文章目录
🐒个人主页:信计2102罗铠威
🏅JavaEE系列专栏
📖前言:
PDF转文本的插件常用的有:pdfbox ,itextpdf 和 spire.pdf 这几个,
spire.pdf这个转图片不推荐使用(图片不完整要收费),推荐使用我发布itextpdf 这篇文章的转图片方式
🎀 1. pdfbox
1.1导入pdfbox 的maven依赖
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.7.3</version>
</dependency>
因为这个是私服仓库,可能有的小伙伴下不下来依赖:在maven的配置文件中配置这个仓库即可:
看不懂的点这里~
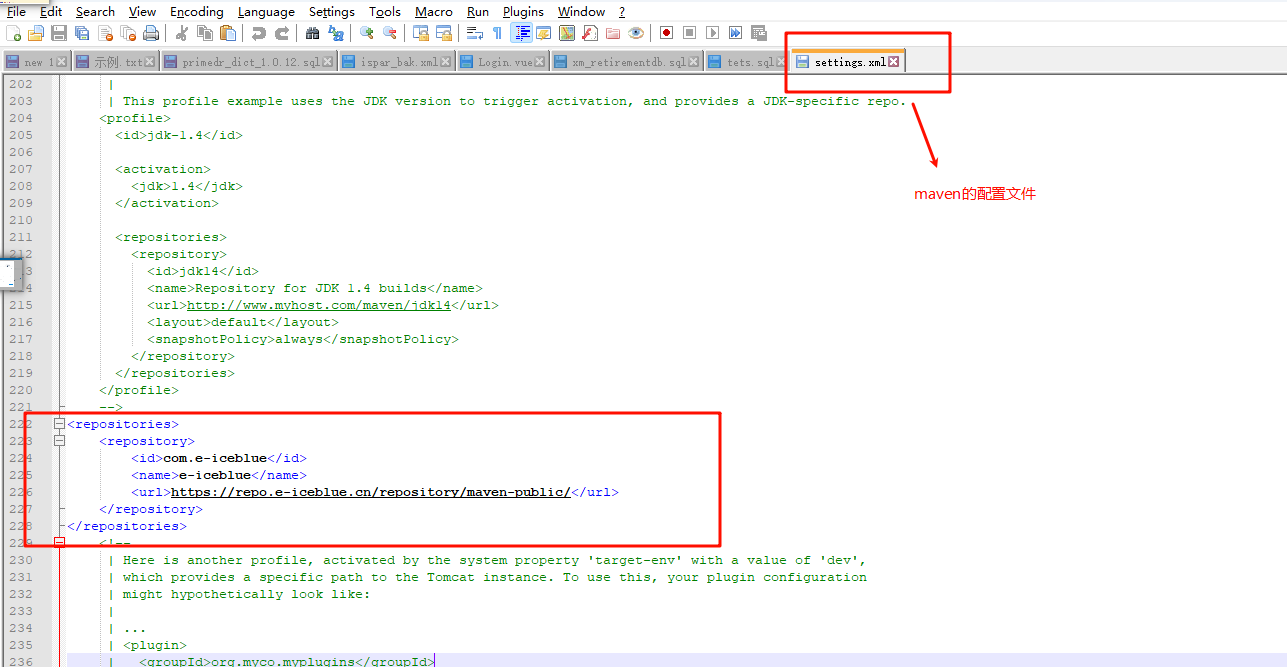
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
1.1 提取文本
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class ExtractTextFromPage
{
public static void main(String[] args) throws IOException
{
// 创建 PdfDocument 对象
PdfDocument doc = new PdfDocument();
// 加载 PDF 文件
doc.loadFromFile("input.pdf");
// 获取第一页,遍历文档所有页便可提取文档所有文本内容
PdfPageBase page = doc.getPages().get(0);
// 创建PdfTextExtractor 对象
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
// 创建PdfTextExtractOptions 对象
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
// 从页面中提取文本
String text = textExtractor.extract(extractOptions);
// 写入到 txt 文件中
Files.write(Paths.get("Extracted.txt"), text.getBytes());
// 释放PdfDocument对象
doc.dispose();
}
}
1.2 提取文本表格(可自行加入逻辑处理)
import com.spire.pdf.*;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractTable {
public static void main(String[] args)throws IOException {
//实例化PdfDocument类的对象
PdfDocument pdf = new PdfDocument();
//加载PDF文档
pdf.loadFromFile("test.pdf");
//创建StringBuilder类的实例
StringBuilder builder = new StringBuilder();
//创建PdfTableExtractor类的对象
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
//遍历每一页
for (int page = 0; page < pdf.getPages().getCount(); page++)
{
//提取页面中的表格存入PdfTable[]数组
PdfTable[] tableLists = extractor.extractTable(page);
if (tableLists != null && tableLists.length > 0)
{
//遍历表格
for (PdfTable table : tableLists)
{
int row = table.getRowCount();//获取表格行
int column = table.getColumnCount();//获取表格列
for (int i = 0; i < row; i++)
{
for (int j = 0; j < column; j++)
{
//todo 获取表格中的文本内容 表格坐标(i,j)
String text = table.getText(i, j);
//将获取的text写入StringBuilder容器
builder.append(text+" ");
}
builder.append("\r\n");
}
}
}
}
//保存为txt文档
FileWriter fileWriter = new FileWriter("ExtractedTable.txt");
fileWriter.write(builder.toString());
fileWriter.flush();
fileWriter.close();
}
}
1.3 pdf转换成图片代码(不推荐)
可以看我发布itextpdf 这篇文章的转图片方式,它这个功能不完整
import com.spire.pdf.*;
import com.spire.pdf.graphics.PdfImageType;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class PDFtoImage {
public static void main(String[] args)throws IOException {
//实例化PdfDocument类的对象
PdfDocument pdf = new PdfDocument();
//加载PDF文档
pdf.loadFromFile("sample.pdf");
//遍历PDF每一页,保存为图片
for (int i = 0; i < pdf.getPages().getCount(); i++) {
//将页面保存为图片,并设置DPI分辨率
BufferedImage image = pdf.saveAsImage(i, PdfImageType.Bitmap,500,500);
//将图片保存为png格式
File file = new File( String.format(("ToImage-img-%d.png"), i));
ImageIO.write(image, "PNG", file);
}
pdf.close();
}
}