目录
一、JVM内存模型
JVM运行时数据区
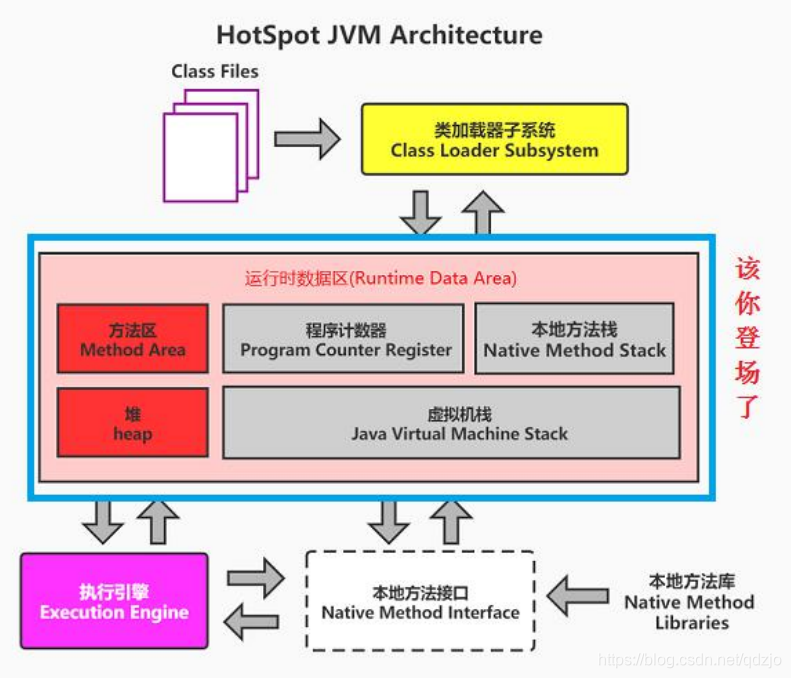
方法区:
1:线程共享
2:它是一个逻辑分区:JDK8之前方法区又称永久代,被分配在JVM内存中,JDK8开始方法区被分配到JVM内存区域外的内存区域(MetaSpace),原因是无需指定这块区域的大小
3:它主要存放:类元信息、运行时常量池、静态变量、JIT代码缓存、域信息、方法信息
4:类元信息:类的成员变量信息、类的方法信息、类的常量池信息等等(具体见oop-klass模型)
5:运行时常量池:
- 每个class文件都有一个常量池,里面存放字符串常量、类名、接口名,字段名和其他一些在class中引用的常量
- 每一个类被加载后,其中的常量池就会被加载到内存里(方法区运行时常量池)方便运行时调用
- 每个类都在运行时常量池有一份自己的数据
- 运行时常量池中有两种类型,分别是symbolic references符号引用和static constants静态常量;String a = "123",其中a就是符号引用,"123"就是静态常量
- 符号引用可以随着程序的运行进行更新,比如a指向了新的字符串
- 静态常量可以随着程序的运行不断的添加新的常量;静态常量包含数字常量和字符串常量,其中字符串常量存储只是字符串常量池的引用,字符串常量池JDK8之前存放在方法区JDK8之后存放在堆内
6:方法区位于MetaSpace,MetaSpace的初始大小为21M(-XX:MetaspaceSize),最大大小为系统内存的1/64(-XX:MaxMetaspaceSize)
堆:
1:线程共享;存放实例对象数据、字符串常量池和.class对象(JDK1.8之后)
2:堆内存初始为系统内存的1/64(可通通过-XX:Xms指定)最大为系统内存的1/4(可通通过-XX:Xmx指定)
虚拟机栈:
1:线程独有;每个线程使用虚拟机栈完成线程的代码执行过程
2:每个线程的栈大小,一般情况下为1024K,可以通过-XX:Xss设置
程序计数器:线程独有;存放栈中执行的下一条指令的指令地址
本地方法栈:调用Native方法时使用的栈空间
Java对象的创建过程
- 步骤一:在运行时常量池中找到Class对象的符号引用,如果找到则直接进入步骤三
- 步骤二:类加载过程
- 加载:从class文件中将类数据加载到内存(Bootstrap-Extension-Application-Custom,双亲委派机制;什么时候使用CustomClassLoader?由于java代码很容易被反编译,如果需要对自己的代码加密的话,可以对编译后的代码进行加密,然后再通过实现自己的自定义类加载器进行解密,最后再加载;也有可能从非标准的来源加载代码,比如从网络来源,此时需要CustomClassLoader进行指定源的类加载)
- 链接:验证(保证加载进来的字节流符合虚拟机规范)-准备(类静态变量分配内存并赋默认值)-解析(将常量池内的符号引用替换为直接引用)
- 初始化:对类静态变量进行初始化过程
- 步骤三:为对象分配内存
- 步骤四:为成员变量赋默认值
- 步骤五:执行构造函数
Java对象的内存布局
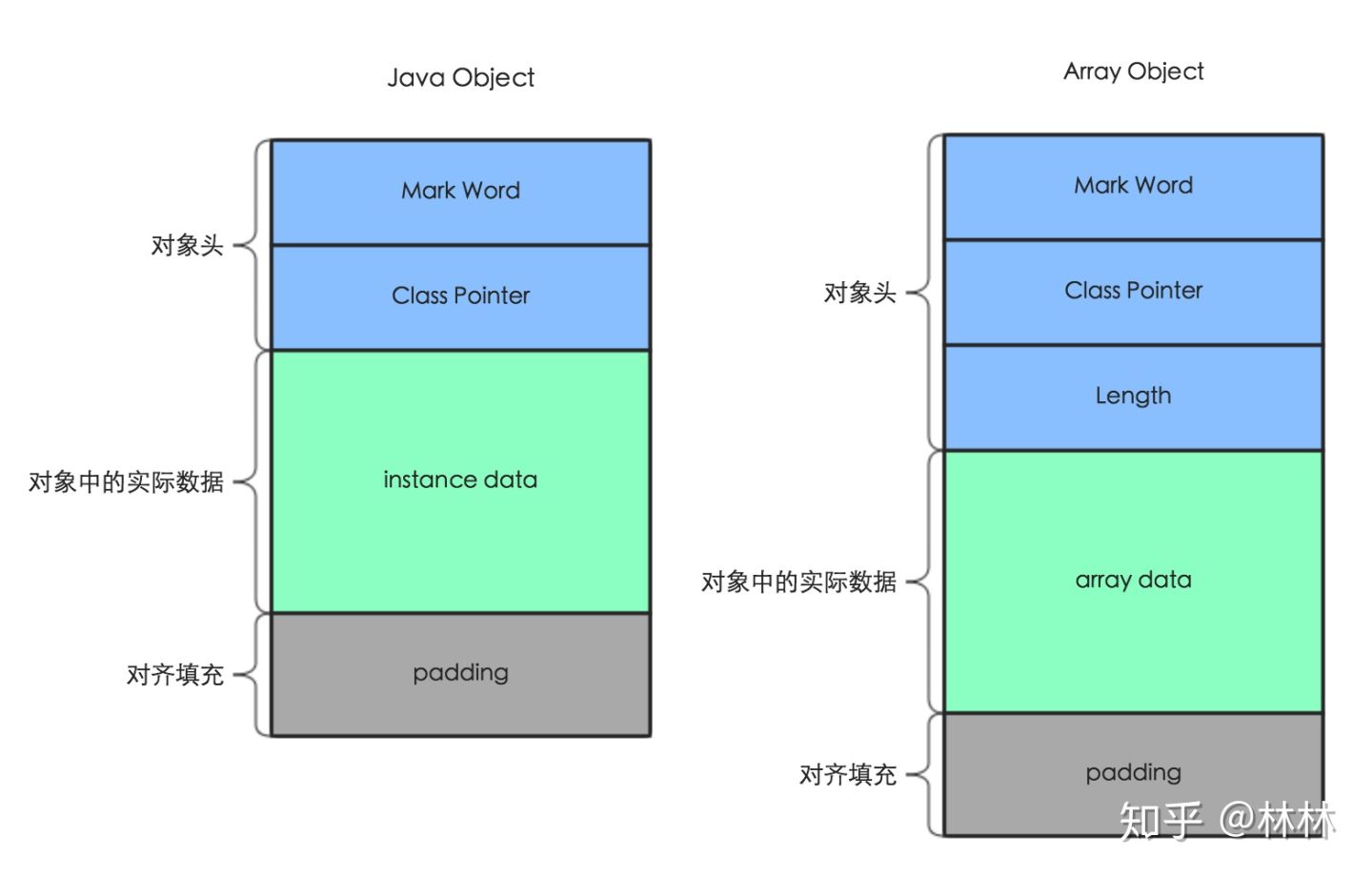
Mark Word存储了对象的hashCode、GC信息、锁信息三部分
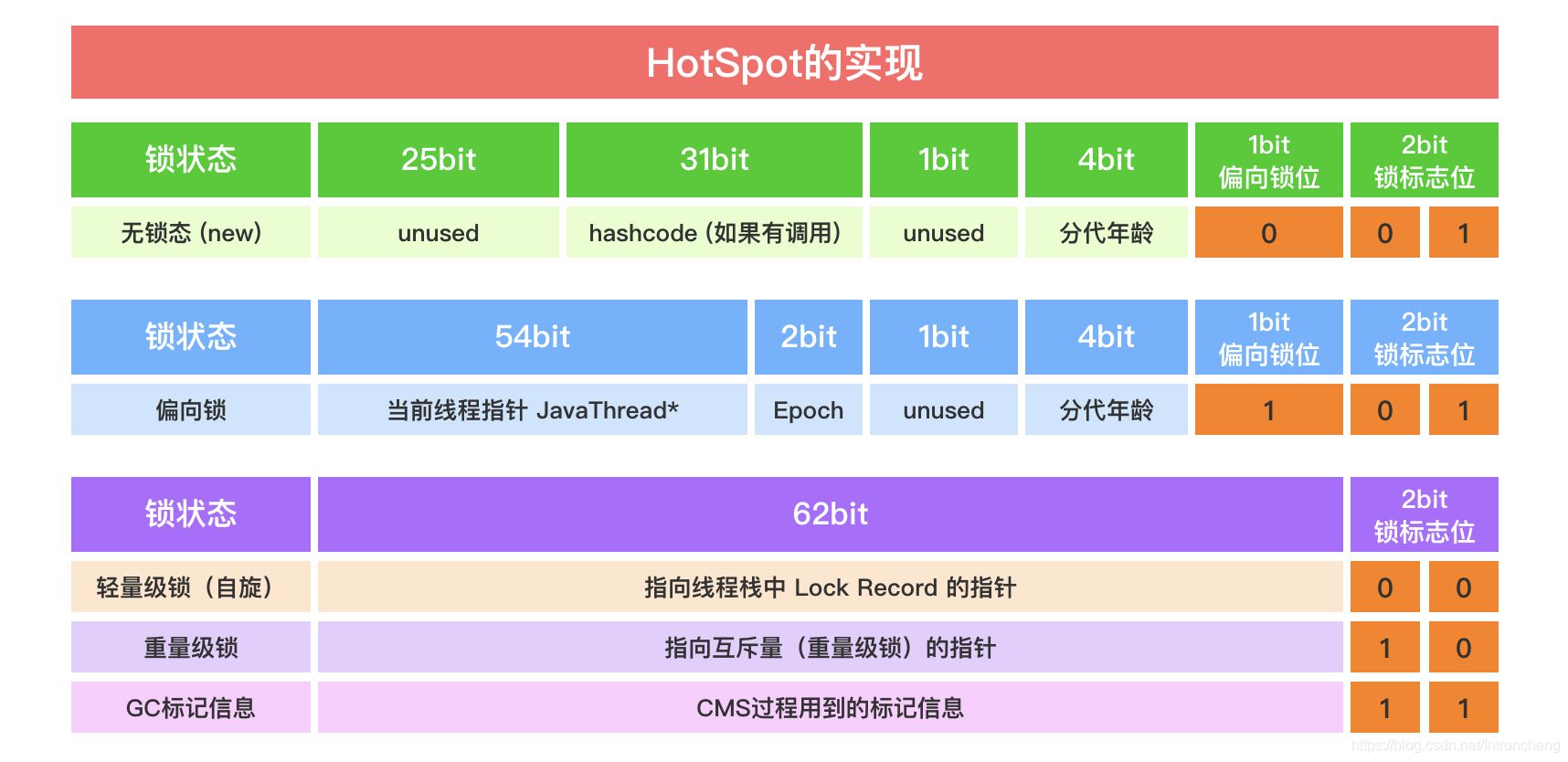
当锁状态为11时,对象处于GC过程中
class Pointer存储了指向方法区内对象类元信息的指针
