目录
2.3 最大池化索引(Max-pooling Indices)
摘要
本周阅读的论文题目是《SegNet:A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation》(《SegNet:一种用于图像分割的深度卷积编码器-解码器架构》)。本文中提出了一种新颖实用的用于语义像素分割的深度全卷积神经网络架构-SegNet。SegNet由一个编码器网络、一个相应的解码器网络和一个像素分类层组成。编码器网络的架构在拓扑上与VGG 16网络中的13个卷积层相同,去除了3个全连接层。解码器是与编码器一一对应的,作用是将低分辨率编码器特征图映射到全输入分辨率特征图以进行逐像素分类。SegNet的主要创新之处在于解码器使用在对应编码器的最大池化步骤中计算的池化索引来执行非线性上采样,这消除了学习上采样的需要,减小了计算量。SegNet旨在设计快速、存储空间较小的适用于实时应用的架构,所以它的可训练参数数量明显少于其他架构,并且可以使用随机梯度下降进行端到端训练,从而提供了良好的性能、有竞争力的推理时间和最有效的推理内存。
Abstract
The paper I read this week is titled "SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation." In this paper, a novel and practical deep fully convolutional neural network architecture for semantic pixel segmentation is proposed, SegNet. SegNet consists of an encoder network, a corresponding decoder network, and a pixel classification layer. The architecture of the encoder network is topologically identical to the 13 convolutional layers in the VGG 16 network, with 3 fully connected layers removed. The decoder is a one-to-one correspondence with the encoder, and its function is to map the low-resolution encoder feature map to the full-input resolution feature map for pixel-by-pixel classification. The main innovation of SegNet is that the decoder performs nonlinear upsampling using the pooling index computed in the maximum pooling step of the corresponding encoder, which eliminates the need to learn to upsample and reduces the computational effort. SegNet is designed to be a fast, small-storage architecture for real-time applications, so it has a significantly lower number of trainable parameters than other architectures, and can be trained end-to-end using stochastic gradient descent, providing good performance, competitive inference time, and the most efficient inference memory.
文献链接🔗:A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
1 引言
在上周学习到的FCN方法中试图直接采用为类别预测设计的深度架构进行像素级标注。虽然结果非常鼓舞人心,但看起来比较粗糙。主要是因为最大池化和上采样降低了特征图分辨率。
