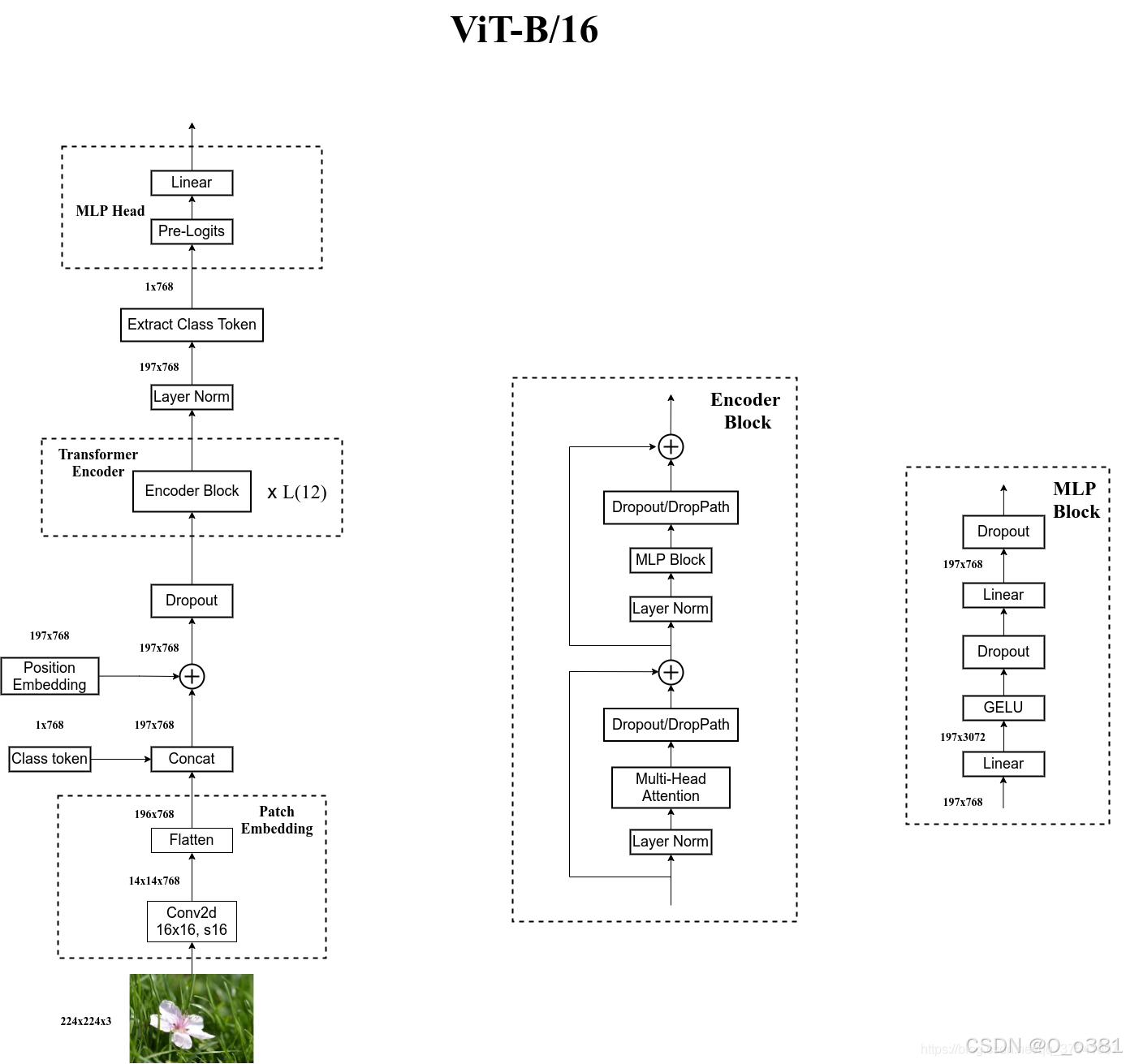
图解:
代码:
class VisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000,
embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True,
qk_scale=None, representation_size=None, distilled=False, drop_ratio=0.,
attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None,
act_layer=None):
"""
Args:
img_size (int, tuple): input image size
#输入图像的大小,通常是 224 或其他标准尺寸
patch_size (int, tuple): patch size
#每个块(patch)的大小,例如 16x16
in_c (int): number of input channels
#输入图像的通道数,RGB 图像是 3
num_classes (int): number of classes for classification head
#最终分类的类别数,默认 1000 类
embed_dim (int): embedding dimension
#嵌入维度,即每个 patch 被映射到的向量的维度,默认是 768
depth (int): depth of transformer
#Transformer 的深度,即堆叠的块(Block)数量。
num_heads (int): number of attention heads
#注意力头的数量,默认设为 12
mlp_ratio (int): ratio of mlp hidden dim to embedding dim
# MLP 隐藏层的维度与嵌入维度的比例。
qkv_bias (bool): enable bias for qkv if True
#是否为 QKV(查询、键、值)矩阵添加偏置
qk_scale (float): override default qk scale of head_dim ** -0.5 if set
#如果设定,将会覆盖默认的 qk 缩放因子
representation_size (Optional[int]): enable and set representation layer (pre-logits) to this value if set
#如果设置了这个值,将会有一个表示层(pre-logits)
distilled (bool): model includes a distillation token and head as in DeiT models
#vit中可以不管这个参数
drop_ratio (float): dropout rate
# Dropout 的比例
attn_drop_ratio (float): attention dropout rate
#注意力层的 Dropout 比例
drop_path_ratio (float): stochastic depth rate
#droppath比例
embed_layer (nn.Module): patch embedding layer
#用于嵌入图像的层,默认使用 PatchEmbed
norm_layer: (nn.Module): normalization layer
#正则化层,通常是 LayerNorm
"""
super(VisionTransformer, self).__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
# 与 embed_dim 保持一致,表示嵌入的维度。
self.num_tokens = 2 if distilled else 1
#不管distilled所以distilled=1
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
#使用 LayerNorm作为默认的规范化层
act_layer = act_layer or nn.GELU
#默认使用 GELU 作为激活函数
self.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_c=in_c, embed_dim=embed_dim)
#Embedding层结构
num_patches = self.patch_embed.num_patches
#patches的个数
