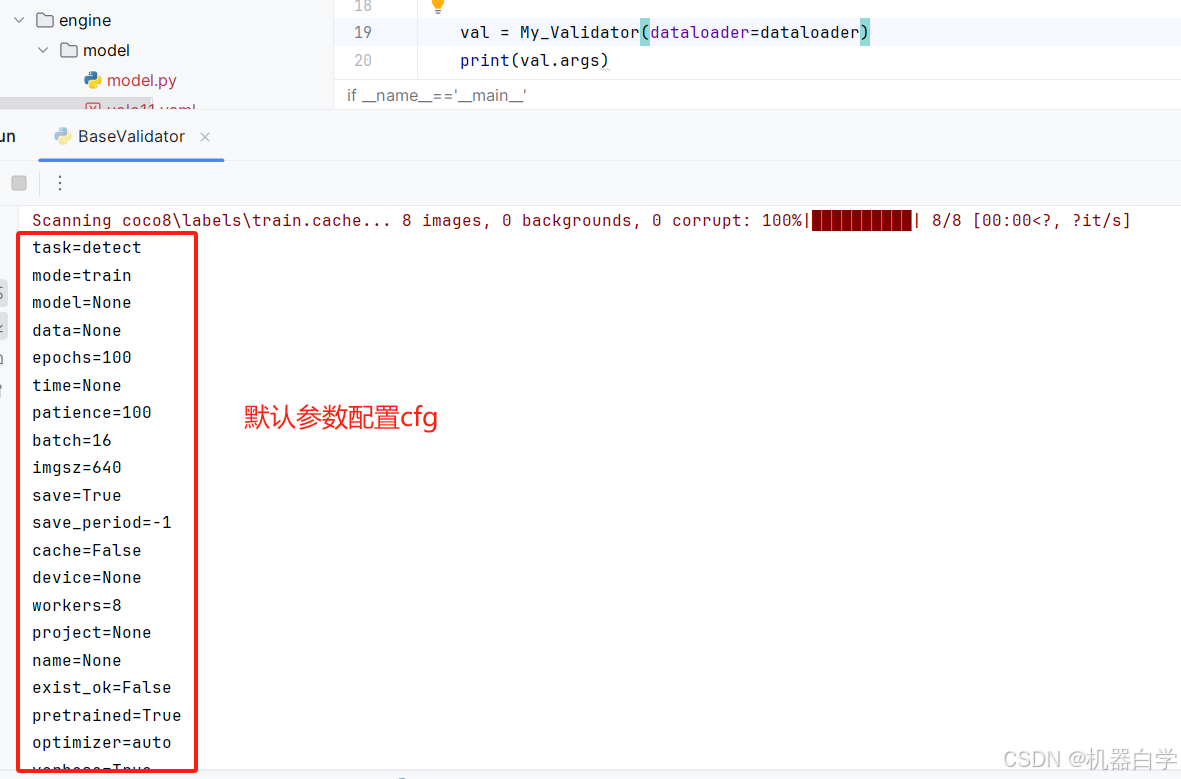
此时只传入了数据加载器参数,没有配置任何args参数。打印一下此时的验证器args参数,可以看到这里实际上加载的就是默认的初始cfg配置参数,具体可参考cfg博文章节(cfg博文地址)。
3.__call__:执行验证过程
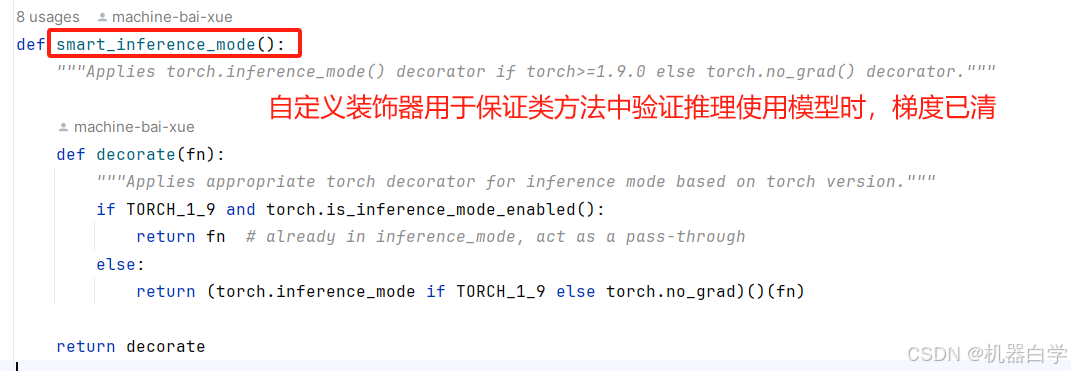
__call__特定的方法名是为了使得BaseValidator类实例可以像函数一样调用,执行验证功能。在分析其具体功能代码前,可以注意到一个自定义的类装饰器 @smart_inference_mode()

这里导入到该自定义装饰器源码查看可知,其主要功能是确保验证时pytorch中的梯度已经清零,这样可以优化推理速度。同时还支持Pytorch1.9之后和之前版本的不同清理梯度方式。
__call__方法是BaseValidator类的核心,负责执行验证过程。
总的来说,其代码逻辑可以分成三个大部分:1.验证前置准备(模型数据加载等)2.批次执行推理验证(推理计算验证指标)3.验证指标后处理(结果统计)
(1)验证前置准备
首先来看验证流程call方法中关于验证前的代码处理。首先在进行验证 Val 操作前,要检测确定当前是训练模式还是单纯的推理模式,训练模式是不允许做数据增强操作的,而如果是训练外的验证可以在验证前做数据增强。
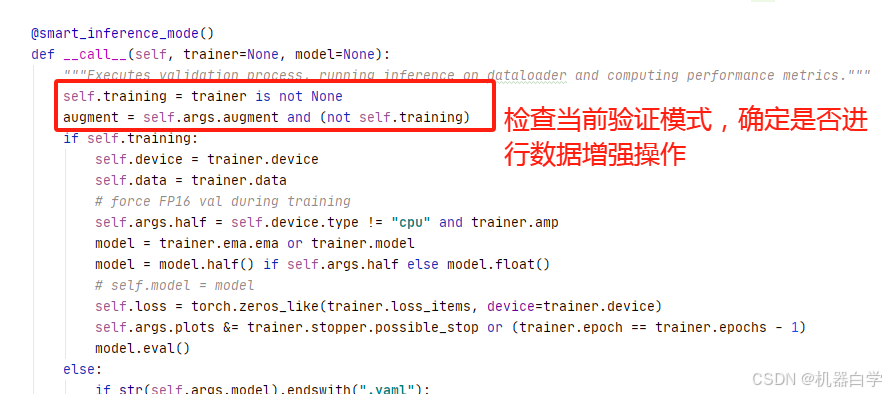
然后,会根据当前模式,分别进行训练模式设置和推理模式设置。
首先看训练模式的设置,包括已有模型的设备、验证数据集信息、选择的数据精度、损失等。特别的,此处会将模型损失初始化为零,这是为了模型在验证过程中累计损失。
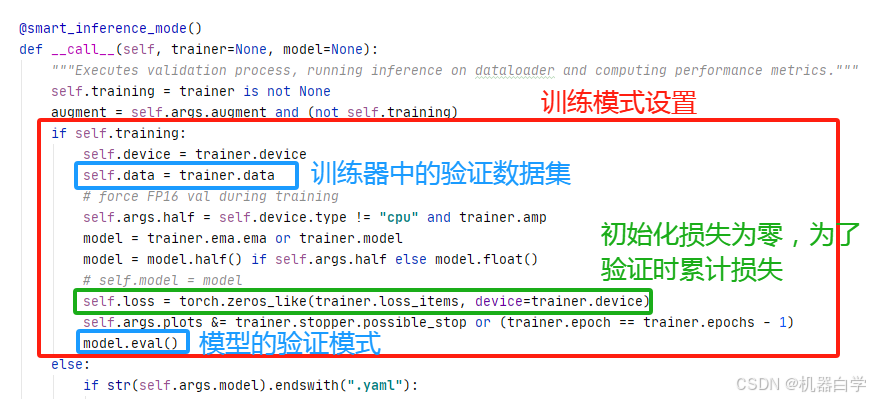
再看推理模式的设置,推理模式不像训练模式在训练中已经加载好的模型以及其对应的验证数据集,推理模型需要重新加载模型,因此其验证前的设置包括初始化模型的各种操作以及设置数据集加载器。因此其代码看起来更复杂,但实际其和训练一样只是在做两件事——配置模型、配置数据加载器。

然后还有一些中间过程结果和进度可视化工具的配置。特别的,批次验证数据集存放在了可视化进度条的TQDM中。如下图所示。
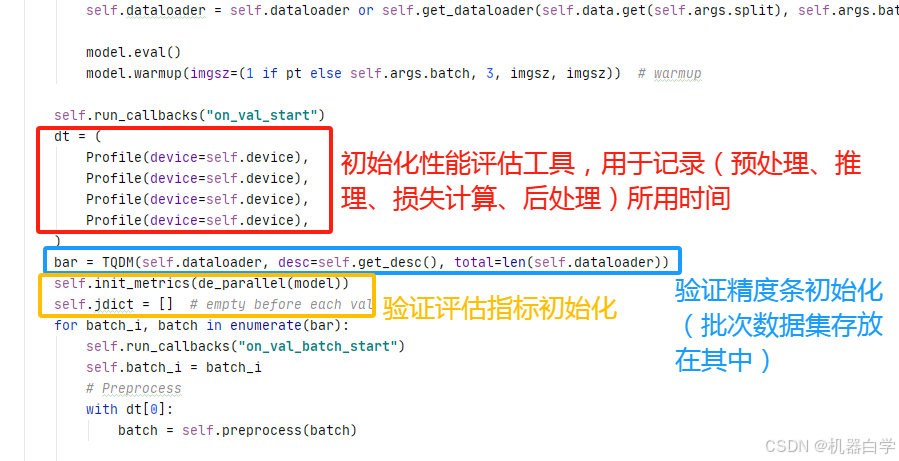
(2)批次执行验证
有了关键的模型和数据集加载器的准备后,可以正式进入执行验证逻辑的代码。此处的主要核心代码吃基类没有定义的,需要在其子类面对的具体模式、具体需求自定义,因此此处只记录几个主要方法大概实现“目的”。
首先是数据的前处理——Preprocess,该部分主要涉及模型预测前的图像尺寸调整、归一化等前置操作,具体要看子类定义。
