1.简介
近期,在人工智能领域,尤其是大型语言模型领域,可谓是热闹非凡。首先,OpenAI公司宣布开放了其最新的大型语言模型o1,紧接着,微软也不甘示弱,宣布开源了其先进的Phi-4模型,这一行动同样在技术社区中掀起了热烈讨论。两大科技巨头的相继动作,仿佛是一场接力赛,一个刚刚结束,另一个便紧随其后,登上了舞台,展现了大型语言模型发展的新趋势和竞争态势。
而国内厂商也不闲着,“深度求索”官方公众号12 月 26 日发布博文,宣布上线并同步开源 DeepSeek-V3 模型,用户可以登录官网 chat.deepseek.com,与最新版 V3 模型对话。
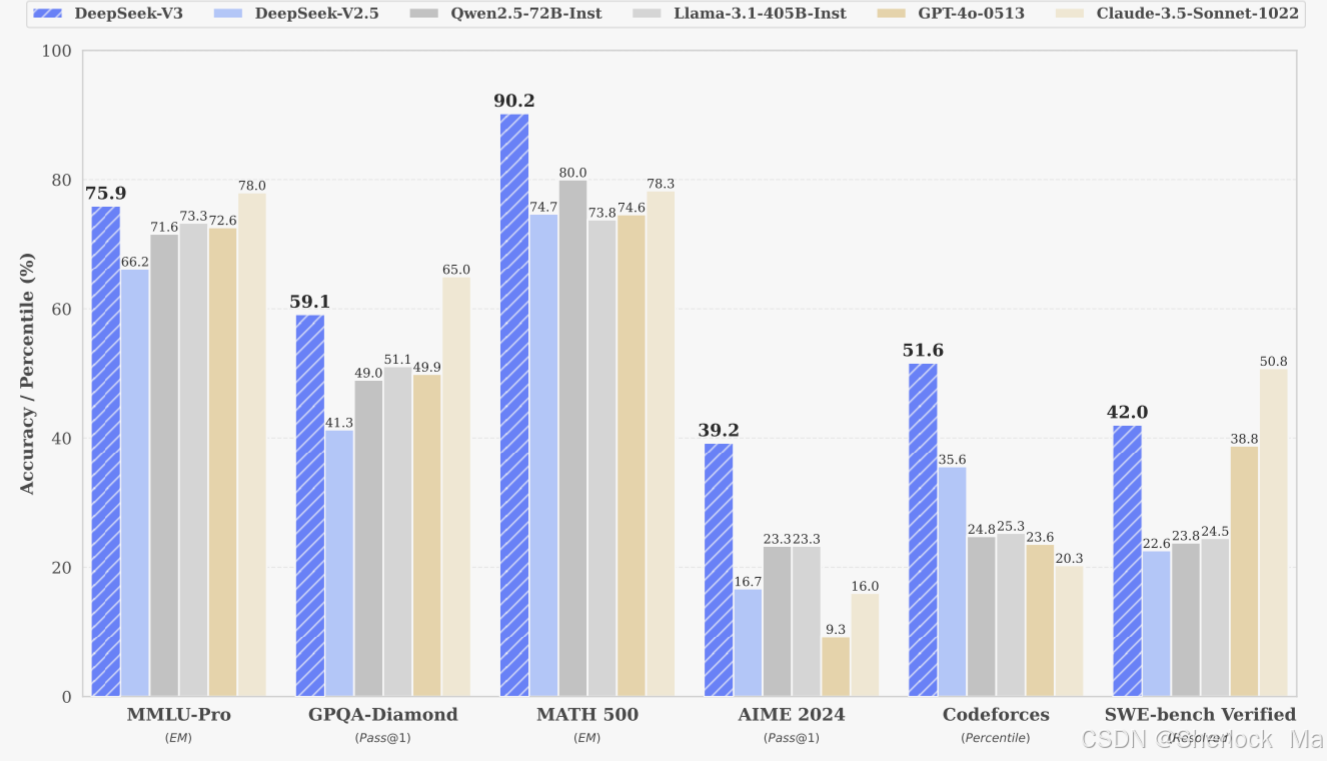
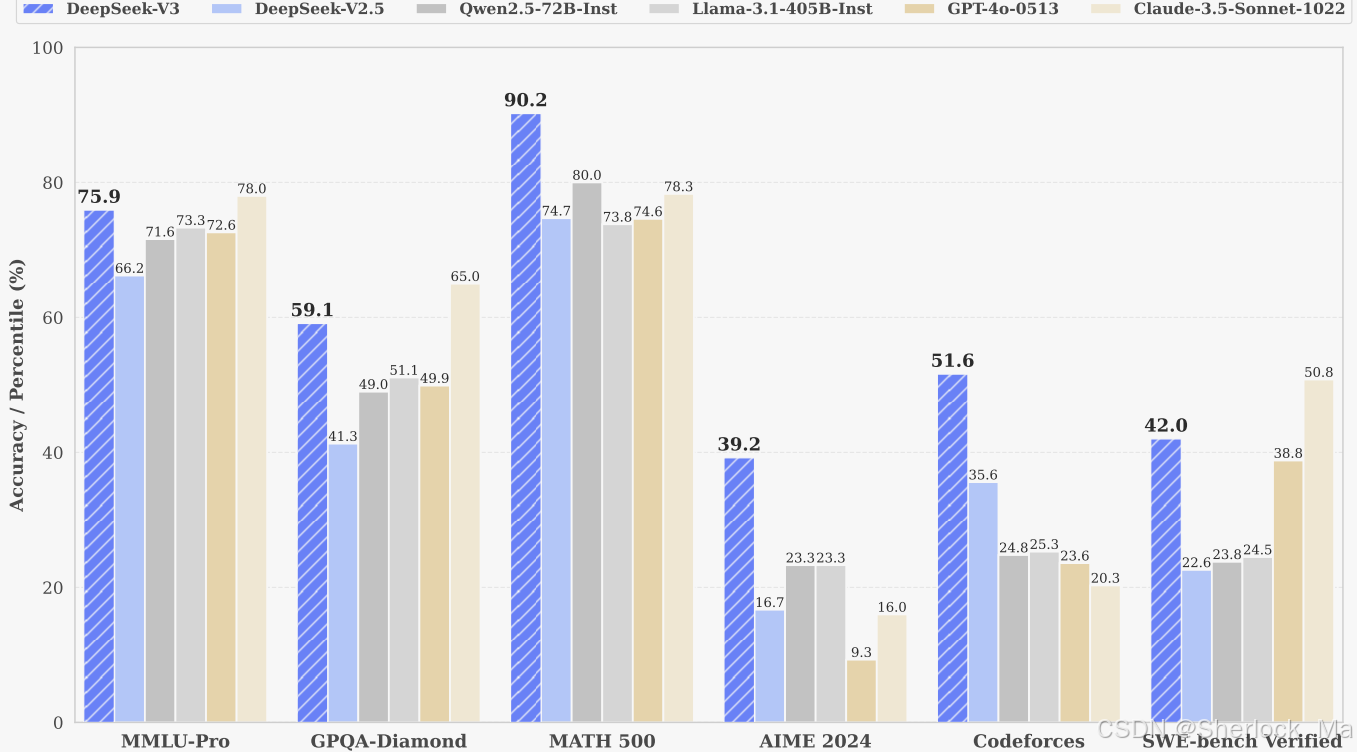
DeepSeek-V3在知识类任务(MMLU, MMLU-Pro, GPQA, SimpleQA)上的水平显著提升,接近当前表现最好的模型Anthropic公司于10月发布的Claude-3.5-Sonnet-1022。在美国数学竞赛(AIME 2024, MATH)和全国高中数学联赛(CNMO 2024)上,DeepSeek-V3大幅超过了其他所有开源闭源模型。另外,在生成速度上,DeepSeek-V3的生成吐字速度从20TPS(Transactions Per Second每秒完成的事务数量)大幅提高至60TPS,相比V2.5模型实现了3倍的提升,能够带来更加流畅的使用体验。据官方技术论文披露,DeepSeek-V3模型的总训练成本为557.6万美元,而GPT-4o等模型的训练成本约为1亿美元,仅为其成本的1/20。
DeepSeek-V3模型API服务定价为每百万输入tokens为0.5元(缓存命中)/2元(缓存未命中),每百万输出tokens价格为8元,并享有45天的优惠价格体验期。

-
目录
-
官方网站:DeepSeek
代码地址:GitHub - deepseek-ai/DeepSeek-V3
权重地址:https://huggingface.co/deepseek-ai
论文地址:DeepSeek-V3/DeepSeek_V3.pdf at main · deepseek-ai/DeepSeek-V3 · GitHub
-
-
2.实测
测一下数草莓中的“r”以及“9.9和9.11哪个大”这种早期的行业难题。可以看到它都答对了


对于图片也能做的清晰的理解,图中是论文图5

-
但是奇怪的是,有时候它仍然会冒出英语,即便我的输入是中文。

遗憾的是,对于超长文本的理解能力,不如Kimi
-
-
3.论文解读
3.1 简介
近年来,大型语言模型(LLM)一直在经历快速的迭代和演变,逐渐缩小了与人工通用智能(AGI)的差距。为了进一步推动开源模型功能的边界,我们扩展了我们的模型并引入了DeepSeek-V3,这是一个大型的专家混合(MOE)模型,具有671 B参数,其中37 B为每个令牌激活。
本文的主要贡献如下:
架构:
- 在DeepSeek-V2的高效架构基础上,首创了无辅助损失(auxiliary-loss-free strategy)的负载均衡策略(load balancing),最大限度地降低了由于寻求负载均衡而导致的性能下降。
- 作者研究了一个多标记预测(Multi-Token Prediction,MTP)目标,并证明了它对模型性能的好处。它也可以用于推理加速。
预训练:迈向终极训练效率
- 作者设计了FP 8混合精度训练框架,并首次在超大规模模型上验证了FP 8训练的可行性和有效性。
- 通过算法、框架和硬件的协同设计,克服了跨节点MOE训练(cross-node MoE training)中的通信瓶颈,实现了近乎完全的计算-通信重叠(near-full computation-
communication overlap)。这大大提高了我们的训练效率并降低了训练成本,使我们能够在不增加额外开销的情况下进一步扩大模型规模。- 注:Computation-communication overlap(计算-通信重叠)是指在并行计算或分布式系统中,计算任务和通信任务在同一时间内同时进行,以提高资源利用率和整体性能的一种技术。在深度学习模型训练中,不同的计算节点(如GPU)需要交换信息,这通常涉及到通信操作。如果通信操作和计算操作能够重叠进行,即在一个节点进行计算的同时,另一个节点可以进行数据传输,那么就可以更有效地利用硬件资源,减少等待时间,从而加速训练过程。
- 作者以仅266.4万H800 GPU小时的经济成本,在14.8T tokens上完成了DeepSeek-V3的预训练,产生了目前最强的开源基础模型。预训练后的后续训练阶段仅需要0.1M GPU小时。
后训练:从R1进行知识蒸馏
- 作者引入了一种创新的方法,从长思想链(CoT)模型中提取推理能力,特别是从DeepSeek R1系列模型中提取推理能力,并将其转化为标准的LLM,特别是DeepSeek-V3。作者将R1的验证和反射模式优雅地整合到DeepSeek-V3中,并显著提高了其推理性能。同时,作者还可以控制DeepSeek-V3的输出样式和长度。

核心评价结果汇总:
- 知识:
- (1)在MMLU、MMLU-Pro和GPQA等教育基准测试中,DeepSeek-V3的表现优于所有其他开源模型,在MMLU上达到88.5,在MMLU-Pro上达到75.9,在GPQA上达到59.1。它的性能与GPT-4 o和Claude-Sonnet-3.5等领先的闭源模型相当,缩小了该领域开源和闭源模型之间的差距。
- (2)对于真实性基准测试,DeepSeek-V3在SimpleQA和中文SimpleQA的开源模型中表现出上级性能。虽然它在英语事实知识(SimpleQA)方面落后于GPT-4 o和Claude-Sonnet-3.5,但它在汉语事实知识(Chinese SimpleQA)方面超过了这些模型,突出了它在汉语事实知识方面的优势。
- 代码、数学和推理:
- (1)DeepSeek-V3在所有非长CoT开源和闭源模型中的数学相关基准测试中达到了最先进的性能。值得注意的是,它甚至在特定的基准测试(如MATH-500)上优于o1-preview,证明了其强大的数学推理能力。
- (2)在编码相关任务方面,DeepSeek-V3成为LiveCodeBench等编码竞赛基准测试的最佳模型,巩固了其在该领域的领先地位。对于工程相关的任务,虽然DeepSeek-V3的性能略低于Claude-Sonnet-3.5,但它仍然远远超过所有其他型号,在各种技术基准中表现出竞争力。
-
3.2 架构
DeepSeek-V3的基本架构仍然是Transformer框架。为了高效的推理和经济的训练,DeepSeek-V3还采用了MLA和DeepSeekMoE,这些都已经被DeepSeek-V2彻底验证过。与DeepSeek-V2相比,作者额外引入了一个无辅助损失的负载均衡策略(auxiliary-loss-free load balancing),以减轻由确保负载平衡的努力引起的性能下降。
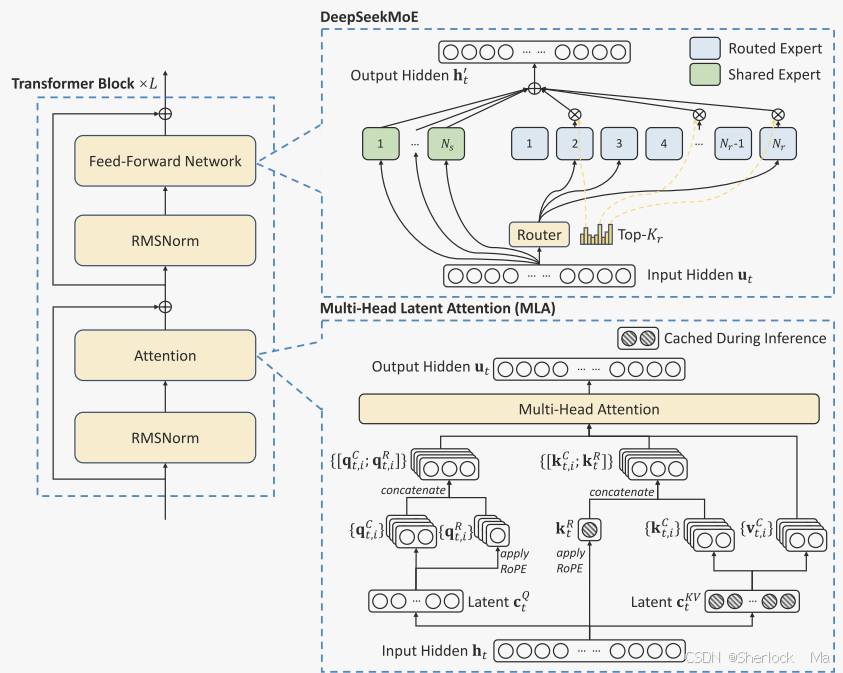
Multi-Head Latent Attention(多头潜在注意力)
对于注意力,DeepSeek-V3采用了MLA架构。令d表示嵌入维数,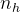
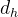
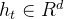
![\begin{matrix}\mathbf{c_t^{KV}}=W^{DKV}h_t,\: \: \: \: \: (1)\\ [k_{t,1}^C;k_{t,2}^C;...k_{t,n_h}^C]=k_t^C=W^{UK}c_t^{KV},\: \: \: \: \: (2)\\ \mathbf{k^R_t}=RoPE(W^{KR}h_t),\: \: \: \: \: (3)\\ k_{t,i}=[k^C_{t,i};k_t^R],\: \: \: \: \: (4)\\ [v_{t,1}^C;v_{t,2}^C;...v_{t,n_h}^C]=v_t^C=W^{UV}c_t^{KV},\: \: \: \: \: (5)\end{matrix}](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUNiZWdpbiU3Qm1hdHJpeCU3RCU1Q21hdGhiZiU3QmNfdCU1RSU3QktWJTdEJTdEJTNEVyU1RSU3QkRLViU3RGhfdCUyQyU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCUyODElMjklNUMlNUMlMjAlNUJrXyU3QnQlMkMxJTdEJTVFQyUzQmtfJTdCdCUyQzIlN0QlNUVDJTNCLi4ua18lN0J0JTJDbl9oJTdEJTVFQyU1RCUzRGtfdCU1RUMlM0RXJTVFJTdCVUslN0RjX3QlNUUlN0JLViU3RCUyQyU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCUyODIlMjklNUMlNUMlMjAlNUNtYXRoYmYlN0JrJTVFUl90JTdEJTNEUm9QRSUyOFclNUUlN0JLUiU3RGhfdCUyOSUyQyU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCUyODMlMjklNUMlNUMlMjBrXyU3QnQlMkNpJTdEJTNEJTVCayU1RUNfJTdCdCUyQ2klN0QlM0JrX3QlNUVSJTVEJTJDJTVDJTNBJTIwJTVDJTNBJTIwJTVDJTNBJTIwJTVDJTNBJTIwJTVDJTNBJTIwJTI4NCUyOSU1QyU1QyUyMCU1QnZfJTdCdCUyQzElN0QlNUVDJTNCdl8lN0J0JTJDMiU3RCU1RUMlM0IuLi52XyU3QnQlMkNuX2glN0QlNUVDJTVEJTNEdl90JTVFQyUzRFclNUUlN0JVViU3RGNfdCU1RSU3QktWJTdEJTJDJTVDJTNBJTIwJTVDJTNBJTIwJTVDJTNBJTIwJTVDJTNBJTIwJTVDJTNBJTIwJTI4NSUyOSU1Q2VuZCU3Qm1hdHJpeCU3RA%3D%3D)
其中,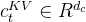
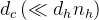
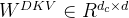
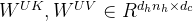
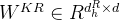
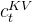
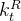
对于注意query,作者还执行了低秩压缩,这可以减少训练期间的激活记忆:
![\begin{matrix} c_t^{Q}=W^{DQ}h_t,\: \: \: \: \: (6)\\ [q_{t,1}^C;q_{t,2}^C;...q_{t,n_h}^C]=q_t^C=W^{UQ}c_t^{Q},\: \: \: \: \: (7)\\ [q_{t,1}^R;q_{t,2}^R;...q_{t,n_h}^R]=q_t^R=RoPE(W^{QR}c_t^Q),\: \: \: \: \: (8)\\ q_{t,i}=[q^C_{t,i};q_{t,i}^R],\: \: \: \: \: (9)\end{matrix}](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUNiZWdpbiU3Qm1hdHJpeCU3RCUyMGNfdCU1RSU3QlElN0QlM0RXJTVFJTdCRFElN0RoX3QlMkMlNUMlM0ElMjAlNUMlM0ElMjAlNUMlM0ElMjAlNUMlM0ElMjAlNUMlM0ElMjAlMjg2JTI5JTVDJTVDJTIwJTVCcV8lN0J0JTJDMSU3RCU1RUMlM0JxXyU3QnQlMkMyJTdEJTVFQyUzQi4uLnFfJTdCdCUyQ25faCU3RCU1RUMlNUQlM0RxX3QlNUVDJTNEVyU1RSU3QlVRJTdEY190JTVFJTdCUSU3RCUyQyU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCUyODclMjklNUMlNUMlMjAlNUJxXyU3QnQlMkMxJTdEJTVFUiUzQnFfJTdCdCUyQzIlN0QlNUVSJTNCLi4ucV8lN0J0JTJDbl9oJTdEJTVFUiU1RCUzRHFfdCU1RVIlM0RSb1BFJTI4VyU1RSU3QlFSJTdEY190JTVFUSUyOSUyQyU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCUyODglMjklNUMlNUMlMjBxXyU3QnQlMkNpJTdEJTNEJTVCcSU1RUNfJTdCdCUyQ2klN0QlM0JxXyU3QnQlMkNpJTdEJTVFUiU1RCUyQyU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCU1QyUzQSUyMCUyODklMjklNUNlbmQlN0JtYXRyaXglN0Q%3D)
其中,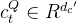
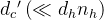
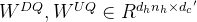
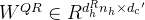
最后,注意力查询(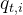
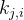
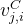
其中,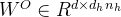
简单来说:使用一个下采样矩阵生成较小尺寸的KV缓存,在生成的时候再使用一个上采样矩阵将保存的KV缓存上采样到原尺寸。这样做就可以大幅减少KV缓存,同时保持较好的性能。

-
DeepSeekMoE with Auxiliary-Loss-Free Load Balancing
基本架构:与传统的MOE架构如GShard,DeepSeekMoE使用更细粒度的专家,并将一些专家分离为共享专家。设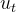
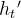
其中,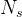
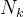
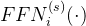
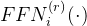
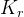
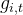
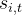
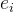
辅助无损失负载平衡(Auxiliary-Loss-Free Load Balancing):对于MOE模型,不平衡的专家负载将导致路由崩溃(routing collapse),并且在具有专家并行性的场景中降低了计算效率。传统的解决方案通常依赖于辅助损失以避免不平衡负载。然而,过大的辅助损失将损害模型性能。为了在负载平衡和模型性能之间实现更好的平衡,我们开创了一种无辅助损失的负载平衡策略以确保负载平衡。具体来说,作者为每个专家引入一个偏差项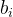

