1 前言
CLIPasso: Semantically-Aware Object Sketching
CLIPasso获得了2022年的SIGGRAPH最佳论文奖,其论文题目Semantically-Aware Object Sketching,意思就是语义感知的物体素描。从下面包含有毕加索(Picasso)名画的这张图,可以看出CLIPasso就是CLIP和毕加索的缩写,这些都表明了这是一篇研究从图片生成简笔画的文章。

2 模型结构
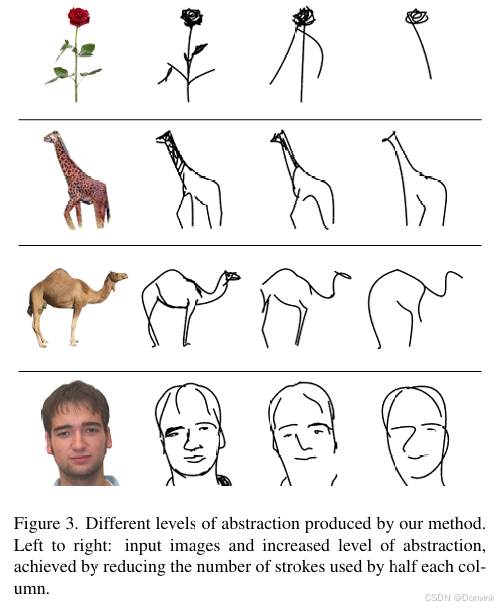
作者对训练方式、loss选择和简笔画初始设置都有所改进,才达到最终非常好的效果。比如下图,通过设置不同的笔画数,可以对图像进行不同层次的抽象:
2.1 训练过程
生成简笔画的方法不是直接做图到图的生成,而是使用图形学中的贝塞尔(贝兹)曲线来完成简笔绘画。贝塞尔曲线就是通过在平面上定义的几个点来确定一条曲线。本文中,每条曲线是通过四个点来确定,每个点都有其x,y坐标,即
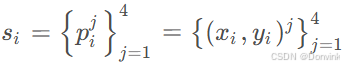
其中s是笔画Stroke的缩写,j从1到4表示其由4个点控制。
所以本文的方法就是随机初始化一些贝塞尔曲线,然后经过不停的训练,更改这些点的位置,从而更改贝塞尔曲线,得到最终的简笔画。训练过程如下图所示:
初始定义一些贝塞尔曲线s1到sn ,然后扔给光栅化器Rasterizer,就可以在二维画布上绘制出我们看得到的图像。根据loss训练笔画参数,得到最终的模型输出。

Rasterizer:光栅化器,图形学方向根据参数绘制贝塞尔曲线的一种方法,可导。所以这部分是是以前就有的方法,不做任何改动。
本文研究的重点:如何选择一个更好的初始化;以及如何选择合适的loss进行训练。
2.2 目标函数
生成的简笔画有两个要求,即在语义和结构上和原图保持一致。比如马还是马、牛还是牛;而且不能生成了马,但是马头的朝向反了,或者马从站着变成趴着。在 CLIPasso 中,这两个要求分别由两个损失函数——语义损失Ls和几何距离损失Lg来保证。
- Ls:semantics loss,计算原图特征和简笔画特征,使二者尽可能相似。使用 CLIP蒸馏CLIPasso模型(类似ViLD),可以让模型提取到的图像特征和 CLIP 图像编码器提取的特征接近。这样就借助了刚刚提到的CLIP的稳健性,即无论在原始自然图像上还是简笔画上都能很好的抽取特征。如果二者描述的是同一物体,那么编码后的特征都是同一语义,其特征必然相近。
- Lg:geometric distance loss,计算原图和简笔画的浅层编码特征的loss。借鉴了一些LowerLevel的视觉任务。因为在模型的前几层,学习到的还是相对低级的几何纹理信息,而非高层语义信息,所以其包含了一些长宽啊这些信息,对几何位置比较敏感。因此约束浅层特征可以保证原图和简笔画的几何轮廓更接近。(比如CLIP预训练模型backbone是ResNet50,就将ResNet50的stage2,3,4层的输出特征抽出来计算loss,而非池化后的2048维特征去计算)
