美团面试问题
1、了解你在项目中做了那些内容
- 1、采购系统(ssm
- 2、台账系统(ssm
- 3、商城系统(分布式
面试的对自己的建议
- 首先回答问题太快
- 然后节奏并不是特别好
- 回答得还是不够清晰,比如acid 没有回答得特别全面
- 另外就是,问题可能了解得还不够清晰(你需要记住他,然后分析他
- 有的问题需要深入回答一下,特别是你知道的,越详细越好
- 同时,经验还是不够,这个是我近两年第一次面试,感觉还是很不错了
整个流程
首先他直接是针对项目问的,ssm他并不感兴趣,分布式十分感兴趣,首先问了我 采购系统是什么样的一个架构,使用了什么技术,你在里面扮演了一个什么样的角色。
- 项目中遇到了那些问题
然后下一个项目,问你干了什么事情,台账系统,
- 干了什么事情
- 你遇到什么困难,在别人的项目中
- 前端使用了什么ui组件吗
下一步,就是商城系统,总共半个小时,我估计搞了我20分钟
- 架构
- 首先就是问项目是什么情况(我说是练习分布式
- 问用了那些技术
- 然后对于nacos 有那些优点,同时,nacos有那些替代品
- 问 你再使用远程调用的时候,他是怎么回事(基于tcp的一个调用
- 那么他们分别属于那一层
- sokect编程的话,对于各个http版本有什么不同
- tomcat是什么情况
- 是那个中间键实现的 tcp到http 和 远程调用的功能
- 线程的生命周期
- 你再项目中使用了那些隔离级别
- 如何保证项目的多线程的性能呐(我从 集合 和 这个锁的角度
redis启动
- redis干了什么事情呀
- redis 如何部署的,详细解释 todo
- redis 有什么可以替换的
- redis 缓存的问题和解决方案
- 你是如何部署的微服务
那我们来做个算法题吧
不会呀,没有思路
然后给我提示
我使劲敲
然后还是报错
- 你说一下你的思路吧
- 那你如何确定哪里有问题呐
- 你还有其他问题想要问我的吗
其他更为深度的问题
- cap是什么情况
- redis的各种模式下的优点
2、项目问题
项目当中使用了那些隔离级别
- 这个问题应该是说类似于数据库中的隔离级别,在那些地方运用到了
- 首先肯定是数据库啦
- redis去读取的时候,可能会出现脏读,也就是缓存问题,会出现这种情况啦(主要还是针对这个缓存问题去回答
purcahse中 消息通知是如何实现的
purchase项目中遇到了那些问题
设计方面
- 数据库考虑得不够全面,有时候一个新的业务冒出来,突然就不知道怎么办了
- 一些主流技术没有使用上,导致开发过程中十分缓慢
需求方面 - 这个是最烦的,挤牙膏似的,一会出现一个业务
数据处理效率
- 有时候需要多个表进行联查,最开始就是使用java代码进行筛选(其实直接使用一个联合查询即可实现)
开发环境问题
- 这个项目处理 搞得比较难受,各种jar包冲突,最后通过去网上查找,官网了解,查看兼容版本
台账系统 的问题
首先你干了什么事情
- 我就是在已有的项目中去添加了富文本的保存和读取,和这个团队链接邀请、数据报表的导出
- 最初的时候,只能够使用表单的形式提交数据,后来需要使用到富文本
- 也是业务的不断扩展,要求使用团队链接邀请
团队链接邀请应该怎么做
- 我直接使用了一个uuid来生成一个唯一的数值,(并设置过期时间)
