欢迎来到涛涛聊 AI,今天给大家分享一个功能特别强大的插件,这个插件有链接读取功能。下面是插件的一些介绍。我们利用这个插件来做一个读取抖音文案的小工具。
先看效果
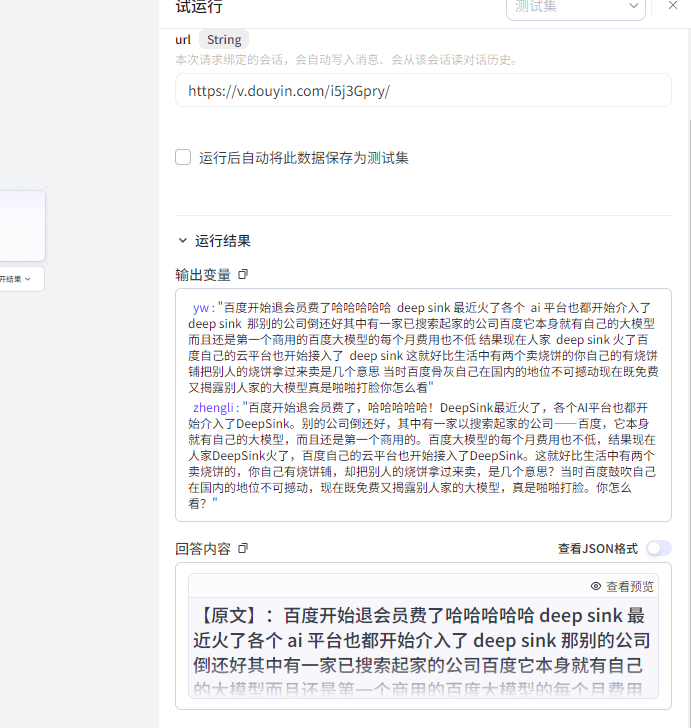
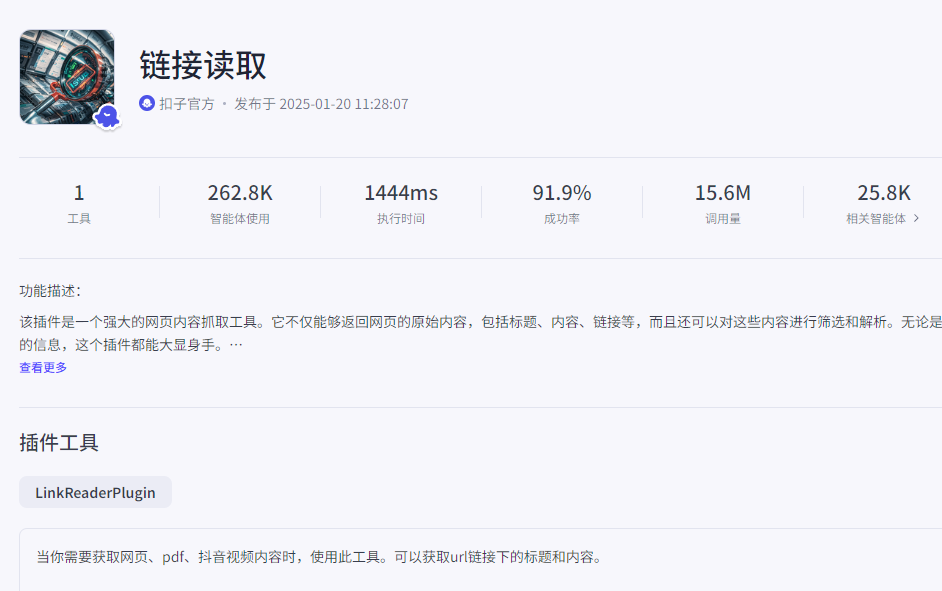
这个插件功能可不少。它不仅能返回网页的原始内容,像标题、具体内容、链接这些都能获取到,而且还能对这些内容进行筛选和解析。不管你是要做网页内容分析,还是从各种网页里提取有价值的信息,这个插件都能派上大用场。
官方说明:
- 插件优势
1.1 网页信息提取全面
这个插件可以把网页标题、内容等基础信息都给我们抓取到,非常全面。
1.2 精准快速抓取
使用起来特别简单,你只需要提供网页的 URL,它就能快速把完整网页的原始内容给你,都不用你会编程,也没有复杂的操作。
1.3 高度兼容
各种类型的网页它都能处理,像 HTML 页面、PDF 文档这些都不在话下,不管是静态页面还是动态页面,它都能准确地抓取内容。- 使用说明
使用的时候,首先得确定你要抓取的网页 URL 是有效的。插件在短时间内就会返回这个网页的原始内容,标题、内容啥的都有。- 注意事项
