一、什么是eBPF
eBPF, 从它的全称“扩展的伯克利数据包过滤器 (Extended Berkeley Packet Filter)” 来看,它是一种数据包过滤技术,是从 BPF (Berkeley Packet Filter) 技术扩展而来的。BPF 提供了一种在内核事件和用户程序事件发生时安全注入代码的机制,这就让非内核开发人员也可以对内核进行控制。随着内核的发展,BPF 逐步从最初的数据包过滤扩展到了网络、内核、安全、跟踪等,而且它的功能特性还在快速发展中,这种扩展后的 BPF 被简称为 eBPF。实际上,现代内核所运行的都是 eBPF,如果没有特殊说明,内核和开源社区中提到的 BPF 等同于 eBPF。
在 eBPF 之前,内核模块是注入内核的最主要机制。由于缺乏对内核模块的安全控制,内核的基本功能很容易被一个有缺陷的内核模块破坏。而 eBPF 则借助即时编译器(JIT),在内核中运行了一个虚拟机,保证只有被验证安全的 eBPF 指令才会被内核执行。同时,因为 eBPF 指令依然运行在内核中,无需向用户态复制数据,这就大大提高了事件处理的效率。正是由于这些突出的特性,eBPF 现如今已经在故障诊断、网络优化、安全控制、性能监控等领域获得大量应用。
二、eBPF 的发展历程
其实eBPF 是从 BPF (Berkeley Packet Filter) 技术扩展而来的,它的历史十分悠长。
1992 年:BPF 全称 Berkeley Packet Filter,诞生初衷提供一种内核中自定义报文过滤的手段(类汇编),提升抓包效率。(tcpdump)
1997 年:Linux 2.1.75 首次引入BPF技术,将高性能的BSD包过滤机制BPF带入Linux。
2011 年:Linux kernel 3.2 版本对 BPF 进行重大改进,引入 BPF JIT(即时编译器),使其性能得到大幅提升。
2014 年:Linux kernel 3.15 版本,BPF 扩展成 eBPF,其功能范畴扩展至:内核跟踪、性能调优、协议栈 QoS 等方面。与之配套改进包括:扩展 BPF ISA 指令集、提供高级语言(C)编程手段、提供 MAP 机制、提供 Help 机制、引入 Verifier 机制等。
2015 年:BCC(BPF Complier Collection)提供了一系列基于eBPF的工具和库函数,大大简化了eBPF程序的开发和运行。同年的Linux 4.1也开始支持kprobe和cls_bpf(用于tc)。
2016 年:linux kernel 4.8 版本,eBPF 支持 XDP,进一步拓展该技术在网络领域的应用。随后 Netronome 公司提出 eBPF 硬件卸载方案。同时也带来了跟踪点、perf事件和cgroups的支持,丰富了eBPF的事件源。
2017 年:BPF成为内核独立的子模块,并支持了KLTS、bpftool、libbpf等。Netfix、Fackbook、Coundfare等公司开始将eBPF用于跟踪、DDOS防御、4层负载均衡。
2018 年:linux kernel 4.18 版本,引入 BTF,将内核中 BPF 对象(Prog/Map)由字节码转换成统一结构对象,这有利于 eBPF 对象与 Kernel 版本的配套管理,为 eBPF 的发展奠定基础。同时,bpftrace和bpffiler项目也正式发布。
2018 年:从 kernel 4.20 版本开始,eBPF 成为内核最活跃的项目之一,新增特性包括:sysctrl hook、flow dissector、struct_ops、lsm hook、ring buffer 等。场景范围覆盖容器、安全、网络、跟踪等。
2019 年:BPF新增了尾调用和热更新的支持,GCC也开始支持BPF编译。Cilum 1.6发布基于BPF的服务发现代理(完全替换基于iptables的kubeproxy)。
2020 年:Google和Facebook为BPF新增LSM和TCP拥塞控制的支持,主流云厂商开始通过SRIOV支持XDP;微软基于eBPF开始为window监控工具Sysmon增加Linux支持。
2021 年:BPF开始支持内核函数调用,eBPF生态非常活跃;微软发布Window eBPF,并与Facebook、Google、Lsovalent、Netfilx等一起成立eBPF基金会;Cilium发布基于eBPF的Server Mesh(取代代理)。
三、eBPF 是怎么工作的
