一 RocketMQ的工作流程
1.1 生产环节producer
Producer可以将消息写入到某Broker中的某Queue中:其中Producer发送消息之前,会先向NameServer发出获取消息Topic的路由信息的请求,NameServer返回该Topic的路由表及Broker列表。简单的说:路由表的key为Topic名称,value则为所有涉及该Topic的BrokerName列表。
1.2 MQ的存储
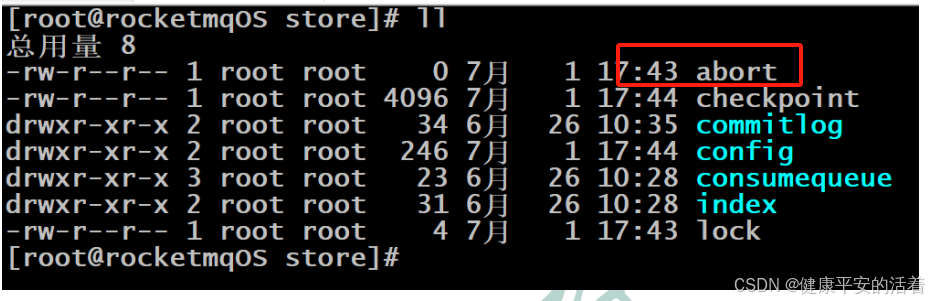
RocketMQ中的消息存储在本地文件系统中,这些相关文件默认在当前用户主目录下的store目录中。
abort:该文件在Broker启动后会自动创建,正常关闭Broker,该文件会自动消失。若在没有启动Broker的情况下,发现这个文件是存在的,则说明之前Broker的关闭是非正常关闭。
1.2.1 mq的commitlog
commitlog目录中存放着很多的mappedFile文件,当前Broker中的所有消息都是落盘到这些mappedFile文件中的。需要注意的是,一个Broker中仅包含一个commitlog目录,所有的mappedFile文件都是存放在该目录中的。
mappedFile文件是顺序读写的文件,所有其访问效率很高。
1.2.2 mq的consumequeue
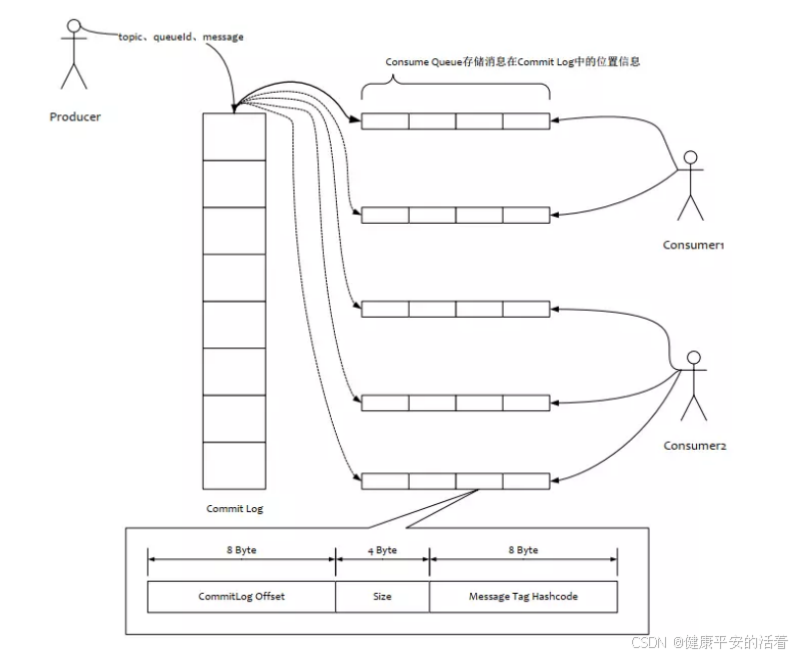
consumequeue文件是commitlog的索引文件,可以根据consumequeue定位到具体的消息,consumequeue文件名也由20位数字构成,表示当前文件的第一个索引条目的起始位移偏移量

1.2.3 mq的存储读写流程
1.3 rocketmq与kafka性能比较*
首先,RocketMQ对文件的读写操作是通过mmap零拷贝进行的,将对文件的操作转化为直接对内存地址进行操作,从而极大地提高了文件的读写效率。
其次,consumequeue中的数据是顺序存放的,还引入了PageCache的预读取机制,使得对consumequeue文件的读取几乎接近于内存读取,即使在有消息堆积情况下也不会影响性能。
RocketMQ中的commitlog目录与consumequeue的结合就类似于Kafka中的partition分区目录。 mappedFile文件就类似于Kafka中的segment段。