请注意,偏置项仅用于路由。将与FFN输出相乘的门控值仍然是从原始亲和性分数
简而言之,Auxiliary-Loss-Free Load Balancing是一种通过动态调整专家偏置值来实现负载均衡的策略,无需引入额外的损失函数,从而减轻负载并保持模型性能。
辅助损失(Auxiliary Loss) 是一种用于实现负载均衡的常见技术。它的主要目的是确保每个专家(expert)处理的 token 数量相对均衡,从而避免某些专家过载而其他专家闲置的情况。辅助损失的目标是让每个专家的负载尽可能接近平均值。常用的方法是计算专家负载的方差或标准差,并将其作为损失函数的一部分。
互补序列辅助损失(Complementary Sequence-Wise Auxiliary Loss.):虽然DeepSeek-V3主要依赖于auxiliary-loss-free strategy来进行负载平衡,但为了防止任何单个序列中的极端不平衡,我们还采用了互补的序列平衡丢失:
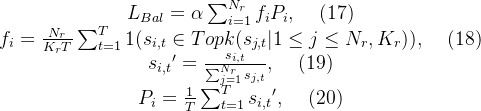
其中,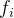
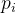
节点限制路由(Node-Limited Routing):与DeepSeek-V2使用的设备受限路由一样,DeepSeek-V3也使用受限路由机制来限制训练期间的通信开销。简而言之,确保每个令牌将被发送到最多M个节点,这些节点是根据分布在每个节点上的专家的最高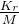
在分布式训练环境中。它的核心思想是通过限制每个 token 被路由到的节点数量,来减少跨节点的通信量,从而提高训练效率。
无令牌丢弃(No Token-Dropping)。由于采用了有效的负载均衡策略,DeepSeek-V3在整个训练过程中保持了良好的负载均衡。因此,DeepSeek-V3在训练期间不会丢弃任何令牌。此外,我们还实现了特定的部署策略以确保推理负载均衡,因此DeepSeek-V3在推理过程中也不会丢弃令牌。
-
Multi-Token Prediction(多令牌预测)
作者研究并为DeepSeek-V3设置了多令牌预测(MTP)目标,该目标将预测范围扩展到每个位置的多个未来令牌。一方面,MTP目标使训练信号密集并且可以提高数据效率。另一方面,MTP可以使模型能够预先规划其表示,以便更好地预测未来的令牌。我们顺序预测额外的token,并在每个预测深度保持完整的因果链。
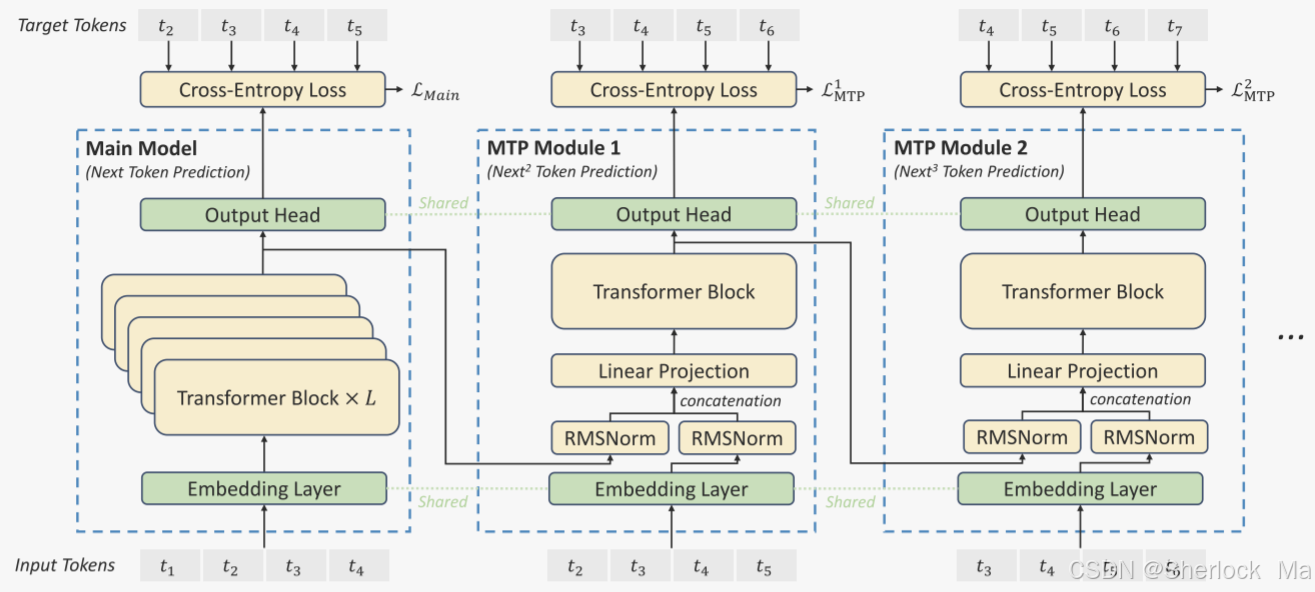
MTP模块:具体地说,MTP使用D个顺序模块来预测额外的令牌。第k个MTP模块由一个共享嵌入层Emb(·)、一个共享输出头OutHead(·)、一个Transformer块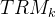
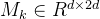
对于第i个输入标记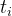
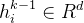
的embedding结合起来:
![h{}'^k_i=M_k[RMSNorm(h_i^{k-1});RMSNorm(Emb(t_{i+k}))]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9oJTdCJTdEJTI3JTVFa19p%3DM_k%5BRMSNorm%28h_i%5E%7Bk-1%7D%29%3BRMSNorm%28Emb%28t_%7Bi+k%7D%29%29%5D)
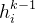
组合的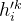
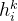
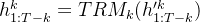
,其中V是词汇大小:
。输出头OutHead(·)将表示线性映射到logit,随后应用Softmax(·)函数来计算第k个附加令牌的预测概率。
此外,对于每个MTP模块,其输出头与主模型共享。这里维持预测因果链的原理与EAGLE相似,但其主要目的是推测解码,而作者利用MTP来改善训练策略。
MTP 使用多个顺序模块,每个模块预测一个额外的 token,用于帮助模型能够更好地规划其表示以预测未来的 token。
MTP训练目标:对于每个预测深度,我们计算交叉熵损失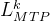
![L^k_{MTP}=CrossEntropy(P^k_{2+k:T+1},t_{2+k:T+1})=-\frac{1}{T}\sum_{i=2+k}^{T+1}logP_i^k[t_i]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9MJTVFa18lN0JNVFAlN0Q%3D%3DCrossEntropy%28P%5Ek_%7B2+k%3AT+1%7D%2Ct_%7B2+k%3AT+1%7D%29%3D-%5Cfrac%7B1%7D%7BT%7D%5Csum_%7Bi%3D2+k%7D%5E%7BT+1%7DlogP_i%5Ek%5Bt_i%5D)
其中,λ表示输入序列长度,![P^k_i[t_i]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9QJTVFa19pJTVCdF9pJTVE)

MTP推理:MTP策略主要是为了提高主模型的性能,所以在推理过程中,我们可以直接丢弃MTP模块,主模型可以独立正常地工作。此外,我们还可以将这些MTP模块重新用于推测性解码,以进一步改善生成延迟。
-
3.3 基本设施
计算集群
DeepSeek-V3在配备2048个NVIDIA H800 GPU的集群上进行训练。H800集群中的每个节点包含8个GPU,通过节点内的NVLink和NVSwitch连接。在不同的节点之间,利用InfiniBand(IB)互连来促进通信。
训练框架
DeepSeek-V3的培训由HAI-LLM框架提供支持,这是一个由作者团队的工程师从头开始精心设计的高效轻量级培训框架。总的来说,DeepSeek-V3应用了16路流水线并行(PP)、64路专家并行(EP)扫描8个节点,以及ZeRO-1数据并行性(DP)。
为了促进DeepSeek-V3的高效训练,作者实施了细致的工程优化。
- 首先,作者设计了DualPipe算法,以实现高效的流水线并行。与现有的PP方法相比,DualPipe具有更少的管道气泡(pipeline bubbles)。更重要的是,它在前向和后向过程中重叠了计算和通信阶段,从而解决了跨节点专家并行性带来的沉重通信开销的挑战。
- 其次,作者开发了高效的跨节点全对全通信内核,以充分利用IB和NVLink带宽,并节省专用于通信的流多处理器。
- 最后,作者在训练过程中精心优化了内存占用,从而使作者能够训练DeepSeek-V3,而无需使用代价高昂的张量并行性(TP)。
在深度学习和特别是大规模模型训练中,"pipeline bubbles"(管道泡沫)是指在流水线并行(pipeline parallelism)训练过程中,由于不同流水线阶段的计算和通信速度不匹配,导致某些阶段出现空闲等待的情况。这些空闲期会降低训练效率,因为它们代表未被充分利用的计算资源。
DualPipe and Computation-Communication Overlap
对于DeepSeek-V3,由跨节点专家并行性引入的通信开销导致计算与通信的低效率比约为1:1。为了应对这一挑战,作者设计了一种创新的流水线并行算法DualPipe,它不仅通过有效地重叠前向和后向计算通信阶段(computation-communication phases)来加速模型训练,而且还减少了流水线气泡(pipeline bubbles)。
DualPipe的关键思想是在一对单独的前向和后向块中重叠计算和通信。具体来说,我们将每个组块划分为四个部分:注意力、全对全调度、MLP和全对全合并。特别地,对于后向组块,注意力和MLP都被进一步分成两部分,后向用于输入和后向用于权重,类似于ZeroBubble。此外,我们还有一个PP通信组件。
如下图所示,对于一对前向和后向块,作者重新排列这些组件,并手动调整专用于通信和计算的GPU SM的比例。在这种重叠策略中,我们可以确保在执行过程中完全隐藏所有对所有和PP通信。

给定有效的重叠策略,完整的DualPipe调度下图所示。它采用了双向流水线调度,从流水线的两端同时馈送微批次,并且通信的大部分可以完全重叠。这种重叠还可以确保随着模型的进一步扩展,只要我们保持恒定的计算与通信比率,我们仍然可以跨节点雇用细粒度的专家,同时实现几乎为零的所有对所有通信开销。

它的核心思想是将前向传播和后向传播的计算与通信任务进行精细调度,从而减少管道中的空闲时间(气泡)并隐藏通信开销。DualPipe 通过双向管道调度和计算-通信重叠,确保在跨节点专家并行训练中,通信不会成为瓶颈,同时显著减少训练时间。
跨节点All-to-All通信的有效实现
在大规模分布式训练中,节点间的通信是一个瓶颈,尤其是在采用专家并行(Expert Parallelism)时,模型的不同部分分布在不同的节点上,需要频繁地交换信息。为了解决这个问题,DeepSeek-V3 实现了一种高效的跨节点全对全通信机制,该机制通过以下几个方面来提高通信效率:
-
定制化的通信核:开发了专门的通信核来处理跨节点的数据分发(dispatching)和聚合(combining),这些通信核与模型的MoE门控算法和集群的网络拓扑结构协同设计,以最大限度地利用InfiniBand和NVLink的带宽。
-
限制每个token的节点数:为了减少InfiniBand的通信流量,每个token被限制最多只能发送到4个节点,这样可以通过NVLink快速转发到目标节点上的特定GPU,而不会因后续到达的token而阻塞。
-
动态调整通信任务:根据实际的工作负载动态调整分配给不同通信任务的流处理器(warp)数量,确保IB发送、IB-to-NVLink转发和NVLink接收等任务能够高效执行。
-
减少内存访问冲突:通过定制化的PTX指令和自动调整通信块大小,减少了对L2缓存的使用,降低了对其他流处理器计算内核的干扰。
-
利用不同的带宽:由于NVLink的带宽是InfiniBand的3.2倍,策略中尽量利用NVLink的高带宽,以减少通信开销。
-
保持SMs的高利用率:通过上述通信策略,只需要较少的流处理器(SMs)就能充分利用IB和NVLink的带宽,保持了SMs的高利用率。
以最小的开销极大地节省内存
DeepSeek-V3通过一系列精心设计的内存优化技术实现了极高的内存节省和最小的开销。这些技术包括在反向传播过程中重新计算RMSNorm操作和MLA上投影,避免了持久存储这些操作的输出激活,从而显著减少了存储激活所需的内存。此外,模型参数的指数移动平均(EMA)在CPU内存中异步更新,避免了额外的内存或时间开销。MTP模块与主模型共享嵌入层和输出头,进一步增强了内存效率。这些策略使得DeepSeek-V3能够在不牺牲性能的情况下,有效地减少了训练过程中的内存占用和开销。
-
FP8 Training
受低精度训练的最新进展的启发,作者提出了一种基于FP 8数据格式的细粒度混合精度框架,用于训练DeepSeek-V3。虽然低精度训练有很大的希望,但它经常受到激活、权重和梯度中离群值的限制。尽管在推理量化方面已经取得了显著的进步,但是相对较少的研究证明了低精度技术在大规模语言模型预训练中的成功应用。
为了解决这一问题并有效地扩展FP 8格式的动态范围,作者引入了一种细粒度量化策略:使用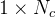
混合精度框架
作者提出了一种用于FP 8训练的混合精度框架。在该框架中,大多数计算密度运算在FP 8中进行,而少数关键运算则策略性地保持在其原始数据格式中,以平衡训练效率和数值稳定性。总体框架下图所示。
混合精度:高精度与低精度结合, 在计算密集型操作(如矩阵乘法)中使用低精度(如 FP8、FP16)以加速计算和减少内存占用,而在对数值敏感的操作(如梯度累加、权重更新)中使用高精度(如 FP32)以确保数值稳定性。
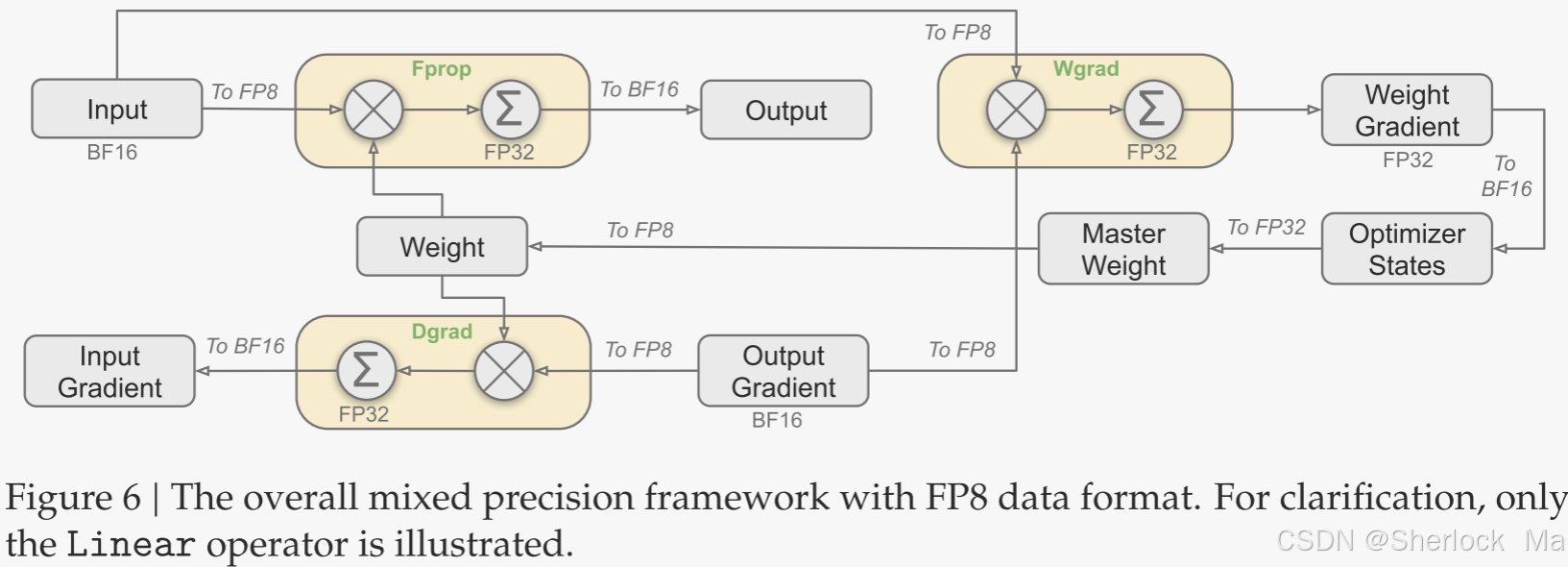
首先,为了加速模型训练,大多数核心计算内核,如GEMM操作,在FP8精度中实现。这些GEMM操作接受FP8张量作为输入,并在BF16或FP32中产生输出。与线性运算符相关的所有三个GEMM,即Fprop(前向传递)、Dgrad(激活后向传递)和Wgrad(权重后向传递),都在FP8中执行。与原始BF 16方法相比,这种设计理论上使计算速度加倍。此外,FP8 Wgrad GEMM允许将激活存储在FP8中,以用于反向传递。这大大降低了内存消耗。
尽管FP 8格式具有效率优势,但由于其对低精度计算的敏感性,某些运算符仍然需要更高的精度。此外,一些低成本运算符还可以利用更高的精度,而总体培训成本的开销可以忽略不计。因此,经过仔细研究,我们保持了原始精度(例如,BF 16或FP 32),用于以下组件:the embedding module, the output head, MoE gating modules,normalization operators, and attention operators。这些针对性的高精度保留确保了DeepSeek-V3的稳定训练动态。
为了进一步保证数值稳定性,作者以更高的精度存储主权重、权重梯度和优化器状态。虽然这些高精度组件会产生一些内存开销,但可以通过在我们的分布式训练系统中跨多个DP行列进行有效分片来最大限度地减少它们的影响。
通过量化和乘法提高精度
细粒度量化。在低精度训练框架中,上溢和下溢是常见的挑战,这是由于FP 8格式的动态范围有限,其受限于其减少的指数位。标准方法通过将输入张量的最大绝对值缩放到FP 8的最大可表示值,将输入分布与FP 8格式的可表示范围对准。该方法使得低精度训练对激活离群值高度敏感(highly sensitive to activation outliers),从而严重降低量化精度。
为了解决这个问题,作者提出了一种细粒度量化方法,该方法在更粒度的级别上应用缩放。如下图(1)所示,对于激活,作者以1x 128块为基础对元素进行分组和缩放(即,每128个信道每个令牌);以及(2)对于权重,作者在128 × 128块的基础上对元素进行分组和缩放(即,每128个输入通道每128个输出通道)。该方法通过根据更小的元素组调整尺度来确保量化过程可以更好地适应离群值。
简单来说:分块量化(Tile-wise Quantization):将输入张量(如激活值、权重)划分为小块(如 1x128 或 128x128),并对每个小块单独进行量化。每个小块使用独立的缩放因子(scale factor),以适应其动态范围,从而减少量化误差。
在作者的方法中的一个关键修改是沿GEMM操作的内部维度沿着引入每组缩放因子。标准FP8 GEMM不直接支持此功能。然而,结合作者精确的FP32积累策略,它可以有效地实现。
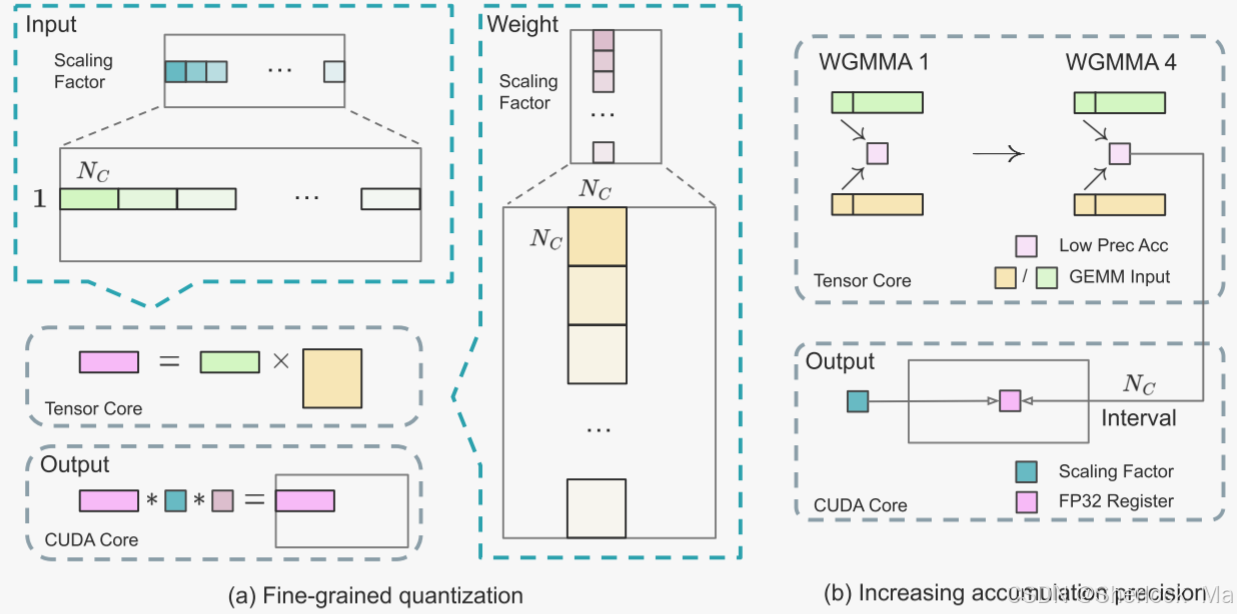
提高累加精度:低精度GEMM运算通常遭受下溢问题,且其精度很大程度上取决于高精度累加,其通常以FP 32精度执行。然而,作者观察到NVIDIA H800 GPU上 FP8 GEMM的累加精度仅限于保留14位左右,这明显低于FP 32的累加精度。当内部尺寸K大时这个问题将变得更加明显,这是大规模模型训练中批量和模型宽度增加的典型场景。尽管存在这些问题,但有限的累积精度仍然是少数FP 8框架(NVIDIA,2024 b)中的默认选项,严重限制了训练精度。
为了解决这一问题,作者采取了向CUDA Core升级以提高精度的策略。该过程如图(B)所示。具体地说,在张量核上执行MMA(矩阵乘法累加)期间,使用有限的位宽累加中间结果。一旦达到的间隔,这些部分结果将被复制到CUDA内核上的FP32寄存器,在其中执行全精度FP32累加。
