MixFormer: End-to-End Tracking with Iterative Mixed Attention
Paper:https://arxiv.org/abs/2203.11082
Code:https://github.com/MCG-NJU/MixFormer
1.文章动机
目前的跟踪器大多都是有三部分组成,其中包括了特征提取模块(backbone),特征融合模块(integration module),目标估计模块(predicted head)。为了简化跟踪流程,该文提出了一个紧凑的跟踪框架,称为MixFormer。该框架仅由两部分组成,一个是基于目标-搜索区域混合注意的骨干网络,另一个就是一个简单的定位网络。
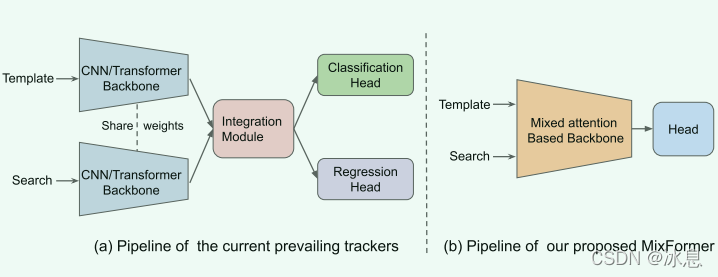
2.方法
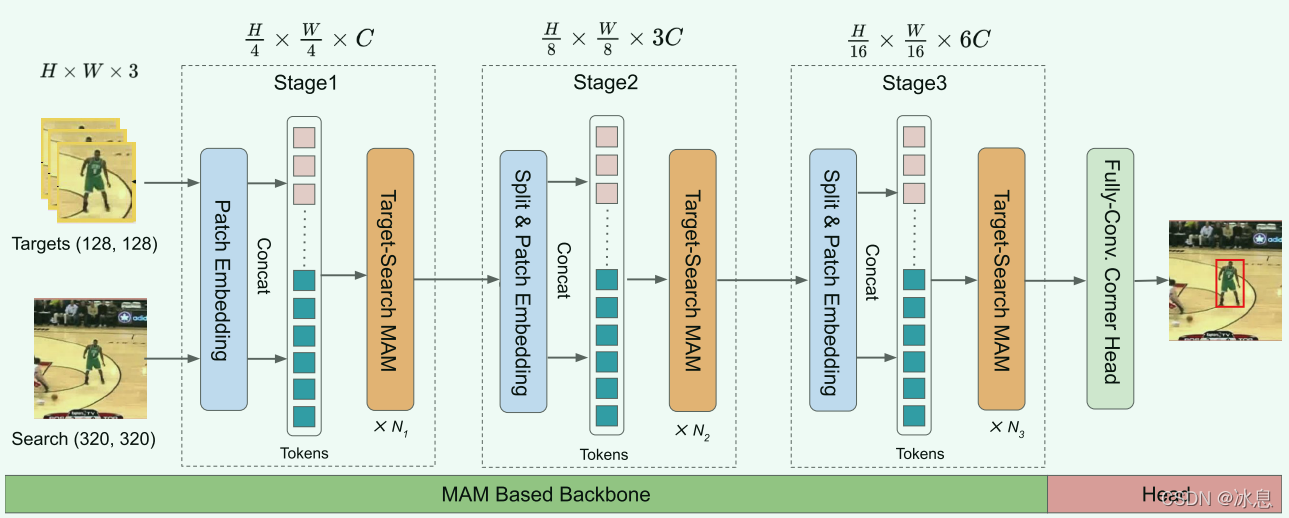
2.1 Mixed Attention Module
提出了一个Mixed Attention Module(MAM),用来统一特征提取过程和目标与搜索区域特征融合的过程。这种方案使得特征提取更加具体到相应的跟踪目标。此外,更好的执行目标信息集成,从而更好地捕捉目标和搜索区域之间的相关性。
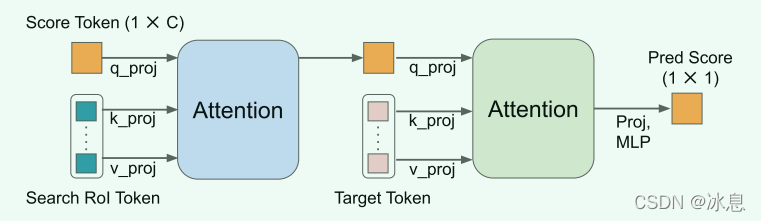