而本文中的SegNet旨在成为像素级语义分割的高效架构。SegNet主要受道路场景理解应用的启发,在典型的道路场景中,大多数像素属于大型类别,如道路、建筑物,因此网络必须产生平滑的分割。架构还必须能够根据物体的形状来描绘物体,即使它们很小,因此,SegNet需要满足将低分辨率特征映射到输入分辨率进行像素级分类的需求,并使这种映射产生对准确边界定位有用的特征。而从计算角度来看,网络在推理过程中必须在内存和计算时间上高效。所以SegNet能够使用如随机梯度下降(SGD)等高效权重更新技术端到端训练,以联合优化网络中的所有权重。
SegNet中的编码器网络在拓扑上与VGG16的13个卷积层相同,但是移除了VGG16中的3个全连接层,这使得SegNet编码器网络比许多其他架构显著更小且更容易训练。
SegNet的关键组件是解码器网络,它由一系列解码器组成,每个解码器对应一个编码器。在这些解码器中,适当的解码器使用从相应编码器接收到的最大池化索引来对其输入特征图进行非线性上采样。在解码过程中重用最大池化索引具有几个实际优点:
- 改善了边界划分;
- 减少了参数数量,从而实现端到端训练;
- 这种上采样形式可以仅通过少量修改集成到任何编码器-解码器架构。
2 SegNet架构
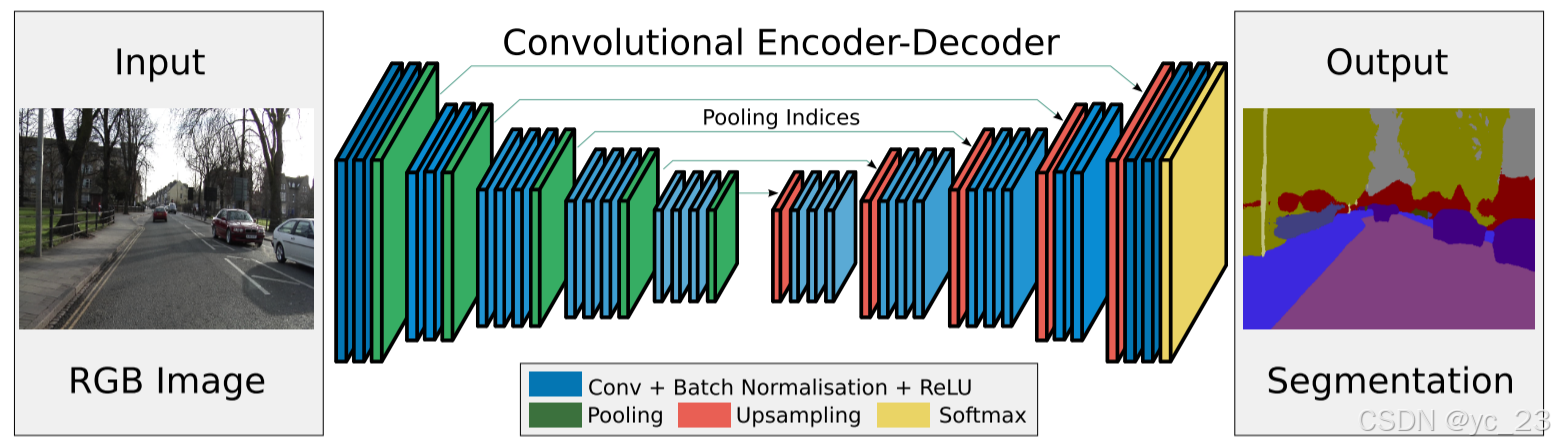
SegNet由编码器网络和相应的解码器网络,之后是一个最终的像素级分类层,如上图所示。编码器网络由13个卷积层组成,对应于VGG16网络中用于物体分类的前13个卷积层。因此,可以从在大数据集上训练的分类权重初始化训练过程。丢弃3个全连接层,以保留最深编码器输出的更高分辨率特征图。这也在很大程度上减少了SegNet编码器网络中的参数数量(从1.34亿减少到1470万)。每个编码器层都有一个相应的解码器层,因此解码器网络有13层。最终的解码器输出被送入多类softmax分类器,以独立地为每个像素产生类别概率。
2.1 编码器网络
编码器网络采用VGG16的前13层卷积层,并丢弃了VGG16的3个全连接层,该部分提取输入特征,用于目标分类,这就是使用预训练的VGG原理所在,至于丢弃全连接层层是为了保持更高的分辨率也减少了参数数量。将13个卷积层和5个池化层划分为5个编码器,单个编码器的组成部分如下:
- 滤波器组:由负责提取图像特征的多个卷积层组成;
- BN层:为执行批量归一化操作的Batch Normalization,加速学习;
- 非线性层:为执行非线性操作的ReLU激活函数
;
- 最大池化层:使用2×2大小、步长为2的滑动窗口,并将结果输出以 2 的倍数进行下采样;
最大池化用于在输入图像的小空间位移上实现平移不变性。但是下采样导致特征图中的每个像素都有一个大的输入图像上下文,会导致特征图的空间分辨率会降低。因此,在执行下采样之前,有必要在编码器特征图中捕获和存储边界信息。所以,本文中提出了一种有效的方式,即最大池化索引来存储这些信息,通过仅存储最大池化索引的方式,即对于每个编码器特征图,每个池化窗口中最大特征值的定位被记住。
解码器网络代码如下:
bn_momentum = 0.1 # BN层的momentum,改变数据分布,归一化加速收敛
class Encoder(nn.Module):
def __init__(self, input_channels):
super(Encoder, self).__init__()
#前13层是VGG16的前13层,分为5个stage
#因为在下采样时要保存最大池化层的索引, 方便起见, 池化层不写在stage中
self.enco1 = nn.Sequential(
nn.Conv2d(input_channels, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64, momentum=bn_momentum),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64, momentum=bn_momentum),
nn.ReLU()
) # 编码器1,包含2个卷积层
self.enco2 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128, momentum=bn_momentum),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128, momentum=bn_momentum),
nn.ReLU()
) # 编码器2,包含2个卷积层
self.enco3 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256, momentum=bn_momentum),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256, momentum=bn_momentum),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256, momentum=bn_momentum),