- 同时,生成一个api的链接
- 这个人点击这个链接后,就来判断是否时间过期,属于那个团队(有个表保存了的)等等
报表导出怎么做
- Java使用itext组件导出pdf报表
你再融入别人的项目过程中遇到了那些问题
- 1、项目不够熟悉,需要做那些判定
- 2、在这个项目中,主要还是权限问题,比较困难,每个请求发过来后,是否允许处理(富文本:是否允许导出改报表,是否,能够编辑这个数据的情况)
这个项目的权限是如何限制的,还需要修改 todo
- 判断是否属于一个团队
- 文件发出者可以设置文件的权限(是否可修改,是否可以编辑,是否可以查看
- 角色权限(系统管理员、队长(都可以,)、二级管理员(可以邀请队员)、成员(不能邀请队员))
下一个就是这个分布式项目,太难顶了
3、MySQL
acid是什么
- 这个手拿把掐
- 原子性 一致性 隔离性 和这个持久性
- 原子性:一个事务(transaction)中的所有操作,要么成功要么失败,不会出现成功一般的情况(或者是一个不可分割性操作)
- 一致性:指的是 事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则(其他几条规则就是为这个服务)
- 隔离性: 允许多个并发事务同时对其数据进行读写和修改的能力(并发情况
- 持久性:是针对事务的,提交事务后,要持久存储在数据库中
4、redis
缓存雪崩 穿透 击穿
- 雪崩是指的这个 redis中,一批热点数据同时失效(解决:设置一个随机数,防止同时失效)
- 穿透是指这个不存在的key,直接去访问(恶意攻击),然后请求直接打到数据库上(redis上存储这些key,或者使用布隆过滤器)
- 击穿,比如这个 秒杀系统, 一个热点key ,很多人访问(直接设置为不过期)
redis是如何部署到项目中的
redis的集群部署、哨兵模式、cluster的特点(是否搭建过)
- 一个是主从复制(集群模式,基于主从复制,一个主节点可以用于写,而其余节点负责读,1、但是不能够去自动挑选master节点,也不能自动恢复数据(哨兵集群实现了这个功能,帮助选取master节点) 2、也无法在线扩容3、结构上为要给一主多从
- 一个是cluster(解决了自动恢复和选举mster问题,但是1、其他节点处于一个冷备的机制,只有master在使用。2、不支持这个 批量操作。另外,cluster模式实现了数据分片(slot 槽机制 范围)的机制,因此是一个多主多从的一个情况,多个节点同时工作)
redis干了什么事情呀
- 缓存,提高访问速度
- 会话存储
- 消息队列(简单的
- 计数器和统计 原子性的操作
- 分布式锁
- 持久化
- 分布式缓存
redis 如何部署的,详细解释 todo
redis 有什么可以替换的吗
5、注册中心
除了nacos还有那些
- 主要还是这个zookeeper,他和nacos的区别(三个方面,一致性可用性、协调服务、配置管理
- 1、ZooKeeper采用了强一致性的Zab协议(ZooKeeper Atomic Broadcast),确保数据的强一致性。这对于某些应用场景,如分布式锁、协调服务等非常重要。
- 1、Nacos在设计上更加注重可用性,使用了一种较为灵活的数据同步策略,权衡了一致性与可用性的关系。