Kafka中消息存放的目录结构是:topic目录下有partition目录,partition目录下有segment文件。
Kafka中无需索引文件。因为生产者是将消息直接写在了partition中的,消费者也是直接从partition中读取数据的。
1.4 rocketmq的消费方式
消费者从Broker中获取消息的方式有两种:pull拉取方式和push推动方式。消费者组对于消息消费的模式又分为两种:集群消费Clustering和广播消费Broadcasting。
Pull拉取方式:
由于拉取时间间隔是由用户指定的,主动权自己掌控。所以在设置该间隔时需要注意平稳:间隔太短,空请求比例会增加;间隔太长,消息的实时性太差
Push方式:
该模式下Broker收到数据后会主动推送给Consumer。该获取方式一般实时性较高。而这些都是基于Consumer与Broker间的长连接的。长连接的维护是需要消耗系统资源的。
集群消费模式下,相同Consumer Group的每个Consumer实例平均分摊同一个Topic的消息。即每条消息只会被发送到Consumer Group中的某个Consumer。
1.5 rocketmq的rebalance
1.5.1 mq的rebalance概述
Rebalance即再均衡,指的是,将⼀个Topic下的多个Queue在同⼀个Consumer Group中的多个Consumer间进行重新分配的过程。
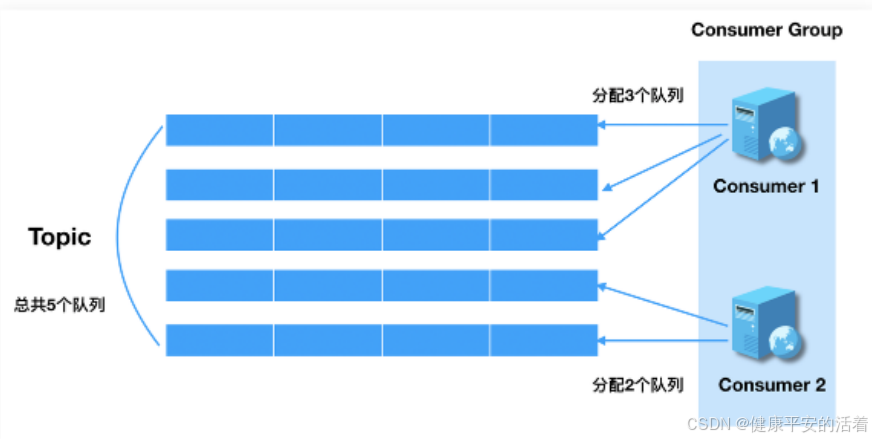
Rebalance机制的本意是为了提升消息的并行消费能力。例如,⼀个Topic下5个队列,在只有1个消费者的情况下,这个消费者将负责消费这5个队列的消息。如果此时我们增加⼀个消费者,那么就可以给。其中⼀个消费者分配2个队列,给另⼀个分配3个队列,从而提升消息的并行消费能力。
1.5.2 发生rebalance的条件
消费者所订阅Topic的Queue数量发生变化,或消费者组中消费者数量发生变化。Kafka中的Rebalance是由Consumer Leader完成的。而RocketMQ中的Rebalance是由每个Consume 自身完成的,Group中不存在Leader。
1.6 Rocketmq的消费策略
一个Topic中的Queue只能由Consumer Group中的一个Consumer进行消费,而一个Consumer可以同时消费多个Queue中的消息。那么Queue与Consumer间的配对关系是如何确定的,即Queue要分配给哪个Consumer进行消费?
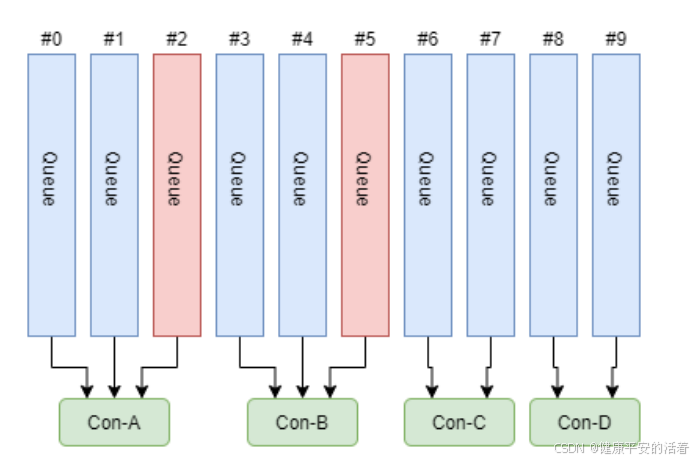
1.平均分配策略
思想:该算法是要根据avg = Qu eueCount / ConsumerCount 的计算结果进行分配的。如果能够整除,则按顺序将avg个Queue逐个分配Consumer;如果不能整除,则将多余出的Queue按照Consumer顺序逐个分配。
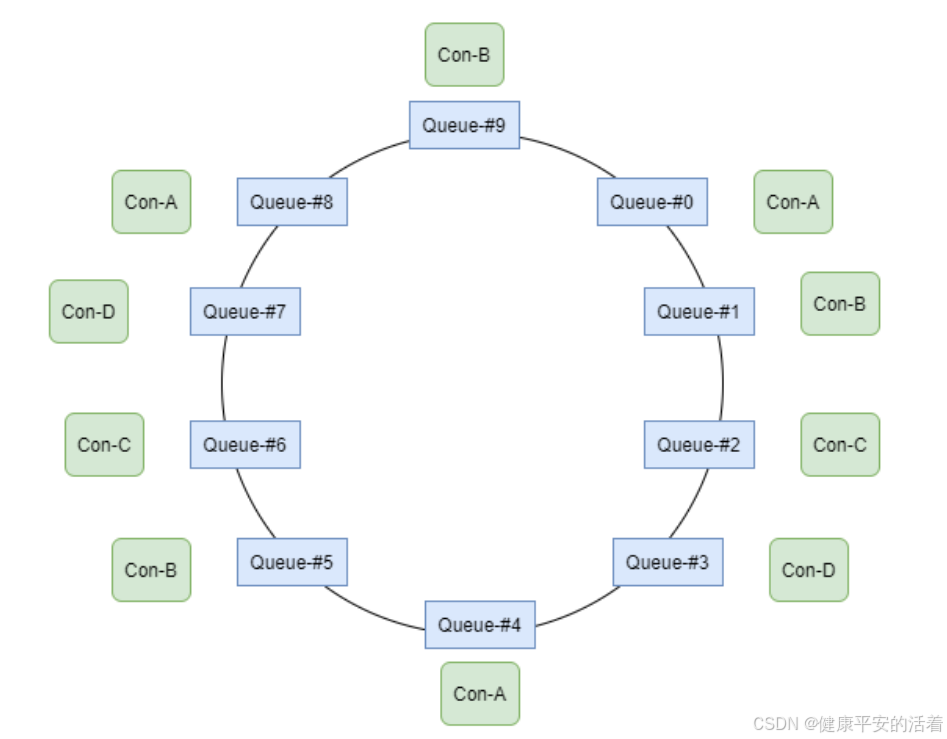
2.环形平均策略
思想:环形平均算法是指,根据消费者的顺序,依次在由queue队列组成的环形图中逐个分配
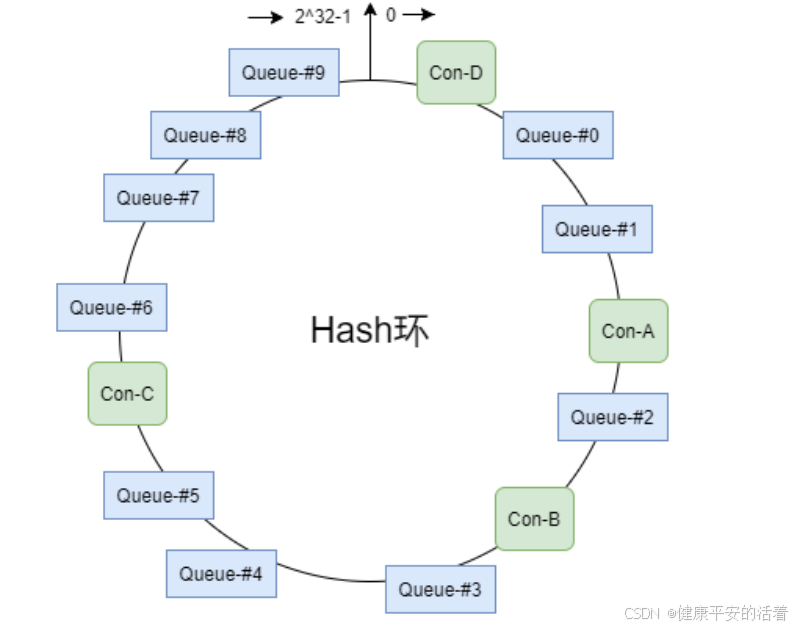
3.一致性hash策略
思想:该算法会将consumer的hash值作为Node节点存放到hash环上,然后将queue的hash值也放到hash环上,通过顺时针方向,距离queue最近的那个consumer就是该queue要分配的consumer。
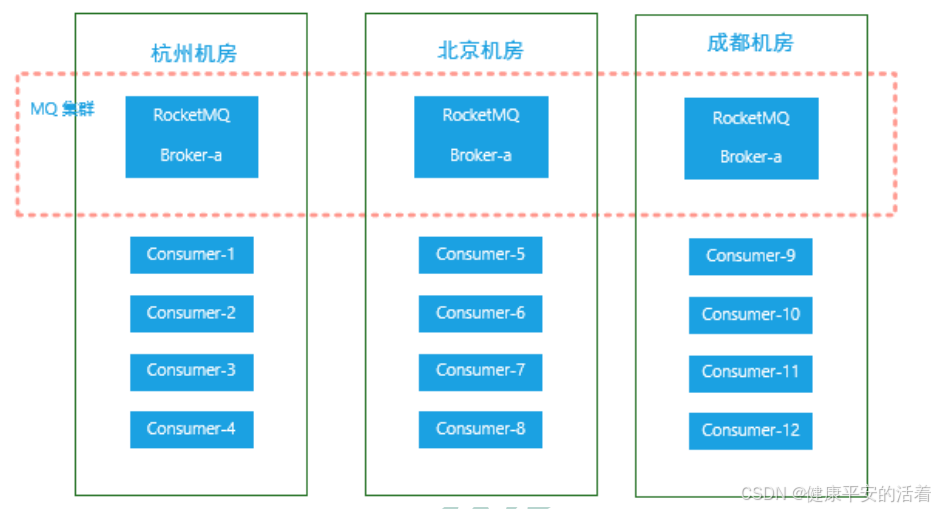
4.同机房策略
5.至少一次原则
每条消息必须要被成功消费一次。
1.7 订阅一致性
