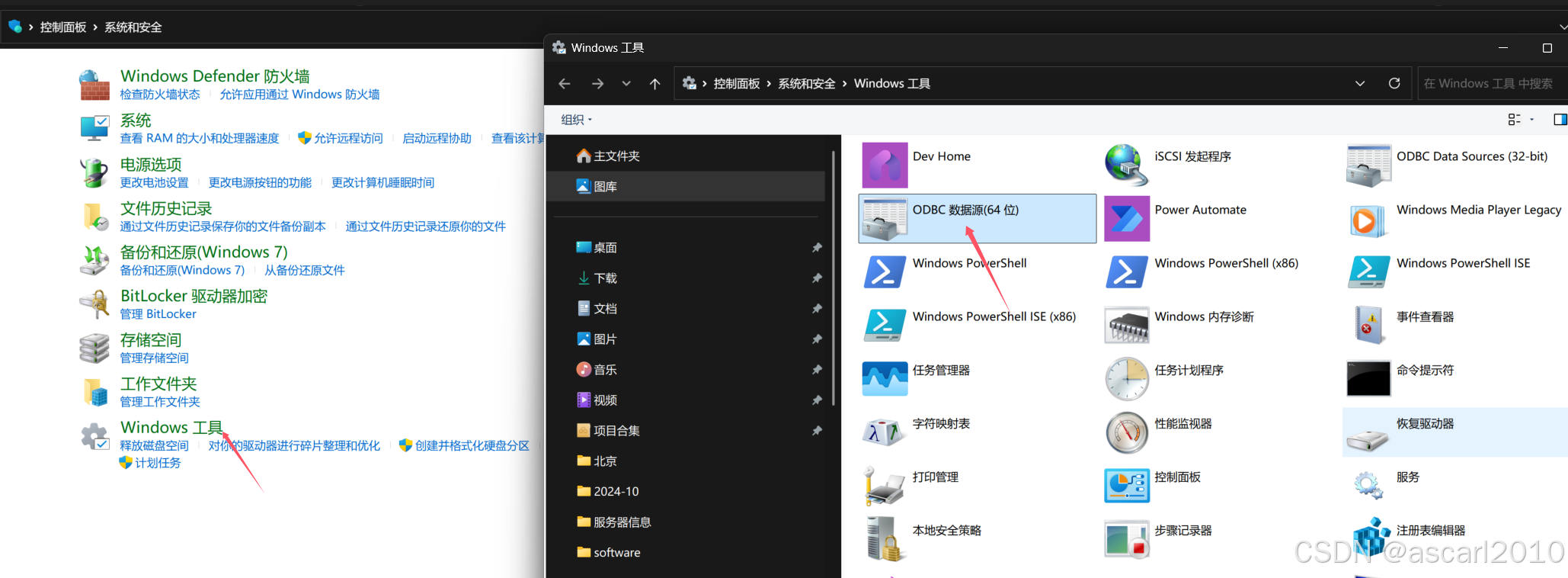
1.首先配置数据源
控制面板\系统和安全\Windows 工具
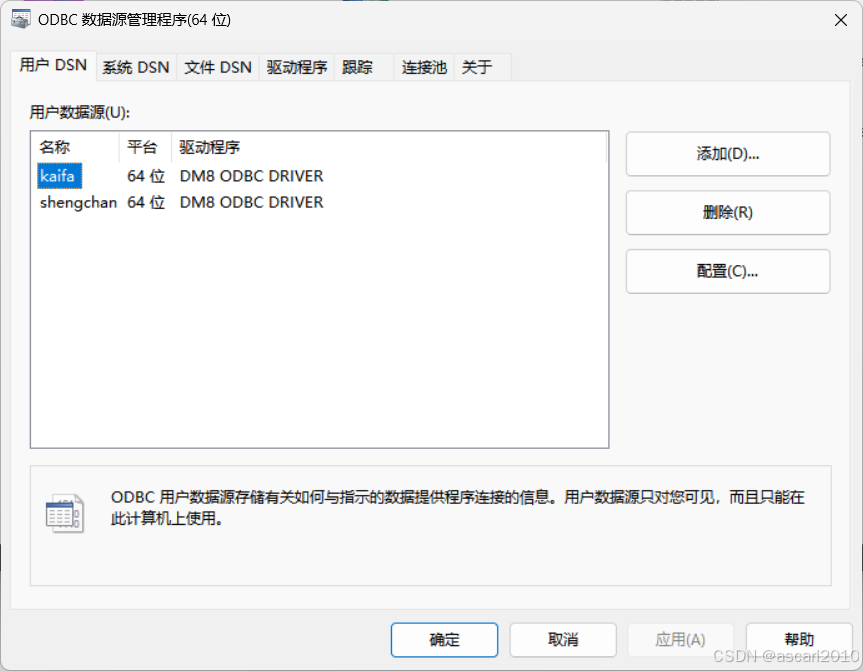
添加相应的数据源
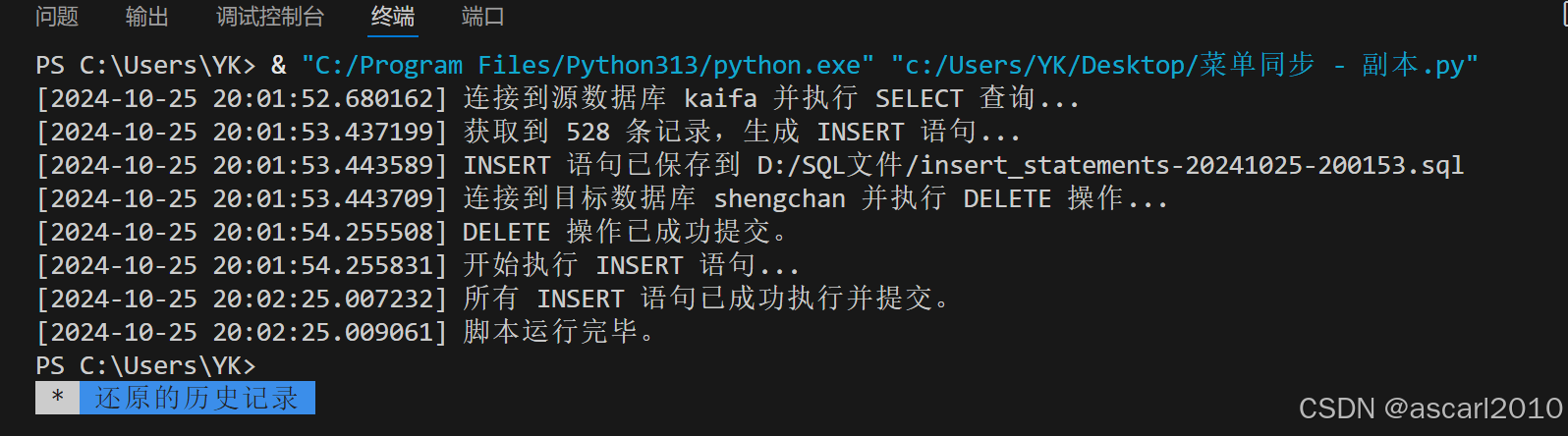
最终实现效果
2.编写脚本
import pyodbc
import sys
from datetime import datetime
def get_connection(dsn):
"""
创建数据库连接。
"""
try:
connection_string = f"DSN={dsn};"
conn = pyodbc.connect(connection_string)
return conn
except pyodbc.InterfaceError:
print("[错误] 无法找到指定的数据源名称,请检查 DSN 是否正确,并确认 ODBC 数据源已正确配置。")
sys.exit(1)
except pyodbc.Error as e:
print(f"[{datetime.now()}] 无法连接到数据库 {dsn}:", e)
sys.exit(1)
def fetch_data(conn, query):
"""
执行查询并返回数据和列名。
"""
try:
cursor = conn.cursor()
cursor.execute(query)
columns = [column[0] for column in cursor.description]
data = cursor.fetchall()
return columns, data
except pyodbc.Error as e:
print(f"[{datetime.now()}] 查询失败: {query}", e)
sys.exit(1)
def generate_insert_statements(table_schema, table_name, columns, data):
"""
根据查询结果生成INSERT语句。
"""
insert_statements = []
columns_joined = ", ".join([f'"{col}"' for col in columns])
for row in data:
values = []
for value in row:
if value is None:
values.append("NULL")
elif isinstance(value, str):
escaped = value.replace("'", "''")
values.append(f"'{escaped}'")
elif isinstance(value, bytes):
values.append(f"'{value.hex()}'")
elif isinstance(value, (datetime,)):
values.append(f"'{value}'")
else:
values.append(str(value))
values_joined = ", ".join(values)
insert_statement = f'INSERT INTO "{table_schema}"."{table_name}" ({columns_joined}) VALUES ({values_joined});'
insert_statements.append(insert_statement)
return insert_statements
def execute_statements(conn, statements):
"""
执行一系列SQL语句。
"""
try:
cursor = conn.cursor()
for stmt in statements:
cursor.execute(stmt)
conn.commit()
print(f"[{datetime.now()}] 所有 INSERT 语句已成功执行并提交。")
except pyodbc.Error as e:
print(f"[{datetime.now()}] 执行 SQL 语句失败:", e)
conn.rollback()
sys.exit(1)
def save_insert_statements_to_file(statements, file_path):
"""
将生成的 INSERT 语句保存到文件中。
"""
try:
with open(file_path, "w", encoding="utf-8") as file:
for stmt in statements:
file.write(stmt + "\n")
print(f"[{datetime.now()}] INSERT 语句已保存到 {file_path}")
except IOError as e:
print(f"[{datetime.now()}] 无法保存 INSERT 语句到文件 {file_path}:", e)
sys.exit(1)
def main():
# 数据源名称
source_dsn = "kaifa"
target_dsn = "shengchan"
# 要执行的 SQL 语句
select_query = 'SELECT * FROM "XXXX_XXXXX"."TXXXX_RXXXX_JGXX_XXXX" WHERE XXX in (13);'
delete_query = 'DELETE FROM "XXXXX_XXXXX"."TXXXX_RXXXX_JGXX_XXXX" WHERE XXX in (13);'
# 日志文件
log_file = "database_transfer.log"
with open(log_file, "a") as log:
log.write(f"\n[{datetime.now()}] 脚本开始运行。\n")
# 第一个连接:执行 SELECT 查询
print(f"[{datetime.now()}] 连接到源数据库 {source_dsn} 并执行 SELECT 查询...")
source_conn = get_connection(source_dsn)
columns, data = fetch_data(source_conn, select_query)
source_conn.close()
print(f"[{datetime.now()}] 获取到 {len(data)} 条记录,生成 INSERT 语句...")
# 生成 INSERT 语句
insert_statements = generate_insert_statements("XXXX_XXXX", "XXXX_XXX_XXXX_XXXXX", columns, data)
# 保存 INSERT 语句到文件
insert_file = f"D:/SQL文件/insert_statements-{datetime.now().strftime('%Y%m%d-%H%M%S')}.sql"
save_insert_statements_to_file(insert_statements, insert_file)
# 第二个连接:执行 DELETE 和 INSERT
print(f"[{datetime.now()}] 连接到目标数据库 {target_dsn} 并执行 DELETE 操作...")
target_conn = get_connection(target_dsn)
try:
cursor = target_conn.cursor()
# 执行 DELETE
cursor.execute(delete_query)
target_conn.commit()
print(f"[{datetime.now()}] DELETE 操作已成功提交。")
# 执行 INSERT
print(f"[{datetime.now()}] 开始执行 INSERT 语句...")
execute_statements(target_conn, insert_statements)
except pyodbc.Error as e:
print(f"[{datetime.now()}] 执行 DELETE 或 INSERT 操作失败:", e)
target_conn.rollback()
sys.exit(1)
finally:
target_conn.close()
with open(log_file, "a") as log:
log.write(f"[{datetime.now()}] DELETE 和 INSERT 操作完成。\n")
print(f"[{datetime.now()}] 脚本运行完毕。")
with open(log_file, "a") as log:
log.write(f"[{datetime.now()}] 脚本运行完毕。\n")
if __name__ == "__main__":
main()
3.脚本解释
在这个脚本中,INSERT 语句确实是先保存在内存中的。
具体来说,这里是整个过程的概述:
-
数据从源数据库提取:
- 首先,脚本通过
fetch_data()函数从数据源kaifa中提取数据,并返回列名和数据。 - 这些数据保存在 Python 的内存中。
- 首先,脚本通过
-
生成
INSERT语句:- 通过
generate_insert_statements()函数,将从源数据库中提取的数据转换为INSERTSQL 语句。 - 这些
INSERT语句同样保存在内存中,以insert_statements列表的形式存在。
- 通过
-
保存到 SQL 文件:
- 之后,脚本将
insert_statements列表中的内容保存到指定的文件路径 (D:/SQL文件/insert_statements-YYYYMMDD-HHMMSS.sql) 中。 - 这样做的目的是将生成的
INSERT语句保存到磁盘文件中,以便可以在必要时查看或手动执行这些 SQL 语句。
- 之后,脚本将
-
将数据导入目标数据库:
- 在导入操作中,脚本使用同一个
insert_statements列表来向目标数据源shengchan执行INSERT操作。 - 因此,
INSERT语句是在内存中保存后,直接从内存中读取并提交给数据库执行的。
- 在导入操作中,脚本使用同一个
总结
-
数据保存方式:
- 在生成
INSERT语句后,数据被保存在内存中的insert_statements列表中。 - 这份数据也被写入文件,但导入的实际操作是基于内存中的
insert_statements列表,而不是从文件中重新读取。
- 在生成
-
为什么这样做:
- 这种方式确保 SQL 执行的流程尽可能快,因为数据是在内存中直接操作的。
- 同时保存为 SQL 文件是为了日志记录或人工检查的目的,但并没有从文件中重新读取来导入数据。