nn.ReLU()
) # 编码器3,包含3个卷积层
self.enco4 = nn.Sequential(
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512, momentum=bn_momentum),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512, momentum=bn_momentum),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512, momentum=bn_momentum),
nn.ReLU()
) # 编码器4,包含3个卷积层
self.enco5 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512, momentum=bn_momentum),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512, momentum=bn_momentum),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512, momentum=bn_momentum),
nn.ReLU()
) # 编码器5,包含3个卷积层
def forward(self, x):
# 用来保存各层的池化索引
id = []
x = self.enco1(x)
x, id1 = F.max_pool2d(x, kernel_size=2, stride=2,
return_indices=True) # 保留编码器1最大值的位置索引
id.append(id1)
x = self.enco2(x)
x, id2 = F.max_pool2d(x, kernel_size=2, stride=2,
return_indices=True) # 保留编码器2最大值的位置索引
id.append(id2)
x = self.enco3(x)
x, id3 = F.max_pool2d(x, kernel_size=2, stride=2,
return_indices=True) # 保留编码器3最大值的位置索引
id.append(id3)
x = self.enco4(x)
x, id4 = F.max_pool2d(x, kernel_size=2, stride=2,
return_indices=True) # 保留编码器4最大值的位置索引
id.append(id4)
x = self.enco5(x)
x, id5 = F.max_pool2d(x, kernel_size=2, stride=2,
return_indices=True) # 保留编码器5最大值的位置索引
id.append(id5)
return x, id2.2 解码器网络
解码器部分主要负责将特征图恢复到原始输入图像相同的空间分辨率,并生成分割结果。解码器也是13层,对应编码器的13层,编码器网络-解码器网络结构呈现对称结构,因此解码器网络也包含5个解码器组成,单个解码器组成部分如下:
- 上采样层:输入编码器下采样时保留的位置,用于将图像恢复到更高空间分辨率;
- 滤波器组:由对经过上采样的特征图进行特征提取和整合的多个卷积层组成:
- BN层:为执行批量归一化操作的Batch Normalization;
- 非线性层:采用执行非线性操作的ReLU激活函数
- softmax层:为k类的分类器,用于预测每个像素的类别,其在解码器的最后一层。
编码器网络+解码器网络组成的SegNet架构代码如下:
class SegNet(nn.Module):
def __init__(self, input_channels, output_channels):
super(SegNet, self).__init__()
self.weights_new = self.state_dict()
# 加载Encoder
self.encoder = Encoder(input_channels)
self.deco1 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512, momentum=bn_momentum),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512, momentum=bn_momentum),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512, momentum=bn_momentum),