- 2、ZooKeeper最初设计用于分布式协调服务,因此在实现分布式锁、选主、配置管理等方面表现出色。
- 2、Nacos更专注于服务发现和配置管理,对于需要强调服务注册与发现的场景更为合适。
- 3、ZooKeeper可以作为配置中心,实现配置的存储和动态更新。
- 3、Nacos专注于配置管理,提供了更多的特性,如动态配置、配置监听等。
- zookeeper为什么可以作为这个配置中心
- 1、一致性
- 2、节点持久化和临时性
- 3、监听机制
- 4、顺序节点(获取锁 并发情况
- 5、分层管理
nacos有什么优点呀
6、计算机网
websocket
- 这个问题首先需要谈到http(内容较多,需要再看一下),他主要有这几个变化,1、一个是长连接,2、一个是使用基于udp的quic协议(减少连接建立的时延),3、还有一个是头部压缩,4、管道化(一个连接,可以发送多个请求,5、多路复用,类似于管道化
- websocket 长连接 减少了延迟 双向实时通信(应用层协议),socket只是一个抽象
计算机网络的7层和4层模型
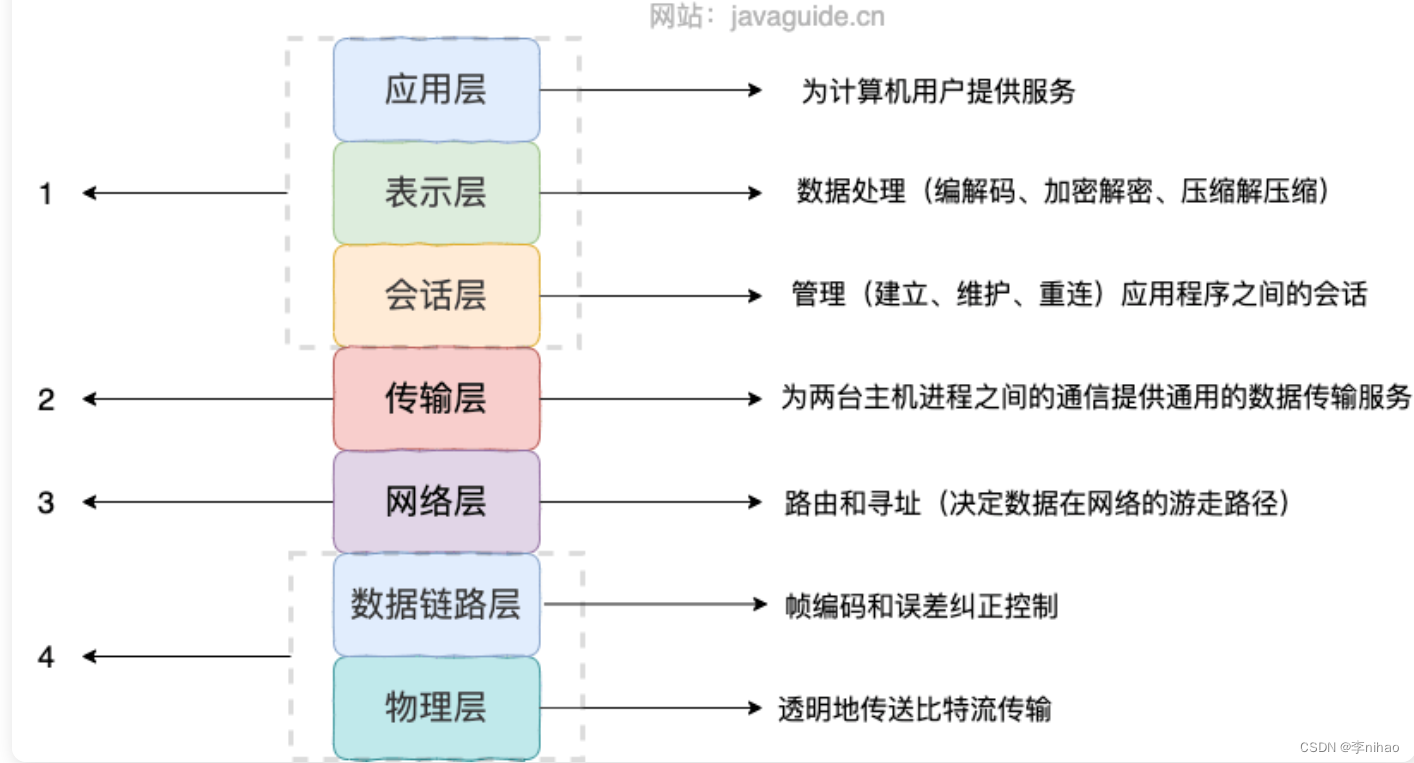
- TCP 是面向连接的、可靠的、有序的、速度慢的协议;UDP 是无连接的、不可靠的、无序的、速度快的协议。
- tcp使用需要稳定连接的情况,udp适合于打视频的情况
feign http tcp分别在那一层
- openfen和http属于应用
- tcp属于这个传输层
quic协议
- 连接更快
- 拥塞控制
- 内置tsl支持
7、微服务架构理论
cap(分布式理论,这里和强一致性和弱一致性又有关系
- 一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
- 一致性是指所有节点在同一时间看到的数据是一致的
- 可用性,每个请求都能够得到响应,即系统是可用的,且正常响应时间
- 分区容错 面对网络分区的情况下,仍然能够继续工作(网络中断的情况,一个分区不知道其他数据,你要保证一致性的化,你就不可用,你要保证可用,那就一段时间不一致
- ap cp,为什么不能同时满足呐?因为你要求一致,
BASE 理论
- 基本可用 不完全崩溃
- 软状态 系统中的数据可以存在中间状态,而不一定是实时一致的。系统允许一段时间内的不一致,但最终会达到一致状态
- 最终一致性 分布式系统中的数据经过一段时间后,最终会达到一致的状态。在这个过程中,系统允许数据的不一致性存在,但最终数据会趋向于一致。
- BASE理论相对于CAP理论,放宽了对一致性的要求,允许系统在一定时间内处于不一致的状态,但最终会趋向于一致。
8、算法题/项目问题
链表 BM14 链表的奇偶重排
- 面试官给了很多提示,然后才开始做的
- 首先拆分为两段,翻转后半段,最后合并
- 因此需要模块化的思想,这样不仅好排查错误,同时能够帮助我们整理思绪
- 分为 reorder reverse merge三个函数
class Solution {
public:
void reorderList(ListNode* head) {
if (head == nullptr || head->next == nullptr) {
return;
}
// 使用快慢指针找到链表中点
ListNode *slow = head, *fast = head;