2.3 初始化
作者发现,如果完全随机初始化贝塞尔曲线的参数,会使得模型训练很不稳定。生成的简笔画有的既简单又好看,有的怎么训练都恢复不了语义,甚至就是一团糟,所以需要找到一种更稳定的初始化方式。
基于saliency(显著性)的初始化:将图像输入ViT模型,对最后的多头自注意力取加权平均,得到saliency map。然后在saliency map上更显著的区域采点完成贝塞尔曲线参数的初始化,这样训练稳定了很多,效果也普遍好了很多。
在显著性区域采点,相当于你已经知道这里有个物体(语义更明确),或者已经相当于沿着物体的边界去绘制贝塞尔曲线了。这样初始化曲线和最终简笔画曲线已经比较接近了。
下图a展示了显著性初始化生成结果(Proposed )和随机初始化的生成结果(Random)的效果对比,可以看到Proposed的脸部特征更接近原图,而且头发更加简约。
这里作者还把自注意力的图和最后的采点分布图可视化了出来。可以看到采点分布图已经和最终的简笔画图像非常接近了。
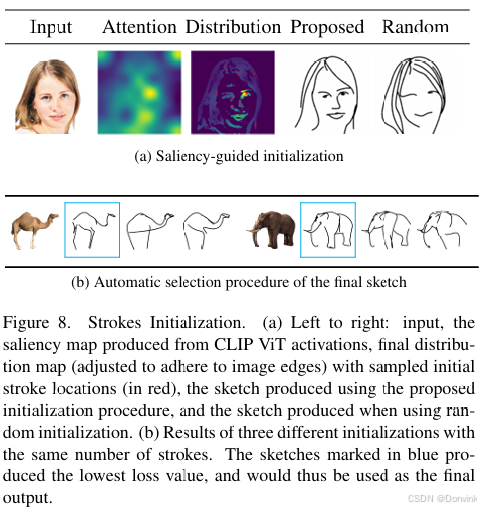
图b是本文的一种后处理操作。CLIPasso对每张图生成三张简笔画,最后计算每张简笔画和原图的loss(Ls + Lg),调出loss最低的一张作为最终结果(蓝色框)。
2.4 训练可视化
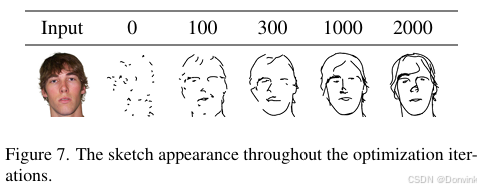
训练一般需要2000次迭代,但一般迭代100次就能看出大概轮廓了。而且作者在附录里说,CLIPasso的训练很快。在一张V100的卡上,用6min就可以完成这2000次迭代。所以在计算资源不足的时候可以试试这种跨界研究。
2.5 局限性
-
输入图片有背景时,生成的效果大打折扣。输入图片必须是一个物体,且在纯白色的背景上,生成的效果才最好。因为只有这样,自注意力图才更准,初始化效果才会好,而有了背景,自注意力就会复杂很多。所以作者是先将图片输入U2Net,从背景中抠出物体,然后再做生成。这样就是两阶段的过程,不是端到端,所以不是最优的结构。如何能融合两个阶段到一个框架,甚至是在设计loss中去除背景的影响,模型适用就更广了。
-
简笔画是同时生成而非序列生成。如果模型能做到像人类作画一样,一笔一画,每次根据前一笔确定下一笔的作画位置,不断优化,生成效果可能更好
-
复杂程度不同物体,需要抽象你的程度不同。CLIPasso控制抽象程度的笔画数必须提前指定,所以最好是将笔画数也设计成可学习的参数。这样对不同的图片上不同复杂程度的物体,都能很好的自动抽象。目前用户每次输入图片,还得考虑用几笔去抽象。