nn.ReLU()
) # 解码器1,对应编码器5
self.deco2 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512, momentum=bn_momentum),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512, momentum=bn_momentum),
nn.ReLU(),
nn.Conv2d(512, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256, momentum=bn_momentum),
nn.ReLU()
) # 解码器2,对应编码器4
self.deco3 = nn.Sequential(
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256, momentum=bn_momentum),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256, momentum=bn_momentum),
nn.ReLU(),
nn.Conv2d(256, 128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128, momentum=bn_momentum),
nn.ReLU()
) # 解码器3,对应编码器3
self.deco4 = nn.Sequential(
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128, momentum=bn_momentum),
nn.ReLU(),
nn.Conv2d(128, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64, momentum=bn_momentum),
nn.ReLU()
) # 解码器4,对应编码器2
self.deco5 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64, momentum=bn_momentum),
nn.ReLU(),
nn.Conv2d(64, output_channels, kernel_size=3, stride=1, padding=1),
) # 解码器5,对应编码器1
def forward(self, x):
x, id = self.encoder(x)
# 池化索引上采样
x = F.max_unpool2d(x, id[4], kernel_size=2, stride=2)
x = self.deco1(x)
x = F.max_unpool2d(x, id[3], kernel_size=2, stride=2)
x = self.deco2(x)
x = F.max_unpool2d(x, id[2], kernel_size=2, stride=2)
x = self.deco3(x)
x = F.max_unpool2d(x, id[1], kernel_size=2, stride=2)
x = self.deco4(x)
x = F.max_unpool2d(x, id[0], kernel_size=2, stride=2)
x = self.deco5(x)
return x2.3 最大池化索引(Max-pooling Indices)
如下图所示,SegNet中的池化处理对应一个2×2非重叠最大池化,2×2区域中的最大值被保留并传递给下一层。
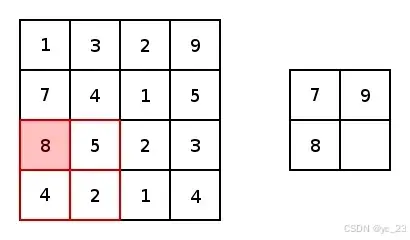
上采样是池化的反向处理,但是在上采样当中存在着一个不确定性,即一个1×1的特征点经过上采样将会变成一个2×2特征区域,这个区域中的任意或者事先规定好的某个1×1区域将会被原来的1×1特征点取代,其他的三个区域为空,而这样就会引入一些误差,并且这些误差会传递给下一层,层数越深,误差影响的范围也就越大,所以把1×1特征点放到正确的位置至关重要。
而在SegNet中采用了池化索引的方法来保存池化点的来源信息。即在编码器的池化层处理中,会记录每一个池化后的1×1特征点来源于之前的2×2的哪个区域。而池化索引会在解码器中使用,由于SegNet是一个对称网络,在解码器中需要对特征图进行上采样的时候,我们就可以利用它对应的池化层的池化索引来确定某个1×1特征点应该放到上采样后的2×2区域中的哪个位置,如下图所示:
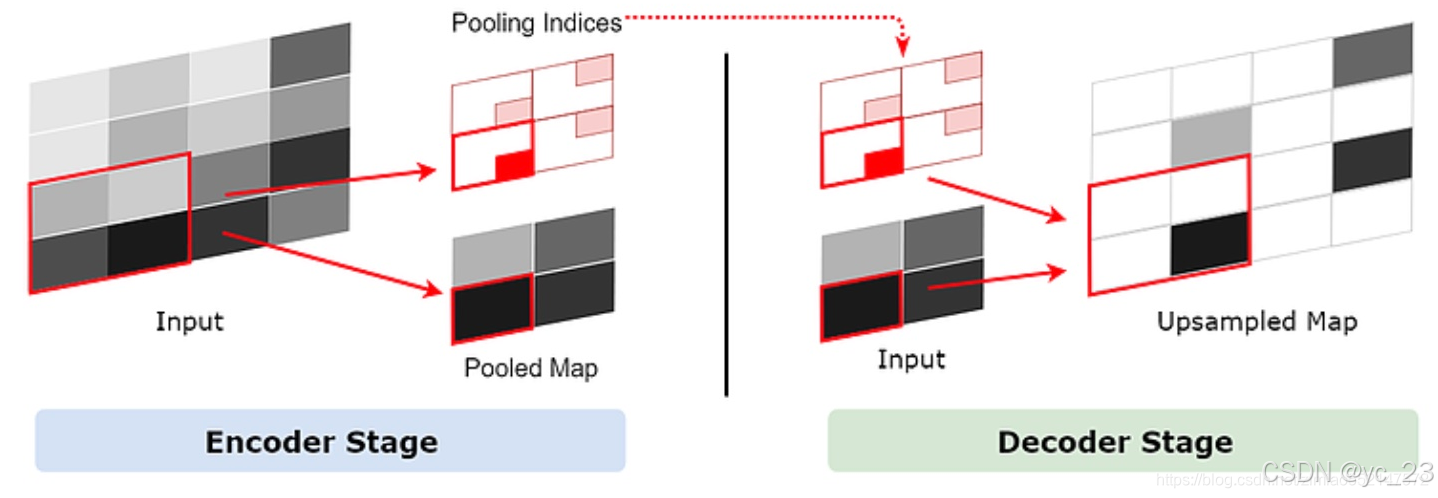
由于采用了最大池化和池化索引的方法,所以结合起来就叫做最大池化索引(Max-pooling Indices)。
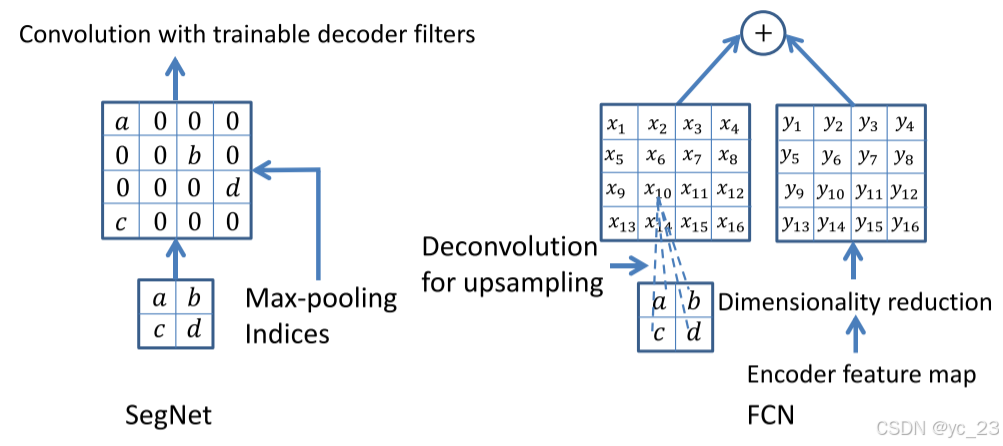
对比SegNet使用的最大池化索引和FCN使用的反卷积方法:
- 最大池化索引:SegNet使用最大池化索引来上采样特征图并卷积一个可训练的解码器滤波器库,由于上采样过程无需学习,计算成本较低,并且参数量减少;
- 反卷积:FCN要学习反卷积输入相应编码器中最大池化层的输出特征图并将相应的编码器特征图添加到解码器输出,由于没有可训练的解码器滤波器,反卷积操作会增加计算成本。
3 训练SegNet
3.1 加载预训练权重
编码器使用VGG16的权重,解码器不用。又由于编码器中不包括VGG16后面3个全连接层,所以需要经过处理,删掉VGG16后面3个全连接层的权重:
# 删掉VGG16后面3个全连接层的权重
def load_weights(self, weights_path):
weights = torch.load(weights_path)
del weights["classifier.0.weight"]
del weights["classifier.0.bias"]
del weights["classifier.3.weight"]
del weights["classifier.3.bias"]
del weights["classifier.6.weight"]
del weights["classifier.6.bias"]
names = []
for key, value in self.encoder.state_dict().items():
if "num_batches_tracked" in key:
continue
names.append(key)
for name, dict in zip(names, weights.items()):
self.weights_new[name] = dict[1]
self.encoder.load_state_dict(self.weights_new)3.2 构建MyDataset类
打开写有训练图片和标签路径的txt文件,然后对训练图片和标签进行预处理,归一化输入:
class MyDataset(Data.Dataset):
def __init__(self, txt_path):
super(MyDataset, self).__init__()
paths = open(txt_path, "r")
image_label = []
for line in paths:
line.rstrip("\n")
line.lstrip("\n")
path = line.split()
image_label.append((path[0], path[1]))
self.image_label = image_label
def __getitem__(self, item):
image, label = self.image_label[item]
image = cv.imread(image)
image = cv.resize(image, (224, 224))
image = image/255.0 # 归一化输入
image = torch.Tensor(image)
image = image.permute(2, 0, 1) # 将图片的维度转换成网络输入的维度(channel, width, height)
label = cv.imread(label, 0)
label = cv.resize(label, (224, 224))
label = torch.Tensor(label)
return image, label
def __len__(self):
return len(self.image_label)3.3 训练
迭代次数、训练集数量、批训练大小、学习率等超参数可自行调节:
from SegNet import *
def train(SegNet):
SegNet = SegNet.cuda()
SegNet.load_weights(PRE_TRAINING)
train_loader = Data.DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)
# 选用adam优化器来训练
optimizer = torch.optim.SGD(SegNet.parameters(), lr=LR, momentum=MOMENTUM)