while (fast->next != nullptr && fast->next->next != nullptr) {
slow = slow->next;
fast = fast->next->next;
}
// 翻转后半段链表
ListNode *secondHalf = reverseList(slow->next);
slow->next = nullptr; // 断开前后两段链表
// 合并两个链表
mergeLists(head, secondHalf);
}
private:
// 翻转链表
ListNode* reverseList(ListNode* head) {
ListNode *prev = nullptr, *curr = head, *next = nullptr;
while (curr != nullptr) {
next = curr->next;
curr->next = prev;
prev = curr;
curr = next;
}
return prev;
}
// 合并两个链表
void mergeLists(ListNode* l1, ListNode* l2) {
while (l1 != nullptr && l2 != nullptr) {
ListNode *next1 = l1->next, *next2 = l2->next;
l1->next = l2;
l2->next = next1;
l1 = next1;
l2 = next2;
}
}
};
9、java基础
arraylist和linklist的区别
- 这个问题就比较简单了,首先是他的底层数据结构
- 然后是这个 数据结构的特点
如何选择集合和锁来实现高效的多线程
- 首先是否需要线程安全
- 使用的场景,比如读多写少,还是写多读少
- 选择合适的锁(数据是否会被修改)
- 锁的顺序
- 线程执行顺序
threadLocal
- 这个多个线程隔离数据,典型的应用场景就是,spring框架的数据库连接 和 事务传递
- 但是会存在内存泄漏的情况,在线程池下面
thread
创建线程的几种方式
- 使用runable 接口
- 使用callable 接口 有返回值
- 集成thread
- 使用Executors 问题也有
线程的生命周期(考的是os的内容)
- 新建
- 就绪
- 运行
- 阻塞
- 等待
- 超时等待
- 结束
10、测试相关
如何定位到错误位置
- 调试
- 使用数据,看预期结果
- 使用日志进行分析
针对java来说
- 第一个分析堆栈信息
- 异常抛出情况
- 断言
- 日志
- 单元测试
- 数据
11、前端
- element-ui 饿了吗
12、feign
远程调用过程中,是那个中间键,实现了http请求变为 项目能够识别的请求
- 首先,服务器从 tcp中解析出 具体的 http请求,用socket或者websocket,
- 然后,来到tomcat容器,根据url 解析路径,将http请求解析为servlet ,然后解析为一些数据,之前写过这种代码
- 然后调用具体的servlet 并返回
算法部分
美团二面
突如其来的二面
首先,他问我这个 采购系统问题
权限是如何设计的
- 经典权限设计rpc??
然后是这个 如何防止这个重复点击 - 返回一个token
spring中并发是怎么回事
- controller是如何单列吗
如果多个请求进来,那么我们该如何处理,servlet
- 我回答加锁,感觉不对
- 观察是否有线程独有资源,有就可以通过加锁来控制
- 否则就不管
然后问我项目中最难的点是什么
权限
消息的轮询
如何进行重构呀
- 重构问题
算法问题
- 就是如何找到股票的最大最小值
项目经验之谈
你知道 RBAC权限模型吗
- 三个角色,用户 角色 权限 多对多的关系
- 基本版本:角色起到了桥梁的作用,连接了用户和权限的关系,每个角色可以关联多个权限,同时一个用户关联多个角色,那么这个用户就有了多个角色的多个权限
- 进一步版本:添加了层次结构,自动获取下级角色的权限
如何防止这个重复点击(接口幂等性)
- 问题性能上的消耗、数据冗余、 出现报错
- 唯一索引,先查询是否存在,再进行插入(检查和执行)
- 使用乐观锁的机制,带上上一次成功的版本(good
- token 令牌,判断是否为同一个请求,重复提交
消息通知和推送如何实现
- 轮询(还可以使用长连接
- websocket(不用客户端发起请求
- 消息队列的发布和订阅
- 专门的推送服务
spring中并发是怎么回事
几个要点:事务 并发控制 多线程
每个请求都会在一个独立的线程中进行处理
Controller 是单例的,
Spring MVC 的默认行为是通过多线程来处理并发请求(开发者自行确保 Controller 方法内的操作是线程安全的。)
如果有需要,我们可以加锁来控制
中间件你熟悉的有那些
消息中间键
Apache Kafka: 分布式流处理平台,用于构建实时数据管道和流应用程序。
RabbitMQ: 高度可靠的消息代理,实现了高级消息队列协议(AMQP)。
ActiveMQ: Apache 出品的开源消息中间件,实现了 Java Message Service(JMS)规范。
缓存中间件:
Redis: 高性能的键值存储系统,支持多种数据结构,用于缓存、消息中间件等。
Memcached: 分布式内存对象缓存系统,用于缓存大量数据,提高访问速度。
分布式数据库:
Apache Cassandra: 高度可扩展的分布式 NoSQL 数据库,适用于大规模分布式系统。
Apache HBase: 面向大表、分布式的 NoSQL 数据库,基于 Hadoop 分布式文件系统。
MongoDB: 面向文档的 NoSQL 数据库,存储 JSON 风格的文档。
分布式服务框架:
Spring Cloud: 用于构建分布式系统的一套全栈式解决方案,提供服务注册与发现、负载均衡、断路器等功能。
Dubbo: 阿里巴巴开源的高性能、轻量级的分布式服务框架。
gRPC: 基于 Protocol Buffers 的高性能 RPC(远程过程调用)框架,由 Google 开源。
搜索引擎:
Elasticsearch: 分布式搜索引擎,用于全文搜索、日志分析、数据可视化等。
Apache Solr: 基于 Apache Lucene 的开源搜索平台,支持全文搜索、分布式搜索等。
Web 服务器和反向代理:
Apache Tomcat: 开源的 Java Servlet 容器,用于运行 Java Web 应用。
Nginx: 高性能的反向代理服务器,常用于负载均衡、静态资源服务等。
分布式配置中心:
Spring Cloud Config: 用于集中管理应用程序配置的分布式配置中心。
nacos
分布式事务中间件:
Seata: 阿里巴巴开源的分布式事务解决方案,支持分布式事务的并发控制和故障恢复。