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
#这是用于分类的分类标记(Class Token),它是一个可学习的参数,初始值为零
self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else None
#不管distilled所以self.dist_token=None
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))
#位置编码(Position Embedding)
self.pos_drop = nn.Dropout(p=drop_ratio)
#位置编码后的 Dropout 操作
dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)] # stochastic depth decay rule
#用于控制每个 Block 的 DropPath 比例
self.blocks = nn.Sequential(*[
Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],
norm_layer=norm_layer, act_layer=act_layer)
for i in range(depth)
])
#使用 Block 类构建了Transformer的主体部分,包括注意力和MLP层,并使用残差连接和 DropPath
self.norm = norm_layer(embed_dim)
#最后的归一化层,用于 Transformer 输出的处理
# Representation layer
if representation_size and not distilled:
#设置了 representation_size则会增加一个表示层 pre_logits,not distilled=true
self.has_logits = True
self.num_features = representation_size
self.pre_logits = nn.Sequential(OrderedDict([
("fc", nn.Linear(embed_dim, representation_size)),
("act", nn.Tanh())
]))
#pre_logits层结构一个全连接和tanh激活函数
else:
self.has_logits = False
self.pre_logits = nn.Identity()
# Classifier head(s)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.head_dist = None
if distilled:
self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity()
#distilled为none不用管
# Weight init
nn.init.trunc_normal_(self.pos_embed, std=0.02)
if self.dist_token is not None:
nn.init.trunc_normal_(self.dist_token, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02)
self.apply(_init_vit_weights)
#权重初始化
def forward_features(self, x):
# [B, C, H, W] -> [B, num_patches, embed_dim]
x = self.patch_embed(x) # [B, 196, 768]
#将输入的图像 x 切分为多个 patch 并嵌入,通过Embedding层
# [1, 1, 768] -> [B, 1, 768]
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
if self.dist_token is None:
x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]
else:
x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)
#分类标记如果有将cls_token加入,因为dist_token为none,所以在维度1上拼接
x = self.pos_drop(x + self.pos_embed)
#添加位置编码并应用 Dropout