简单来说:在 NVIDIA GPU 上,利用 CUDA Core 进行高精度累加,而不是完全依赖 Tensor Core 的低精度累加。
值得注意的是,此修改降低了单个翘曲组的WGMMA(Warpgroup-level Matrix Multiply-Accumulate)指令发出率。然而,在H800体系结构上,两个WGMMA通常会同时存在:当一个warpgroup执行提升操作时,另一个warpgroup能够执行MMA操作。这种设计能够实现两种操作的重叠,从而保持张量核心的高利用率。根据我们的实验,设置=128个元素,相当于4个WGMMA,表示可以显著提高精度而不引入大量开销的最小累加间隔。
(WGMMA) 是 NVIDIA GPU 架构中的一种高效矩阵乘法累加操作,专为 Tensor Core 设计,用于加速低精度矩阵计算(如 FP8、FP16)。它通过利用 Tensor Core 的并行计算能力,显著加速大规模矩阵计算,同时支持高精度累加以减少精度损失。
尾数除以指数:与先前工作所采用的混合FP 8格式不同,在Fprop中使用E4 M3(4位指数和3位尾数),作者在Dgrad和Wgrad中使用E5 M2(5位指数和2位尾数),在所有张量上都采用E4 M3格式以获得更高的精度。作者将这种方法的可行性归因于细粒度量化策略,即,平铺和块式缩放。通过对较小的元素组进行操作,作者的方法有效地在这些分组的元素之间共享指数位,从而减轻了有限动态范围的影响。
在线量化:在张量式量化框架中采用延迟量化,其保持在先前迭代中的最大绝对值的历史以推断当前值。为了确保秤的准确性并简化框架,作者在线计算每个1x 128激活块或128 x128砝码块的最大绝对值。在此基础上,作者推导出比例因子,然后将激活或权重在线量化为FP 8格式。
简单来说:在每次计算时动态计算缩放因子,而不是使用历史统计值,确保量化过程更加准确。
低精度存储和通信
作者通过将缓存的激活和优化器状态压缩为较低精度的格式,进一步减少了内存消耗和通信开销。
低精度优化器状态:作者采用BF16数据格式而不是FP32来跟踪AdamW优化器中的一阶和二阶矩,而不会导致可观察到的性能下降。然而,主权重(由优化器存储)和梯度(用于批量累积)仍然保留在FP32中,以确保整个训练过程中的数值稳定性。
低精度激活:Wgrad操作在FP8中执行。为了减少内存消耗,自然会选择以FP8格式缓存激活,以便向后传递线性运算符。但是,为了进行低成本高精度培训,对几个运算符进行了特殊考虑:
- 注意力运算符之后的线性输入。
- MOE中SwiGLU运算符的输入。
低精度通信:通信带宽是MoE模型训练中的一个关键瓶颈。为了缓解这一挑战,我们在MOE上投影之前将激活量化到FP8中,然后在MOE上投影中应用与FP8 Fprop兼容的调度组件。与操作符之后的线性的输入类似,用于该激活的缩放因子是2的整数幂。在莫伊向下投影之前,将类似的策略应用于激活梯度。对于前向和后联合收割机组件,作者将其保留在BF16中,以保持训练管道关键部分的训练精度。
-
推理和部署
作者在H800集群上部署了DeepSeek-V3,其中每个节点内的GPU通过NVLink互连,整个集群中的所有GPU通过IB完全互连。为了同时确保在线服务的服务级别目标(SLO)和高吞吐量,作者采用以下部署策略,将预填充和解码阶段分开。
预装填
预填充阶段的最小部署单元由4个节点和32个GPU组成。注意力部分采用4向张量分类(TP 4)和序列分类(SP),结合8向数据分类(DP 8)。
为了在MOE部分的不同专家之间实现负载平衡,我们需要确保每个GPU处理大约相同数量的令牌。为此,我们引入了冗余专家的部署策略,重复高负载的专家,并部署他们冗余。基于在线部署期间收集的统计信息来检测高负载专家,并且周期性地调整高负载专家(例如,每隔10分钟)。在确定冗余专家集之后,我们根据观察到的负载在节点内的GPU之间仔细重新安排专家,努力在不增加跨节点所有对所有通信开销的情况下尽可能地平衡GPU之间的负载。对于DeepSeek-V3的部署,我们为预填充阶段设置了32名冗余专家。对于每个GPU,除了原有的8个专家外,它还将托管一个额外的冗余专家。
最后,作者正在探索专家的动态冗余策略,其中每个GPU托管更多专家(例如,16个专家),但在每个推理步骤中只有9个将被激活。在每一层的所有对所有操作开始之前,我们在运行中计算全局最优路由方案。考虑到预填充阶段涉及的大量计算,计算此路由方案的开销几乎可以忽略不计。
解码
在解码过程中,我们将共享专家视为路由专家。从这个角度来看,每个令牌将在路由期间选择9个专家,其中共享的专家被视为将始终被选择的重负载专家。对于MoE部分,每个GPU只托管一个专家,64个GPU负责托管冗余专家和共享专家。调度和合并部分的全对全通信通过IB上的直接点对点传输来执行,以实现低延迟。此外,我们还利用IBGDA技术进一步减少延迟并提高通信效率。
与预填充类似,作者根据在线服务的统计专家负载,在一定的时间间隔内定期确定冗余专家的集合。然而,不需要重新安排专家,因为每个GPU只托管一个专家。作者还在探索解码的动态冗余策略。
此外,为了提高吞吐量并隐藏所有对所有通信的开销,作者还在探索在解码阶段同时处理两个具有相似计算工作量的微批。与预填充不同,注意力在解码阶段消耗了更大部分的时间。
在解码阶段,每个专家的批量大小相对较小(通常在256个令牌内),瓶颈是内存访问而不是计算。由于MoE部分只需要加载一个专家的参数,因此内存访问开销最小,因此使用较少的SM不会显著影响整体性能。因此,为了避免影响注意力部分的计算速度,作者可以只分配一小部分SM来dispatch+MoE+combine。
-
硬件设计建议
本节讨论了DeepSeek-V3在硬件设计方面的建议,分为两个主要部分:
- 通信硬件建议:DeepSeek-V3提出了未来通信硬件设计的建议,希望开发出能够从宝贵的计算单元SM中卸载通信任务的硬件,如GPU协处理器或网络协处理器。同时,建议这些硬件能够统一InfiniBand(IB)和NVLink网络,简化计算单元的操作复杂性。
- 计算硬件建议:对于计算硬件,DeepSeek-V3建议未来的芯片设计应该增加Tensor Cores中的FP8 GEMM累积精度,支持Tile和Block级别的量化,支持在线量化,以及支持转置GEMM操作。这些改进旨在提高训练和推理算法的准确性,同时保持计算效率。
3.4 预训练
数据
与DeepSeek-V2相比,作者通过提高数学和编程样本的比例来优化预训练语料,同时扩大英语和中文以外的多语言覆盖范围。此外,作者对数据处理管道进行了改进,以尽量减少冗余,同时保持语料库的多样性。作者实现了用于数据完整性的文档打包方法,但在训练过程中没有引入跨样本注意力掩蔽。最后,DeepSeek-V3的训练语料库由作者的tokenizer中的14.8T高质量和多样化的token组成。
在DeepSeekCoder-V2的训练过程中,我们观察到中间填充(Fill-in-Middle,缩写为FLM)策略不会影响next-token的预测能力,同时使模型能够根据上下文线索准确预测中间文本。为了与DeepSeekCoder-V2保持一致,我们还在DeepSeek-V3的预训练中加入了FLM策略。具体来说,我们使用Prefix-Suffix-Middle(PSM)框架来构建数据,如下所示:
<|fim_begin|> 𝑓pre<|fim_hole|> 𝑓suf<|fim_end|> 𝑓middle<|eos_token|>.此结构作为预打包过程的一部分应用于文档级别。按照PSM框架,以0.1的比率应用FIM战略。
Fill-in-Middle(FIM)是一种数据增强技术,通常用于训练语言模型,特别是在预训练阶段。这种方法的核心思想是将输入文本的中间部分替换为一个特殊的标记(如
<|fim_hole|>),然后让模型基于文本的上下文(即替换部分前后的文本)来预测被替换的中间部分。这种技术可以增强模型对上下文的理解能力,提高其在各种语言任务上的性能。例如,如果有一个句子:“DeepSeek-V3 is a large language model with 671B parameters.” 使用FIM策略,可能会被处理成:
DeepSeek-V3 is a large language model with <|fim_hole|> parameters.