Java对象怎么定位
1:直接引用(HotSpot虚拟机用的是这种方式)
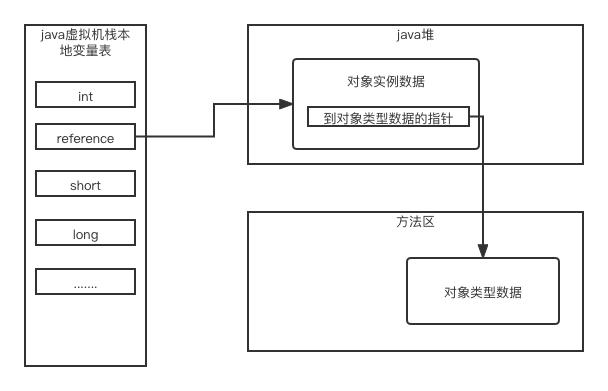
2:句柄方式引用
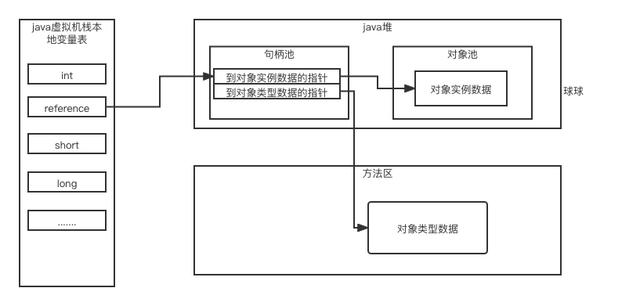
使用直接指针定位方式优点是快,使用句柄池定位方式有点是提升GC效率
Java对象怎么分配
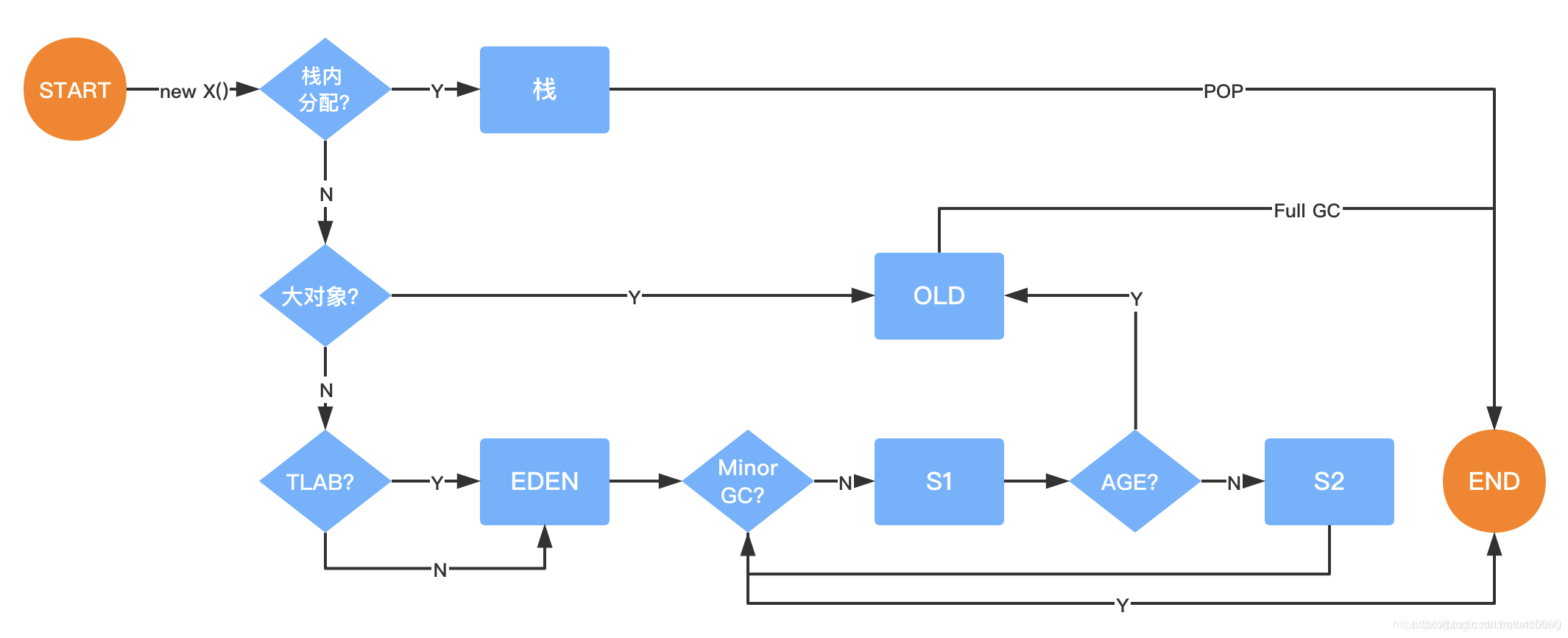
1:进入栈区:对对象进行逃逸分析和大对象分析,如果对象不逃逸且不是大对象,则对象被分配进入栈区
逃逸分析:对象不会在方法外被引用
大对象:Eden区分配不下;超过-XX:PretenureSizeThreshold参数(只对Serial和ParNew两种eden区垃圾回收器有效)
2:进入TLAB区:如果TLAB区域足够装下对象则直接进入,如果装不下则根据refill_waste(JVM运行时动态维护的一个变量)会有两种情况:1:请求对象大于refill_waste时将当前TLAB区域剩余的区域用dump object填满然后新开辟一块TLAB区域存放该对象;2:请求对象小于refill_waste时直接将请求对象放入Eden区
TLAB:Thread Local Allocation Buffer;多个对象被分配到堆上时会出现指针碰撞引起冲突,此时便出现了TLAB(也可以用CAS来解决指针碰撞问题),每个线程被创建出来之后JVM会在Eden区开放一块儿内存(约占Eden区的1%)作为该线程独有的内存区域
3:进入Eden区:1里已经进行过大对象分析,所以TLAB进不去对象就直接进入Eden区了
二、JVM垃圾回收
如何定位垃圾?