x = self.blocks(x)
#通过 Transformer 的 Block 堆叠进行处理
x = self.norm(x)
#进行归一化
#vit中self.dist_token is None所以模型只有分类标记 (class token)。
if self.dist_token is None:
return self.pre_logits(x[:, 0])
#x[:, 0]表示提取分类标记(class token) 的输出向量。这个向量是用于分类任务的主要特征表示。
else:
return x[:, 0], x[:, 1]
def forward(self, x):
x = self.forward_features(x)
#首先获取 Transformer 的特征输出
if self.head_dist is not None:
x, x_dist = self.head(x[0]), self.head_dist(x[1])
if self.training and not torch.jit.is_scripting():
# during inference, return the average of both classifier predictions
return x, x_dist
else:
return (x + x_dist) / 2
else:
#self.head_dist为none只看head层就是最后的全连接层输出为num_classes
x = self.head(x)
return x操作:
代码:
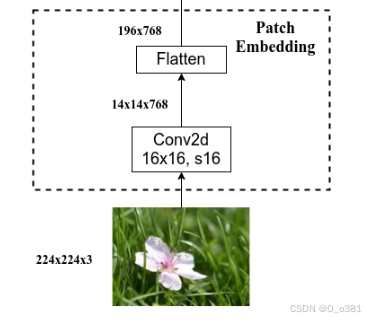
# [B, C, H, W] -> [B, num_patches, embed_dim]
x = self.patch_embed(x) # [B, 196, 768]
#将输入的图像 x 切分为多个 patch 并嵌入,通过Embedding层
操作:

代码:
# [1, 1, 768] -> [B, 1, 768]
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
if self.dist_token is None:
x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]
else:
x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)
#分类标记如果有将cls_token加入,因为dist_token为none,所以在维度1上拼接
操作:

代码:
x = self.pos_drop(x + self.pos_embed)
#添加位置编码并应用 Dropout
操作:
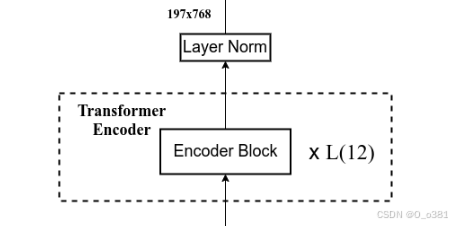
代码:
x = self.blocks(x)
#通过 Transformer 的 Block 堆叠进行处理
x = self.norm(x)
#进行归一化
操作:
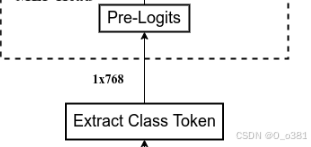
代码:
#vit中self.dist_token is None所以模型只有分类标记 (class token)。
if self.dist_token is None:
return self.pre_logits(x[:, 0])
#x[:, 0]表示提取分类标记(class token) 的输出向量。这个向量是用于分类任务的主要特征表示。
else:
return x[:, 0], x[:, 1]
操作:
代码:
#self.head_dist为none只看head层就是最后的全连接层输出为num_classes
x = self.head(x)
分类标记 (Class Token):
是一种特殊的 输入 token,在 Transformer 模型中被用来聚合全局特征。
它在模型中起到了类似于 CNN 中全局池化 (Global Pooling) 的作用,负责从所有 patch 的信息中提取一个全局表示。
这个 token 的输出向量被用作分类任务的特征输入,之后会被送入分类头 (classifier head) 进行最终的类别预测。
embedding层:
Vision Transformer(vit)的Embedding层结构-CSDN博客
Multi-Head Self-Attention:
Vision Transformer(vit)的Multi-Head Self-Attention(多头注意力机制)结构-CSDN博客
MLP模块:
Vision Transformer(vit)的MLP模块-CSDN博客
Encoder block: