kafka是一个消息中间键
9092端口----- kafka端口
2182端口----- zookeeper端口
kafka命令:
kafka-topics.sh命令:
--bootstrap-server:连接kafka的主机名称以及端口号
--replication-factor 设置副本数
#查看topic列表
bin/kafka-topics.sh --bootstrap-server bigdata01:9092 --list
#创建分区数为1 副本数为3 的 topic topicB
kafka-topics.sh --bootstrap-server bigdata01:9092 --create --partitions 1 --replication-factor 3 --topic topicB
#修改分区数(注意:分区数只能增加,不能减少)
kafka-topics.sh --bootstrap-server bigdata01:9092 --alter --topic topicB --partitions 3
#查看topic主题详情
kafka-topics.sh --bootstrap-server bigdata01:9092 --describe --topic topicB
#删除topic主题
kafka-topics.sh --bootstrap-server bigdata01:9092 --delete --topic topicBtopicB主题详情如下: 如图可见 现在的分区数为3,副本数为3

删除后,使用list查看topic列表,可以看到topicB主题已经删除了

kafka-console-producer.sh
在控制台中使用生产者(没什么大用,主要用于测试)
#生产者连接topicA主题进行操作
kafka-console-producer.sh --bootstrap-server bigdata01:9092 --topic topicA
kafka-console-consumer.sh
#消费者连接topicA进行消息接收
kafka-console-consumer.sh --bootstrap-server bigdata01:9092 --topic topicA
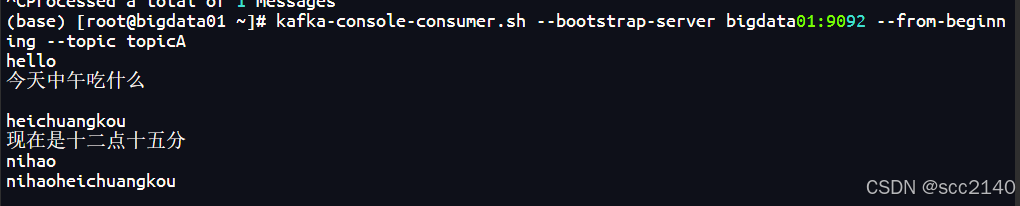
#把主题中所有的数据都读取出来(包括历史数据)并且还可以接收来自生产者的新数据
kafka-console-consumer.sh --bootstrap-server bigdata01:9092 --from-beginning --topic topicA
展示所有数据(包括历史数据)
Kafka在java上书写代码
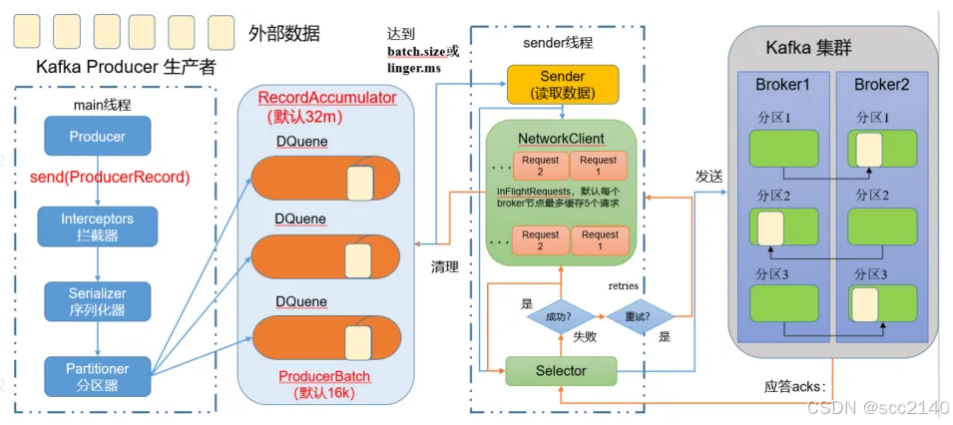
异步发送:
创建 Kafka 生产者,采用异步的方式发送到 Kafka Broke
就是外部数据通过生产者,将数据发送至这个32M的队列中,不用管这个队列中的数据是否发送到了kafka集群
-
导入依赖
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
</dependencies>普通异步
package com.bigdata;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class Demo01 {
public static void main(String[] args) {
Properties properties = new Properties();
// 设置连接kafka集群的ip和端口
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
String str = "今天是2024年11月7日";
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("topicA",str);
kafkaProducer.send(producerRecord);
kafkaProducer.close();
}
}calllback:
就是在send的api中,创建一个匿名内部类callback,里面可以获取关系指定主题信息
package com.bigdata;
import org.apache.kafka.clients.producer.*;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;
public class Demo02_Callback {
public static void main(String[] args) {
Properties properties = new Properties();
// 设置连接kafka集群的ip和端口
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
String str = "今天是2024年11月7日";
System.out.println("发送之前");
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("topicA",str);
kafkaProducer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
// 获取指定主题的分区数量
int partition = recordMetadata.partition();
// 获取指定主题的主题名
String topic = recordMetadata.topic();
// 获取时间
long timestamp = recordMetadata.timestamp();
// 复习,将时间戳转换为日期格式
Date date = new Date(timestamp);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println(sdf.format(date));
// 获取偏移量
long offset = recordMetadata.offset();
System.out.println("分区数量是 "+partition);
System.out.println("主题名是 "+topic);
System.out.println("时间是 "+timestamp);
System.out.println("偏移量是 "+offset);
}
});
}
System.out.println("发送之后");
kafkaProducer.close();
}
}同步:
package com.bigdata;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class Demo03_shishi {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties properties = new Properties();
// 设置连接kafka集群的ip和端口
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
String str = "今天是2024年11月7日";
System.out.println("发送之前");
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("topicA",str);
kafkaProducer.send(producerRecord).get();
}
System.out.println("发送之后");
kafkaProducer.close();
}
}log4j日志:
如果运行的时候没有日志,在resource下创建properties文件,将内容粘贴进去即可看到

# Global logging configuration
# Debug info warn error
log4j.rootLogger=DEBUG, stdout
# MyBatis logging configuration...
log4j.logger.org.mybatis.example.BlogMapper=TRACE
# Console output...
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n指定分区:
package com.bigdata;
import org.apache.kafka.clients.producer.*;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;
public class Demo04_Callback_fenqu {
public static void main(String[] args) {
Properties properties = new Properties();
// 设置连接kafka集群的ip和端口
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
String str = "今天是2024年11月7日";
System.out.println("发送之前");
for (int i = 0; i < 10; i++) {
// key:假如发送消息没有指定分区,指定了Key值,对Key进行hash,然后对分区数取模,得到哪个分区就使用哪个分区 例如key="abc" 就是0分区 abc的hash值对分区数(3)取模
// ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("topicA","abc",str);
// 假如没有写key,也没有指定分区,就随机,粘到那个分区就是那个分区
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("topicA",str);
// 指定了分区数为1 就不看key的值了,使用指定分区
// ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("topicA",1,"a",str);
kafkaProducer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
// 获取指定主题的分区数量
int partition = recordMetadata.partition();
// 获取指定主题的主题名
String topic = recordMetadata.topic();
// 获取时间
long timestamp = recordMetadata.timestamp();
// 复习,将时间戳转换为日期格式
Date date = new Date(timestamp);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println(sdf.format(date));
// 获取偏移量
long offset = recordMetadata.offset();
System.out.println("分区数是 "+partition);
System.out.println("主题名是 "+topic);
System.out.println("时间是 "+timestamp);
System.out.println("偏移量是 "+offset);
}
});
}
System.out.println("发送之后");
kafkaProducer.close();
}
}自定义分区:
需求,如果输入字符中含有bigdata,就存入0分区,没有就存入1分区
首先先创建一个自定义分区类CustomPartitionerMy:
在里面实现Partitioner ,在partition写我们需要的代码需求
package com.bigdata;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
public class CustomPartitionerMy implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 如果输入字符中含有bigdata,就存入0分区,没有就存入1分区
String val1 = value.toString();
String val2 = new String(valueBytes);
// 判断一个字符串是否包含另一个字符串
if (val1.contains("bigdata")){
return 0;
}
return 1;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}之后再在引入我们所自定义的分区类即可,此时即使是写了key,key此时在这里就无效了,但是指定分区依旧有效,还是按照指定分区的分区数进行数据发送
// 引入我们所自定义的分区类
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");package com.bigdata;
import org.apache.kafka.clients.producer.*;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;
public class Demo05_Callback_zidingyifenqu {
public static void main(String[] args) {
Properties properties = new Properties();
// 设置连接kafka集群的ip和端口
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.bigdata.CustomPartitioner");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
String str = "今天是2024年11月7日,bigdata";
System.out.println("发送之前");
for (int i = 0; i < 10; i++) {
// key:假如发送消息没有指定分区,指定了Key值,对Key进行hash,然后对分区数取模,得到哪个分区就使用哪个分区 例如key="abc" 就是0分区 abc的hash值对分区数(3)取模
// ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("topicA","abc",str);
// 假如没有写key,也没有指定分区,就随机,粘到那个分区就是那个分区
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("topicA",str);
// 指定了分区数为1 就不看key的值了,使用指定分区
// ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("topicA",1,"a",str);
kafkaProducer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
// 获取指定主题的分区数量
int partition = recordMetadata.partition();
// 获取指定主题的主题名
String topic = recordMetadata.topic();
// 获取时间
long timestamp = recordMetadata.timestamp();
// 复习,将时间戳转换为日期格式
Date date = new Date(timestamp);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println(sdf.format(date));
// 获取偏移量
long offset = recordMetadata.offset();
System.out.println("分区数是 "+partition);
System.out.println("主题名是 "+topic);
System.out.println("时间是 "+timestamp);
System.out.println("偏移量是 "+offset);
}
});
}
System.out.println("发送之后");
kafkaProducer.close();
}
}注意:假如我自定义了一个分区规则,如果代码中指定了消息发送到某个分区,自定义的分区规则无效。
比如:我自定义了一个分区器,包含 bigdata 发送 0 分区,不包含发送 1 分区,但假如发送消息的时候指定消息发送到 2 分区,那么消息就必然发送 2 分区。不走咱们自定义的分区器规则了。
在kafka的设置分区中
指定分区的优先级最大,其次是自定义的函数类,接着是key,最后才是随机粘一个分区
指定 > 自定义 > key > 默认
kafka使用的是稀疏索引,所以运行速度较快
零拷贝其实就是数据不需要再次经过kafka重新拷贝后发送给消费者,而是直接从生产者发送给kafka的页缓存直接给消费者