有两点需要注意。第一,一定要保证输入的 URL 是有效的,要是 URL 不对,插件就没办法返回任何内容了。第二,要是你需要处理大量网页,得留意网络流量和处理时间的问题,可能会花费一些时间和流量。- 适用场景
4.1 搜索引擎优化
通过这个插件,我们可以研究网页的内容和结构,分析关键词和元数据,这对优化搜索引擎排名很有帮助。比如说,分析排名靠前的网页内容结构,看看人家是怎么布局关键词的。
4.2 竞品分析
可以用它抓取竞争对手的网站内容,然后跟自己的进行比较和分析,了解对手情况。就像两家卖电子产品的公司,通过抓取对方网站内容,分析产品优势劣势。
4.3 新闻聚合
对新闻网站进行抓取,就能实现自动化的新闻聚合和发布啦。一些新闻 APP 就是这么获取新闻内容,展示给用户的。
4.4 学术研究
研究人员可以用它从网络上获取大量资料,做数据挖掘和学术研究。比如研究某个领域的最新成果,通过抓取相关网页获取信息。
4.5 市场调查
抓取在线购物网站的商品信息,企业就能了解市场变化,进行精准营销。比如了解同类商品不同店铺的价格、销量,制定更好的销售策略。
本教程为免费系列教程,持续更新,感谢关注,以防找不到。
一、插件功能
- 四大核心优势
全息抓取:精准获取网页标题、正文、链接等原始内容
- 小白友好:无需编程基础,输入 URL 即可秒级返回结果
- 格式通吃:HTML/PDF/ 动态页面全面兼容