然后进入模型推理——Inference,该部分可以选择是否启用数据增强augment,其会得到模型的预测结果。
再如果是训练模式,会进行损失计算——Loss,通过model的计算损失的方法(输入真实标签框batch和预测标签框pred)累加损失进训练模型
继续对预测的结果还会做后处理——Postprocess,该部分也是子类定义,一般是指做非极大值抑制(NMS)等操作。
最后将预测和真实框和类型信息输入验证统计指标计算的方法,得到评估的最终指标,这些指标至少包括精度、召回率、maP、IoU等。

(3)指标结果统计
最后部分就是对之前批次读取验证集推理计算验证指标后的完整汇总了,并且会打印相关重要的统计信息。
由于该部分逻辑也是在基类外的子类编写,这里也粗略概括,在一篇文章的具体子类例子中再详细分析。

4.match_predictions:真实与预测框配对算法
下面记录BaseValidator中另一个很重要的方法——match_predictions,顾名思义,其是用来将模型检测的框和其对应位置的验证集中真实框进行配对,以方便后续验证指标计算的。
下面分三个方面来记录该重要方法,分别是——1.输入 2.输出 3.内部逻辑
(1)输入解读与构建
首先来看该算法的输入参数,根据官方解释记录在下面表格。
| pred_classes | 检测到的类别号,数量对应检测的框数,torch.Tensor数据类型,形状(N,) |
| true_classes | 真实验证集中的类别号, 数量对应真实样本框数,torch.Tensor数据类型,形状(M,) |
| iou | 检测和真实框每个框两两对应的iou结果矩阵,行代表检测的,列代表真实的,torch.Tensor数据类型,形状(N,M) |
| use_scipy | 是否使用scipy库进行精确二分图最大匹配 |
下面根据上面的参数输入解读含义,构建一个测试样本示例,来方便解读算法含义。下面代码实现了生成一个随机的上述输入所需的验证、检测和 iou 结果。
from PIL import Image, ImageDraw
import random
import os
import torch
import numpy as np
from ultralytics.utils.metrics import box_iou
def generate_true(savefile, imgsz=(640,640), num=5, seed=35):
img = Image.new('RGB', imgsz, (255,255,255)) # 纯白背景
draw = ImageDraw.Draw(img)
bboxes = [] # 保存真实的目标检测框
if seed is not None:
