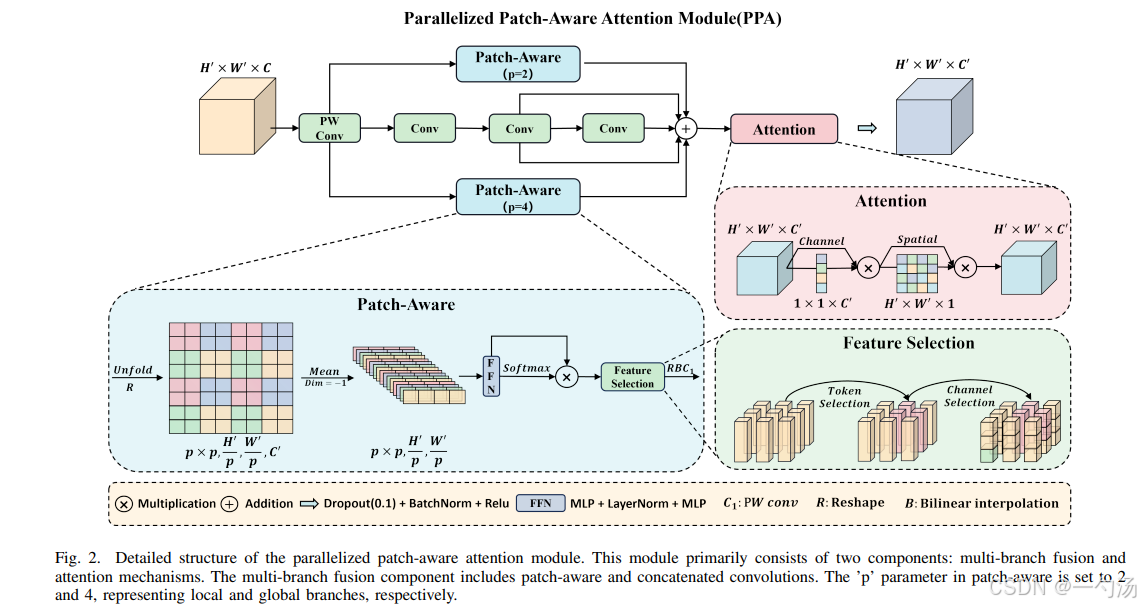
本篇文章将介绍一个新的改进机制——并行化补丁感知注意力模块PPA ,并阐述如何将其应用于YOLOv11中,显著提升模型性能。首先,PPA 是用于解决红外小目标检测下采样信息丢失问题的模块。它由多分支融合和注意力机制构成,通过多分支提取不同尺度特征,再经注意力机制自适应增强特征。随后,我们将详细讨论他的模型结构,以及如何将PPA模块与YOLOv11相结合,以提升目标检测的性能。
1. PPA(Parallelized Patch - Aware Attention Module)结构介绍
PPA(Parallelized Patch - Aware Attention Module)是 HCF - Net 中的一个重要模块,主要用于解决红外小目标检测中多次下采样操作导致小目标关键信息丢失的问题,其结构主要由多分支融合和注意力机制两部分组成,以下是详细介绍:
1.1. 多分支特征提取
1.多分支策略: PPA 采用并行多分支方法,包含局部、全局和串行卷积三个分支。这种设计可以提取不同尺度和层次的特征,有助于捕获目标的多尺度特征,进而提高小目标检测的准确性。
2. 具体操作: 首先对输入特征张量进行逐点卷积调整。然后分别通过三个分支进行计算,最后将三个分支的结果相加。
1.2. 特征融合和注意力
1.注意力机: 在多分支特征提取之后,使用注意力机制进行自适应特征增强。注意力模块包含一系列高效的通道注意力和空间注意力组件。
2. 具体计算:依次经过一维通道注意力图和二维空间注意力图处理,最终得到 PPA 的输出。通过这些处理,能够更好地融合和突出重要特征。
2. YOLOv11与PPA的结合
本文将YOLOv11模型的C3K2模块相结合 ,组合成C3k2_PPA模块。有助于C3K2模块提取特征的时候,保留更多关于小目标的信息,使得在后续的检测和识别阶段,小目标的特征更加完整,减少因信息丢失而导致的漏检或误检情况。
3. PPA代码部分
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from .conv import Conv
from .block import C2f, C3k
class conv_block(nn.Module):
def __init__(self,
in_features,
out_features,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1),
dilation=(1, 1),
norm_type='bn',
activation=True,
use_bias=True,
groups = 1
):
super().__init__()
self.conv = nn.Conv2d(in_channels=in_features,
out_channels=out_features,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
bias=use_bias,
groups = groups)
self.norm_type = norm_type
self.act = activation
if self.norm_type == 'gn':
self.norm = nn.GroupNorm(32 if out_features >= 32 else out_features, out_features)
if self.norm_type == 'bn':
self.norm = nn.BatchNorm2d(out_features)
if self.act:
# self.relu = nn.GELU()
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x = self.conv(x)
if self.norm_type is not None:
x = self.norm(x)
if self.act:
x = self.relu(x)
return x
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.sigmoid(self.conv2d(out))
return out * x
class ECA(nn.Module):
def __init__(self,in_channel,gamma=2,b=1):
super(ECA, self).__init__()
k=int(abs((math.log(in_channel,2)+b)/gamma))
kernel_size=k if k % 2 else k+1
padding=kernel_size//2
self.pool=nn.AdaptiveAvgPool2d(output_size=1)
self.conv=nn.Sequential(
nn.Conv1d(in_channels=1,out_channels=1,kernel_size=kernel_size,padding=padding,bias=False),
nn.Sigmoid()
)
def forward(self,x):
out=self.pool(x)
out=out.view(x.size(0),1,x.size(1))
out=self.conv(out)
out=out.view(x.size(0),x.size(1),1,1)
return out*x
class LocalGlobalAttention(nn.Module):
def __init__(self, output_dim, patch_size):
super().__init__()
self.output_dim = output_dim
self.patch_size = patch_size
self.mlp1 = nn.Linear(patch_size*patch_size, output_dim // 2)
self.norm = nn.LayerNorm(output_dim // 2)
self.mlp2 = nn.Linear(output_dim // 2, output_dim)
self.conv = nn.Conv2d(output_dim, output_dim, kernel_size=1)
self.prompt = torch.nn.parameter.Parameter(torch.randn(output_dim, requires_grad=True))
self.top_down_transform = torch.nn.parameter.Parameter(torch.eye(output_dim), requires_grad=True)
def forward(self, x):
x = x.permute(0, 2, 3, 1)
B, H, W, C = x.shape
P = self.patch_size
# Local branch
local_patches = x.unfold(1, P, P).unfold(2, P, P) # (B, H/P, W/P, P, P, C)
local_patches = local_patches.reshape(B, -1, P*P, C) # (B, H/P*W/P, P*P, C)
local_patches = local_patches.mean(dim=-1) # (B, H/P*W/P, P*P)
local_patches = self.mlp1(local_patches) # (B, H/P*W/P, input_dim // 2)
local_patches = self.norm(local_patches) # (B, H/P*W/P, input_dim // 2)
local_patches = self.mlp2(local_patches) # (B, H/P*W/P, output_dim)
local_attention = F.softmax(local_patches, dim=-1) # (B, H/P*W/P, output_dim)
local_out = local_patches * local_attention # (B, H/P*W/P, output_dim)
cos_sim = F.normalize(local_out, dim=-1) @ F.normalize(self.prompt[None, ..., None], dim=1) # B, N, 1
mask = cos_sim.clamp(0, 1)
local_out = local_out * mask
local_out = local_out @ self.top_down_transform
# Restore shapes
local_out = local_out.reshape(B, H // P, W // P, self.output_dim) # (B, H/P, W/P, output_dim)
local_out = local_out.permute(0, 3, 1, 2)
local_out = F.interpolate(local_out, size=(H, W), mode='bilinear', align_corners=False)
output = self.conv(local_out)
return output
class PPA(nn.Module):
def __init__(self, in_features, filters) -> None:
super().__init__()
self.skip = conv_block(in_features=in_features,
out_features=filters,
kernel_size=(1, 1),
padding=(0, 0),
norm_type='bn',
activation=False)
self.c1 = conv_block(in_features=in_features,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
self.c2 = conv_block(in_features=filters,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
self.c3 = conv_block(in_features=filters,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
self.sa = SpatialAttentionModule()
self.cn = ECA(filters)
self.lga2 = LocalGlobalAttention(filters, 2)
self.lga4 = LocalGlobalAttention(filters, 4)
self.bn1 = nn.BatchNorm2d(filters)
self.drop = nn.Dropout2d(0.1)
self.relu = nn.ReLU()
self.gelu = nn.GELU()
def forward(self, x):
x_skip = self.skip(x)
x_lga2 = self.lga2(x_skip)
x_lga4 = self.lga4(x_skip)
x1 = self.c1(x)
x2 = self.c2(x1)
x3 = self.c3(x2)
x = x1 + x2 + x3 + x_skip + x_lga2 + x_lga4
x = self.cn(x)
x = self.sa(x)
x = self.drop(x)
x = self.bn1(x)
x = self.relu(x)
return x
class Bottleneck_PPA(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a standard bottleneck module with optional shortcut connection and configurable parameters."""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = PPA(c_, c2)
self.add = shortcut and c1 == c2
def forward(self, x):
"""Applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
# 在c3k=True时,使用普通的Bottleneck,为false的时候我们使用Bottleneck_RepVGG提取特征
class C3k2_PPA(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
"""Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks."""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck_PPA(self.c, self.c, shortcut, g) for _ in range(n)
)
if __name__ =='__main__':
ASSA_Attention = PPA(256,128)
#创建一个输入张量
batch_size = 1
input_tensor=torch.randn(batch_size, 256, 64, 64 )
#运行模型并打印输入和输出的形状
output_tensor =ASSA_Attention(input_tensor)
print("Input shape:",input_tensor.shape)
print("0utput shape:",output_tensor.shape)4. 将PPA引入到YOLOv11中
第一: 将下面的核心代码复制到D:\bilibili\model\YOLO11\ultralytics-main\ultralytics\nn路径下,如下图所示。
第二:在task.py中导入PPA包
第三:在task.py中的模型配置部分下面代码
第四:将模型配置文件复制到YOLOV11.YAMY文件中
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2_PPA, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2_PPA, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2_PPA, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2_PPA, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2_PPA, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2_PPA, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2_PPA, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2_PPA, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
第五:运行成功
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
if __name__=="__main__":
# 使用自己的YOLOv11.yamy文件搭建模型并加载预训练权重训练模型
model = YOLO(r"D:\bilibili\model\YOLO11\ultralytics-main\ultralytics\cfg\models\11\yolo11_PPA.yaml")\
.load(r'D:\bilibili\model\YOLO11\ultralytics-main\yolo11n.pt') # build from YAML and transfer weights
results = model.train(data=r'D:\bilibili\model\ultralytics-main\ultralytics\cfg\datasets\VOC_my.yaml',
epochs=100, imgsz=640, batch=8)