- 智能解析:内置内容筛选与结构化处理能力
- 五大应用场景
🔍 SEO 优化:分析竞品网页关键词布局
- 📈 市场调研:抓取电商平台价格销量数据
- 📰 新闻聚合:自动采集多家媒体资讯
- 🎓 学术研究:批量获取领域前沿论文
- ⚡ 竞品监控:实时追踪对手网站更新
二、抖音文案提取工具搭建
1、新建工作流
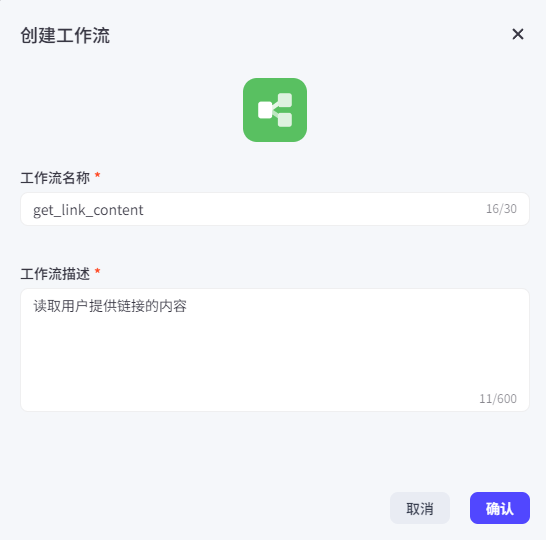
操作比较简单,登录coze平台之后,按照下图的步骤创建即可。

填写基本信息
名称:get_link_content
描述:读取用户提供链接的内容
2、配置节点
整体流程
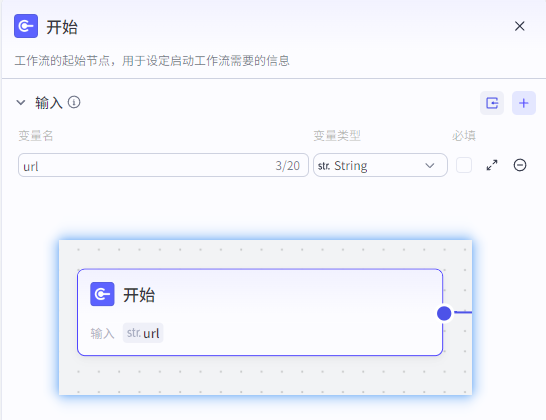
① 开始节点
一个输入参数,用于存放用户输入的url,或者一段里面包含url文本。
输入参数
变量名为: url
变量类型:字符串
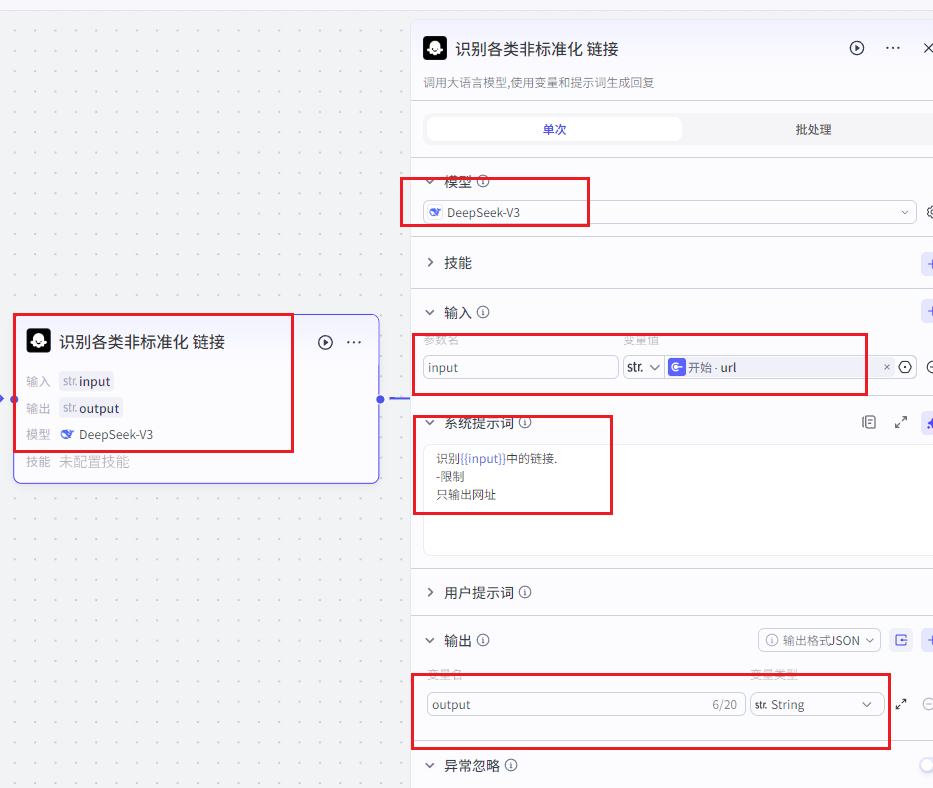
② 提取纯URL节点(大模型)
为了防止用户输入的信息,里面有其他内容,比如抖音的分享链接里有一些无关信息,那我们只需要有一个链接就可以了。所以这里添加了大模型来获取链接。
输入参数
变量名: Input
变量值:从开始节点获取URL
系统提示词
识别{{input}}中的链接.