random.seed(seed) # 设置随机种子
for _ in range(num):
# 选择图像类型
shape_type = random.choice(['rectangle', 'circle'])
# 随机形状
x1, y1 = random.randint(50, imgsz[0]-100), random.randint(50, imgsz[1]-100)
x2, y2 = random.randint(x1+20, imgsz[0]-80), random.randint(y1+20, imgsz[1]-80)
# 生成图像
if shape_type == 'rectangle':
draw.rectangle([x1, y1, x2, y2], outline='black', fill='blue')
bbox = (x1-8,y1-8,x2+8,y2+8, 0)
elif shape_type == 'circle':
radius = random.randint(10,30)
cx, cy = random.randint(x1+radius, x2-radius),random.randint(y1+radius, y2-radius)
draw.ellipse([cx-radius, cy-radius, cx+radius, cy+radius], outline='black', fill='red')
bbox = (cx-radius-8, cy-radius-8, cx+radius+8, cy+radius+8, 1)
bboxes.append(bbox)
savedir = os.path.join(savefile, 'test.jpg')
img.save(savedir)
# 真实框可视化
vis_img = img.copy()
for b in bboxes:
vis_draw = ImageDraw.Draw(vis_img)
vis_draw.rectangle(tuple(b[:4]), outline='black', width=2)
visdir = os.path.join(savefile, 'vis.jpg')
vis_img.save(visdir)
return bboxes, img, vis_img
def virtual_pred(savefile, img, true_boxes, pred_ratio=0.8, noise_num=3, imgsz=(640,640), offset=0.05):
offset_box = []
# 加入真实框的小偏移
for box in true_boxes[:int(pred_ratio*len(true_boxes))]:
xmin, ymin, xmax, ymax, cls = box
width = xmax-xmin
height = ymax-ymin
offset_x = random.uniform(-width*offset, width*offset)
offset_y = random.uniform(-height * offset, height * offset)
new_xmin = max(0, xmin+offset_x)
new_ymin = max(0, ymin+offset_y)
new_xmax = min(imgsz[0], xmax+offset_x)
new_ymax = min(imgsz[1], ymax+offset_y)
if new_xmax > new_xmin and new_ymax > new_ymin:
offset_box.append((new_xmin, new_ymin, new_xmax, new_ymax, cls))
# 加入噪音框
for _ in range(noise_num):
n_wid = random.randint(30,80)
n_hgt = random.randint(30,80)
n_xmin = random.randint(0, imgsz[0]-n_wid)
n_ymin = random.randint(0, imgsz[1]-n_hgt)
offset_box.append((n_xmin, n_ymin, n_xmin+n_wid, n_ymin+n_hgt, 2))
for b in offset_box:
draw = ImageDraw.Draw(img)
draw.rectangle(tuple(b[:4]), outline='yellow', width=2)
visdir = os.path.join(savefile, 'box.jpg')
img.save(visdir)
return offset_box, img
if __name__=='__main__':
savefile = './'
# 真实框、图片、真实框可视化图
bboxes, img, vis = generate_true(savefile)
# 预测框、预测框可视化
preds, p_vis = virtual_pred(savefile, vis, bboxes)
# 框信息转为torch.tensor类型
pt_true = torch.from_numpy(np.array(bboxes, dtype=np.int32))
pt_pred = torch.from_numpy(np.array(preds, dtype=np.int32))