具体来说,PSM方法包括以下几个步骤:
前缀(Prefix):这是输入文本的开始部分,为模型提供上下文信息,帮助模型理解后续需要预测的内容。
后缀(Suffix):这是输入文本的结束部分,同样提供上下文信息,但在这里,它通常用于指示模型预测完成后应该继续的文本内容。
中间部分(Middle):这是位于前缀和后缀之间的文本部分,通常被替换为一个特殊的标记或掩码(如
<|fim_hole|>),模型的任务是预测这部分的内容。在实际应用中,PSM可以这样操作:
- 将一个文档或句子分为前缀、中间和后缀三个部分。
- 将中间部分替换为一个特殊的标记,如
<|fim_hole|>。- 让模型根据前缀和后缀的上下文信息预测中间部分的内容。
例如,考虑以下句子:
“DeepSeek-V3 is a state-of-the-art language model with 671B parameters.”
使用PSM方法,这个句子可以被重构为:
“DeepSeek-V3 is a state-of-the-art language model with <|fim_hole|> parameters.”
在这里,
<|fim_hole|>代表被掩码的中间部分,模型需要预测出“671B”这个具体的数值。
用于DeepSeek-V3的tokenizer采用字节级BPE(Byte-level BPE),扩充了128K的词汇量。为了优化多语言压缩效率,我们修改了pretokenizer和tokenizer的训练数据。此外,与DeepSeek-V2相比,新的pretokenizer引入了combine punctuations和 line breaks。然而,当模型处理多行提示而没有终端行中断时,特别是对于few-shot评估提示词,这种技巧可能会引入标记边界偏差(token boundary bias)。为了解决这一问题,我们在训练过程中随机分割一定比例的此类组合标记(combined tokens),这将模型暴露于更广泛的特殊情况,并减轻了这一偏差。
Pretokenizer 是文本预处理的一个步骤,它发生在正式的分词(tokenization)之前。Pretokenizer 的主要作用是对原始文本进行初步的处理,以便为后续的分词器提供一个更干净、更规范的输入。这样可以提高分词的准确性和效率,尤其是在处理多种语言或者包含复杂结构(如代码、数学公式等)的文本时。
Pretokenizer 通常会执行以下操作:
- 去除空白字符:删除文本中的多余空格、换行符、制表符等。
- 处理标点符号:识别并处理标点符号,例如将它们与相邻的单词分开,或者在某些情况下将它们与单词合并(例如缩写)。
- 识别特殊符号:识别文本中的特殊符号,如表情符号、数学符号等,并进行适当的处理。
- 处理数字和日期:识别数字、日期和其他数值实体,并可能将它们转换为标准化的格式。
- 合并或分割字符:根据需要合并连续的字符(如连字符)或分割字符(如中文中的标点符号)。
- 语言特定的处理:对于特定语言的文本,Pretokenizer 可能会执行语言特有的预处理步骤,如处理中文文本中的全角和半角字符。
-
Hyper-Parameters
模型超参数:我们将Transformer的层数设置为61,将隐藏维度设置为7168。所有可学习的参数都是随机初始化的,标准差为0.006。在MLA中,我们将注意头的数量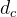

-
长上下文扩展
作者采用了与DeepSeek-V2类似的方法来实现DeepSeek-V3中的长上下文功能。在预训练阶段之后,作者应用YaRN用于上下文扩展,并且执行两个附加的训练阶段,每个训练阶段包括1000个步骤,以将上下文窗口从4K逐渐扩展到32 K,然后扩展到128 K。YaRN配置与DeepSeek-V2中使用的配置一致,仅应用于解耦共享key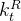
通过这种两阶段的扩展训练,DeepSeek-V3能够处理长度高达128 K的输入,同时保持强大的性能。
-
评估
DeepSeek-V3的基础模型是在以英语和中文为主的多语言语料库上进行预训练的,因此我们在一系列主要以英语和中文为主的基准测试以及多语言基准测试上评估其性能。我们的评估是基于我们的内部评估框架集成在我们的HAI-LLM框架。
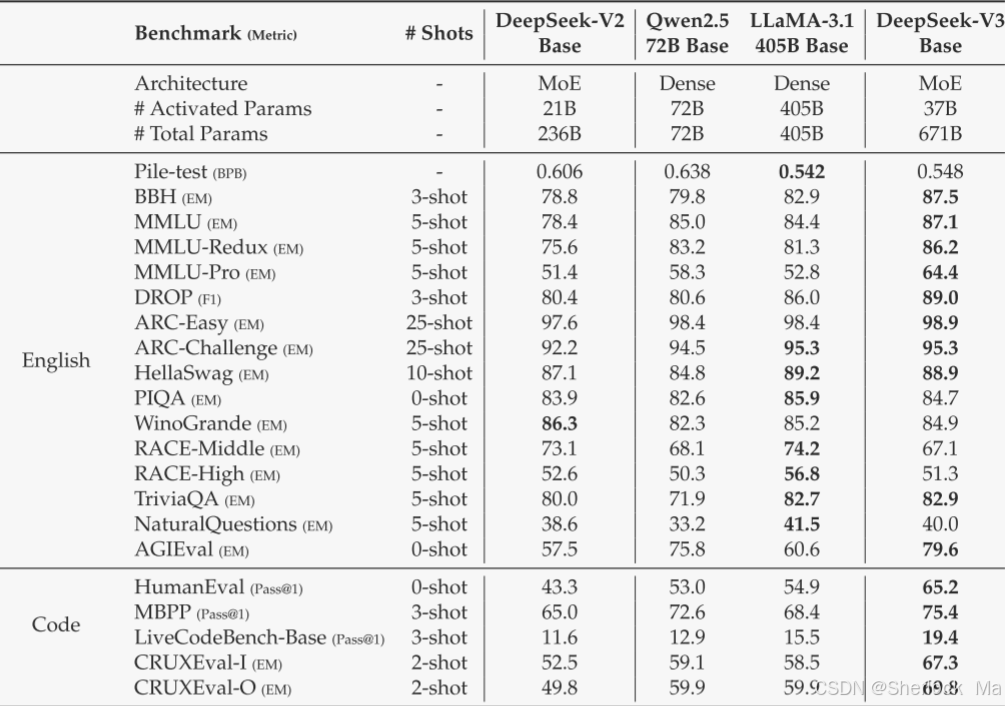
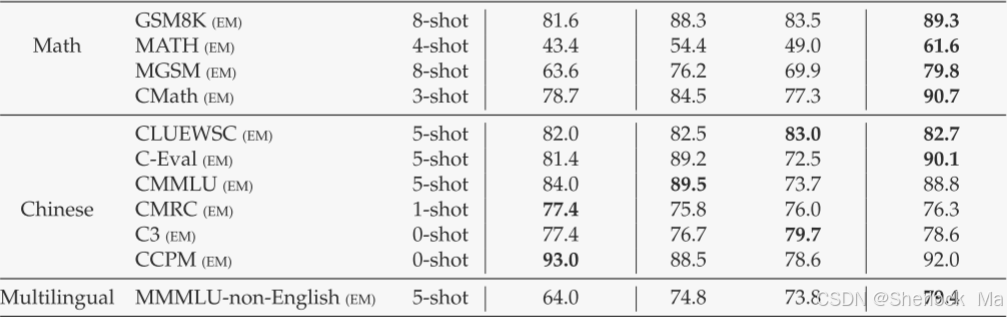
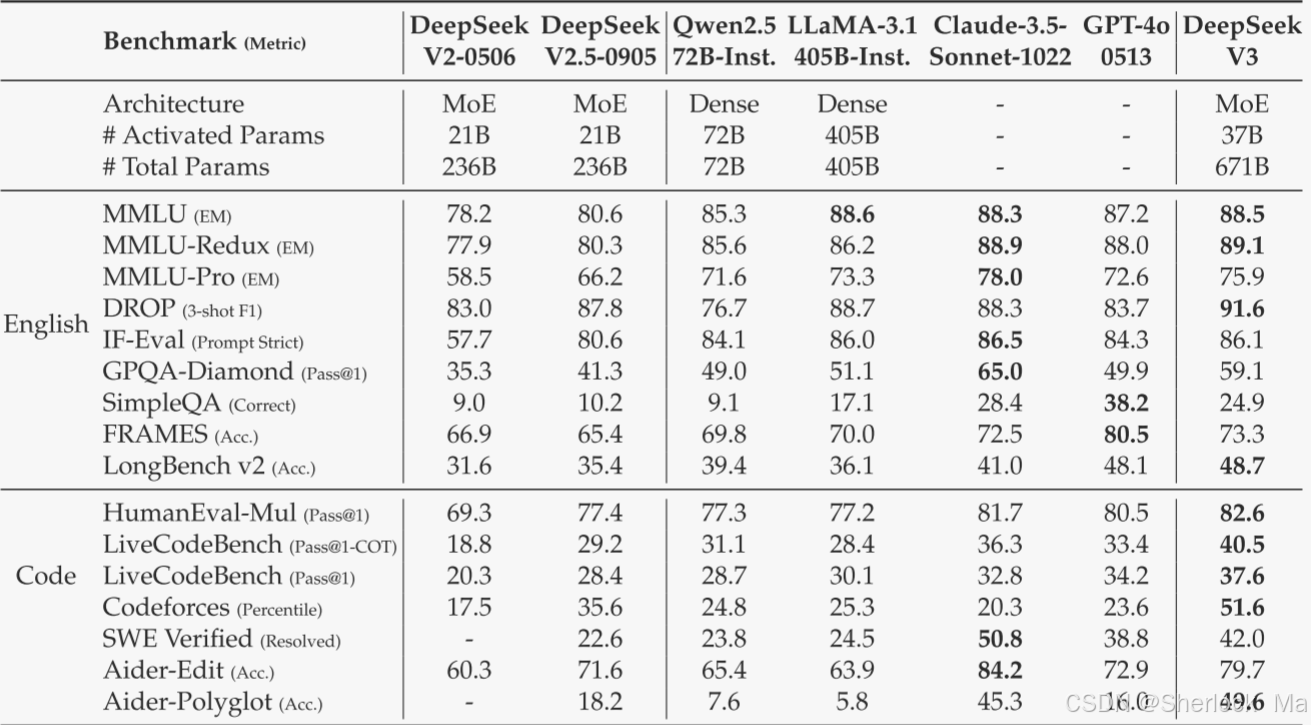
总体而言,DeepSeek-V3-Base全面优于DeepSeek-V2-Base和Qwen2.5 72 B Base,并在大多数基准测试中超过LLaMA-3.1 405 B Base,基本上成为最强的开源模型。
由于作者高效的架构和全面的工程优化,DeepSeekV 3实现了极高的训练效率。在作者的训练框架和基础设施下,在每万亿个令牌上训练DeepSeek-V3只需要180 K H800 GPU小时,这比训练72 B或405 B密集模型便宜得多。