根可达算法:从根元素(栈里引用的对象、本地方法栈引用的对象、常量池内对象、静态变量引用的对象、.class对象)开始寻找,凡是通过根元素可以搜索到的对象,都不是垃圾
如何清理垃圾?
- 标记-清除算法:找到垃圾,然后标记垃圾,然后清除垃圾;缺点:位置不连续,会出现内存碎片
- 拷贝算法:开辟相同大小的内存空间,将不是垃圾的对象拷贝过去,拷贝完成后将旧的内存地址正片删除;缺点:虽然解决了内存碎片问题但太浪费内存
- 标记-压缩算法:先标记垃圾,然后清除垃圾的同时,将后面的非垃圾对象往前移动整理,最后将清理后的内存地址回收;缺点:算法效率低
JVM堆内存分带模型
1:传统垃圾回收器使用的模型(例如G1垃圾回收器就不适用新生代+老年代的模型)
2:新生代+老年代+永久代(JDK1.7)/元数据区(JDK1.8)
永久代和元数据区都是装.class对象
永久代必须指定大小限制,元数据区可以不指定大小限制
字符串常量存放在永久代(JDK1.7)/字符串常量存放在堆里(JDK1.8)
3:新生代=eden区+2个survivor区域(8:1:1)
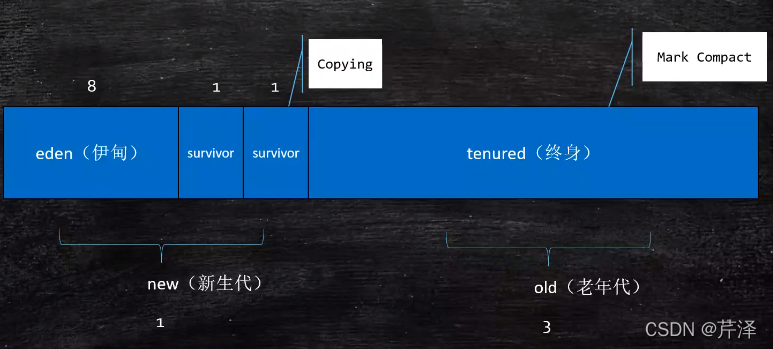
1:YoungGC后,回收eden的大部分对象,eden区活着的对象 -> survivor0区
2:再次YoungGC后,eden区域的对象+survivor0区的对象 -> survivor1区
3:再次YoungGC后,eden区域的对象+survivor1区的对象 -> survivor0区
4:每次YoungGC回收都会给对象增加年龄,年龄到了直接进入老年代
5:每次往survivor区拷贝对象时,如果survivor区内存不够了,则对象直接进入老年代
6:这种GC的模式比较适合使用拷贝算法
4:老年代