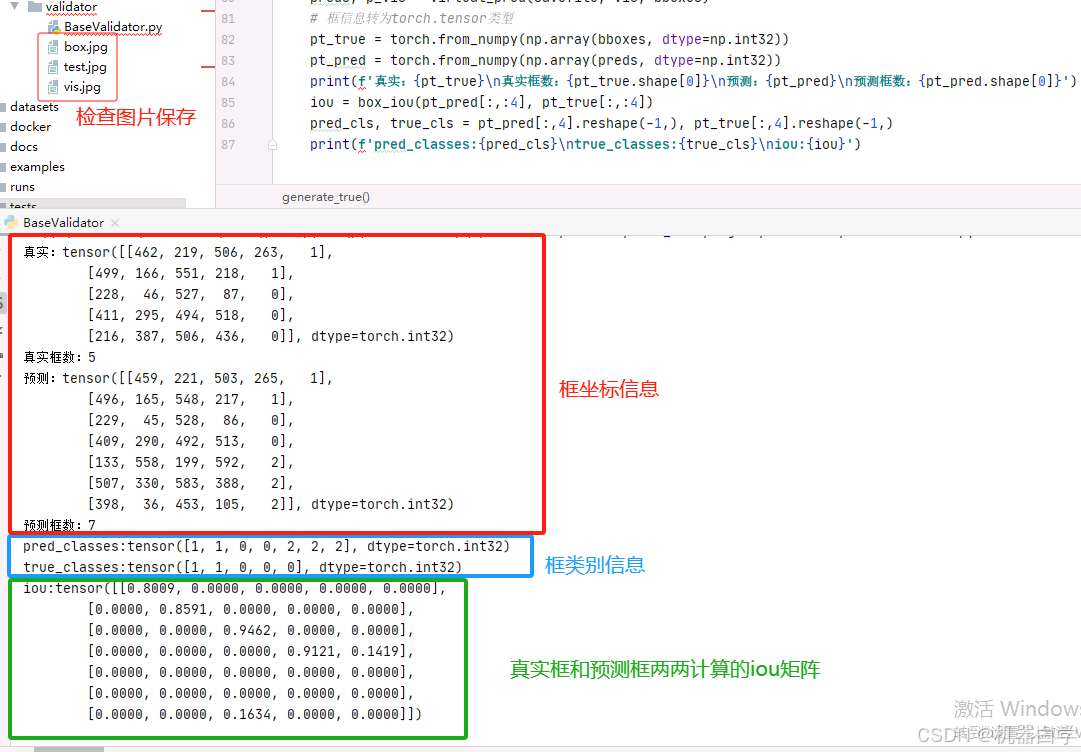
print(f'真实:{pt_true}\n真实框数:{pt_true.shape[0]}\n预测:{pt_pred}\n预测框数:{pt_pred.shape[0]}')
iou = box_iou(pt_true[:,:4], pt_pred[:,:4])
pred_cls, true_cls = pt_pred[:,4].reshape(-1,), pt_true[:,4].reshape(-1,)
print(f'pred_classes:{pred_cls}\ntrue_classes:{true_cls}\niou:{iou}')运行上述代码会在指定的savefile文件处保存原图图片、真实框和预测框的可视化图片。 下图可见,在纯白背景的随机位置生成了形状随机的矩形和圆形。其中第二张图的黑色框代表验证集的真实框,第三张图黄色框模拟了模型预测框(可能存在噪音)
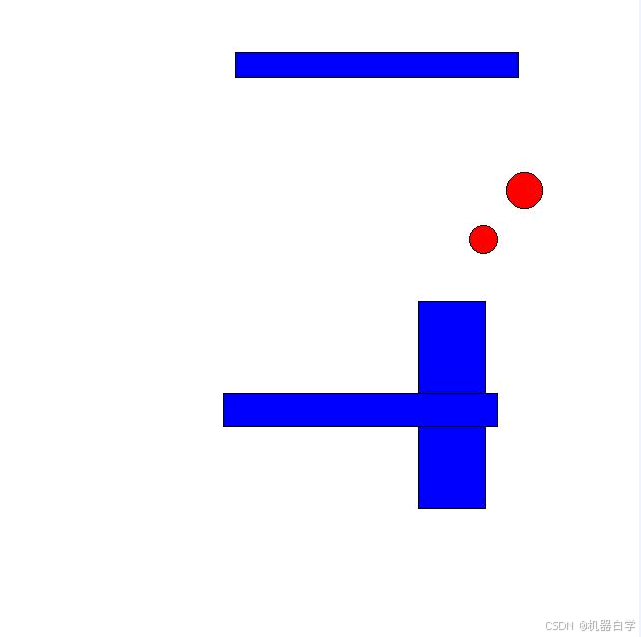
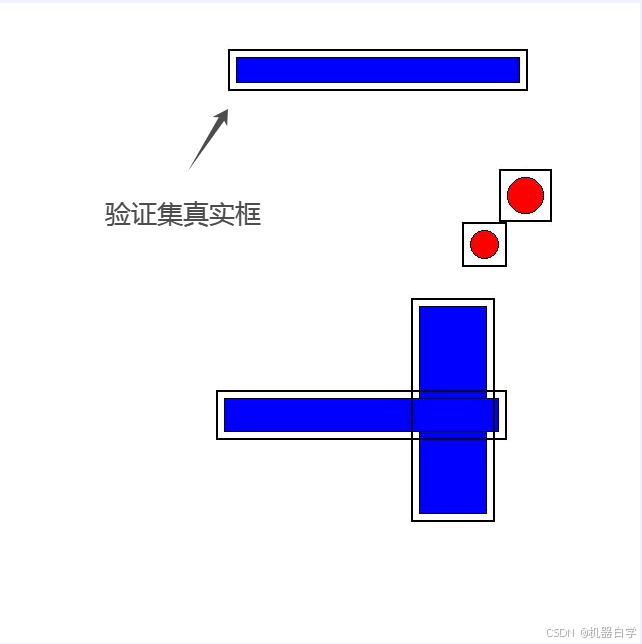

下面继续解读上述代码的打印结果。首先是框的坐标信息,红色框中,这些可以修改代码方法参数来改变生成的框数,其中每行代表一个检测框,前四个值是坐标信息,最后一个值代表类别信息(本例中 0 代表矩形,1 代表圆形)。
然后是输入match_predictions中的重要参数——检测和真实的类别(蓝色框信息)和 iou 矩阵,这里的iou矩阵信息是直接使用 ultralytics.utils.metrics 中定义的 box_iou 方法计算得出,矩阵的每个值代表两框间的位置近似程度。
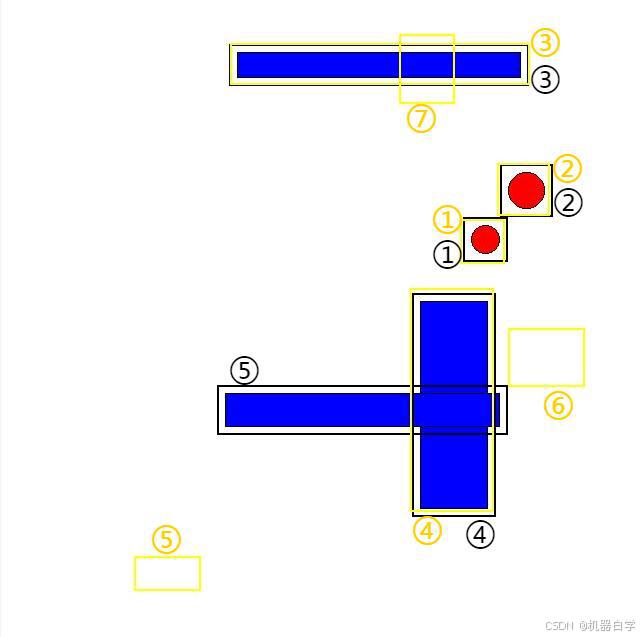
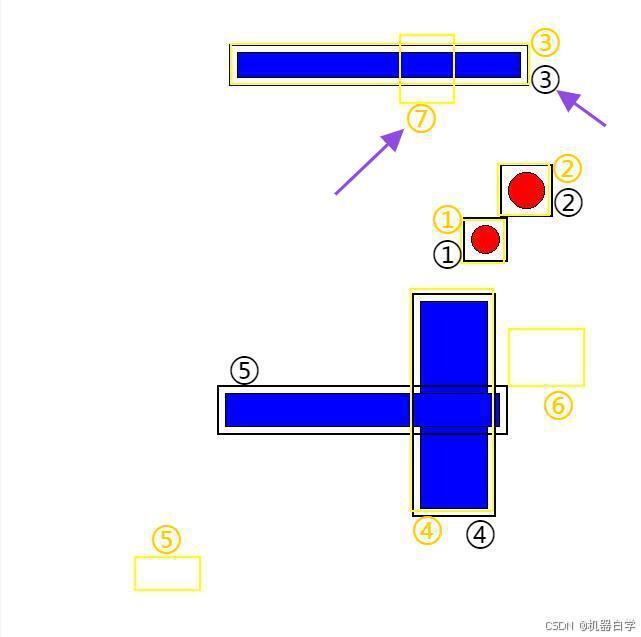
具体来说 iou 矩阵是符合官方输入要求的,这在运筹学中又称为匹配矩阵(指此处iou结果),即每列代表预测的所有框,列代表真实的所有框,矩阵中每个值是两两框匹配计算的结果。如下图所示,如果两框近似重叠,如蓝色①和红色①,则对应位置值大(0.8009),反之对于蓝色①的其他真实框与之计算结果都是0,因此可知蓝色①检测框对应红色①真实框。


上图通过编号可以看到 iou 矩阵中真实框和红色框的①号(即iou矩阵第一个值)是横向纵向最高的,这代表红色编号①和蓝色编号①应该是配对框。
下图可以清晰看到配对关系,而且可以看到蓝色编号⑤⑥⑦都是噪音框,其对应行的iou都没有超过0.2的。而红色编号⑤该列也没有大于0.2的,代表该真实框被“检测漏掉”了。
有了上述对于输入的解读和虚拟构建后,就可以正式开始测试 match_predictions 方法了。