2.2. Score Prediction Module
在线的模板可以捕获时间信息和处理对象变形和外观变化。SPM 由两个注意力块和一个三层感知器组成。 首先,可学习的分数标记用作查询以参与搜索 ROI 标记。 它使分数token能够对挖掘的目标信息进行编码。 接下来,分数token关注初始目标token的所有位置,以隐式地将挖掘的目标与第一个目标进行比较。 最后,分数由 MLP 层和 sigmoid 激活产生。 在线模板在其预测分数低于 0.5 时被视为负样本。
3.实验
3.1. 模型结构
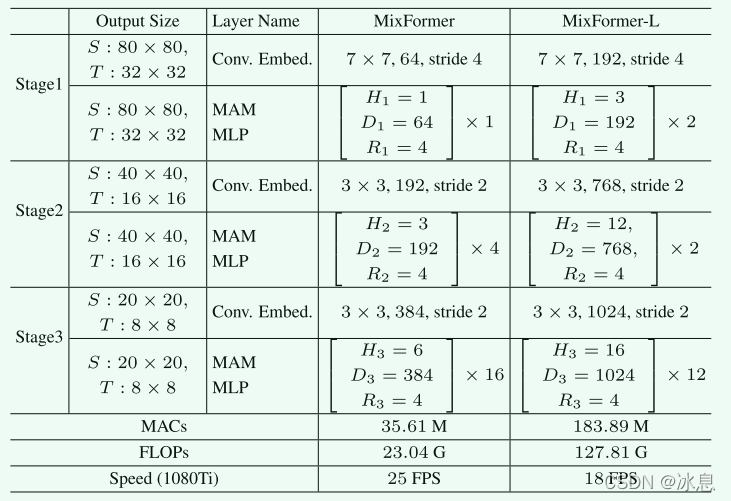
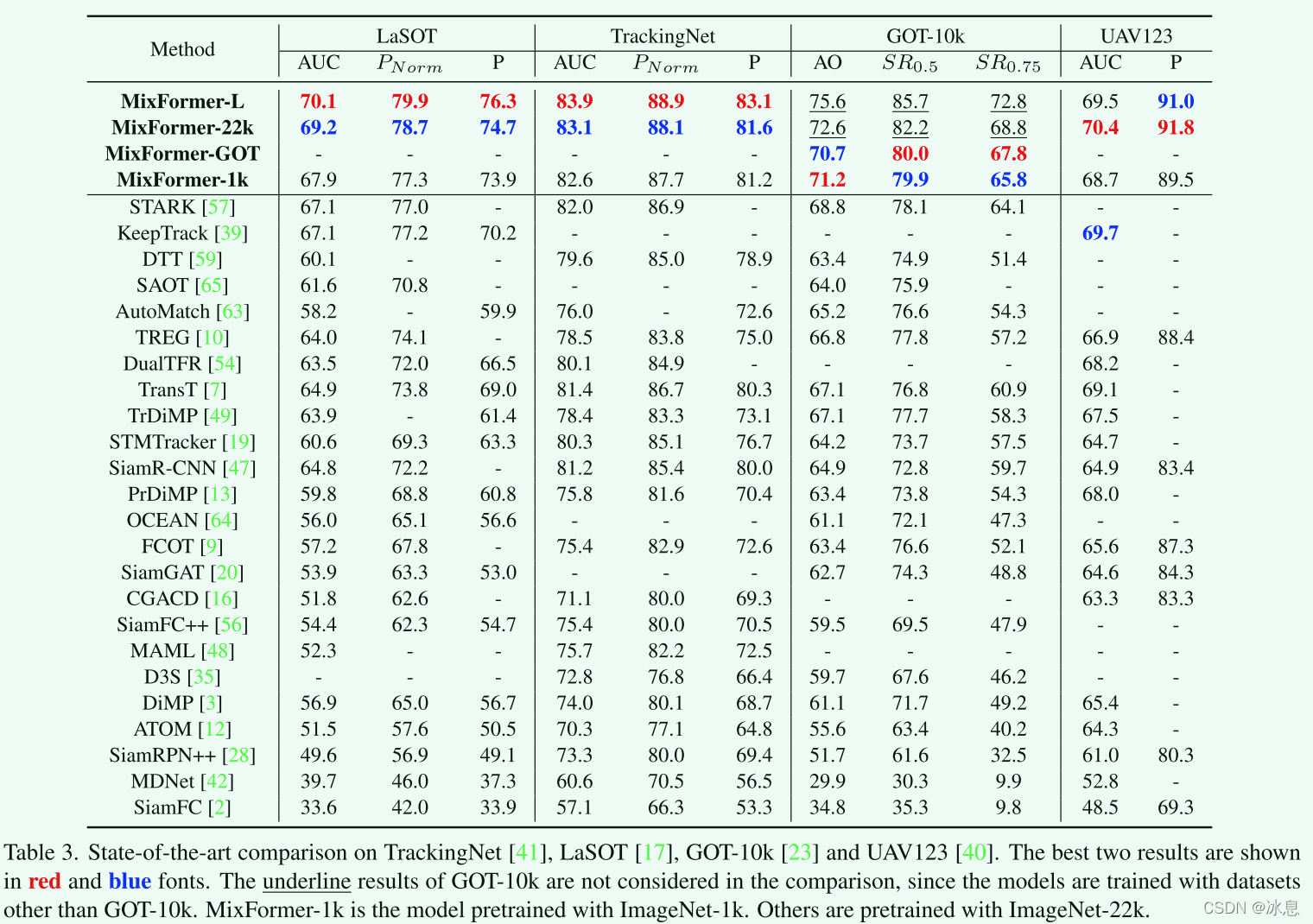
3.2 Sota对比

5.结论
就今年的CVPR现有的文章来说,感觉现在的目标跟踪都是在不停的做大模型,真正对于目标跟踪任务中的来说,挖掘的却不够深刻。但就其性能来说,确实是提升了很多,也是一篇很优秀的工作,给大家提供了模型构建的新方向。对于论文中在线模板的内容,和2021年CVPR中的STMTrack中的比较相似。个人认为这种基于多模板的方法会在未来的目标跟踪领域成为一个热点,毕竟第一帧中的目标以及场景信息是有限的,挖掘跟踪过程中的信息对于提升跟踪器性能来说十分重要。以上结论都是基于我目前的认知来说的,如有不妥敬请谅解。同时也希望和有相同研究方向的小伙伴一起讨论。