# 损失函数选用多分类交叉熵损失函数
loss_func = nn.CrossEntropyLoss(weight=torch.from_numpy(np.array(CATE_WEIGHT)).float()).cuda()
SegNet.train()
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader):
b_x = b_x.cuda()
b_y = b_y.cuda()
b_y = b_y.view(BATCH_SIZE, 224, 224)
output = SegNet(b_x)
loss = loss_func(output, b_y.long())
loss = loss.cuda()
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 1 == 0:
print("Epoch:{0} || Step:{1} || Loss:{2}".format(epoch, step, format(loss, ".4f")))
torch.save(SegNet.state_dict(), WEIGHTS + "SegNet_weights" + str(time.time()) + ".pth")
parser = argparse.ArgumentParser()
parser.add_argument("--class_num", type=int, default=2, help="训练的类别的种类")
parser.add_argument("--epoch", type=int, default=100, help="训练迭代次数")
parser.add_argument("--batch_size", type=int, default=10, help="批训练大小")
parser.add_argument("--learning_rate", type=float, default=0.1, help="学习率大小")
parser.add_argument("--momentum", type=float, default=0.9)
parser.add_argument("--category_weight", type=float, default=[0.7502381287857225, 1.4990483912788268], help="损失函数中类别的权重")
parser.add_argument("--train_txt", type=str, default="train.txt", help="训练的图片和标签的路径")
parser.add_argument("--pre_training_weight", type=str, default="vgg16_bn-6c64b313.pth", help="编码器预训练权重路径")
parser.add_argument("--weights", type=str, default="./weights/", help="训练好的权重保存路径")
opt = parser.parse_args()
print(opt)
CLASS_NUM = opt.class_num
EPOCH = opt.epoch
BATCH_SIZE = opt.batch_size
LR = opt.learning_rate
MOMENTUM = opt.momentum
CATE_WEIGHT = opt.category_weight
TXT_PATH = opt.train_txt
PRE_TRAINING = opt.pre_training_weight
WEIGHTS = opt.weights
train_data = MyDataset(txt_path=TXT_PATH)
SegNet = SegNet(3, CLASS_NUM)
train(SegNet)
模型训练结果如下:
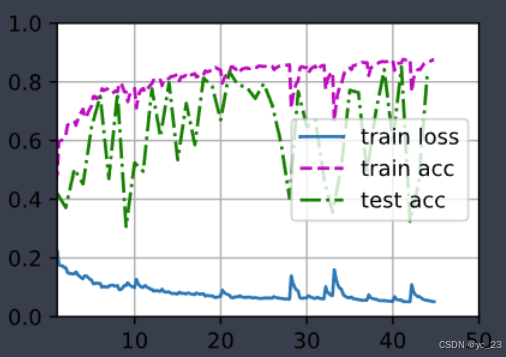
4 测试
所训练的是2个类:道路和其他,原始图片如下:

测试结果如下:

总结
SegNet相较于其他算法,它寻求存储成本、精度准确性及推理时间之间的平衡,减小模型架构、提升计算效率,旨在设计快速、存储空间较小的适用于实时应用的架构。通过在编码阶段的下采样过程中存储最大池化索引,在解码阶段依据索引位置信息进行上采样,从而保留原始图像中更细致准确的边界信息,在精度准确性上大大提升了,并且Segnet结构更小,提供了良好的性能、有竞争力的推理时间和最有效的推理内存。。
虽然SegNet在处理尺寸较小物体上的能力有限,分割效果不佳,并且在评价指标不如其他的一些先进算法,但其提出的编码器-解码器的思想影响着后面的很多模型。