(2)输出
有了上述构建的虚拟模拟输入——预测框类别、真实框类别、根据框坐标计算的 iou 矩阵后,就可以实验该方法的输出效果了。
但在具体运行前,还需要在初始化中定义一个全局参数:iouv(框交并比匹配区间)。这个参数就是在使用YOLO训练或者验证时得到的指标结果——mAP50-95中的50-95,代表在交并比50-95区间下的准确率。下面先定义(并打印)该指标参数,后面再结合match_predictions的输出结果,详细解释这个指标的含义。
首先在定义我们自己的验证器实例中加上这个 iouv 的具体数值定义,这里使用官方的标准,实际中可以根据需要修改这里的数值。打印一下运行结果检查。
# 在自定义验证器中加入iouv
class My_Validator(BaseValidator):
def __init__(self, dataloader=None, save_dir=None, pbar=None, args=None, _callbacks=None):
super().__init__(dataloader, save_dir, pbar, args, _callbacks)
self.iouv = torch.linspace(0.5, 0.95, 10) # IoU vector for [email protected]:0.95
print(f'iouv:{self.iouv}')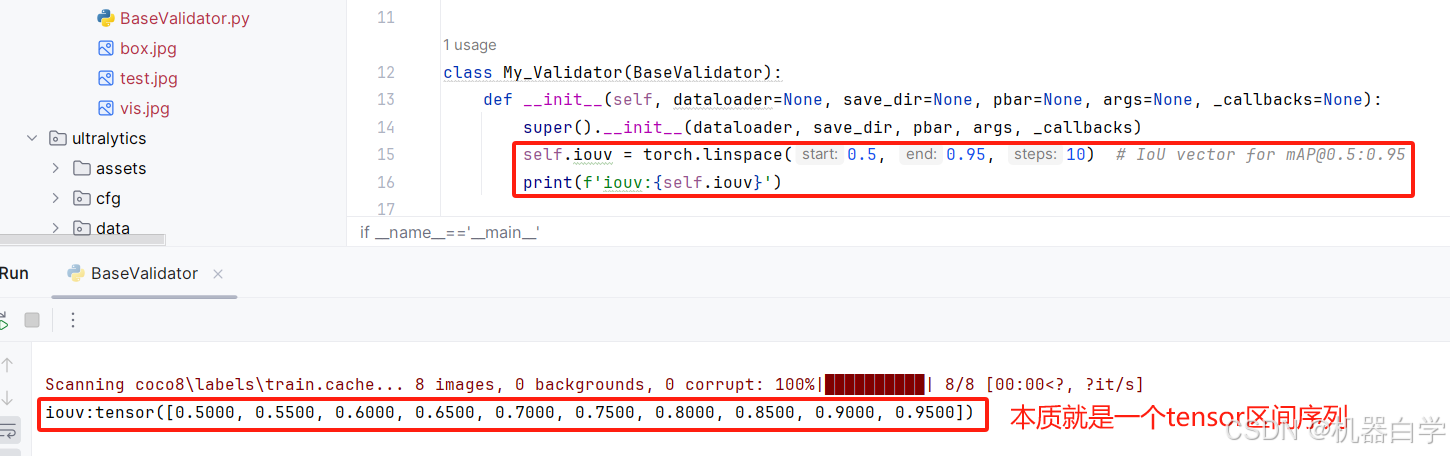
有了上述所有准备之后,现在可以放心使用该方法了,将之前定义虚拟的数据结果输入,得到以下结果。
# 输入上述虚拟预测类别、真实类别和iou矩阵
results = val.match_predictions(pred_cls, true_cls, iou)
print(f'match_prections results:\n{results}')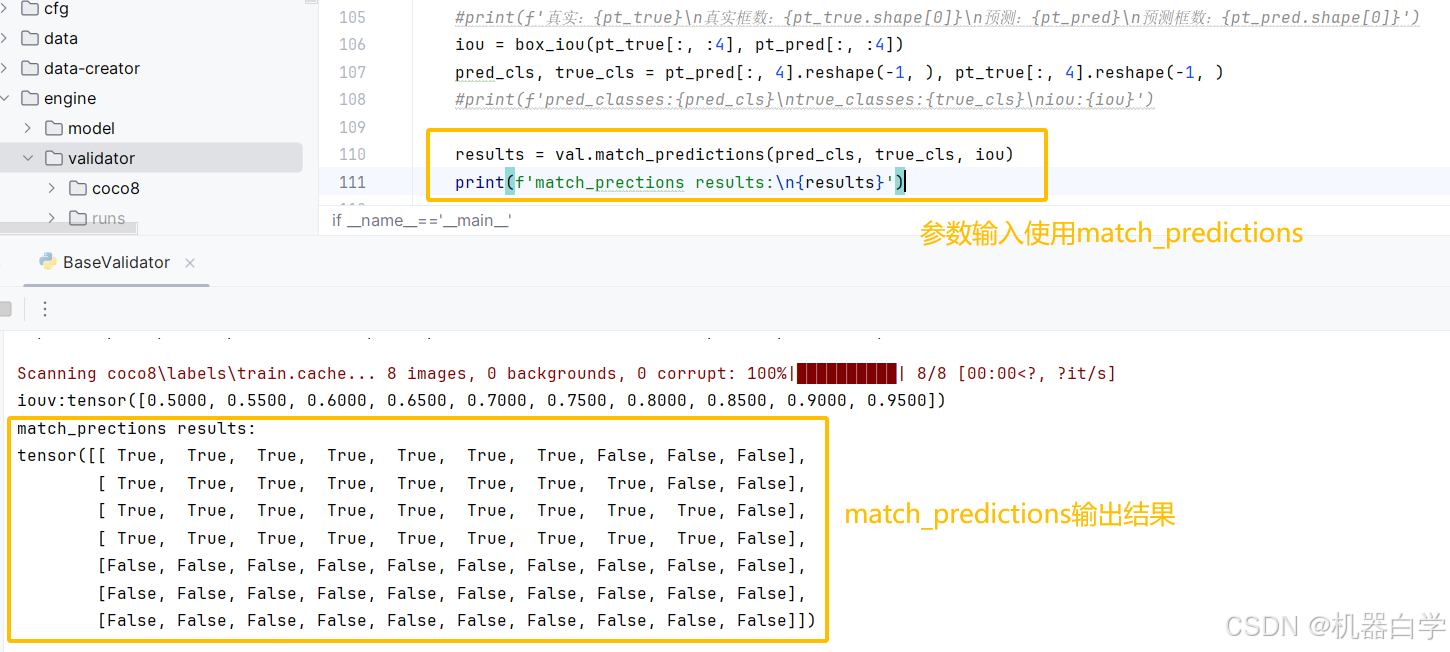
下面来具体分析输出结果。
首先输出还是一个tensor布尔矩阵,形状(预测框类别数量 x 10),意思是输出永远是以模型预测框结果为基准,行依次代表了每个预测框,列数固定为10。实际上这里的列数就是定义的 iouv 区间长度。
如下图所示,每个框在列不同的 iou 交并比阈值下,如果对应值为 True 则代表该预测框存在真实框与其位置“近似对应重叠”,且预测与真实识别的类别索引号相同。
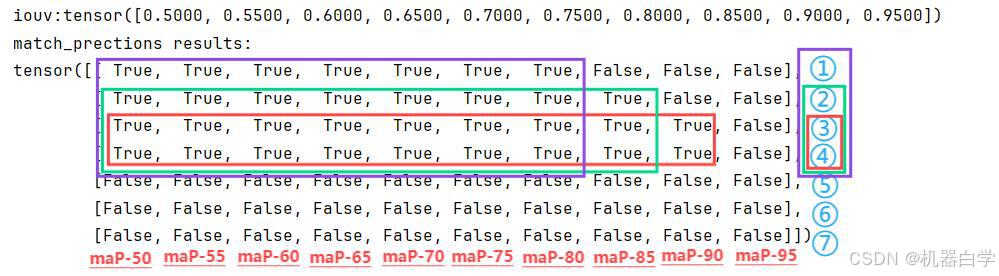
从虚拟检测框(下图黄色框)和上述结果的对应关系可以更清晰看到,①②③④号框都“近似”和真实框重叠是正确预测。在不同的iou阈值下,可能其结果会变化,但总的来说,如果在阈值 0.8 下,这四个框都可以视为“正确框”,下图也体现了这一点。