老年代满了,则进行FullGC(新生代和老年代进行一次整体GC,采用压缩算法)
5:占用内存
- JVM的堆内存初始为系统内存的1/64(可通通过-XX:Xms指定)最大为系统内存的1/4(可通通过-XX:Xmx指定)
- 新生代和老年代的大小比例默认比例为1:2,可以通过–XX:NewRatio指定
- 新生代里的Eden和Survivor区默认比例为8:1:1,可以通过–XX:SurvivorRatio指定(同时需要关闭-XX:UseAdaptiveSizePolicy)
MinorGC和FullGC的触发时机
MinorGC触发时机:Eden 区没有足够的空间分配给新创建的对象
FullGC触发时机:老年代空间不足、方法区空间不足、MinorGC后需要进入老年代的对象大于老年代的剩余空间、MinorGC前历史平均每次MinorGC进入老年代的对象大小大于老年代的剩余空间
JVM常见的垃圾回收器
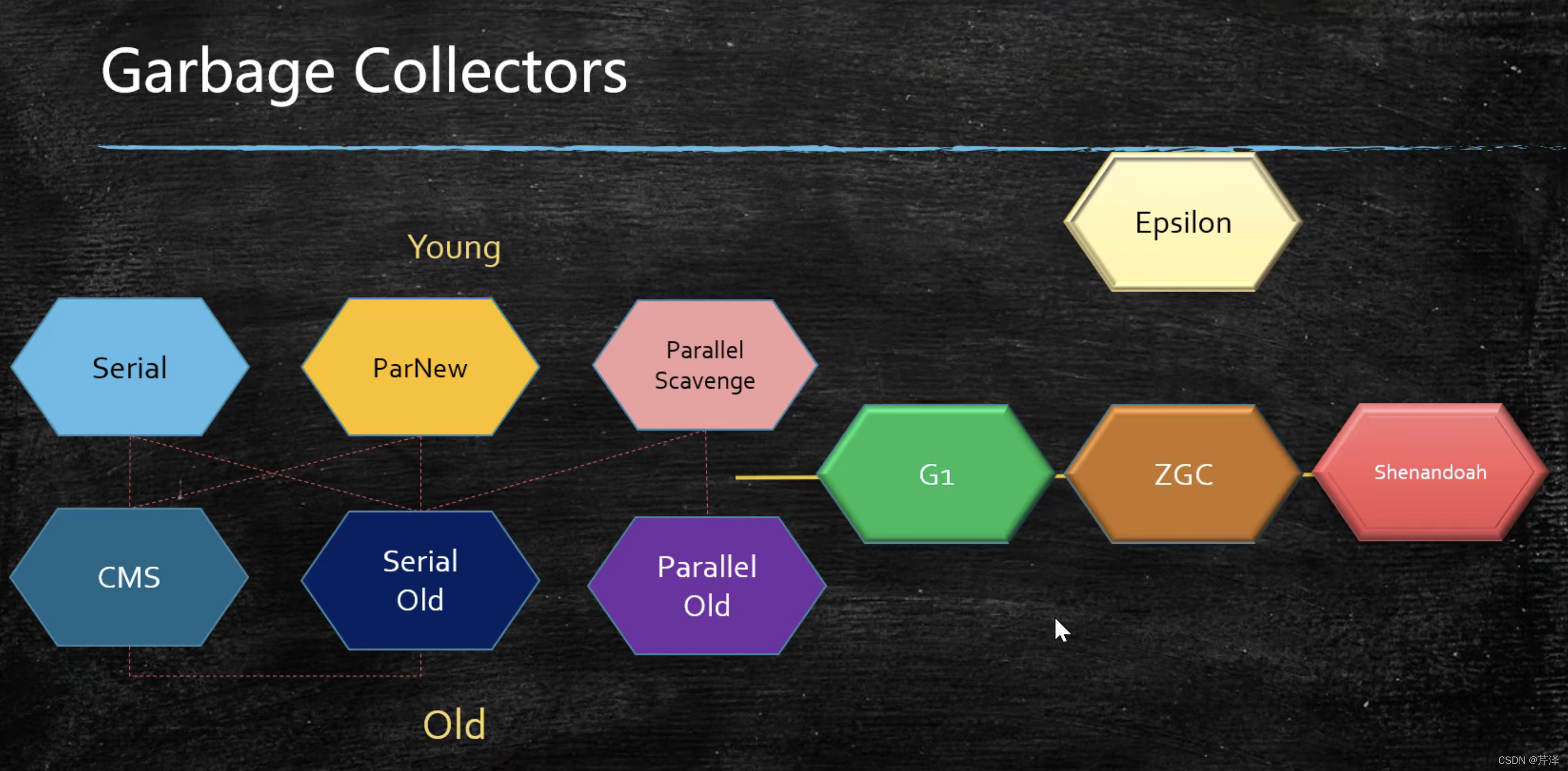
1.Serial:应用于新生代,串行回收器
2.Parallel Scavenge:应用于新生代,并行回收器
3.ParNew:应用于新生代,并行回收器 ,因为Parallel Scavenge无法和CMS配合使用,因而产生
4.Serial Old:就是将Serial算法应用于老年代
5.Parallel Old:就是将Parallel Scavenge算法应用于老年代
6.CMS:应用于老年代,并发,与应用程序并行运行,降低了STW时间,复杂
7.G1(10ms):未深究,视频有1小时40分钟专门讲G1
8.ZGC(1ms):使用三色标记法
9.Shenadoah
10.Eplison
JDK1.8默认的垃圾回收器是2+5
三色标记算法