eBPF 程序并不像常规的线程那样,启动后就一直运行在那里,它需要事件触发后才会执行。这些事件包括系统调用、内核跟踪点、内核函数和用户态函数的调用退出、网络事件,等等。借助于强大的内核态插桩(kprobe)和用户态插桩(uprobe),eBPF 程序几乎可以在内核和应用的任意位置进行插桩。
看到这个令人惊叹的能力,你一定有疑问:这会不会像内核模块一样,一个异常的 eBPF 程序就会损坏整个内核的稳定性呢?其实,确保安全和稳定一直都是 eBPF 的首要任务,不安全的 eBPF 程序根本就不会提交到内核虚拟机中执行。
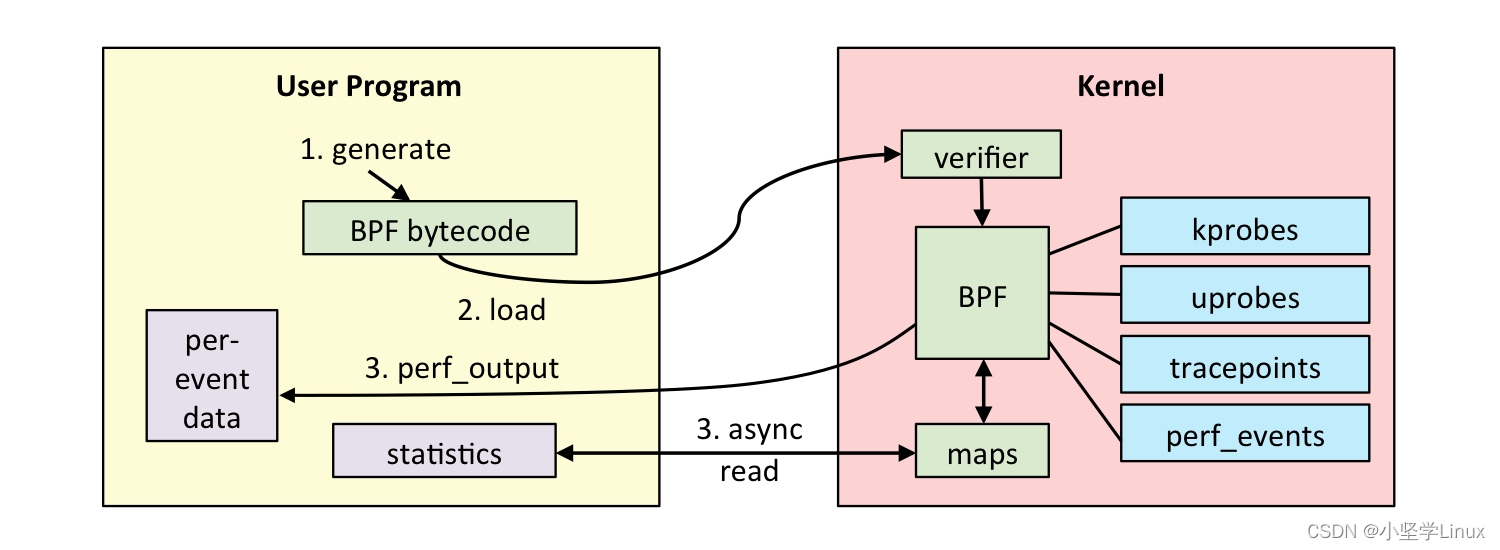
如下图所示,通常我们借助 LLVM 把编写的 eBPF 程序转换为 BPF 字节码,然后再通过 bpf 系统调用提交给内核执行。内核在接受 BPF 字节码之前,会首先通过验证器对字节码进行校验,只有校验通过的 BPF 字节码才会提交到即时编译器执行。
如果 BPF 字节码中包含了不安全的操作,验证器会直接拒绝 BPF 程序的执行。比如,下面就是一些典型的验证过程:
- 只有特权进程才可以执行 bpf 系统调用;
- BPF 程序不能包含无限循环;
- BPF 程序不能导致内核崩溃;
- BPF程序必须在有限时间内完成。
eBPF 程序以内核事件触发的方式运行,并且其运行过程包括编译、加载、验证和内核态执行等。为了保护内核的安全和稳定,如果编译后 BPF 字节码中包含了不安全的操作,验证阶段会直接拒绝 BPF 程序的执行。
四、eBPF的使用环境搭建
虽然 Linux 内核很早就已经支持了 eBPF,但很多新特性都是在 4.x 版本中逐步增加的。所以,想要稳定运行 eBPF 程序,内核至少需要 4.9 或者更新的版本,但是这里推荐使用5以上版本的linux内核。
然后就是安装开发工具:
sudo apt-get install -y make clang llvm libelf-dev libbpf-dev bpfcc-tools libbpfcc-dev linux-tools-$(uname -r) linux-headers-$(uname -r)
linux-tools-$(uname -r)-generic linux-cloud-tools-$(uname -r)-generic
编译内核BTF失败:
sudo apt install dwarves
ubuntu 20.04环境搭建
sudo apt install -y bison build-essential cmake flex git libedit-dev pkg-config libmnl-dev python zlib1g-dev libssl-dev libelf-dev libcap-dev libfl-dev llvm clang pkg-config gcc-multilib luajit libluajit-5.1-dev libncurses5-dev libclang-dev clang-tools
五、eBPF程序开发流程
我们先来看一下eBPF程序的开发和执行过程。一般来说,这个过程分为以下 5 步:
- 使用 C 语言开发一个 eBPF 程序;
- 借助 LLVM 把 eBPF 程序编译成 BPF 字节码;
- 通过 bpf 系统调用,把 BPF 字节码提交给内核;
- 内核验证并运行 BPF 字节码,并把相应的状态保存到 BPF 映射中;
- 用户程序通过 BPF 映射查询 BPF 字节码的运行状态。
六、eBPF程序开发方式
我们需要全方位掌握 eBPF 程序的开发过程,就要学会三种一般eBPF 程序的开发方式:bpftrace、BCC 和 libbpf 这三种方式。这三种方式各有优缺点,在实际的生产环境中都有大量的应用:
- bpftrace 通常用在快速排查和定位系统上,它支持用单行脚本的方式来快速开发并执行一个 eBPF 程序。不过,bpftrace
的功能有限,不支持特别复杂的 eBPF 程序,也依赖于 BCC 和 LLVM 动态编译执行。 - BCC 通常用在开发复杂的 eBPF 程序中,其内置的各种小工具也是目前应用最为广泛的 eBPF 小程序。不过,BCC
也不是完美的,它依赖于 LLVM 和内核头文件才可以动态编译和加载 eBPF 程序。 - libbpf 是从内核中抽离出来的标准库,用它开发的 eBPF 程序可以直接分发执行,这样就不需要每台机器都安装 LLVM
和内核头文件了。不过,它要求内核开启 BTF 特性,需要非常新的发行版才会默认开启。
在实际应用中,你可以根据你的内核版本、内核配置、eBPF 程序复杂度,以及是否允许安装内核头文件和 LLVM 等编译工具等,来选择最合适的方案。