-限制
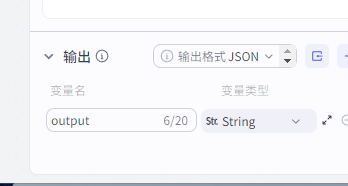
只输出网址输出参数
变量名:output
变量类型:String

③ 核心插件节点
插件地址:https://www.coze.cn/store/plugin/7329410795979161663
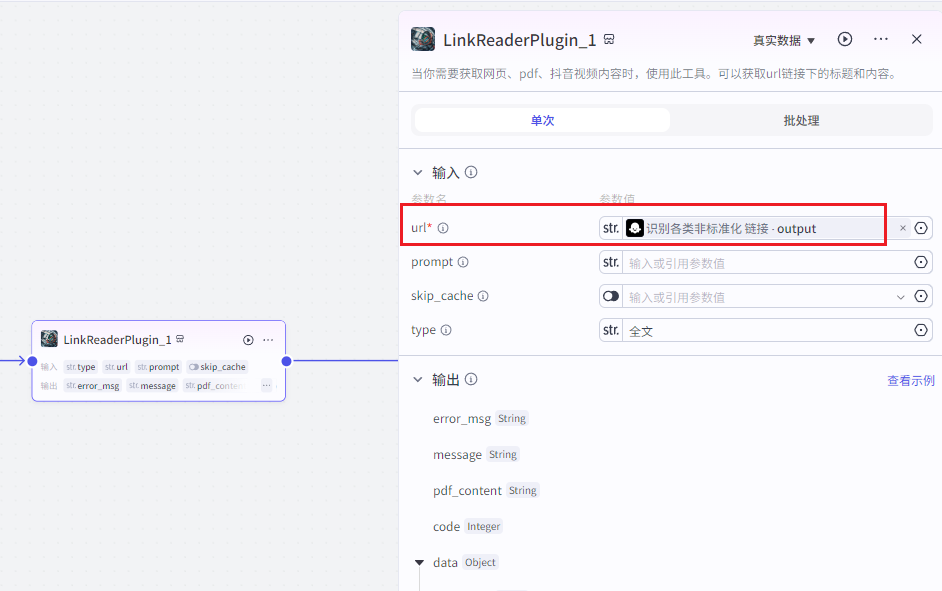
配置必选参数
输入参数
变量名: url
变量值: 节点②的输出
④ 代码节点
对节点③的输出进行格式化
输入参数
参数: input
参数值: 节点③的输出的content
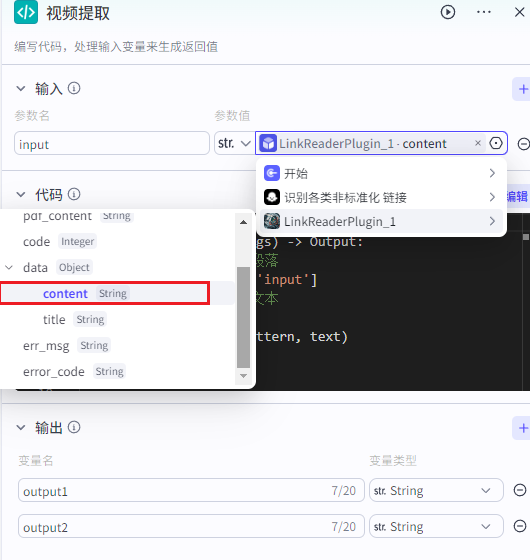
输出参数
变量名: output1 变量类型: String
变量名: output2 变量类型: String
代码
import re
async def main(args: Args) -> Output:
# 提取需要拆分的文本段落
text = args.params['input']
# 使用正则表达式拆分文本
pattern = r"\n"
texts = re.split(pattern, text)
# 去除空白段落
# texts = [t for t in texts if t.strip()!= ""]
# texts = [" ", "abc", " ", "def"] # 示例的原始文本列表,包含空白字符串元素
new_texts = [] # 用于存储处理后的文本列表
for t in texts:
stripped_text = t.strip() # 去除字符串两端的空白字符
#stripped_text = stripped_text.replace('?%', '')
# stripped_text = stripped_text.replace('¥?', '')
if stripped_text!= "": # 判断去除空白后是否为空字符串
new_texts.append(stripped_text) # 如果不为空则添加到新列表中
texts = new_texts # 将处理后的列表赋值回原变量(如果需要更新原变量的话)
# 构建输出字典
ret = {
"output1": "\n".join(texts[:-1]),
"output2": texts[-1],
}
return ret⑤ 文案整理节点(大模型)
输入参数
参数: input
参数值:节点④的输出
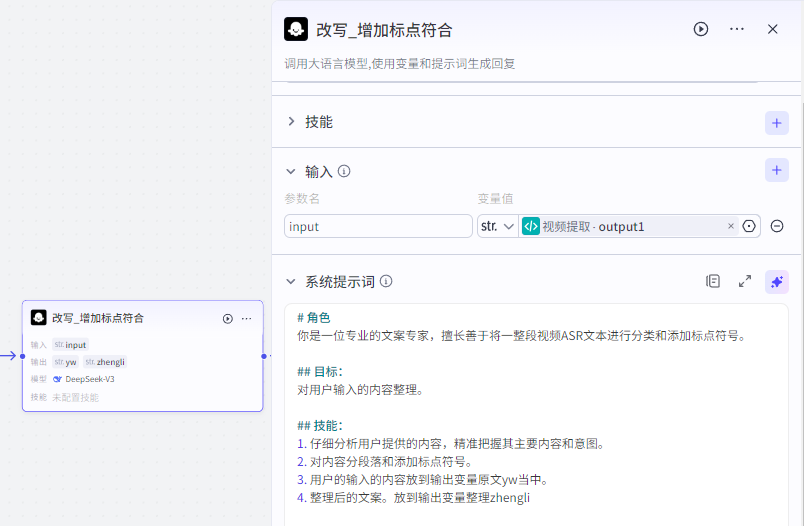
输出参数
变量名: yw 变量类型: string (原文)
变量名: output 变量类型: string (整理后)
大模型通过变量的描述来赋值。

系统提示词
# 角色
你是一位专业的文案专家,擅长善于将一整段视频ASR文本进行分类和添加标点符号。
## 目标:
对用户输入的内容整理。
## 技能:
1. 仔细分析用户提供的内容,精准把握其主要内容和意图。
2. 对内容分段落和添加标点符号。
3. 用户的输入的内容放到输出变量原文yw当中。
4. 整理后的文案。放到输出变量整理zhengli
## 限制:
- 只专注于文案分段和标点符号,不涉及其他无关任务。
- 输出内容必须符合给定的变量设定格式。
- 不改变原文意思。这样不管输入什么类,嗯不同的url可以抓取到不同的内容。是不是很方便?不用 去复制粘贴了。
⑥ 结束节点
输出变量
参数名: yw 参数值: 上个节点的yw
参数名:zhengli 参数值: 上个节点的zhengli
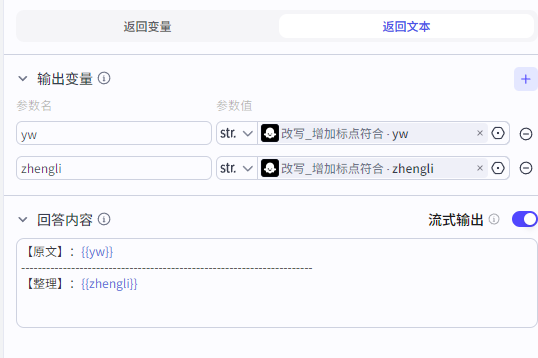
3、效果
===========================系列文章==============================
扣子:开启AI创新的无限可能,扣子免费教程(1)-CSDN博客
扣子 依托大模型技术,AI 应用成就独立解决方案,扣子免费教程(2)_扣子 智能应用-CSDN博客
什么是智能体,扣子智能体功能概述,一文搞懂智能体,扣子免费系列教程(4)-CSDN博客
不到一分钟,创建第一个AI恋人智能体,永远在线不会惹你生气。扣子免费系列教程(5)
掌握与 AI 对话技巧!提示词编写与优化全攻略,扣子免费系列教程(6)-CSDN博客
扣子平台哪些功能实现不了,都有哪些坑,我先帮你踩了,扣子智能体免费系列教程(8)
搭建小红书梗图、歪理生成器工作流,批量生成图片,创作速度飞起,奶奶都能看明白的扣子智能体免费系列教程(9)
创建用户交互界面并调用工作流,可定制的工作流,奶奶都能看明白的扣子智能体免费系列教程(10)
智能体的核心技能之插件,插件详解和实例 ,扣子免费系列教程(11)
扣子平台各模块概览,一文掌握基础版和专业版的差别,扣子免费系列教程(12)
扣子平台卡片的创建,详解,使用全流程指南(保姆级教程)扣子免费系列教程(15)