回收对象时对对象进行三色标记,黑色、灰色、白色
存在浮动垃圾问题,CMS和G1的解决方案不同
三、面试问题
CPU突然100%问题排查
原因:
1:cpu的内核上下文切换频率过高。上下文切换需要经历保存运行线程的执行状态、让处于等待中的线程恢复执行这2个过程,这2个过程需要CPU执行内核指令,所以频繁的切换会占据大量的CPU资源;在java中文件IO、网络IO、锁等待都会促使CPU执行上下文切换
2:CPU资源过度消耗。过多的线程和执行时间较长的业务代码,都会导致CPU资源的消耗
排查步骤:
第一步:top 找出哪个进程占用cpu
第二步:top -Hp 进程号 找出这个进程的哪个线程占用cpu
第三步:printf "%x\n" tid将线程id转换为16进制,jstack进程号 |grep 线程号 -A 30,查看堆栈信息进行分析
分析:
情况1:占用CPU的线程总是同一个
jstack查看程序堆栈,分析是哪块儿业务逻辑在消耗CPU资源
情况2:占用CPU的线程总是不断变化
此时需要挑选出几个线程进行逐个分析
内存充裕,为什么会发生FullGC
有大对象;连续空间不够;方法区或MetaSpace满了;手动调用System.gc();
一个Object占多少个字节
内存小于32G:MarkWord占8个,klass pointer占4个,对象实例数据0个,padding占4个,一共16
内存大于32G:MarkWord占8个,klass pointer占8个,对象实例数据0个,padding占0个,一共16
四、JVM调优
JVM参数分类
标准:-开头,所有hotspot版本都支持
非标准:-X开头,不是所有hotspot版本都支持 查看 java -X