-
讨论
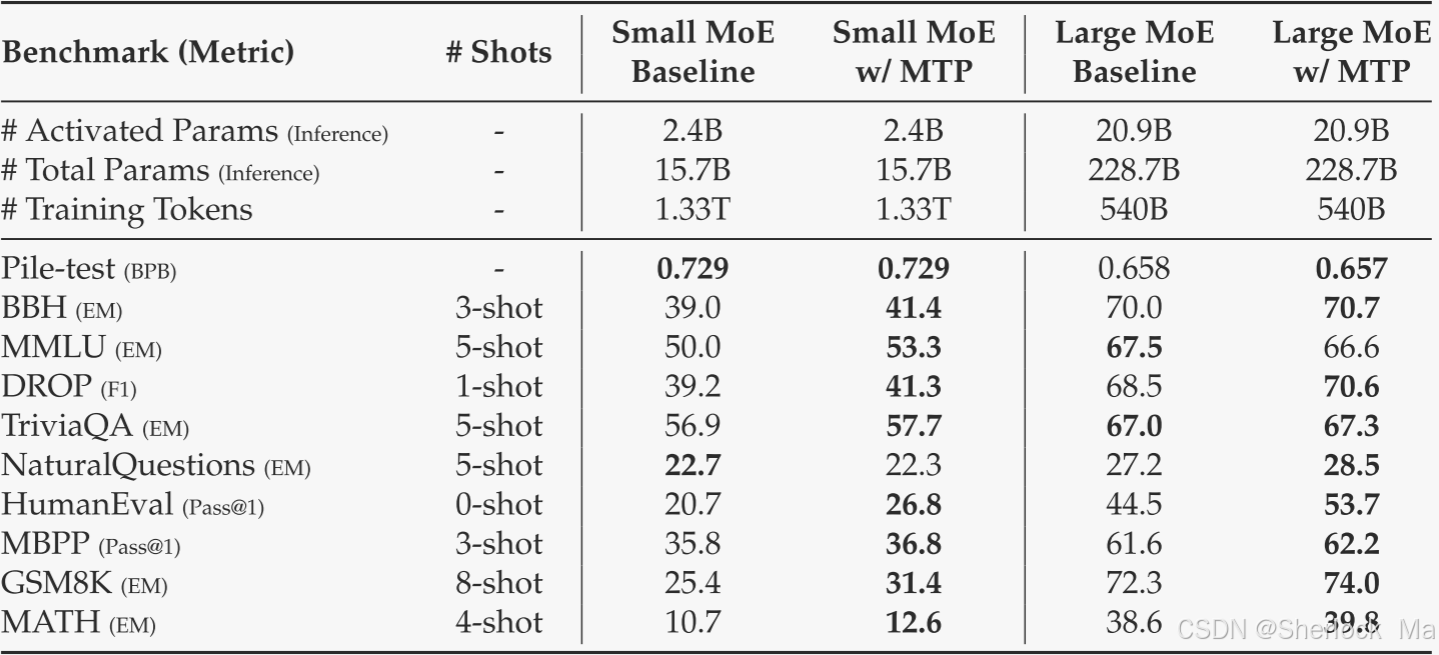
MTP的消融实验
以下是MTP策略的消融结果。具体来说,作者在两个不同尺度的基线模型上验证了MTP策略。在小规模下,我们在1.33 Ttoken上训练了一个包含15.7 B总参数的基线MoE模型。在大规模上,作者训练了一个基线MoE模型,该模型包括540 B令牌上的228.7 B总参数。在它们之上,保持训练数据和其他架构相同,作者在它们上面附加了一个深度为1的MTP模块,并使用MTP策略训练两个模型进行比较。请注意,在推理过程中,作者直接丢弃MTP模块,因此比较模型的推理成本完全相同。从表中,我们可以观察到MTP策略在大多数评估基准上持续增强了模型性能。
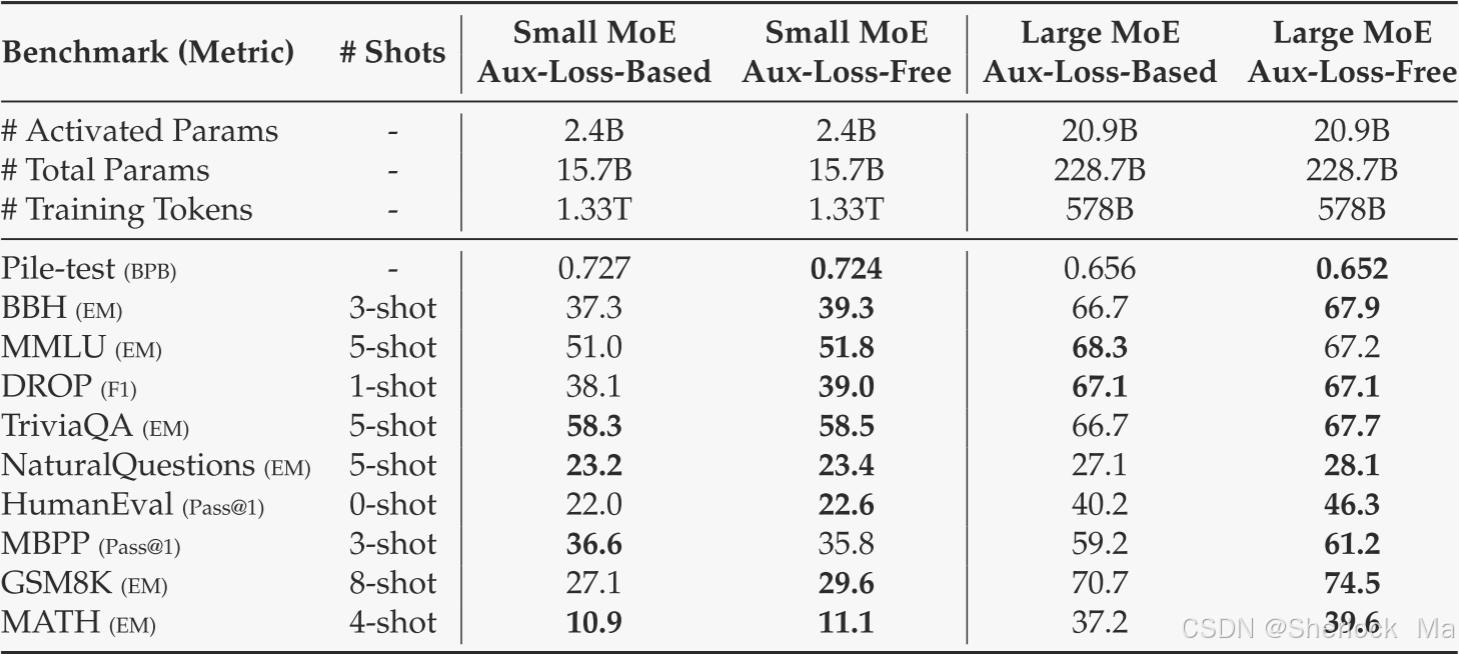
Auxiliary-Loss-Free Balancing Strategy的消融实验
作者同样在两个不同尺度的基线模型上验证该策略
两个基线模型都纯粹使用辅助损失来促进负载平衡,并使用具有前K亲和力归一化的sigmoid门控函数。它们控制辅助损失强度的超参数分别与DeepSeek-V2-Lite和DeepSeek-V2相同。在这两个基线模型之上,保持训练数据和其他架构相同,我们去除了所有辅助损失,并引入了无辅助损失的平衡策略进行比较。从表中,我们可以观察到,在大多数评估基准上,无损失策略始终实现更好的模型性能。
Batch-Wise Load Balance VS. Sequence-Wise Load Balance
无辅助损失平衡和序列辅助损失之间的关键区别在于它们的平衡范围:批与训练。与训练辅助损失相比,批量平衡施加了更灵活的约束,因为它不对每个序列强制域内平衡。这种灵活性使专家能够更好地专注于不同的领域。为了验证这一点,我们记录和分析专家负载的16B的基于辅助损失的基线和16B的无辅助损失模型在不同的领域的表现。

无损失模型比基于损失的模型显示出更大的专家专业化模式。相对专家负荷(relative expert load)表示实际专家负荷与理论上平衡的专家负荷之间的比率。
此外,虽然批量负载均衡方法显示出一致的性能优势,但它们在效率上也面临两个潜在的挑战:(1)某些序列或小批量内的负载不平衡,以及(2)推理期间域移位(domain-shift-induced)引起的负载不平衡。第一个挑战自然由作者的训练框架解决,该框架使用大规模专家并行性和数据并行性,这保证了每个微批的大尺寸。对于第二个挑战,作者还设计和实现了一个有效的推理框架,冗余的专家部署以克服它。
-
3.5 后训练
监督微调
作者准备了一个指令调优数据集,包括跨越多个域的150万个实例,每个域都采用针对其特定要求定制的不同数据创建方法。
推理数据:对于与推理相关的数据集,包括那些专注于数学、代码问题和逻辑谜题的数据集,作者通过利用内部DeepSeek-R1模型来生成数据。具体来说,虽然R1生成的数据显示了很高的准确性,但它存在一些问题,如考虑过多、格式不佳和过长。作者的目标是平衡R1生成的推理数据的高准确性和规则格式的推理数据的清晰度和简洁性。
作者开发了一个针对特定领域(如代码,数学或一般推理)的专家模型,使用组合的监督微调(SFT)和强化学习(RL)训练管道。该专家模型作为最终模型的数据生成器。训练过程涉及为每个实例生成两种不同类型的SFT样本:第一种将问题与其原始响应以<问题,原始响应>的格式结合,而第二种将系统提示与问题和R1响应一起以<系统提示,问题,R1响应>的格式合并。
系统提示经过精心设计,包括指导模型产生响应的指令,这些响应富含反射和验证机制。在RL阶段,即使没有明确的系统提示,该模型也会利用high-temperature采样来生成响应,这些响应将来自R1生成的数据和原始数据集成在一起。在数百个RL步骤之后,中间RL模型学习并入R1模式,从而策略性地增强整体性能。
在完成RL训练阶段后,我们实施拒绝抽样来为最终模型管理高质量的SFT数据,其中专家模型用作数据生成源。这种方法确保最终的训练数据保留了DeepSeek-R1的优势,同时产生简洁有效的响应。
非推理性数据:对于非推理数据,如创意写作、角色扮演、简单问答等,我们使用DeepSeek-V2.5生成响应,并招募人工标注员验证数据的准确性和正确性。
SFT设置:作者使用SFT数据集微调DeepSeek-V3-Base的两个时期,使用从5 × 10−6开始并逐渐降低到1 × 10−6的余弦衰减学习率调度。在训练过程中,从多个样本中打包每个单个序列。但是,作者采用了一种样本掩蔽策略,以确保这些示例保持隔离和相互不可见。
-
强化学习
我们采用基于规则的奖励模型(RM)和基于模型的RM在我们的RL过程。
基于规则的RM:对于可以使用特定规则进行验证的问题,我们采用基于规则的奖励系统来确定反馈。例如,某些数学问题具有确定性的结果,我们要求模型以指定的格式提供最终答案(例如,在框中),允许我们应用规则来验证正确性。类似地,对于LeetCode问题,我们可以利用编译器来基于测试用例生成反馈。通过尽可能利用基于规则的验证,我们确保了更高级别的可靠性,因为这种方法可以防止操纵或利用。