而⑤⑥号框没有框住任何物体属于“噪音”,⑦号框只框住了部分目标, 且其识别类别出错,与真实框的iou值也小于最低的0.5,因此前面这三个框对于行都是False。
还可以注意到,match_predictions 是以预测结果为基准的,这可能会带来一个风险——真实框的漏检无法从输出结果体现。对于验证来说,这点可以从之后的召回率表现,但对于训练中的损失累加,使用match_predictions 方法会带来模型漏检增多的风险(这个问题:漏检也在实际数据集中实验得到验证)。
上述只关心预测正确的样本好处是可以帮助模型更快速收敛(即对于预测正确的样本其对应的损失梯度更大)。当然,这些都是后话了,在后续具体构建验证器和训练器章节再详细分析该部分内容,并尝试改写部分源码。
(3)方法逻辑:两种匹配算法
有了上述的输入输出分析后,已经可以基本使用该方法。总结来说,其实现的功能就是计算在不同框重叠度iou阈值下,预测框匹配真实框的正确情况。
下面开始具体分析该方法内部代码的实现逻辑。在本部分为了方便理解,会逐一打印过程变量,一步步解释其中的变化过程。
首先是初始化最终的输出矩阵。可以再次看见是以预测框的数量和自定义的阈值区间数量构成行列的布尔矩阵。

然后会根据预测框与真实框类别的匹配情况,将 iou 矩阵中两两对应框中类别不匹配的都归为0,这样是将类别匹配信息考虑进了 iou位置信息矩阵。
如下图预测⑦号框和真实③号框,由于预测的是噪音类(2),真实框是矩形类(0),因此经过此处操作会直接pass这两个框的联系——对应iou位置(黄框)变为0。


有了上述准备,遍历自定义阈值区间内的阈值,进行匹配。这里官方提供了两种算法,我们先从简单阈值匹配开始。
①简单阈值匹配算法
下面以 mAP阈值90(0.9)为例,可以看到得到的matches是满足大于阈值的行和列一一对应的索引值。在iou矩阵中对应(2,2)和(3,3)位置。

下面的操作考虑的是一个真实框对应多个可能的预测框的情况,由于上述简单的虚拟场景没有出现这种情况,因此调整之前的虚拟生成函数中的参数——预测框的数量,下面虚拟了这一复杂场景,并且还是以 mAP阈值90(0.9)为例。
下面先解释三个连续的操作。
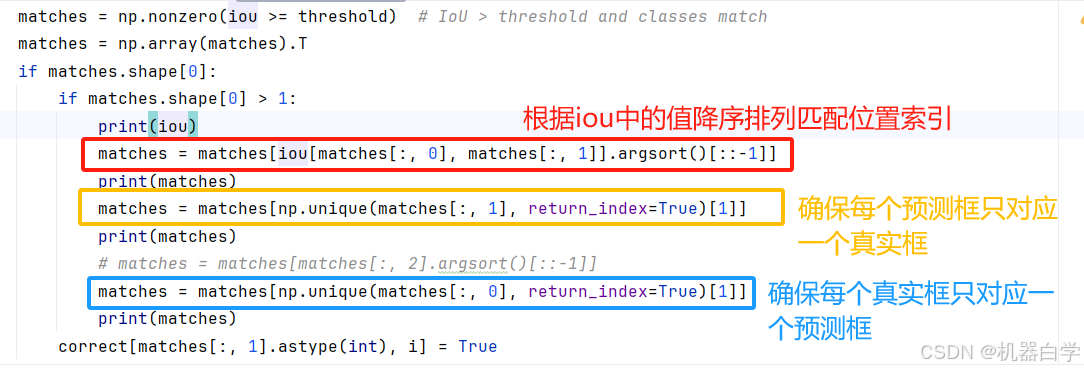
其本质就是预测框和真实框一一对应,去除匹配中的重复框选项,且只取第一次出现满足阈值那个对应框(列从上往下看,行从左往右看)。下图具体结果理解展示。
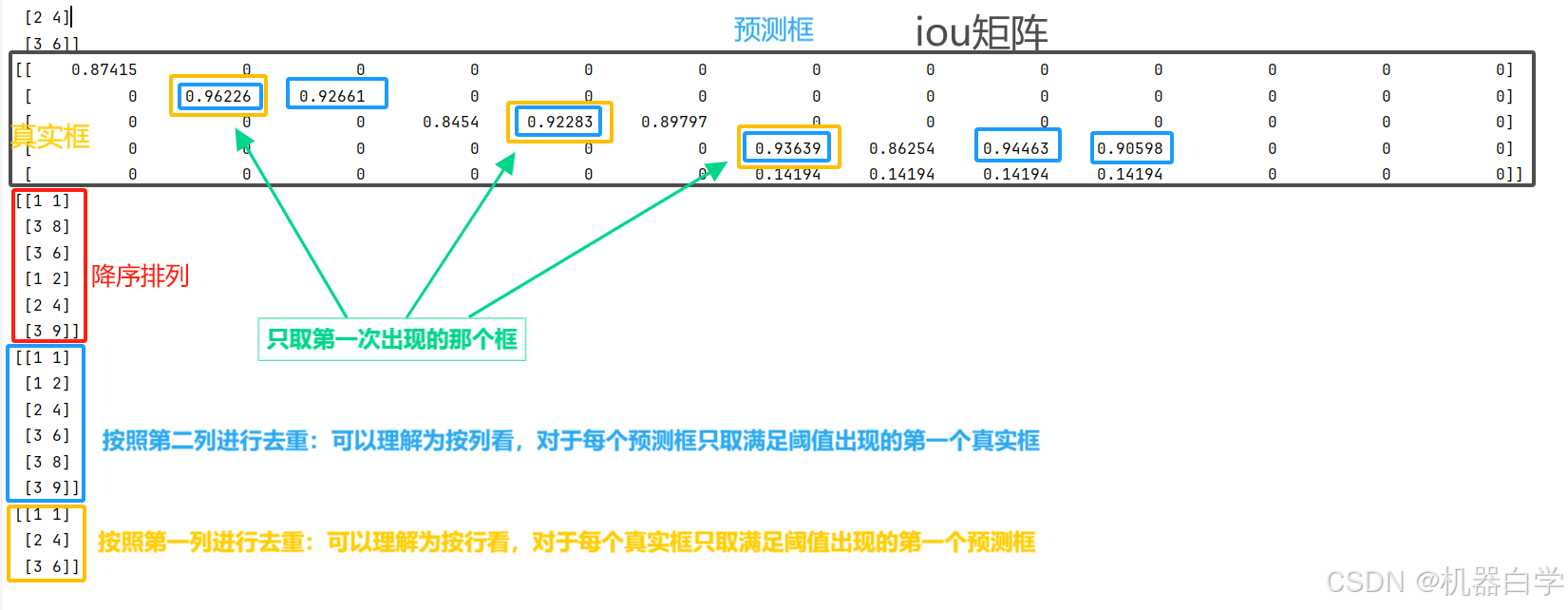
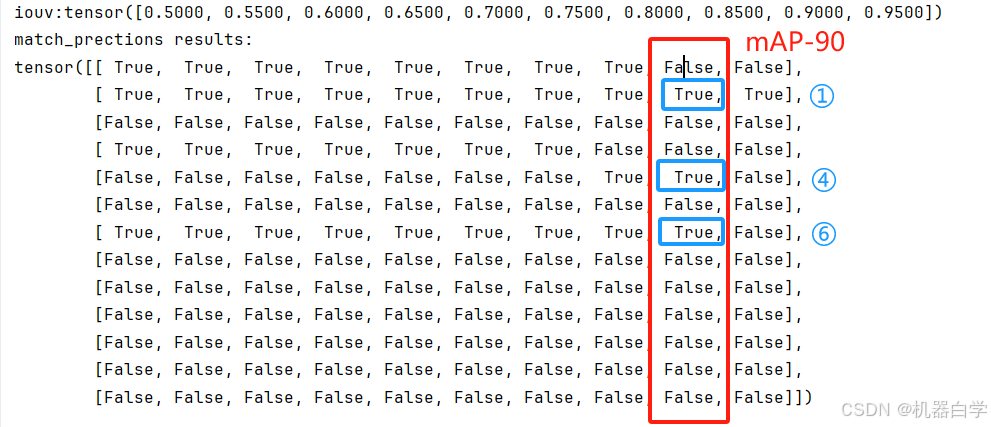
最终将不同阈值下,满足条件的预测框索引位置设为True就得到了最终结果。还是以 mAP阈值90(0.9)为例,上述结果表明,在0.9阈值下,只有索引为【1,4,6】的预测框是满足要求的“正确框”,最终结果也反映了这一问题(最终结果行代表预测框索引)
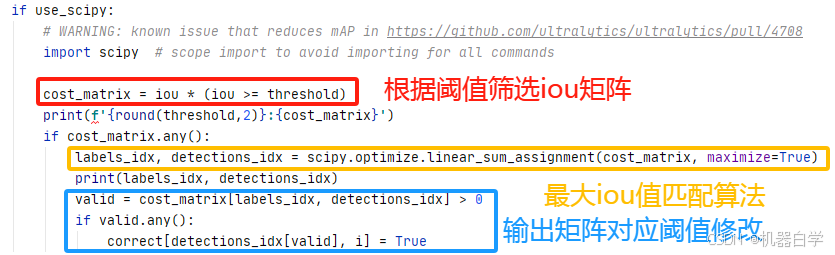
②Scipy优化匹配算法
除了上述简单的匹配算法——选择第一次出现的匹配框,match_predictions还支持Scipy库下的优化匹配算法。只需在输出参数中将 use_scipy 开关打开为True。
这里不讨论其中具体的线性指派算法scipy中的逻辑,只打印最终结果。结果表明,该算法匹配会考虑iou值信息,如果存在多个匹配框会选择其中 iou 值最大的(对比简单匹配只会选择第一次出现的框,因为使用的是numpy简单去重算法)
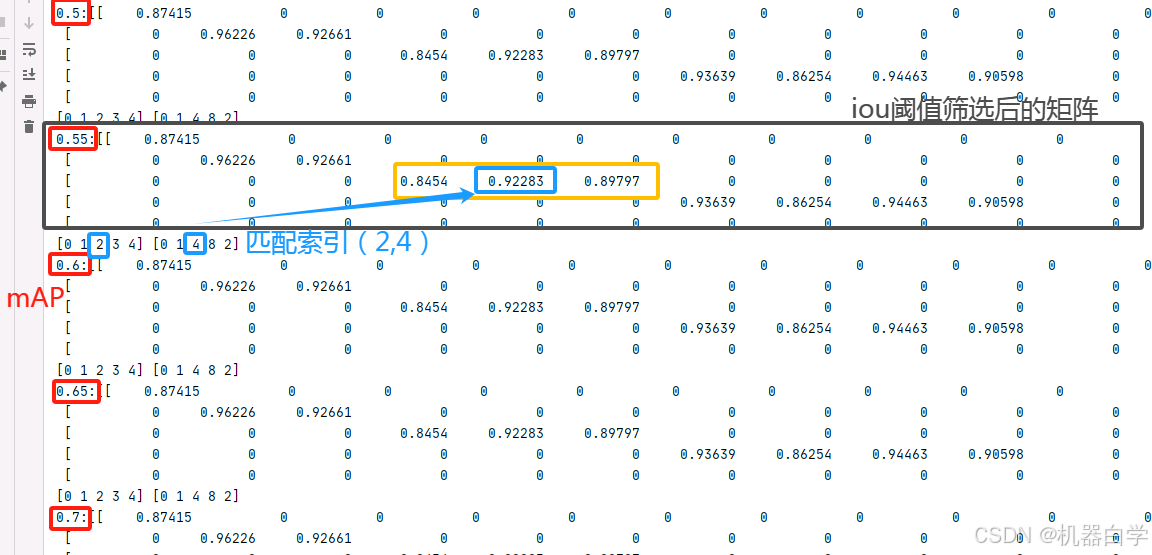
下图以红框中的mAP55为例,首先会根据阈值筛选 iou 矩阵,只保留大于0.55的。可以看到第三行(对应索引为2的真实框)有三个值的预测框(对应列)与该真实框对应。在可选的黄色框内的预测框中,最后选择到的匹配框是蓝色框对应iou矩阵索引位置(2,4),这也是该行iou值最大的。
对比之前的简单算法,在该情况下选择的应该是从左往右第一次出现的匹配框(2,3),对应 iou值为0.8454,不是该行最大的,因此匹配的两个框也不是最近似的。
因此优化后的算法,考虑了iou值,保证了匹配的两个框是最近似的,这在要求高精度预测框的实践中有用,使得评估更加精确。
最后输出上,输出结果矩阵跟简单算法理论上是一致的——这是因为输出结果只统计是否有匹配框这一粗略信息,而不关心匹配哪个框更近似,因此不管是简单算法还是优化算法,只要该预测框在当前阈值下有真实框与其对应,那么两个算法就都返回相同的 True 值。
不过如果后续要统计匹配框的更精确的近似程度,而不是存在与否这种单一信息,使用优化算法更好(当然这需要源码修改,自定义自己的验证器)。
至此,验证器基类介绍解读完毕。该基类规定了所有验证过程的代码逻辑,这样标准化的流程在后续创建验证器时无需修改,只用方便的定义相关流程中的具体方法,就可以实现多种任务的扩展。
同时该基类另一个重点就是定义了匹配算法——match_predictions,该方法以预测框为锚点,通过多种 iou 阈值使用真假二值来批判预测框的“正确与否”,提供了一个非常方便简单好用的多真实框多预测框多阈值的统计算法,是对预测结果进行评估的一种实用方法。
在下一章节,将暂时跳过训练器等其他在engine下的基类分析,趁热打铁,继续分析验证器,在验证器基类的基础上,解读 detect 检测任务的验证器具体是如何构建并实验的,详情参见开头目录文章的更新。