不稳定:-XX开头,有可能下个版本会移除 查看 java -XX:+PrintCommandLineFlags
java -XX:+PrintFlagsInitial --查看出厂默认值
java -XX:+PrintFlagsFinal -version --查看修改更新
java -XX:+PrintFlagsFinal -version |grep HeapSize --查找指定参数配置(:=为被更新过的值)
java -XX:+PrintCommandLineFlags -version --打印命令行参数(可以看默认垃圾回收器)
arthas
dashboard:展示所有线程的cpu和mem占用,展示GC情况
thread:打印线程详细信息
trace:跟踪类或者函数的所有调用并记录时间
jad:反编译class或者method代码
redefine:在线上修改类后,javac生成class文件,redefine重新加载class文件,redefine不能给类添加新的field或method
tt:追踪某个method的详细信息,入参 返回值等等
如何解决OOM问题
方法1:
设置JVM参数,-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/tomcat,让程序发生OOM时自动生成文件
方法2:当很久才会发生一次OOM,不可能等到OOM才分析时
使用jmap -histo [进程号]命令直接分析内存中哪些实例有可能会导致OOM,不推荐该方法,因为jmap本身非常占用内存
方法3:当使用jmap -histo [进程号]需要看的东西太多时
使用jmap -dump:live,format=b,file=[文件名].hprof [进程号]生成hprof文件,然后用MAT或VisualVM分析文件