基于模型的RM:对于没有确定的基本事实的问题,例如那些涉及创造性写作的问题,奖励模型的任务是基于问题和作为输入的相应答案来提供反馈。奖励模型是从DeepSeek-V3 SFT检查点训练的。为了提高其可靠性,我们构建了偏好数据,不仅提供了最终的奖励,而且还包括导致奖励的思维链。这种方法有助于降低特定任务中的报酬黑客攻击风险。
组相关策略优化(Group Relative Policy Optimization)
与DeepSeek-V2类似,作者采用组相对策略优化(GRPO),其放弃了通常与策略模型具有相同大小的批评者模型,而是根据组分数来估计基线。具体而言,对于每个问题,GRPO从旧策略模型中抽取一组输出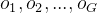
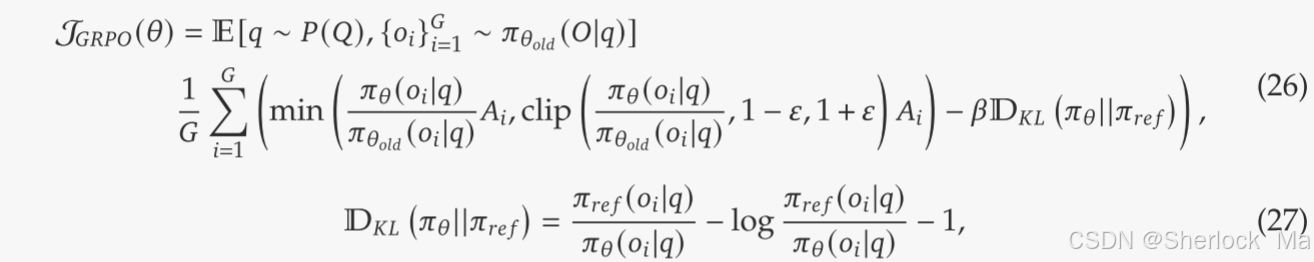
其中,
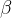
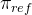
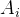
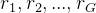

在RL过程中,作者结合了来自不同领域的提示,例如编码,数学,写作,角色扮演和问答。这种方法不仅使模型与人类偏好更紧密地保持一致,而且还增强了基准测试的性能,特别是在可用SFT数据有限的情况下。
-
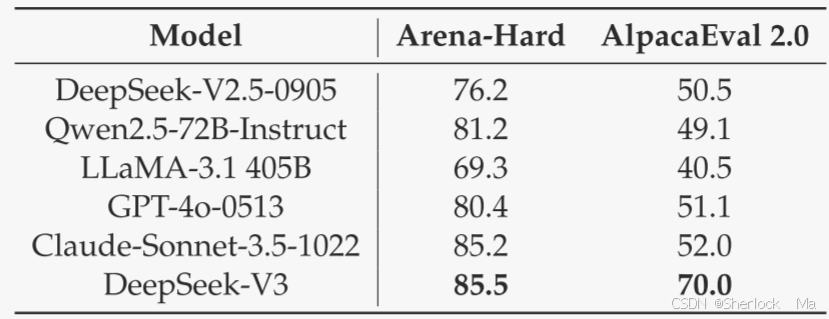
评估

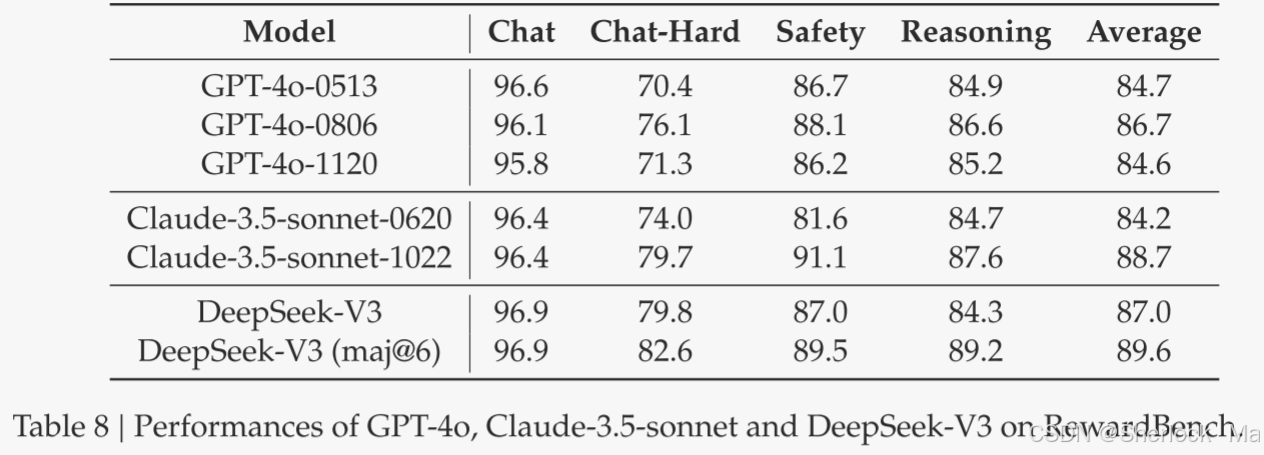
-
讨论
Distillation from DeepSeek-R1
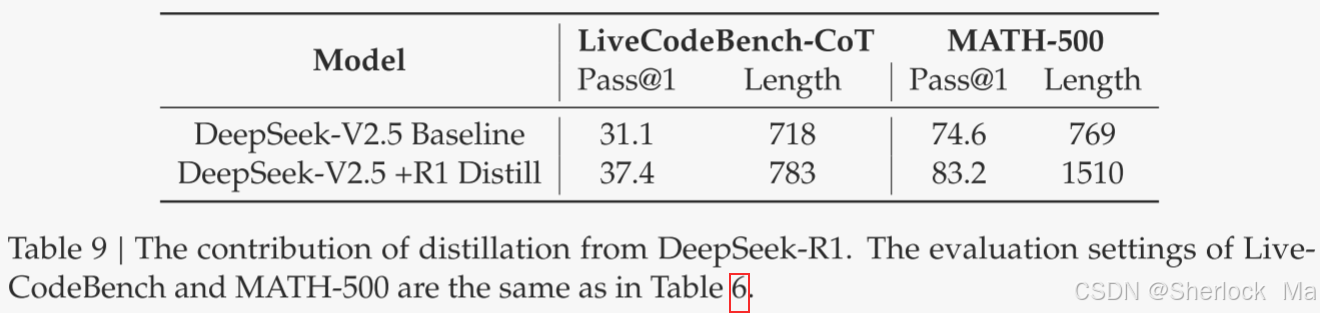
表9展示了蒸馏数据的有效性,显示了LiveCodeBench和MATH-500基准测试的显著改进。作者的实验揭示了一个有趣的权衡:蒸馏导致更好的性能,但也大大增加了平均响应长度。
虽然作者目前的工作重点是从数学和编码领域提取数据,但这种方法显示出在各种任务领域更广泛应用的潜力。在这些特定领域中证明的有效性表明,长CoT蒸馏对于增强其他需要复杂推理的认知任务中的模型性能可能是有价值的。在不同领域进一步探索这种方法仍然是未来研究的重要方向。
Self-Rewarding:奖励在强化学习中发挥着关键作用,引导着优化过程。在通过外部工具进行验证很简单的领域,例如一些编码或数学场景,RL表现出非凡的功效。然而,在更一般的场景中,通过硬编码来构建反馈机制是不切实际的。在DeepSeek-V3的开发过程中,对于这些更广泛的背景,我们采用了constitutional AI,利用DeepSeek-V3本身的投票评估结果作为反馈来源。该方法产生了显著的对齐效果,显著提高了DeepSeek-V3在主观评价中的性能。通过整合额外的constitutional输入,DeepSeek-V3可以朝着constitutional方向进行优化。作者相信,这种将补充信息与LLM作为反馈源相结合的范式至关重要。LLM作为一个多功能的处理器,能够将非结构化信息从不同的场景转换为奖励,最终促进LLM的自我完善。
多令牌预测评估:DeepSeek-V3不是只预测下一个单个令牌,而是通过MTP技术预测下两个令牌。结合推测解码(speculative decoding)的框架,可以显著加快模型的解码速度。一个自然的问题是关于额外预测的令牌的接受率。根据我们的评估,在不同的生成主题中,第二个令牌预测的接受率在85%到90%之间,证明了一致的可靠性。这种高接受率使DeepSeek-V3能够显著提高解码速度,提供1.8倍的TPS(每秒令牌数)。
-
-
4.总结
DeepSeek-V3技术报告总结了一个具有671B参数的大型混合专家(Mixture-of-Experts,MoE)语言模型,它在每个token上激活了37B参数。该模型采用了多头潜在注意力(Multi-head Latent Attention,MLA)和DeepSeekMoE架构,以实现高效的推理和成本效益的训练。DeepSeek-V3还首次采用了无辅助损失的负载平衡策略,并设置了多token预测训练目标,以增强性能。模型在14.8万亿高质量tokens上进行了预训练,随后通过监督式微调和强化学习阶段,充分发挥其能力。
DeepSeek-V3在多个基准测试中表现出色,特别是在代码和数学任务上,超越了其他开源模型,并与领先的闭源模型相媲美。尽管性能优异,DeepSeek-V3的完整训练仅需要2.788M H800 GPU小时,训练过程非常稳定,没有经历任何不可恢复的损失峰值或回滚操作。模型权重可在GitHub上找到。
-
🌟✨ 探索知识的星辰大海,与我们一起启航!✨🌟
👍 点赞,让智慧的光芒照亮你我前行的道路; 🔄 关注,与我们携手,不错过每一次思维的火花。
在这里,我们不仅分享信息,我们共同创造未来。每一次互动,都是对无限可能的一次投票。加入我们,一起在知识的海洋中乘风破浪,发现更多的精彩!🚀🌐️