订阅关系的一致性指的是,同一个消费者组(Group ID相同)下所有Consumer实例所订阅的Topic与 Tag,以及对消息的处理逻辑必须完全一致。
正确:
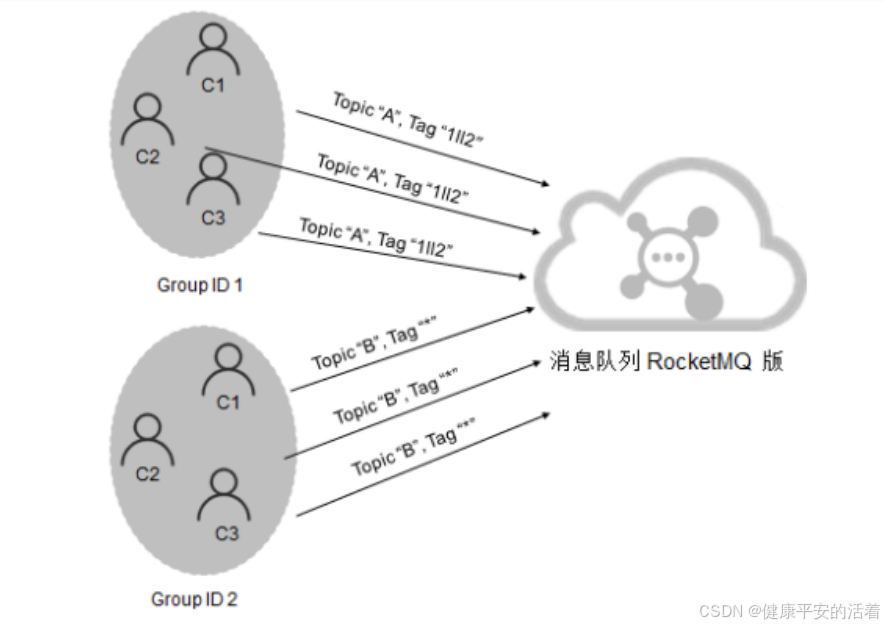
错误:该例中的错误在于,同一个消费者组中的两个Consumer实例订阅了不同的Topic。 同一个消费组的消费者必须消费同一个topic。
1.8 消费的幂等性*
幂等:若某操作执行多次与执行一次对系统产生的影响是相同的,则称该操作是幂等的。
RocketMQ能够保证消息不丢失,但不能保证消息不重复。
解决思路:使用幂等令牌,与唯一性处理。利用这两要素,设计出幂等解决方案。
幂等令牌:生产者和消费者约定协议,双方使用具有唯一标识的字符串。如订单号、流水号。一般由Producer随着消息一同发送来的。
唯一性处理:服务端通过采用⼀定的算法策略,保证同⼀个业务逻辑不会被重复执行成功多次。例如,对同一笔订单的多次支付操作,只会成功一次。
案例:
1. 当支付请求到达后,首先在Redis缓存中却获取key为支付流水号的缓存value。若value不空,则说明本次支付是重复操作,业务系统直接返回调用侧重复支付标识;若value为空,则进入下一步操作
2. 到DBMS中根据支付流水号查询是否存在相应实例。若存在,则说明本次支付是重复操作,业务系统直接返回调用侧重复支付标识;若不存在,则说明本次操作是首次操作,进入下一步完成唯一性处理
3. 在分布式事务中完成三项操作:
完成支付任务
将当前支付流水号作为key,任意字符串作为value,通过set(key, value, expireTime)将数据写入到Redis缓存
将当前支付流水号作为主键,与其它相关数据共同写入到DBMS
1.9 消息的堆积*
消息堆积的主要瓶颈在于客户端的消费能力,而消费能力由消费耗时和消费并发度决定。注意,消费耗时的优先级要高于消费并发度。即在保证了消费耗时的合理性前提下,再考虑消费并发度问题。
对于普通消息、延时消息及事务消息,并发度计算都是 单节点线程数*节点数量。但对于顺序消息则是不同的。顺序消息的消费并发度等于 Topic的Queue分区数量。
消息是被顺序存储在commitlog文件的,且消息大小不定长,所以消息的清理是不可能以消息为单位进。commitlog文件存在一个过期时间,默认为72小时,即三天。
1.10 提高消费的吞吐量*
生产端:使用批量发送消息,减少网络IO次数。
Broker端:增加Topic的分区数,这样可以并行处理消息。
消费端:增加消费者组内的消费者实例数,可以提高消费能力。
调整消费者的消费模式,例如采用批量消费或者顺序消费。