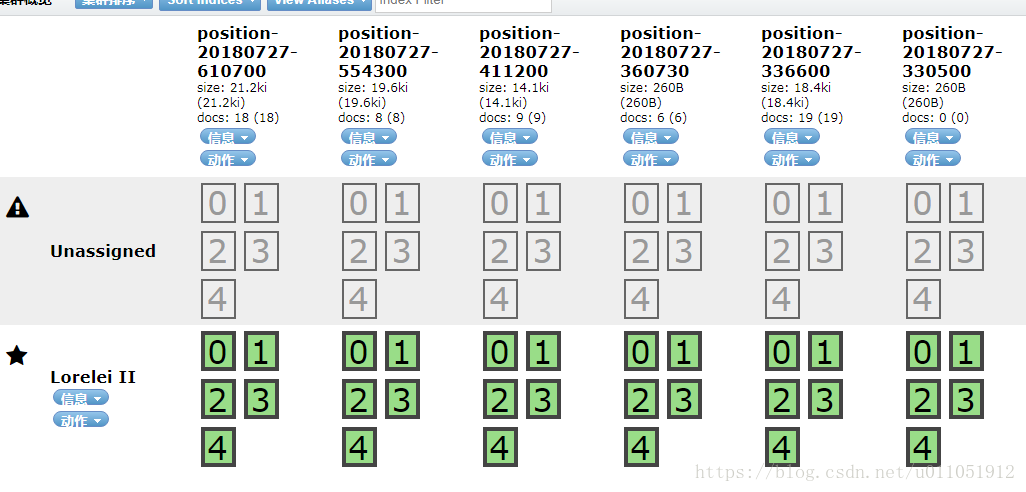
Rabbitmq中的数据通过logstash保存到ElasticSearch中,有以下几步即可完成
首先,保证Rabbitmq,ElasticSearch安装并且可以使用,logstash可用。具体安装过程在本文不做说明,不会的同学可以自行查找资料。
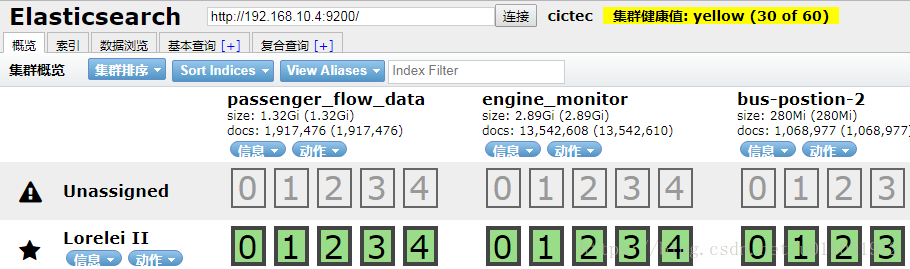
如图所示,我的ElasticSearch和Rabbitmq已经正常可以使用。
接下来就是配置logstash并且启动使用:
input{
rabbitmq{
host=>"ip" # 这里填写Rabbitmq的地址,确保可以ping通
port=> 5672 # 这里填写Rabbitmq的端口
user=>"guest" # 这里填写Rabbitmq的用户名
password=>"guest" # 这里填写Rabbitmq的密码
queue=>"queuename" # 这里填写Rabbitmq的队列的名称
durable=> true # 这里填写Rabbitmq的队列的durable属性
codec=>json # 这里填写Rabbitmq的队列的内容是什么格式
type=> "result" # 这里选填
}
}
filter{
if([messageType] not in "2,3"){ # 过滤条件,可以不要
drop{}
}
}
output {
elasticsearch {
hosts => ["192.168.10.4:9200"] # ElasticSearch的地址加端口
index => "position-%{+YYYYMMdd}" # ElasticSearch的保存文档的index名称,
document_type=>"%{messageType}" # ElasticSearch的保存文档的type
document_id=>"%{mark_uuid}" # ElasticSearch的保存文档的id
flush_size => 500 # ElasticSearch的保存文档的多少条提交保存
idle_flush_time => 10 # ElasticSearch的保存文档的多少秒提交保存
}
}
最后一步就是生效刚刚的配置并且生效:
bin/logstash -f rabbitmq.conf
rabbitmq.conf 就是我刚刚配置的文件,文件名随便命名。然后如果队列里有数据了,ElasticSearch中就有数据保存了。效果图: